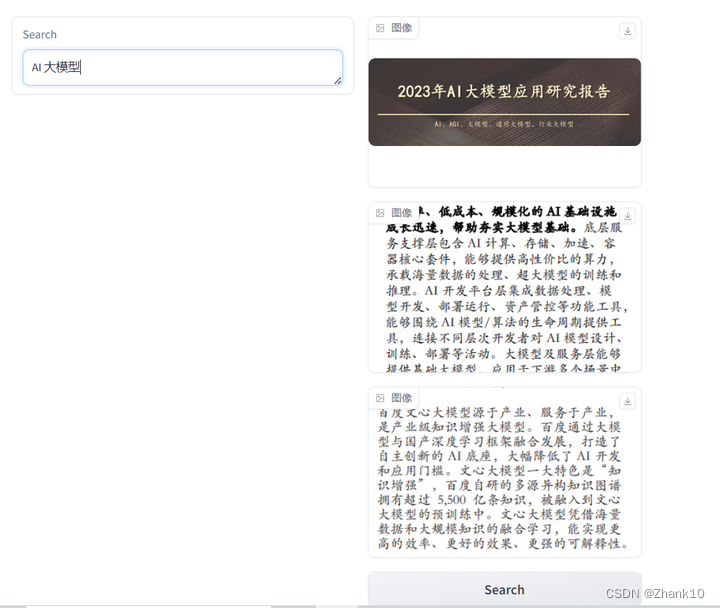
通过PaddleOCR识别图片中的文字,将识别结果报存到es中,利用es查询语句返回结果图片。
技术逻辑
- PaddleOCR部署、es部署
- 创建mapping
- 将PaddleOCR识别结果保存至es
- 通过查询,返回结果
前期准备
PaddleOCR、es部署请参考https://blog.csdn.net/zhanghan11366/article/details/137026144?spm=1001.2014.3001.5502
创建mapping
from elasticsearch import Elasticsearch
# 连接Elasticsearch
es_client = Elasticsearch("http://0.0.0.0:9200/", basic_auth=("elastic", "ZargEZ7NmJRkXLFlEqgE"))
# 创建新的ES index
mapping = {
'properties': {
'description': {
'type': 'text',
'analyzer': 'ik_smart',
'search_analyzer': 'ik_smart'
},
"insert_time": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
},
"image_path":{
'type': 'text'
}
}
}
es_client.indices.create(index='wechat_search_ocr', ignore=400)
result = es_client.indices.put_mapping(index='wechat_search_ocr', body=mapping)
print(result)
将PaddleOCR识别结果保存至es
核心代码展示
def image_ocr(image_dir):
files = os.listdir(image_dir)
image_files = [file for file in files if file.endswith(('jpg', 'jpeg', 'png', 'gif'))]
for image_file in image_files:
image_path = os.path.join(image_dir, image_file)
if not os.path.isfile(image_path):
print(f"文件不存在:{image_path}")
continue
image = cv2.imread(image_path)
if image is None:
print(f"无法读取图像:{image_path}")
continue
image_base64 = cv2_to_base64(image)
data = {'images': [image_base64]}
headers = {"Content-type": "application/json"}
url = "http://192.168.30.71:8866/predict/ch_pp-ocrv3"
try:
r = requests.post(url=url, headers=headers, data=json.dumps(data))
r.raise_for_status() # 检查请求是否成功
ocr_results = r.json().get("results", [])
if ocr_results:
description = "\n".join([ocr_record["text"].strip() for ocr_record in ocr_results[0]["data"]])
doc = {
"description": description,
"insert_time": dt.now().strftime("%Y-%m-%d %H:%M:%S"),
"image_path": image_file
}
es_client.index(index="wechat_search_ocr", body=doc)
print("成功插入到 Elasticsearch 中!")
else:
print("OCR 服务返回结果为空!")
except Exception as e:
print(f"处理图像 {image_path} 时发生错误:{str(e)}")
通过查询,返回结果
核心代码展示
def image_search_by_text(query_str):
result = []
# 对query进行全文搜索
queries = query_str.split()
dsl = {
"query": {
"bool": {
"must": [
{"match": {"description": _}} for _ in queries
]
}
},
"size": 5
}
search_result = es_client.search(index='wechat_search_ocr', body=dsl)
return search_result
def image_search_interface(query_str):
# 查询图像
search_results = image_search_by_text(query_str)
# 构建结果
images=[]
for hit in search_results['hits']['hits']:
image_filename = hit['_source']['image_path']
image_path = os.path.join('./data', image_filename)
image = Image.open(image_path).convert('RGB')
images.append(image)
if len(images) >= 3:
images = images[:3]
else:
for _ in range(3 - len(images)):
images.append(None)
return images[0], images[1], images[2]
结果如下: