clickhouse 新特性:
从clickhouse 22.3至最新的版本24.3.2.23,clickhouse在快速发展中,每个版本都增加了一些新的特性,在数据写入、查询方面都有性能加速。
本文根据clickhouse blog中的clickhouse release blog中,学习并梳理了一些在实际工作中可能用到的新特性。
以下是如何基于docker,如果试用这些新性
docker run -d --name=ch -p 8123:8123 -p 9000:9000 -p 9009:9009 --ulimit nofile=262144:262144 -v D:/ch/latest/external:/external:rw -v chlatest:/var/lib/clickhouse:rw -v D:/ch/latest/logs:/var/log/clickhouse-server:rw -v D:/ch/latest/etc/clickhouse-server:/etc/clickhouse-server:rw clickhouse/clickhouse-server:24.3.2.23
docker exec -it bash
clickhouse-client --format_csv_delimiter=','
transform函数
进行字典替换
transform(x, array_from, array_to, default)
transform(T, Array(T), Array(U), U) -> U
transform(x, array_from, array_to)
UK-house-price-dataset.csv
CREATE TABLE uk_price_paid
(
price UInt32,
date Date,
postcode1 LowCardinality(String),
postcode2 LowCardinality(String),
type Enum8('terraced' = 1, 'semi-detached' = 2, 'detached' = 3, 'flat' = 4, 'other' = 0),
is_new UInt8,
duration Enum8('freehold' = 1, 'leasehold' = 2, 'unknown' = 0),
addr1 String,
addr2 String,
street LowCardinality(String),
locality LowCardinality(String),
town LowCardinality(String),
district LowCardinality(String),
county LowCardinality(String)
)
ENGINE = MergeTree
ORDER BY (postcode1, postcode2, addr1, addr2);
INSERT INTO uk_price_paid
WITH
splitByChar(' ', postcode) AS p
SELECT
toUInt32(price_string) AS price,
parseDateTimeBestEffortUS(time) AS date,
p[1] AS postcode1,
p[2] AS postcode2,
transform(a, ['T', 'S', 'D', 'F', 'O'], ['terraced', 'semi-detached', 'detached', 'flat', 'other']) AS type,
b = 'Y' AS is_new,
transform(c, ['F', 'L', 'U'], ['freehold', 'leasehold', 'unknown']) AS duration, addr1, addr2, street, locality, town, district, county
FROM file('UK-house-price-dataset.csv','CSV','uuid_string String, price_string String, time String, postcode String, a String, b String, c String, addr1 String, addr2 String, street String, locality String, town String, district String, county String, d String, e String'
);
SELECT transform(number, [0, 1, 2, 3, 4, 5, 6, 7, 8, 9], ['zero', 'one', 'two', 'three', 'four', 'five', 'six', 'seven', 'eight', 'nine'], NULL) AS numbers
FROM system.numbers
LIMIT 10
读取文件
可以自动识别文件的类型,推荐字段类型
SELECT * FROM (
WITH
splitByChar(' ', postcode) AS p
SELECT
toUInt32(price_string) AS price,
parseDateTimeBestEffortUS(time) AS date,
p[1] AS postcode1,
p[2] AS postcode2,
transform(a, ['T', 'S', 'D', 'F', 'O'], ['terraced', 'semi-detached', 'detached', 'flat', 'other']) AS type,
b = 'Y' AS is_new,
transform(c, ['F', 'L', 'U'], ['freehold', 'leasehold', 'unknown']) AS duration, addr1, addr2, street, locality, town, district, county
FROM file('UK-house-price-dataset.csv','CSV','uuid_string String, price_string String, time String, postcode String, a String, b String, c String, addr1 String, addr2 String, street String, locality String, town String, district String, county String, d String, e String'
) SETTINGS format_csv_delimiter=','
) LIMIT 2;
自定义函数
根据需要,编写自定义函数
CREATE OR REPLACE TABLE line_changes
(
version UInt32,
line_change_type Enum('Add' = 1, 'Delete' = 2, 'Modify' = 3),
line_number UInt32,
line_content String,
time datetime default now()
)
ENGINE = MergeTree
ORDER BY time;
INSERT INTO default.line_changes (version,line_change_type,line_number,line_content) VALUES
(1, 'Add' , 1, 'ClickHouse provides SQL'),
(2, 'Add' , 2, 'with improvements'),
(3, 'Add' , 3, 'that makes it more friendly for analytical tasks.'),
