
目录
1.实验背景
分类是现实生活中常见的问题,是人们认识事物本质,进行科学研究的主要手段之一。传统的分类学已有十分完善的理论框架和方法体系,但即便如此,随着计算机技术的进步和社会的发展,越来越多的领域出现了复杂庞大的分类问题,采用传统的方法无法产生理想的结果,因此,人们借助计算机,研究出了更多的分类算法,如支持向量机SVM分类,随机森林分类以及本实验采取的LSTM分类方法等。该实验在LSTM相关理论基础之上,依据HCV检测者的测试指标对测试者进行分类,检验该方法是否对于多指标多分类问题具有较好适用性。
2.实验内容及数据
2.1概述
项目数据来自UCI机器学习知识库。收录日期是2020-06-10,由德国汉诺威医科大学临床化学研究所捐赠。该数据集包含献血者和丙型肝炎患者的实验室数据和年龄等人口学数据。
数据集特征: 多元
实例数量:377
领域:生活
属性特征:实整型
属性数量:14
相关的任务:分类 (含有缺失的值,对缺失值采取填充的方式解决)。
数据集分类的目标属性是类别:0=献血者(即未发现丙肝病毒的人)、0s=疑似者、与三类丙型肝炎者,包括:1=仅为丙型肝炎、2=纤维化、3=肝硬化。部分数据如下图2.1原始数据所示:
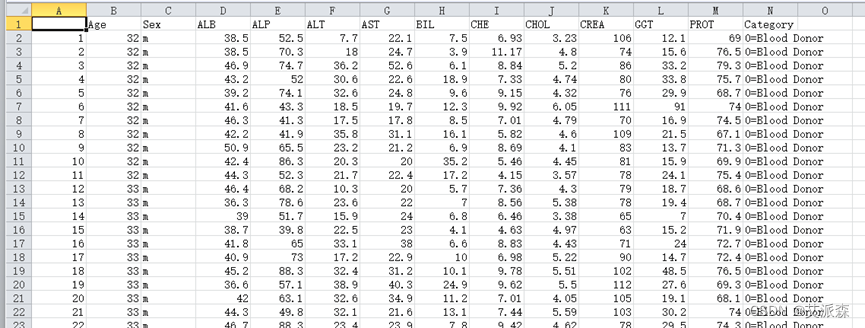
图 2.1 原始数据
2.2变量介绍
下面对原始数据中的变量进行相关说明,变量说明如表 2.1 变量说明所示。
表 2.1 变量说明
| 变量名 | 说明 |
| Age | 年龄 |
| Sex | 性别(m:男 f:女) |
| ALB | 白蛋白 |
| ALP | 碱性磷酸酶 |
| ALT | 谷丙转氨酶(表现肝功能是否正常) |
| AST | 天门冬氨酸氨基转移酶 |
| BIL | 胆红素 |
| CHE | 血清胆碱酯酶 |
| CHOL | 胆固醇 |
| CREA | 血清肌酐 |
| GGT | 谷氨酰转肽酶 |
| PROT | 蛋白质纤维 |
| Category | 类别(标签) |
前两项为被测者基本信息,3-12项为被测者检测指标,为浮点型数据,也是分类的主要属性,最后一项为被测者的实际类别(Category :values: '0=Blood Donor', '0s=suspect Blood Donor', '1=Hepatitis', '2=Fibrosis', '3=Cirrhosis';分别表示0=献血者(即未发现丙肝病毒的人)、0s=疑似者、1=仅为丙型肝炎、2=纤维化、3=肝硬化。
3.实验步骤
3.1导入数据和模块
进行程序编写前先导入我们所需要的模块。
运行下面区域的代码载入hcv数据集。以进行后续的分析。

