1-数据库发展历程
1.1 数据库发展概述
从1960年:Integrated Database System(IDS),该系统是一个网状模型(Network Model)到 IMS(Information Management System),使用了层次模型(Hierarchical Model)支持事务处理。
再到IBM的E.F.Codd提出:A Relational Model of Data for Large Shared Data Banks 中 提 出 了 关 系 模 型(Relational Model),Michael Stonebraker 开 发 出PG的前身INGRES(Interactive Graphics and Retrieval System),后续便是DB2 Oracle…
1.1.4 云原生与分布式时代
随着业务处理规模增加,一种方法是垂直扩展(Scale up),提升数据库各个组件的容量,使用更好的硬件,比如小型机、高端存储,如著名的“IOE”解决方案,数据库系统架构使用多个计算节点共享一份存储,称为Shared-Storage架构
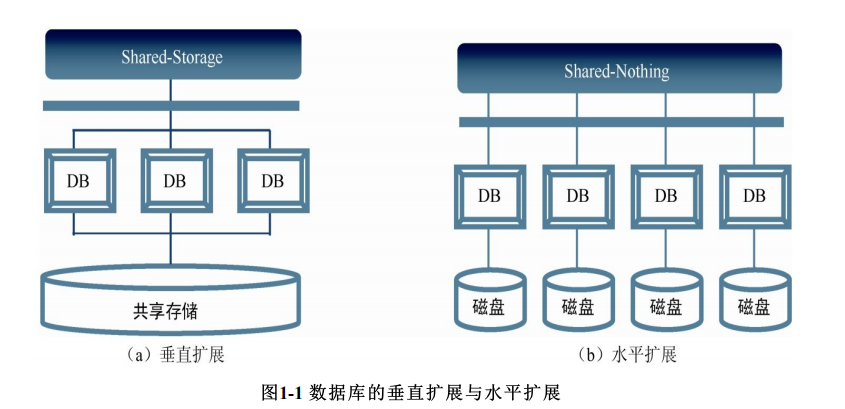
另一种方法是水平扩展(Scale out),还是保持原来单个数据库实例的容量不变,用更多的数据库节点组合为一个无共享(Shared-Nothing)分布式系统来解决问题,每个节点根据分布规则(Sharding Rule)存储一部分数据(Shard),处理一部分请求。
然后就是Google三驾马车,GFS、BigTable、MapReduce。
在处理频繁变化的业务和一些专用的特殊结构时殊为不便。一些使用更灵活的数据模型定义(Schemaless)或特殊的数据模型的数据库出现了,统称为NoSQL系统。NoSQL数据库主要包括键值(KeyValue,KV)数据库、文(Document)数据库、图(Graph)数据库三大类。键值数据库的代表为Redis、HBase和Canssandra;文档数据库的代表为MongoDB;图数据库的代表为Neo4j等。
1.2 数据库技术发展趋势
1.2.1 云原生与分布式
对于云数据库而言,基于资源解耦的高可用性是其基本特征。
面对高并发与大数据处理需求,云数据库应该具备水平扩展与分布式处理能力,包括但不限于负载均衡、分布式事务处理、分布式锁、多租户下的资源隔离与调
度、CPU混合负载和大规模并行处理等。
1.2.2 大数据与数据库一体化
要使云数据库具备大数据处理能力,一方面需要借助云基础设施的快速弹性、分布式并行处理特性,打造强劲的内核引擎,实现计算与存储资源效能的最大化,以可接受的性价比对外输出海量数据分析处理能力。另一方面,需要有与大数据分析处理相配套的生态工具,主要是数据流转迁移工具、数据集成开发工具以及数据资产管理能力。
1.2.3 软硬件一体化
利用异构计算设备GPU加速这些计算操作、还有FPGA、NVM。
网络上 RDMA、InfiniBand等。
1.2.4 多模
图(Graph)、键值(Key-Value)、文档(Document)、时序(Time Series)和时空(Spatial)等,以及图片、流媒体等非结构化数据
1.2.5 智能化运维
1.2.6 安全可信
1.3 关系数据库主要技术原理
- 接入管理
主要是ODBC JDBC
- 查询引擎
SQL引擎子系统负责将用户发送过来的SQL请求进行解析、语义检查、生成逻辑计划(Logical Plan),经过一系列重写(Rewrite)与优化(Optimize),生成物理计划(Physical Plan),交由计划执行器(Plan Executor)执行
- 事务处理
并发控制,根据异常不同等级定义了多个隔离级别(Isolation Level)选项,以严格程度依次增加分为:读未提交(ReadUncommitted)、读已提交(Read Committed)、可重复读(RepeatableRead)和可串行化(Serializable)。
主要的并发控制技术有以下几种:2PL、MVCC、OCC
日志与恢复系统:日志系统是数据库存储引擎中的核心部分,主要功能是保证已提交事务中的持久性(D),使得数据库在崩溃后仍然能将之前已提交的事务恢复过来,并且确保回滚中止执行的事务的原子性(A)。目前主要是根据ARIES论文的日志机制进行设计。
- 存储引擎
数据组织和索引管理:行列存储以及混合存储
缓冲区管理等。