(4, 'Add' , 2, 'with many extensions'),
(5, 'Modify', 3, 'and powerful improvements'),
(6, 'Delete', 1, ''),
(7, 'Add' , 1, 'ClickHouse provides a superset of SQL');
-- add a string (str) into an array (arr) at a specific position (pos)
CREATE OR REPLACE FUNCTION add AS (arr, pos, str) ->
arrayConcat(arraySlice(arr, 1, pos-1), [str], arraySlice(arr, pos));
-- delete the element at a specific position (pos) from an array (arr)
CREATE OR REPLACE FUNCTION delete AS (arr, pos) ->
arrayConcat(arraySlice(arr, 1, pos-1), arraySlice(arr, pos+1));
-- replace the element at a specific position (pos) in an array (arr)
CREATE OR REPLACE FUNCTION modify AS (arr, pos, str) ->
arrayConcat(arraySlice(arr, 1, pos-1), [str], arraySlice(arr, pos+1));
arrayFold
SELECT arrayFold((acc, v) -> (acc + v), [10, 20, 30], 0::UInt64) AS sum;
CREATE OR REPLACE VIEW text_version AS
WITH T1 AS (
SELECT arrayZip(
groupArray(line_change_type),
groupArray(line_number),
groupArray(line_content)) as line_ops
FROM (SELECT * FROM line_changes
WHERE version <= {version:UInt32} ORDER BY version ASC)
)
SELECT arrayJoin(
arrayFold((acc, v) ->
if(v.'change_type' = 'Add', add(acc, v.'line_nr', v.'content'),
if(v.'change_type' = 'Delete', delete(acc, v.'line_nr'),
if(v.'change_type' = 'Modify', modify(acc, v.'line_nr', v.'content'), []))),
line_ops::Array(Tuple(change_type String, line_nr UInt32, content String)),
[]::Array(String))) as lines
FROM T1;
SELECT * FROM text_version(version = 3);
Parallel window functions
窗口函数采用并行计算,性能大幅提升
SELECT
country,
day,
max(tempAvg) AS temperature,
avg(temperature) OVER (PARTITION BY country ORDER BY day ASC ROWS BETWEEN 5 PRECEDING AND CURRENT ROW) AS moving_avg_temp
FROM noaa
WHERE country != ''
GROUP BY
country,
date AS day
ORDER BY
country ASC,
day ASC
FINAL
基于FINAL及enable_vertical_final,在如下引擎
ReplacingMergeTree、 AggregatingMergeTree引擎中,可以快速查询到最新的数据
SELECT
postcode1,
formatReadableQuantity(avg(price))
FROM uk_property_offers FINAL
GROUP BY postcode1
ORDER BY avg(price) DESC
LIMIT 3;
SELECT
postcode1,
formatReadableQuantity(avg(price))
FROM uk_property_offers
GROUP BY postcode1
ORDER BY avg(price) DESC
LIMIT 3
SETTINGS enable_vertical_final = 1;
Variant Type
SET allow_experimental_variant_type=1,
use_variant_as_common_type = 1;
SELECT
map('Hello', 1, 'World', 'Mark') AS x,
toTypeName(x) AS type
FORMAT Vertical;
SELECT
arrayJoin([1, true, 3.4, 'Mark']) AS value,
toTypeName(value)
Row 1:
──────
x: {'Hello':1,'World':'Mark'}
type: Map(String, Variant(String, UInt8))
┌─value─┬─toTypeName(value)─────────────────────┐
1. │ true │ Variant(Bool, Float64, String, UInt8) │
2. │ true │ Variant(Bool, Float64, String, UInt8) │
3. │ 3.4 │ Variant(Bool, Float64, String, UInt8) │
4. │ Mark │ Variant(Bool, Float64, String, UInt8) │
└───────┴───────────────────────────────────────┘
字符相似性函数
-
byteHammingDistance: the Hamming distance between two strings or vectors of equal length is the number of positions at which the corresponding symbols are different. In other words, it measures the minimum number of substitutions required to change one string into the other, or equivalently, the minimum number of errors that could have transformed one string into the other. In a more general context, the Hamming distance is one of several string metrics for measuring the edit distance between two sequences. It is named after the American mathematician Richard Hamming.
- “karolin” and “kathrin” is 3.
- “karolin” and “kerstin” is 3.
- “kathrin” and “kerstin” is 4.
- 0000 and 1111 is 4.
- 2173896 and 2233796 is 3.
-
editDistance:a way of quantifying how dissimilar two strings (e.g., words) are to one another, that is measured by counting the minimum number of operations required to transform one string into the other.
-
damerauLevenshteinDistance: a string metric for measuring the edit distance between two sequences. Informally, the Damerau–Levenshtein distance between two words is the minimum number of operations (consisting of insertions, deletions or substitutions of a single character, or transposition of two adjacent characters) required to change one word into the other.
-
jaroWinklerSimilarity: a string metric measuring an edit distance between two sequences. It is a variant of the Jaro distance metric
-
levenshteinDistance: a string metric for measuring the edit distance between two sequences. Informally, the Damerau–Levenshtein distance between two words is the minimum number of operations (consisting of insertions, deletions or substitutions of a single character, or transposition of two adjacent characters) required to change one word into the other.
https://clickhouse.com/docs/en/sql-reference/functions/string-functions#dameraulevenshteindistance
CREATE TABLE domains
(
`domain` String,
`rank` Float64
)
ENGINE = MergeTree
ORDER BY domain;
INSERT INTO domains SELECT
c2 AS domain,
1 / c1 AS rank
FROM url('domains.csv', 'CSV');
SELECT
domain,
levenshteinDistance(domain, 'facebook.com') AS d1,
damerauLevenshteinDistance(domain, 'facebook.com') AS d2,
jaroSimilarity(domain, 'facebook.com') AS d3,
jaroWinklerSimilarity(domain, 'facebook.com') AS d4
FROM domains
ORDER BY d1 ASC
LIMIT 10
Query id: 6f499f27-8274-4787-819a-b510322bdce3
┌─domain────────┬─d1─┬─d2─┬─────────────────d3─┬─────────────────d4─┐
1. │ facebook.com │ 0 │ 0 │ 1 │ 1 │
2. │ facebonk.com │ 1 │ 1 │ 0.8838383838383838 │ 0.9303030303030303 │
3. │ fabebook.com │ 1 │ 1 │ 0.914141414141414 │ 0.9313131313131312 │
4. │ facabook.com │ 1 │ 1 │ 0.9444444444444443 │ 0.961111111111111 │
5. │ facobook.com │ 1 │ 1 │ 0.8535353535353535 │ 0.8974747474747474 │
6. │ facebook1.com │ 1 │ 1 │ 0.9743589743589745 │ 0.9846153846153847 │
7. │ faceook.com │ 1 │ 1 │ 0.9722222222222221 │ 0.9833333333333333 │
8. │ faacebook.com │ 1 │ 1 │ 0.9743589743589745 │ 0.9794871794871796 │
9. │ faceboock.com │ 1 │ 1 │ 0.9326923076923077 │ 0.9596153846153846 │
10. │ facebool.com │ 1 │ 1 │ 0.9444444444444443 │ 0.9666666666666666 │
└───────────────┴────┴────┴────────────────────┴────────────────────┘
Vectorized distance functions
可以作为向量数据库使用,支持L2,cosineDistance,IP三种向量相似度的度量方法
https://clickhouse.com/blog/clickhouse-release-24-02
WITH 'dog' AS search_term,
(
SELECT vector
FROM glove
WHERE word = search_term
LIMIT 1
) AS target_vector
SELECT word, cosineDistance(vector, target_vector) AS score
FROM glove
WHERE lower(word) != lower(search_term)
ORDER BY score ASC
LIMIT 5;
WITH
'dog' AS search_term,
(
SELECT vector
FROM glove
WHERE word = search_term
LIMIT 1
) AS target_vector
SELECT
word,
1 - dotProduct(vector, target_vector) AS score
FROM glove
WHERE lower(word) != lower(search_term)
ORDER BY score ASC
LIMIT 5;
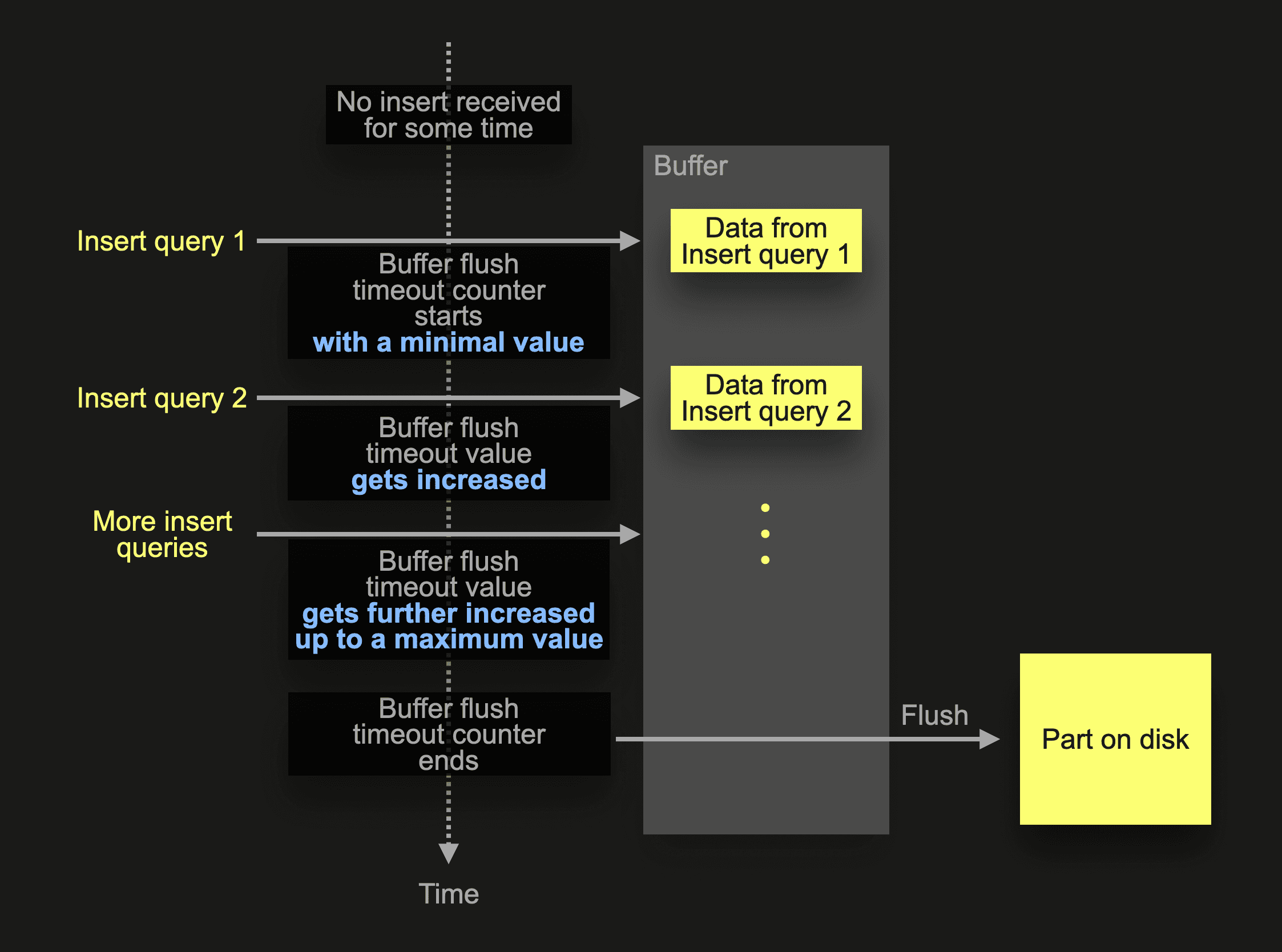
Adaptive asynchronous inserts
Asynchronous inserts shift data batching from the client side to the server side: data from insert queries is inserted into a buffer first and then written to the database storage later or asynchronously respectively.