3.2分析数据
3.2.1基础统计
用info命令,head命令和describe命令分别对数据集进行初步的查看与分析。

data.info()查看数据集基本信息如图3.1所示:
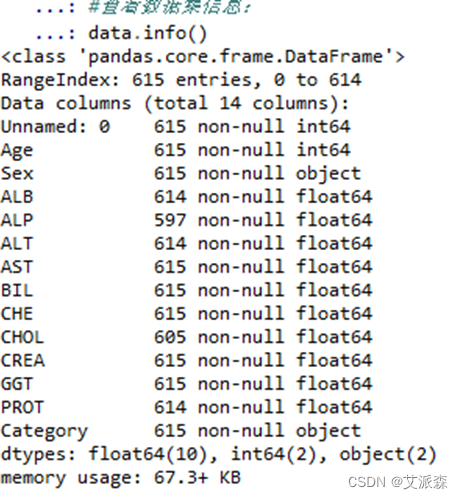
图 3.1 data.info()
可以看出,数据共有615条记录,14列,部分特征存在缺失值,如ALP只有597条有效数据。
data.head()查看数据集基本信息如图3.2所示: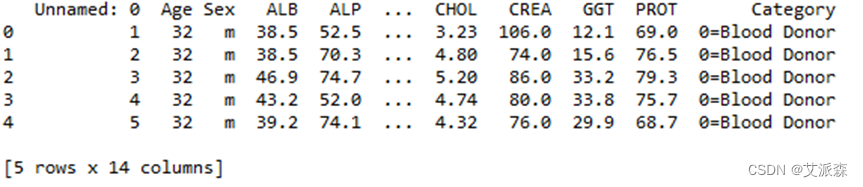
图 3.2 data.head()
可以看到数据的前5条记录。
data.describe()查看数据集基本信息如图3.3所示:
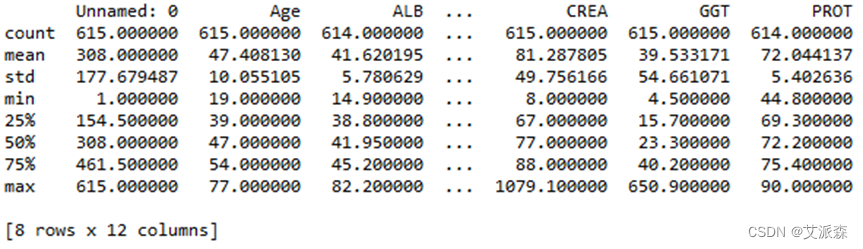
图 3.3
可以看出各列数据的统计信息,最大最小值,均值等信息,可以为后面的作图提供依据。
3.2.2特征标签关系
下面将对各特征与标签之间的关系进行研究,通过下方代码可以绘制出各特征与标签的散点分布图关系,考虑到篇幅问题,这里只展示指标ALB,ALP及CHE与类别的关系。绘制结果如图3.4至图3.5所示。

