上两次教程集中学习了R语言的基本知识,那么我们很多时候使用R语言是进行统计分析,因此对于生物信息学和统计科学来说,R语言提供了简单优雅的方式进行统计分析。教程参考《Rlearning》
3.1 描述性统计分析
3.1.1 载入数据集及summary函数
我们使用mtcars数据集,里面是一个不同信号汽车不同统计参数的矩阵:
data("mtcars")
coln <- c("mpg","hp","wt") #每加仑行驶数、马力、车重
mydata <- mtcars[coln]
head(mydata)我们可以通过summary函数直接粗略查看一下各个列数据的统计值:
summary(mydata)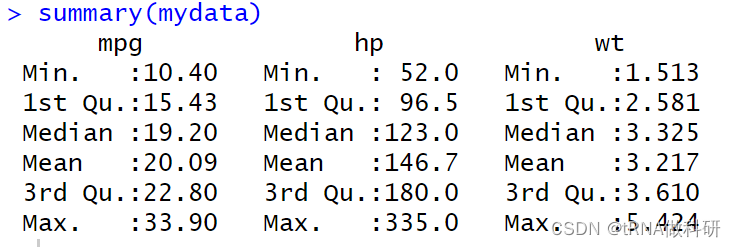
3.1.2 Hmisc包、pastect包、psych包
一些第三方包提供了优雅和快捷的统计分析,我们先安装及载入包:
install.packages("Hmisc")
install.packages("pastecs")
install.packages("psych")
library(Hmisc)
library(pastecs)
library(psych)(1)Hmisc的describe函数计算描述性统计可以得到变量/观测值/缺失值/唯一值/及五个最大最小值/各分位数等详细信息
Hmisc::describe(mydata)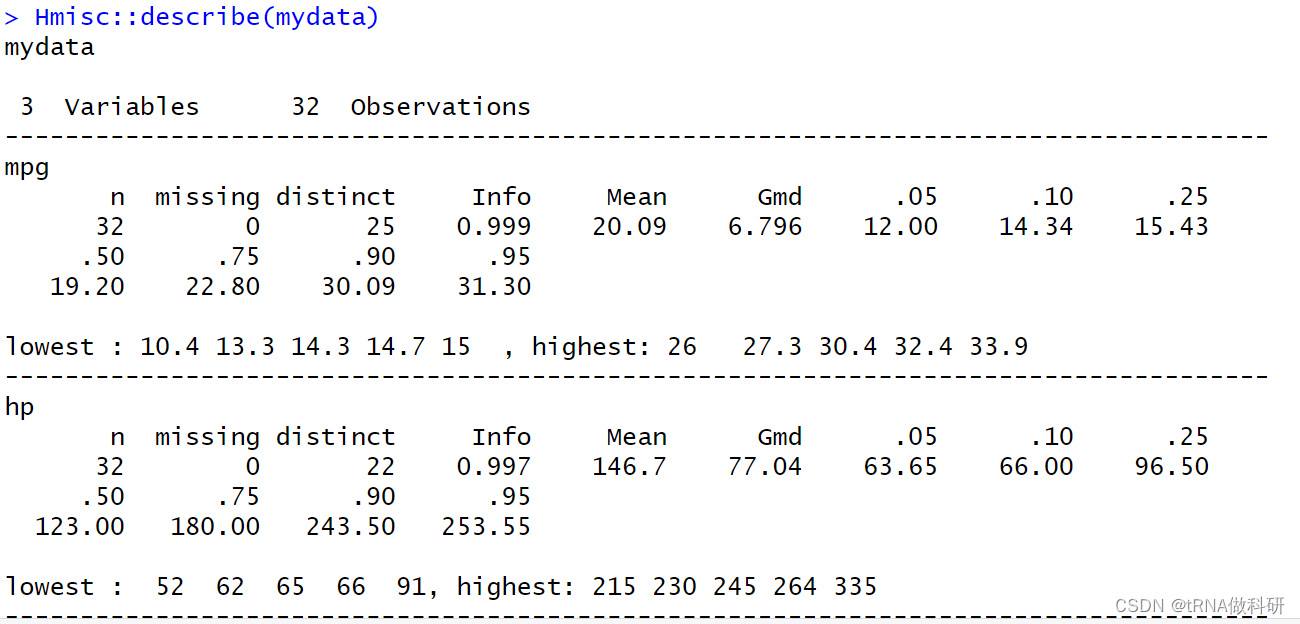
(2)pastecs包的stat.desc()函数计算复杂多样描述性统计量:
stat.desc(mydata)
(3)psych包的describe函数提供值域、偏度、峰度、标准误等信息:
psych::describe(mydata)
大家可以根据不同的需求选择不同的包实现简单统计计算。
3.1.3 分组统计计算
在我们的很多统计分析中,变量是由很多不同组的数据组成的,因此不分组直接进行计算是不正确的,因此我们可以对不同组的描述性变量进行统计分析。我们的数据集中,有一个变量am是自动手动挡的分类变量,我们用这个变量进行演示:
(1)使用doBy包的summaryBy函数分组:
install.packages("doBy")
library(doBy)
doBy::summary_by(mpg+hp+wt~am,data = mtcars)
(2)psych包分组计算:
psych::describeBy(mydata,list(am=mtcars$am))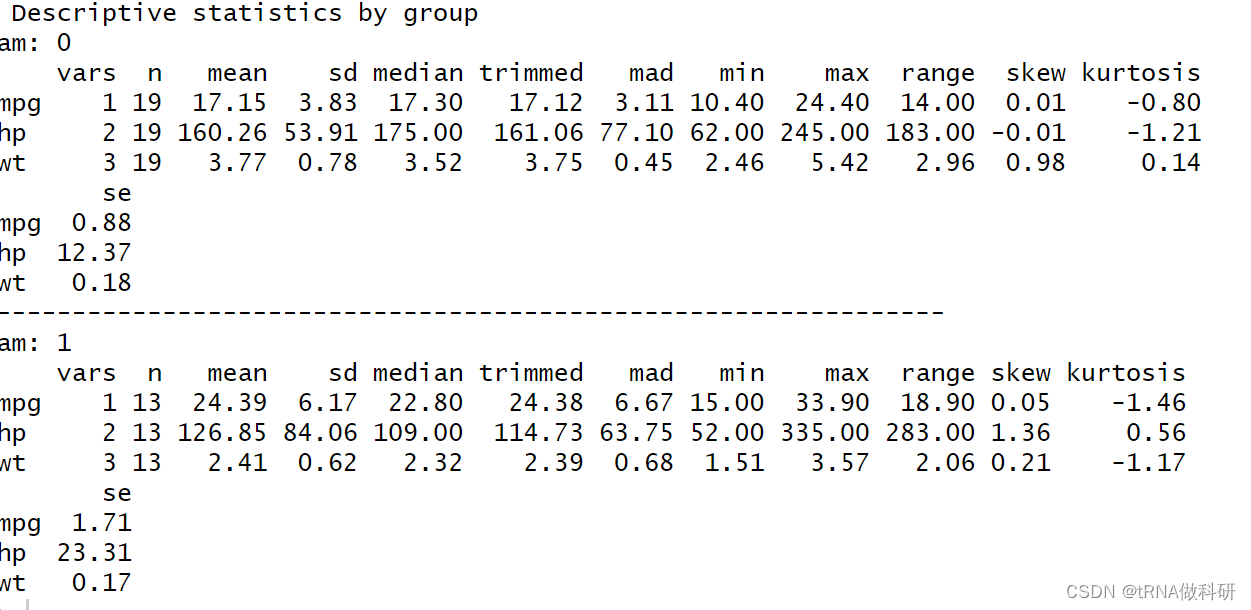
这样得到的分组统计信息是更详细的
3.2 频数表和列联表
对于非连续型变量,比如名字或者性别,我们更关注的是总量或者分类总量,那我们就可以使用频数表或者列联表进行展示:我们使用临床数据集,关于风湿关节炎治疗的数据进行演示:
install.packages('vcd')
library(vcd)
head(Arthritis)
3.2.1 一维列联表
如果我们感兴趣某一个非连续变量,比如改善状况的统计:
(1)频数统计
tab1 <- with(Arthritis,table(Improved))
tab1 
(2)占比统计:
tab2 <- prop.table(tab1)*100
tab2  、
、
3.2.2 二维列联表
(1)当我们想看不同分组变量在另一个非连续变量中的统计,我们可以使用二维列联表
tab3 <- xtabs(~ Treatment+Improved, data = Arthritis)
tab3
(2)计算边际频数及比例:
我们在医学使用列联表的时候,常常需要计算边际频数及其比例(1和2代表第一个变量或者第二个变量)
margin.table(tab3, 1)
prop.table(tab3, 1) 
margin.table(tab3, 2)
prop.table(tab3, 2) 
我们也可以计算总共的边际变量及其比例:
addmargins(tab3)
addmargins(prop.table(tab3)) 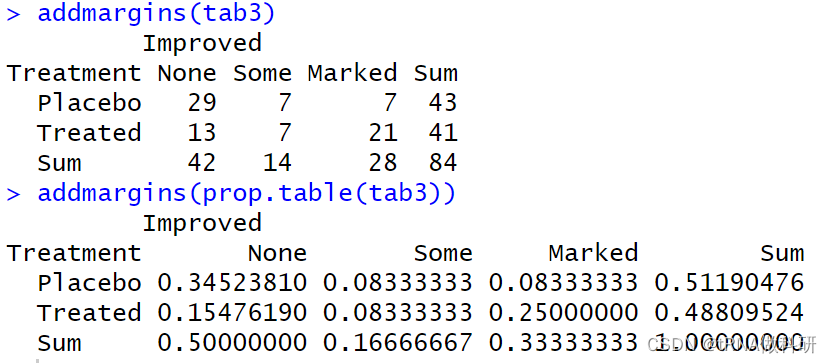
这样我们可以看到明显改善患者里25%都是接受治疗的
(2)使用gmodels包进行精美二维列联表绘制:
install.packages('gmodels')
library(gmodels)
CrossTable(Arthritis$Treatment,Arthritis$Improved) 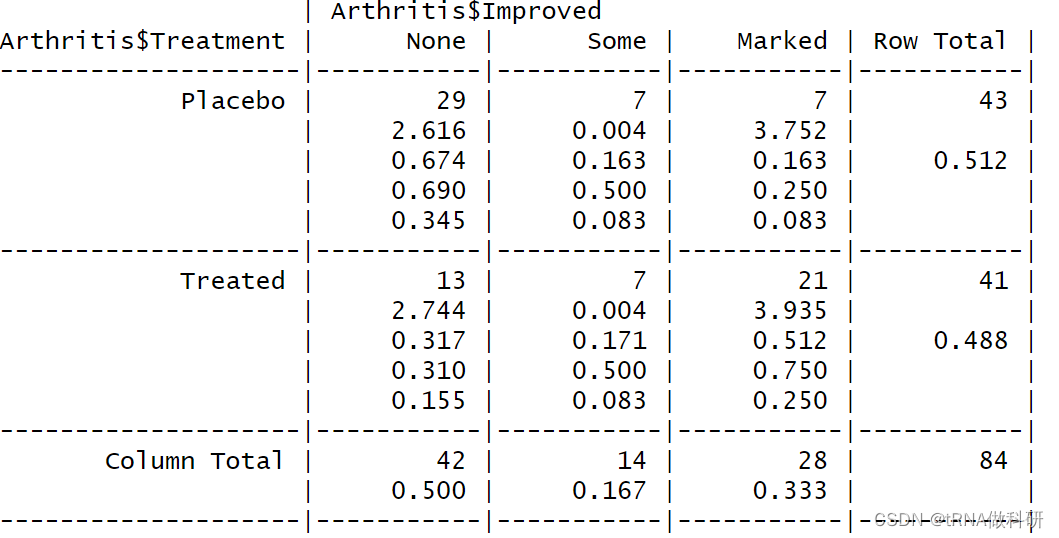
3.3 独立性检验
3.3.1 卡方检验
使用chisq.test()函数可以对二维列联表的行列向量进行卡方独立性检验,我们以代码演示:
library(vcd)
mytable <- xtabs(~Treatment+Improved, data=Arthritis)
chisq.test(mytable)
mytable <- xtabs(~Improved+Sex, data=Arthritis)
chisq.test(mytable)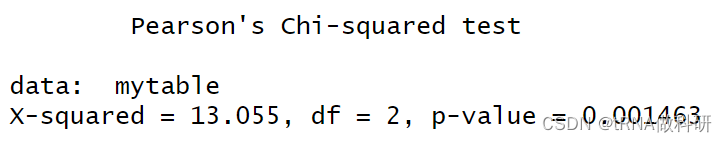
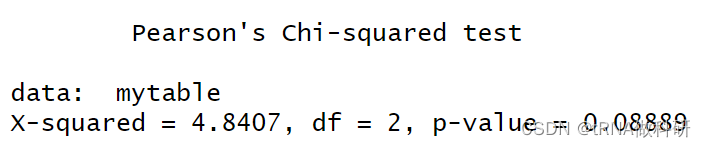
我们通过卡方检验可以获得变量之间是否存在关系,比如对于治疗方法和改善效果之间我们发现p-value远小于0.01,说明有关系,但是患者的性别和治疗效果之间并没有发现很明显的关系。
![]()
报错是因为计算发现有突出的样本,所以我们算出来的性别和治疗效果之间虽然大于0.05,但是不足够大。
3.3.2 Fisher精确检验
Fisher精确性检验,也称为Fisher's Exact Test,是一种统计学上用于检验两个分类变量之间是否相互独立的假设检验方法。这种检验特别适用于当数据呈现为2x2列联表(即四格表)的情形,并且在列联表的任何一栏中理论频数小于5时,传统的卡方检验可能不再适用,因为此时卡方检验的准确性会受到影响。Fisher精确性检验的基本原理是利用超几何分布来计算在给定边缘频率(即每一行和每一列的总频率)固定的情况下,观察到的频数分布出现的概率。如果这个概率值很小,我们就有理由拒绝原假设(通常指两个变量独立),从而认为两个变量之间存在某种关联性。值得注意的是,Fisher检验与卡方检验不同,它是一种确切概率法,能够提供真正的P值而不是一个近似值。因此,当数据不满足卡方检验的条件时,或者研究者希望得到一个更准确的结果时,Fisher检验是一个很好的选择。我们通过代码来实现:
library(vcd)
mytable <- xtabs(~Treatment+Improved, data=Arthritis)
fisher.test(mytable)
mytable <- xtabs(~Improved+Sex, data=Arthritis)
fisher.test(mytable)

我们发现得到了精确的p值,而且我们刚刚猜测不想关的性别和治疗的p-value变得比较大,因此我们有足够依据进行否定。
3.3.3 三变量独立性检验-Cochran-Mantel-Haenszel检验
Cochran-Mantel-Haenszel检验(简称CMH检验)是一种在统计学中用于处理分层数据的多变量测试方法,它主要用于检验多个层次上的变量间是否存在关联。这种方法尤其适用于当研究设计涉及多个分层因素时,例如在流行病学研究中,研究者可能会考虑性别、年龄组等多个分层变量来评估某一暴露因素与疾病之间的关联。CMH检验的原理在于计算一个综合优势比(Odds Ratio,OR),该优势比是在控制了所有分层变量后的暴露因子与疾病之间关系的度量。其基本步骤包括:首先设定原假设,即所有层的OR都等于1,表示暴露因子与疾病无关;接着,通过特定的公式计算CMH统计量,并据此得出P值以判断结果是否具有统计学意义。在实际应用中,CMH检验有助于减少由于分层变量导致的偏差,提高估计的准确性和可靠性。例如,在一项关于药物效果的研究中,研究人员可能会使用CMH检验来调整患者的年龄、性别等人口学特征,以确保所观察到的药物效果不是由这些变量引起的假象。
mytable <- xtabs(~Treatment+Improved+Sex, data=Arthritis)
mantelhaen.test(mytable)
得到治疗方法与改善在性别上并不独立。
3.4 相关性检验
我们可以先进行独立性检验后再仔细看看相关性:
library(vcd)
mytable <- xtabs(~Treatment+Improved, data=Arthritis)
assocstats(mytable) 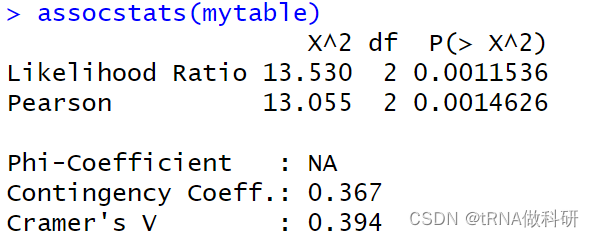
3.4.1 Pearson、Spearman和Kendall相关
Pearson、Spearman 和 Kendall 都是用于衡量两个变量之间相关性程度的统计指标。
(1)Pearson相关系数是最常用的相关系数之一,主要用于度量两个连续型随机变量之间的线性相关程度。其值的范围是从-1到1,其中1表示完全正相关,-1表示完全负相关,而0表示没有线性关系。Pearson相关系数的计算公式基于两变量的协方差与各自标准差的乘积之比,适用于数据呈正态分布或接近正态分布的情况。
(2)Spearman等级相关系数则是一种非参数的相关性检验方法,它通过计算两个变量的秩次(即数据的排名顺序)之间的相关性来评估它们之间的关系。Spearman相关系数对异常值和数据分布形态不敏感,因此当数据不满足正态分布假设时,或者存在离群值时,使用Spearman相关系数更为合适。
(3)Kendall等级相关系数也是基于秩次的非参数相关性测量方法,它考虑了所有可能的配对数目,并通过比较每一对观测值的秩次一致性来计算相关系数。Kendall相关系数同样适用于非正态分布的数据,并且对异常值的影响较小。
(4)如果数据满足正态分布,可以使用Pearson相关系数;如果数据分布未知或不满足正态分布,或者存在异常值,那么可以考虑使用Spearman或Kendall相关系数。
# 生成模拟数据
set.seed(123)
x <- rnorm(100, mean = 50, sd = 10)
y <- 2 * x + rnorm(100, mean = 0, sd = 5)
# 计算Pearson相关系数
pearson_cor <- cor(x, y, method = "pearson")
print(paste("Pearson correlation coefficient:", pearson_cor))
# 计算Spearman相关系数
spearman_cor <- cor(x, y, method = "spearman")
print(paste("Spearman rank correlation coefficient:", spearman_cor))
# 计算Kendall相关系数
kendall_cor <- cor(x, y, method = "kendall")
print(paste("Kendall rank correlation coefficient:", kendall_cor))这样我们就可以对数据集计算三个相关性系数:

3.4.2 偏相关
偏相关,也称为部分相关,是指在控制了其他变量影响的情况下,两个变量之间的相关性。这种分析方法允许研究者排除第三变量的干扰,从而更准确地估计目标变量间的直接关系。在统计学中,偏相关系数是通过回归分析得到的,具体地,它是通过将其他控制变量纳入回归模型后,所保留的两个变量间的相关系数。这个概念在处理多变量数据时尤为重要,因为它有助于识别和量化变量间的独立关联,而不是由于与其他变量的共线性而产生的虚假关联。
举个例子,如果我们想研究教育水平和收入水平之间的相关性,但同时知道工作经验也会影响收入,那么我们就可以通过计算偏相关系数来排除工作经验的影响,从而得到教育水平和收入之间更纯粹的关系。
偏相关系数通常用ρ表示,它的取值范围是-1到1。正值表示正相关,负值表示负相关,而数值的绝对大小则表示相关性的强度。值得注意的是,偏相关系数的解释与普通的相关系数类似,但它提供了一种在多变量情境下控制和分离变量效应的方法。
我们使用美国各州人口、收入等变量数据集进行演示:
states <- state.x77[, 1:6]
cov(states)
cor(states)
install.packages('ggm')
library(ggm)
colnames(states)
pcor(c(1,5,2,3,6),cov(states))得到在控制2/3/6变量的情况下,1和5的偏相关系数也就是人口和谋杀率的相关性
![]()
3.4.3 相关性显著性检验
我们通过psych包进行计算
library(psych)
corr.test(states, use = 'complete')
可以得到一个相关性系数矩阵
3.5 t检验
T检验是一种统计方法,用于确定两组数据是否存在显著差异。这种方法特别适用于样本量较小的情况,比如少于30个样本。T检验可以帮助研究人员判断观察到的差异是否超出了偶然变异的范围,也就是说,它可以帮助确定差异是否具有统计学意义。
在进行T检验之前,需要确保数据满足一些前提条件,包括数据的正态性、独立性以及两组数据的方差相等。如果不满足这些条件,可能需要采用非参数检验方法,如Mann-Whitney U检验。
T检验可以分为单样本T检验、独立样本T检验和配对样本T检验三种类型。单样本T检验用于比较单个样本的均值与已知的总体均值是否有显著差异。独立样本T检验则用于比较两个独立样本组的均值是否有显著差异。配对样本T检验适用于比较同一组受试者在两种不同条件下的表现是否有显著差异。
T检验的结果通常以P值的形式呈现,P值小于事先设定的显著性水平(通常是0.05)时,我们认为两组数据之间存在显著差异。
3.5.1 独立样本t检验
独立样本t检验是一种统计方法,用于比较两组独立样本的平均数是否存在显著差异。这种检验通常在实验设计中使用,其中实验组和对照组的数据是相互独立的。独立样本t检验的基本前提是每组数据都来自正态分布的总体,并且两组的方差相等(即方差齐性)。
假设一个教育研究员想要测试一种新的教学方法对学生考试成绩的影响。他选择了两个班级的学生作为样本,其中一个班级采用传统教学方法(对照组),另一个班级采用新的教学方法(实验组)。在学期末,两个班级的学生都参加了同样的考试。研究员收集了两组学生的考试成绩,并希望了解新教学方法是否比传统教学方法更有效。
在这种情况下,研究员可以运用独立样本t检验来分析数据。他会计算出两个班级考试成绩的平均数,并检查这两个平均数是否存在显著差异。如果t检验的结果显示P值小于预先设定的显著性水平(例如0.05),那么研究员就可以得出结论,认为新教学方法与传统教学方法相比,在提高学生考试成绩方面有显著的差异。
需要注意的是,独立样本t检验只适用于两个独立样本组的比较,而不能用于配对样本(例如同一个学生在两种不同教学方法下的成绩比较)或单一样本(例如一个班级的成绩与理论上的全国平均水平比较)的情况。在这些情况下,应使用相应的配对样本t检验或单样本t检验。
library(MASS)
t.test(Prob ~ So, data = UScrime)
3.5.2 非独立样本t检验
sapply(UScrime[c("U1","U2")], function(x)(c(mean=mean(x),sd=sd(x))))
with(UScrime, t.test(U1, U2, paired=TRUE))
3.6 小结
本次教程,我们聚焦如何使用R语言进行统计分析,这对于临床分析至关重要,当然现在不断有新的包出现来解决统计的计算,后续也会更新新包的用法教程,有什么问题欢迎一起讨论交流。










