
嘿马头条项目从到完整开发笔记总结完整教程(附代码资料)主要内容讲述:课程简介,ToutiaoWeb虚拟机使用说明1 产品介绍,2 原型图与UI图,3 技术架构,4 开发,1 需求,2 注意事项。数据库,理解ORM1 简介,2 安装,3 数据库连接设置,4 模型类字段与选项,5 构建模型类映射。数据库,SQLAlchemy操作1 新增,2 查询,3 更新,4 删除,5 事务,1. 复制集与分布式。数据库,分布式ID1 方案选择,2 头条,1 理解索引,2 SQL查询优化,3 数据库优化。数据库,Redis1 Redis事务,2 Redis持久化,3 Redis高可用,4 Redis集群,5 用途,6 相关补充阅读。Git工用流,调试方法。OSS对象存储,七牛云存储。缓存,缓存架构缓存数据的类型,缓存数据的保存方式,有效期 TTL (Time to live),缓存淘汰 eviction。缓存,缓存问题1 缓存穿透,2 缓存雪崩,缓存设计,持久存储设计。APScheduler定时任务,定时修正统计数据1. 什么是RPC,2. 背景与用途,3. 概念说明,4. 优缺点,架构,使用方法。RPC,编写客户端。即时通讯,Socket.IO1 简介,2 Python服务器端开发,3 Python客户端。Elasticsearch,简介与原理概念,Elasticsearch 集群(cluster),索引,类型和映射。Elasticsearch,文档。单元测试,部署相关数据库性能,缓存雪崩,缓存编写。缓存模式缓存的架构,缓存数据,缓存数据的有效期和淘汰策略,淘汰策略,头条项目缓存数据的设计。
全套笔记资料代码移步: 前往gitee仓库查看
感兴趣的小伙伴可以自取哦,欢迎大家点赞转发~
全套教程部分目录:


部分文件图片:
数据库
-
数据库设计
-
SQLAlchemy
-
数据库理论
-
分布式ID
-
Redis
SQLAlchemy操作
1 新增
user = User(mobile='15612345678', name='itcast')
db.session.add(user)
db.session.commit()
profile = Profile(id=user.id)
db.session.add(profile)
db.session.commit()
对于批量添加也可使用如下语法
db.session.add_all([user1, user2, user3])
db.session.commit()
2 查询
all()
查询所有,返回列表
User.query.all()
first()
查询第一个,返回对象
User.query.first()
get()
根据主键ID获取对象,若主键不存在返回None
User.query.get(2)
另一种查询方式
db.session.query(User).all()
db.session.query(User).first()
db.session.query(User).get(2)
filter_by
进行过虑
User.query.filter_by(mobile='13911111111').first()
User.query.filter_by(mobile='13911111111', id=1).first() # and关系
filter
进行过虑
User.query.filter(User.mobile=='13911111111').first()
逻辑或
from sqlalchemy import or_
User.query.filter(or_(User.mobile=='13911111111', User.name.endswith('号'))).all()
逻辑与
from sqlalchemy import and_
User.query.filter(and_(User.name != '13911111111', User.mobile.startswith('185'))).all()
逻辑非
from sqlalchemy import not_
User.query.filter(not_(User.mobile == '13911111111')).all()
offset
偏移,起始位置
User.query.offset(2).all()
limit
获取限制数据
User.query.limit(3).all()
order_by
排序
User.query.order_by(User.id).all() # 正序
User.query.order_by(User.id.desc()).all() # 倒序
复合查询
User.query.filter(User.name.startswith('13')).order_by(User.id.desc()).offset(2).limit(5).all()
query = User.query.filter(User.name.startswith('13'))
query = query.order_by(User.id.desc())
query = query.offset(2).limit(5)
ret = query.all()
优化查询
user = User.query.filter_by(id=1).first() # 查询所有字段
select user_id, mobile......
select * from # 程序不要使用
select user_id, mobile,.... # 查询指定字段
from sqlalchemy.orm import load_only
User.query.options(load_only(User.name, User.mobile)).filter_by(id=1).first() # 查询特定字段
聚合查询
from sqlalchemy import func
db.session.query(Relation.user_id, func.count(Relation.target_user_id)).filter(Relation.relation == Relation.RELATION.FOLLOW).group_by(Relation.user_id).all()
关联查询
1. 使用ForeignKey
class User(db.Model):
...
profile = db.relationship('UserProfile', uselist=False)
followings = db.relationship('Relation')
class UserProfile(db.Model):
id = db.Column('user_id', db.Integer, db.ForeignKey('user_basic.user_id'), primary_key=True, doc='用户ID')
...
class Relation(db.Model):
user_id = db.Column(db.Integer, db.ForeignKey('user_basic.user_id'), doc='用户ID')
...
# 测试
user = User.query.get(1)
user.profile.gender
user.followings
2. 使用primaryjoin
class User(db.Model):
...
profile = db.relationship('UserProfile', primaryjoin='User.id==foreign(UserProfile.id)', uselist=False)
followings = db.relationship('Relation', primaryjoin='User.id==foreign(Relation.user_id)')
# 测试
user = User.query.get(1)
user.profile.gender
user.followings
3. 指定字段关联查询
class Relation(db.Model):
...
target_user = db.relationship('User', primaryjoin='Relation.target_user_id==foreign(User.id)', uselist=False)
from sqlalchemy.orm import load_only, contains_eager
Relation.query.join(Relation.target_user).options(load_only(Relation.target_user_id), contains_eager(Relation.target_user).load_only(User.name)).all()
3 更新
- 方式一
user = User.query.get(1)
user.name = 'Python'
db.session.add(user)
db.session.commit()
- 方式二
User.query.filter_by(id=1).update({'name':'python'})
db.session.commit()
4 删除
- 方式一
user = User.query.order_by(User.id.desc()).first()
db.session.delete(user)
db.session.commit()
- 方式二
User.query.filter(User.mobile='18512345678').delete()
db.session.commit()
5 事务
environ = {'wsgi.version':(1,0), 'wsgi.input': '', 'REQUEST_METHOD': 'GET', 'PATH_INFO': '/', 'SERVER_NAME': 'itcast server', 'wsgi.url_scheme': 'http', 'SERVER_PORT': '80'}
with app.request_context(environ):
try:
user = User(mobile='18911111111', name='itheima')
db.session.add(user)
db.session.flush() # 将db.session记录的sql传到数据库中执行
profile = UserProfile(id=user.id)
db.session.add(profile)
db.session.commit()
except:
db.session.rollback()
数据库
-
数据库设计
-
SQLAlchemy
-
数据库理论
-
分布式ID
-
Redis
数据库理论
1. 复制集与分布式
-
复制集(Replication)
-
数据库中数据相同,起到备份作用
-
高可用 High Available HA
-
分布式(Distribution)
-
数据库中数据不同,共同组成完整的数据集合
- 通常每个节点被称为一个分片(shard)
-
高吞吐 High Throughput
-
复制集与分布式可以单独使用,也可以组合使用(即每个分片都组建一个复制集)
-
关于主(Master)从(Slave)
-
这个概念是从使用的角度来阐述问题的
- 主节点 -> 表示程序在这个节点上最先更新数据
- 从节点 -> 表示这个节点的数据是要通过复制主节点而来
- 复制集 可选 主从、主主、主主从从
- 分布式 每个分片都是主,组合使用复制集的时候,复制集的是从
2. MySQL
1) 主从复制
复制分成三步:
- master将改变记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary log events);
- slave将master的binary log events拷贝到它的中继日志(relay log);
- slave重做中继日志中的事件,将改变反映它自己的数据。
下图描述了这一过程:
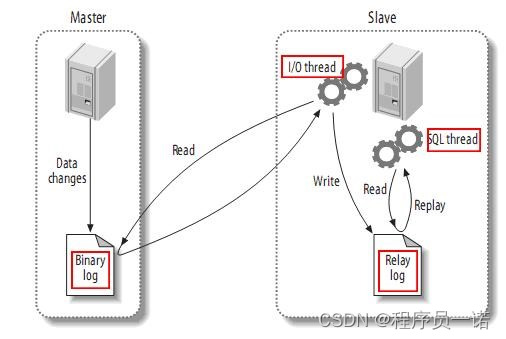
该过程的第一部分就是master记录二进制日志。在每个事务更新数据完成之前,master在二日志记录这些改变。MySQL将事务串行的写入二进制日志,即使事务中的语句都是交叉执行的。在事件写入二进制日志完成后,master通知存储引擎提交事务。
下一步就是slave将master的binary log拷贝到它自己的中继日志。首先,slave开始一个工作线程——I/O线程。I/O线程在master上打开一个普通的连接,然后开始binlog dump process。Binlog dump process从master的二进制日志中读取事件,如果已经跟上master,它会睡眠并等待master产生新的事件。I/O线程将这些事件写入中继日志。
SQL slave thread处理该过程的最后一步。SQL线程从中继日志读取事件,更新slave的数据,使其与master中的数据一致。只要该线程与I/O线程保持一致,中继日志通常会位于OS的缓存中,所以中继日志的开销很小。
此外,在master中也有一个工作线程:和其它MySQL的连接一样,slave在master中打开一个连接也会使得master开始一个线程。
利用主从在达到高可用的同时,也可以通过读写分离提供吞吐量。
思考:读写分离对事务是否有影响?
对于事务中同时包含读写操作,与事务隔离级别设置有关,如果事务隔离级别为read-uncommitted 或者 read-committed,读写分离没影响,如果隔离级别为repeatable-read、serializable,读写分离就有影响,因为在slave上会看到新数据,而正在事务中的master看不到新数据。
2)分库分表(sharding)
分库分表前的问题
任何问题都是太大或者太小的问题,我们这里面对的数据量太大的问题。
- 用户请求量太大
因为单服务器TPS,内存,IO都是有限的。 解决方法:分散请求到多个服务器上; 其实用户请求和执行一个sql查询是本质是一样的,都是请求一个资源,只是用户请求还会经过网关,路由,http服务器等。
- 单库太大
单个数据库处理能力有限;单库所在服务器上磁盘空间不足;单库上操作的IO瓶颈 解决方法:切分成更多更小的库
- 单表太大
CRUD都成问题;索引膨胀,查询超时 解决方法:切分成多个数据集更小的表。
分库分表的方式方法
一般就是垂直切分和水平切分,这是一种结果集描述的切分方式,是物理空间上的切分。 我们从面临的问题,开始解决,阐述: 首先是用户请求量太大,我们就堆机器搞定(这不是本文重点)。
然后是单个库太大,这时我们要看是因为表多而导致数据多,还是因为单张表里面的数据多。 如果是因为表多而数据多,使用垂直切分,根据业务切分成不同的库。
如果是因为单张表的数据量太大,这时要用水平切分,即把表的数据按某种规则切分成多张表,甚至多个库上的多张表。 分库分表的顺序应该是先垂直分,后水平分。 因为垂直分更简单,更符合我们处理现实世界问题的方式。
垂直拆分
- 垂直分表
也就是“大表拆小表”,基于列字段进行的。一般是表中的字段较多,将不常用的, 数据较大,长度较长(比如text类型字段)的拆分到“扩展表“。 一般是针对那种几百列的大表,也避免查询时,数据量太大造成的“跨页”问题。
- 垂直分库
垂直分库针对的是一个系统中的不同业务进行拆分,比如用户User一个库,商品Producet一个库,订单Order一个库。 切分后,要放在多个服务器上,而不是一个服务器上。为什么? 我们想象一下,一个购物网站对外提供服务,会有用户,商品,订单等的CRUD。没拆分之前, 全部都是落到单一的库上的,这会让数据库的单库处理能力成为瓶颈。按垂直分库后,如果还是放在一个数据库服务器上, 随着用户量增大,这会让单个数据库的处理能力成为瓶颈,还有单个服务器的磁盘空间,内存,tps等非常吃紧。 所以我们要拆分到多个服务器上,这样上面的问题都解决了,以后也不会面对单机资源问题。
数据库业务层面的拆分,和服务的“治理”,“降级”机制类似,也能对不同业务的数据分别的进行管理,维护,监控,扩展等。 数据库往往最容易成为应用系统的瓶颈,而数据库本身属于“有状态”的,相对于Web和应用服务器来讲,是比较难实现“横向扩展”的。 数据库的连接资源比较宝贵且单机处理能力也有限,在高并发场景下,垂直分库一定程度上能够突破IO、连接数及单机硬件资源的瓶颈。
水平拆分
- 水平分表
针对数据量巨大的单张表(比如订单表),按照某种规则(RANGE,HASH取模等),切分到多张表里面去。 但是这些表还是在同一个库中,所以库级别的数据库操作还是有IO瓶颈。不建议采用。
- 水平分库分表
将单张表的数据切分到多个服务器上去,每个服务器具有相应的库与表,只是表中数据集合不同。 水平分库分表能够有效的缓解单机和单库的性能瓶颈和压力,突破IO、连接数、硬件资源等的瓶颈。
-
水平分库分表切分规则
-
- RANGE
从0到10000一个表,10001到20000一个表;
- HASH取模 离散化
一个商场系统,一般都是将用户,订单作为主表,然后将和它们相关的作为附表,这样不会造成跨库事务之类的问题。 取用户id,然后hash取模,分配到不同的数据库上。
- 地理区域
比如按照华东,华南,华北这样来区分业务,七牛云应该就是如此。
- 时间
按照时间切分,就是将6个月前,甚至一年前的数据切出去放到另外的一张表,因为随着时间流逝,这些表的数据 被查询的概率变小,所以没必要和“热数据”放在一起,这个也是“冷热数据分离”。
分库分表后面临的问题
- 事务支持
分库分表后,就成了分布式事务了。如果依赖数据库本身的分布式事务管理功能去执行事务,将付出高昂的性能代价; 如果由应用程序去协助控制,形成程序逻辑上的事务,又会造成编程方面的负担。
-
多库结果集合并(group by,order by)
-
跨库join
分库分表后表之间的关联操作将受到限制,我们无法join位于不同分库的表,也无法join分表粒度不同的表, 结果原本一次查询能够完成的业务,可能需要多次查询才能完成。 粗略的解决方法: 全局表:基础数据,所有库都拷贝一份。 字段冗余:这样有些字段就不用join去查询了。 系统层组装:分别查询出所有,然后组装起来,较复杂。
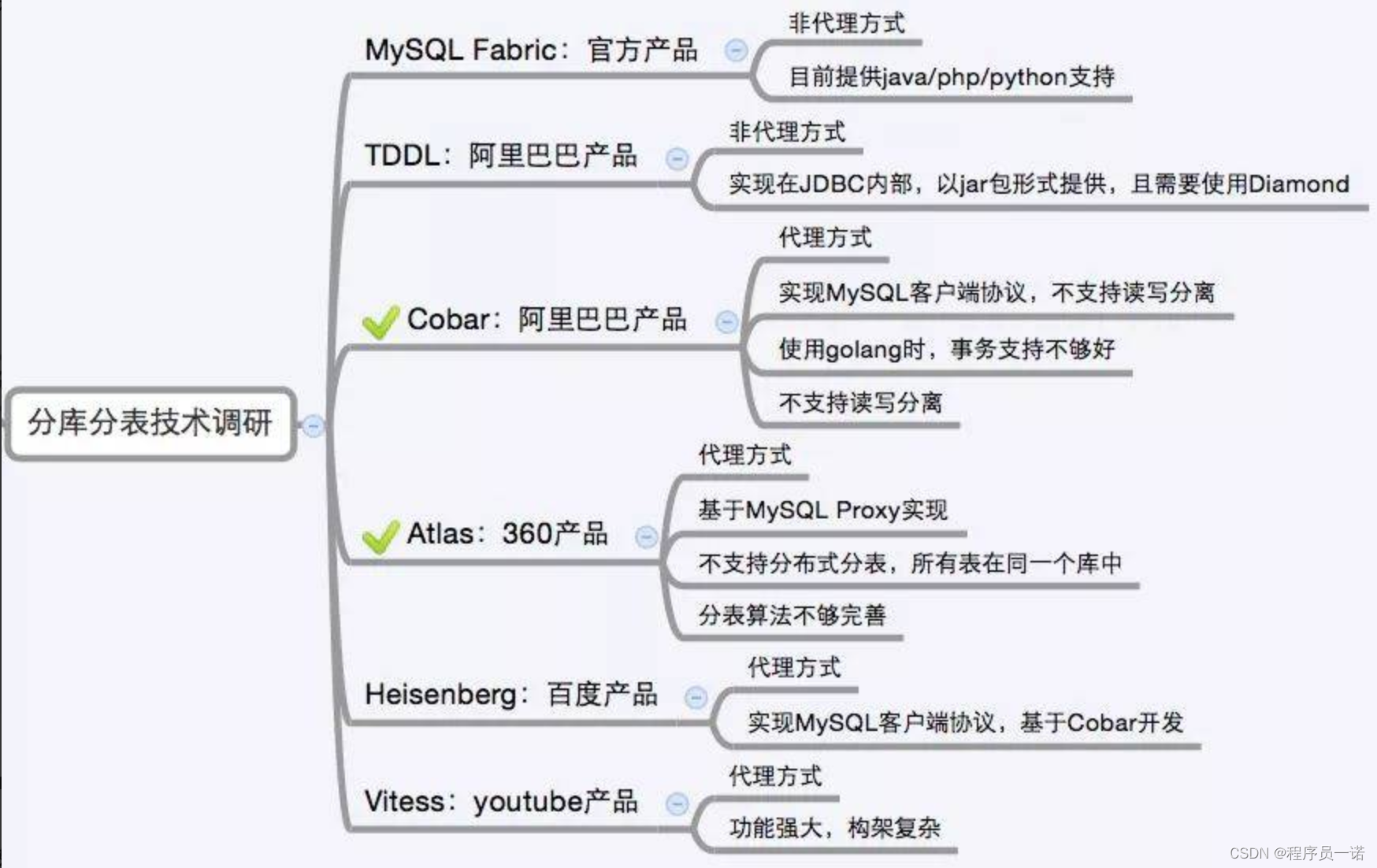
分库分表方案产品
目前市面上的分库分表中间件相对较多,其中基于方式的有MySQL Proxy和Amoeba, 基于Hibernate框架的是Hibernate Shards,基于jdbc的有当当sharding-jdbc, 基于mybatis的类似maven插件式的有蘑菇街的蘑菇街TSharding, 通过重写spring的ibatis template类的Cobar Client。
还有一些大公司的开源产品:
3 头条项目应用
-
主从
-
垂直分表
CREATE TABLE `user_basic` (
`user_id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '用户ID',
`account` varchar(20) COMMENT '账号',
`email` varchar(20) COMMENT '邮箱',
`status` tinyint(1) NOT NULL DEFAULT '1' COMMENT '状态,是否可用,0-不可用,1-可用',
`mobile` char(11) NOT NULL COMMENT '手机号',
`password` varchar(93) NULL COMMENT '密码',
`user_name` varchar(32) NOT NULL COMMENT '昵称',
`profile_photo` varchar(128) NULL COMMENT '头像',
`last_login` datetime NULL COMMENT '最后登录时间',
`is_media` tinyint(1) NOT NULL DEFAULT '0' COMMENT '是否是自媒体,0-不是,1-是',
`is_verified` tinyint(1) NOT NULL DEFAULT '0' COMMENT '是否实名认证,0-不是,1-是',
`introduction` varchar(50) NULL COMMENT '简介',
`certificate` varchar(30) NULL COMMENT '认证',
`article_count` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '发文章数',
`following_count` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '关注的人数',
`fans_count` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '被关注的人数',
`like_count` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '累计点赞人数',
`read_count` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '累计阅读人数',
PRIMARY KEY (`user_id`),
UNIQUE KEY `mobile` (`mobile`),
UNIQUE KEY `user_name` (`user_name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用户基本信息表';
CREATE TABLE `user_profile` (
`user_id` bigint(20) unsigned NOT NULL COMMENT '用户ID',
`gender` tinyint(1) NOT NULL DEFAULT '0' COMMENT '性别,0-男,1-女',
`birthday` date NULL COMMENT '生日',
`real_name` varchar(32) NULL COMMENT '真实姓名',
`id_number` varchar(20) NULL COMMENT '身份证号',
`id_card_front` varchar(128) NULL COMMENT '身份证正面',
`id_card_back` varchar(128) NULL COMMENT '身份证背面',
`id_card_handheld` varchar(128) NULL COMMENT '手持身份证',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`register_media_time` datetime NULL COMMENT '注册自媒体时间',
`area` varchar(20) COMMENT '地区',
`company` varchar(20) COMMENT '公司',
`career` varchar(20) COMMENT '职业',
PRIMARY KEY (`user_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用户资料表';
CREATE TABLE `news_article_basic` (
`article_id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '文章ID',
`user_id` bigint(20) unsigned NOT NULL COMMENT '用户ID',
`channel_id` int(11) unsigned NOT NULL COMMENT '频道ID',
`title` varchar(128) NOT NULL COMMENT '标题',
`cover` json NOT NULL COMMENT '封面',
`is_advertising` tinyint(1) NOT NULL DEFAULT '0' COMMENT '是否投放广告,0-不投放,1-投放',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`status` tinyint(1) NOT NULL DEFAULT '0' COMMENT '贴文状态,0-草稿,1-待审核,2-审核通过,3-审核失败,4-已删除',
`reviewer_id` int(11) NULL COMMENT '审核人员ID',
`review_time` datetime NULL COMMENT '审核时间',
`delete_time` datetime NULL COMMENT '删除时间',
`reject_reason` varchar(200) COMMENT '驳回原因',
`comment_count` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '累计评论数',
`allow_comment` tinyint(1) NOT NULL DEFAULT '1' COMMENT '是否允许评论,0-不允许,1-允许',
PRIMARY KEY (`article_id`),
KEY `user_id` (`user_id`),
KEY `article_status` (`status`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='文章基本信息表';
CREATE TABLE `news_article_content` (
`article_id` bigint(20) unsigned NOT NULL COMMENT '文章ID',
`content` longtext NOT NULL COMMENT '文章内容',
PRIMARY KEY (`article_id`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8 COMMENT='文章内容表';