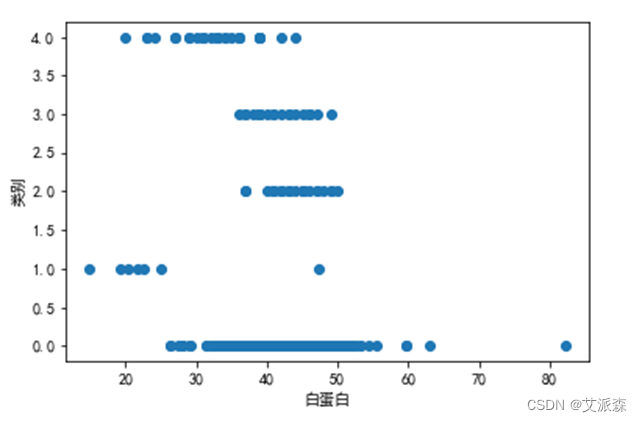
图 3.4 白蛋白与类别的关系
可以看出类别1与类别4白蛋白数量明显小于其他三类,但考虑到1类疑似者数量等其他方面的误差因素,白蛋白指标差异并不足以推断该案例中类别与该指标的关系。
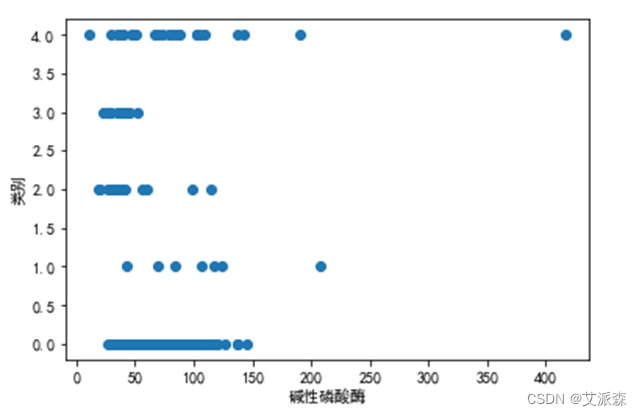
图 3.5碱性磷酸酶与类别的关系
可以看出1到4类被测者体内碱性磷酸酶含量明显低于正常者,可推断碱性磷酸酶是确定HCV类别的较为重要的指标。
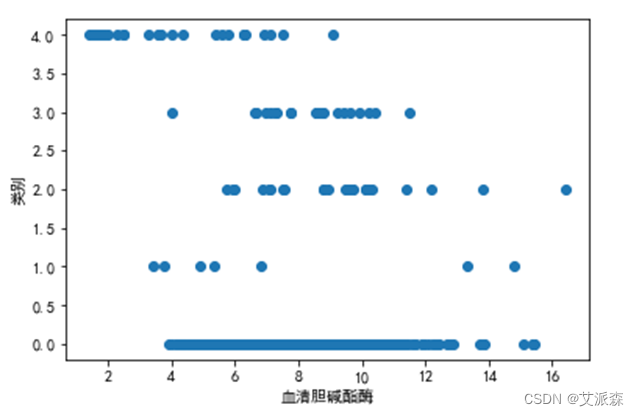
图 3.6 血清胆碱酯酶与类别的关系
可以看出,4类人体内血清胆碱酯酶明显低于其他几类。
同时,也可以通过如下代码查看各指标之间的相关性。

热力图绘制结果如图3.7所示。

图 3.7 各指标相关热力图
可以看到,相关性最强没有超过0.5,AST与GGT0.49,OHOL与OHE0.43, ALP与GGT0.45, ALB与OHE0.38,可推测不同指标之间相关性较小。
3.2.3标签统计图
采用如下代码对标签进行可视化操作,做出条形图,观察各标签即类别的数量特征。
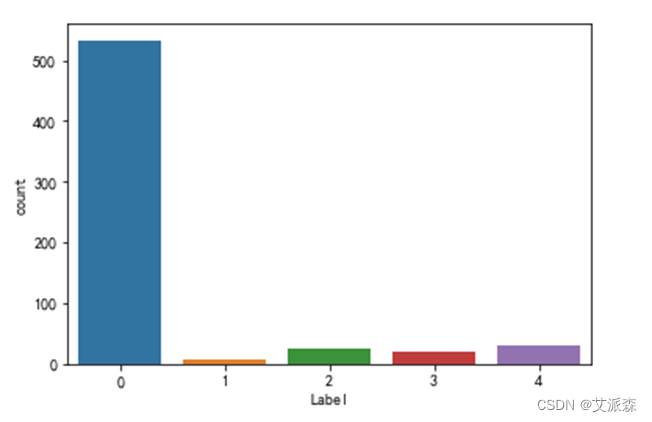
图 3.8 标签数量统计图
3.3模型选择
基于实验目的,选择LSTM模型对该案例进行分类。
3.3.1建模准备
在建模之前对数据进行热编码,get_dummies 是利用pandas实现one hot encode的方式。编码完成后所有的属性值将被展开,每个属性值成为新的属性,新属性只有0和1两个值。实现代码如下:

接下来,使用sklearn.model_ selection 中的train_test_ spli划分测试集和训练集,该实验记录共有615条,选取测试集比例为20%。

通常在这个过程中,数据也会被重排列,以消除数据集中由于顺序而产生的偏差。最后,将分割后的训练集与测试集分配给X_train,X_test,y_train和 y_test,查看运行结果如下图3.9:

图 3.9 运行结果
3.3.2模型的建立

上面代码建立了一个序列模型,采用的Lstm。相关参数作如下说明:
(1)关于return_sequences=True与False。model.add(LSTM(units=100, return_sequences=False))中就不需要执model.add(LSTM(units=100, return_sequences=False)),但是在我们执行model.add(LSTM(units=100, return_sequences=True))时后面是必须要接,model.add(LSTM(units=100, return_sequences=False))的,具体原因及扩展原因是:Kears LSTM API 中给出的两个参数描述:return_sequences:默认 False。在输出序列中,返回单个 hidden state值还是返回全部time step 的 hidden state值。 False 返回单个, true 返回全部。所以如果是model.add(LSTM(units=100, return_sequences=True)),后面就需要接model.add(LSTM(units=100, return_sequences=False))。
(2)Sigmoid函数是传统神经网络中最常用的激活函数,该函数实际上就是把数据映射到一个 (0,1)的空间上。
(3)关于model.compile:loss是目标函数,也叫损失函数,而categorical_crossentropy就是多分类的对数损失函数。是机器学习建模中所用到的目标函数中的一种;Accuracy(准确率)是机器学习中最简单的一种评价模型好坏的指标, Keras中accuracy在Keras.metrics中总共给出了6种,这里采用最简单的accuracy,即通过y-true和y-pred之比来确定模型准确率。
(4)使用keras构建深度学习模型,通过model.summary()输出模型各层的参数状况,如下图3.10所示:
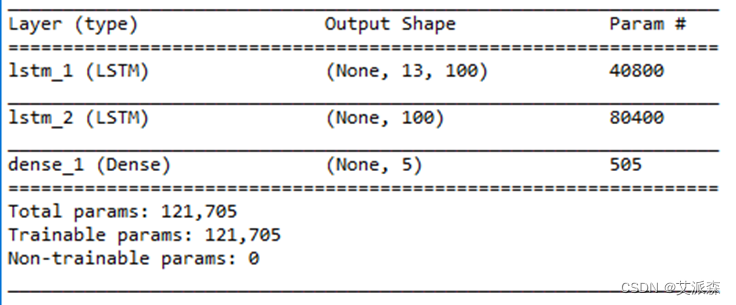
图 3.10 模型信息
3.3.3训练模型
模型训练的方式有三种:内置fit方法,内置train_on_batch方法,自定义训练循环。fit方法功能非常强大, 支持对numpy array, tf.data.Dataset以及 Python generator数据进行训练。并且可以通过设置回调函数实现对训练过程的复杂控制逻辑。内置train_on_batch方法相比较fit方法更加灵活,可以不通过回调函数而直接在批次层次上更加精细地控制训练的过程。自定义训练循环无需编译模型,直接利用优化器根据损失函数反向传播迭代参数,拥有最高的灵活性。下面的代码实现模型的训练。

相关参数说明:
(1) batch_size:整数 ,每次梯度更新的样本数。默认为32,此处指定为64。
(2) validation_split:浮点数0-1之间,用作验证集的训练数据的比例。模型将分出一部分不会被训练的验证数据,并将在每一轮结束时评估这些验证数据的误差和任何其他模型指标。验证数据是混洗之前x,y数据的最后一部分。
(3)epochs:整数,训练模型迭代次数。
(4)shuffle:布尔值。是否在每轮迭代之前混洗数据
(5)verbose:日志展示,整数
0 :为不在标准输出流输出日志信息
1 :显示进度条
2 :每个epoch输出一行记录
最后,绘制训练和验证损失函数图,以及准确率变化趋势图,如图3.11,图3.12所示。

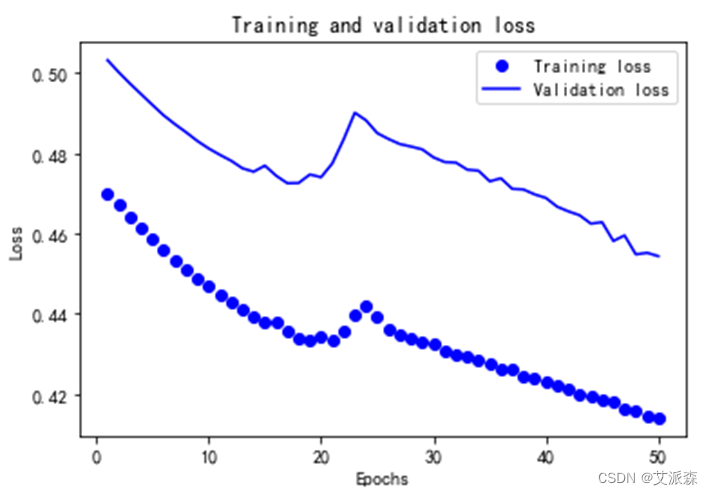
图 3.11 损失函数图
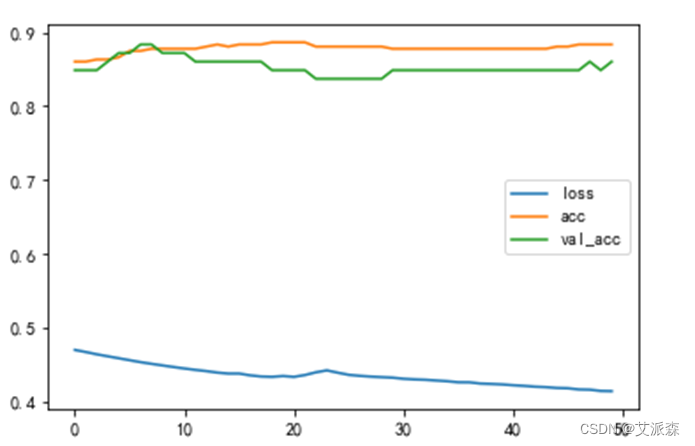
图 3.12 准确率和损失图
通过50次的迭代,可以看出,训练损失和验证损失同步减小,但中间有一定范围的波动,准确率在前20次迭代中有所上升,但后面的迭代中又有下降的波动最后稳定下来。
3.4模型评估
如下代码查看模型预测结果,如图3.13


图 3.13 预测结果
查看各类测试数量:


图 3.14 测试数量
查看模型准确率等参数:

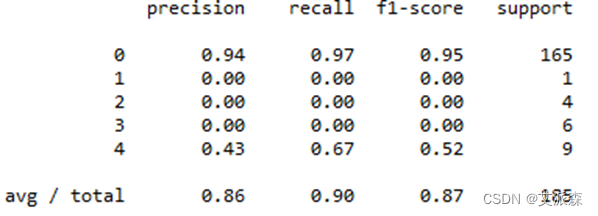
图 3.15 模型准确率
Precision为0.86,recall为0.9,f1-score为0.87。
4.实验总结
从实验结果可以看出,精确率为0.86,且经过多次参数调整,精确率仍变动不大,这样的精确率还有提高的空间;召回率为0.9;F1分数(F1 Score),是统计学中用来衡量二分类模型精确度的一种指标。它同时兼顾了分类模型的精确率和召回率。其结果为0.87。该实验说明,LSTM可以实现多分类,但难以保证准确率,可以对模型进行探索和提高,也可以考虑采取其他的更加精确地算法进行该案例的多分类。
源代码
from __future__ import division, print_function
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import random
from sklearn.metrics import roc_curve, auc ###计算roc和auc
from sklearn.model_selection import train_test_split
from keras.models import Sequential
from keras import optimizers
from keras.optimizers import RMSprop
from keras.layers import LSTM, Activation, Dense, Dropout, Input, Embedding, SpatialDropout1D,Flatten
from sklearn.metrics import precision_score, recall_score, f1_score
from sklearn.preprocessing import MinMaxScaler,StandardScaler
import matplotlib.pyplot as plt
from keras.utils.np_utils import to_categorical
# 导入数据集
data = pd.read_csv('hcv.csv')
#查看数据集信息:
data.info()
#查看数据集的头 5 条记录:
data.head()
#先查看数据集各特征列的摘要统计信息:
data.describe()
#各特征与标签的散点分布图
ALB = data['ALB']
ALP = data['ALP']
ALT = data['ALT']
AST = data['AST']
BIL = data['BIL']
CHE = data['CHE']
CHOL = data['CHOL']
CREA = data['CREA']
GGT = data['GGT']
PROT = data['PROT']
Category = data['Category']
data.Category[data.Category=='0=Blood Donor']=0
data.Category[data.Category=='0s=suspect Blood Donor']=1
data.Category[data.Category=='1=Hepatitis']=2
data.Category[data.Category=='2=Fibrosis']=3
data.Category[data.Category=='3=Cirrhosis']=4
def draw(x,y):
plt.plot(x,y,'o')
plt.xlabel('ALB')
plt.ylabel('Category')
plt.show()
plt.plot(ALB,Category,'o')
plt.xlabel('白蛋白')
plt.ylabel('类别')
plt.show()
plt.plot(ALP,Category,'o')
plt.xlabel('碱性磷酸酶')
plt.ylabel('类别')
plt.show()
plt.plot(CHE,Category,'o')
plt.xlabel('血清胆碱酯酶')
plt.ylabel('类别')
plt.show()
#相关性
fig=plt.gcf()
fig.set_size_inches(12, 8)
fig=sns.heatmap(data.corr(), annot=True, cmap='GnBu', linewidths=1, linecolor='k', square=True, mask=False, vmin=-1, vmax=1, cbar_kws={"orientation": "vertical"}, cbar=True)
def loaddata2():
data['Category']=data['Category'].astype(int)
plt.figure()
plt.rcParams['font.sans-serif'] = ['SimHei'] #解决中文显示
plt.rcParams['axes.unicode_minus'] = False #解决符号无法显示
sns.countplot(data.Category)
plt.xlabel('Label',size = 10)
plt.xticks(size = 10)
plt.show()
#random.shuffle(data)
datay=pd.get_dummies(data['Category']).values
dataname=['Age','Sex','ALB','ALP','ALT','AST','BIL','CHE','CHOL','CREA','GGT','PROT']
datax=pd.get_dummies(data[dataname]).values
tempx= datax.reshape((datax.shape[0], datax.shape[1], 1))
tempy=datay
return(tempx,tempy)
tempx,tempy=loaddata2()
x_train,x_test,y_train,y_test = train_test_split (tempx, tempy ,test_size=0.20,random_state=10)
x_train.shape
y_train.shape
print(tempx.shape)
print(x_train.shape)
print(x_test.shape)
#模型训练
def create_model(input_length,output_length):
model = Sequential()
model.add(LSTM(units=100, activation='sigmoid', return_sequences=True, input_shape=(input_length, 1)))
#model.add(Dropout(0.2))
model.add(LSTM(units=100, activation='sigmoid', return_sequences=False))
#model.add(Dropout(0.2))
model.add(Dense(output_length, activation='softmax'))
#sgd = optimizers.SGD(lr=0.00001, decay=1e-6, momentum=0.001, nesterov=True)
sgd=RMSprop()
#标准的优化器 训练过程中监控精度
model.compile(loss="categorical_crossentropy",optimizer=sgd,metrics=["accuracy"])
return model
model = create_model(len(x_train[0]),y_train.shape[1])
model.summary()
hist = model.fit(x_train, y_train, batch_size=64, validation_split = 0.2, epochs=50, shuffle=False, verbose=1)
history_dict = hist.history
history_dict.keys()
loss_values = history_dict['loss']
val_loss_values = history_dict['val_loss']
epochs = range(1,len(loss_values)+1)
#绘制训练和验证损失函数图
plt.plot(epochs,loss_values,'bo',label='Training loss')
plt.plot(epochs,val_loss_values,'b',label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
plt.plot(hist.history['loss'], label='loss')
plt.plot(hist.history['acc'], label='acc')
plt.plot(hist.history['val_acc'], label='val_acc')
plt.legend()
plt.show()
#模型评价 输出测试集分类预测
y_pred = model.predict_classes(x_test, verbose=0)
print(y_pred)
#各类别测试集数量
y_test = np.array(y_test).argmax(axis=1)
y_test
from sklearn.metrics import confusion_matrix,classification_report
print(confusion_matrix(y_test ,y_pred))
#准确率
yn=y_train.shape[1]
listny=[]
for i in range(yn):
listny.append(str(i))
listny
print(classification_report(y_test ,y_pred, target_names=listny))
资料获取,更多粉丝福利,关注下方公众号获取











