文章目录
一、词与分词
1、词 vs 词素
- 词是语言中能够独立运用的最小单位,是指词在语法结构中的地位和作用而言的。
- 从语言的词本身来讲,很多词可以进一步分析成若干个最小的音义统一体,即词素。
- 词素是构成词的要素。词素是比词低一级的单位。
- 参考黄伯荣和廖旭东老师的《现代汉语(上)》(P251)中介绍的“替代法”。简单来说,能被替换的是词,不能被替换的是词素。比如说“茶杯”这个词,“茶杯”中的“茶”可以替换成“水”,“杯”又可以替换成“叶”,所以“茶杯”是一个词,有两个词素。但是“彷徨”这个词中,“彷”和“徨”都不能被替换,所以“彷徨”是一个词素,不过同时也是一个词。“茶杯”和“彷徨”都有两个字,也都是一个词。但是,“茶杯”是一个由两个语素组成的词,而“彷徨”既是一个由一个语素组成的词。。。

2、世界语言分类
-
孤立语:又称“词根语”、“无形态语”,以汉语为代表
- 词内没有专门表示语法意义的附加成分,形态变化很少,语法关系靠词序和虚词来表示
- 例如:“我吃饭”中的“我”、“吃”、“饭”都是独立的词,词序和上下文决定了它们之间的语法关系。
-
黏着语:又称“胶着语”,以日语为代表
- 词内有专门表示语法意义的附加成分,一个附加成分表达一种语法意义,词根或词干跟附加成分结合不紧密
-
曲折语:以英语为代表
- 用词的形态变化表示语法关系,词根或词干跟词的附加成分结合的很紧密,一个附加成分表达多种语法意义
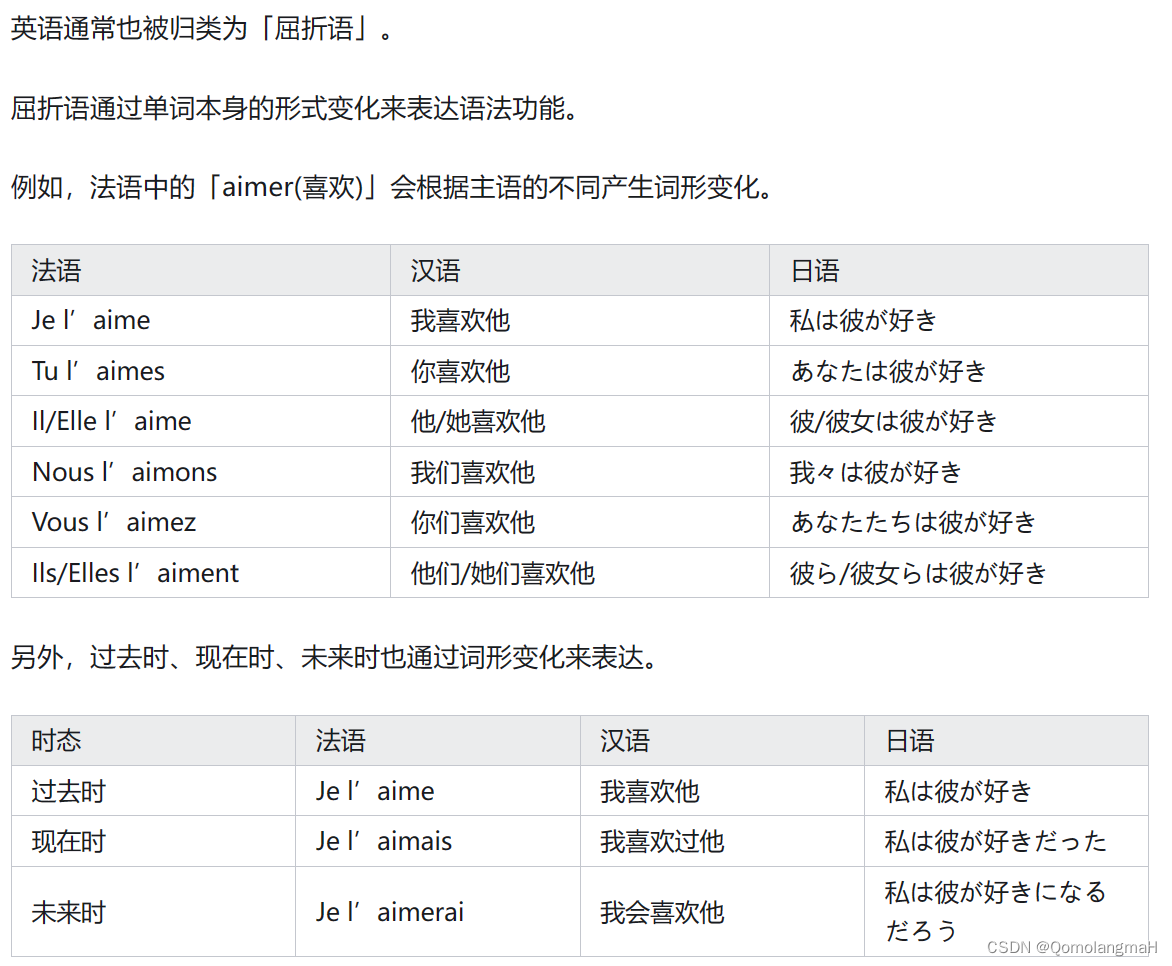
- 用词的形态变化表示语法关系,词根或词干跟词的附加成分结合的很紧密,一个附加成分表达多种语法意义
-
孤立语和黏着语存在分词问题
- 在孤立语言和黏着语言中,由于词本身没有太多的形态变化,因此分词相对较简单。在汉语中,词语之间一般使用空格或标点符号进行分隔,每个词都具有独立的语义和语法功能。
二、分词的原因与基本原因
1、为什么要分词
- 汉语的机器自动分词是汉语信息处理系统的重要组成部分
- 正确的机器自动分词是正确的中文信息处理的基础
- 文本检索
- 和服 | 务 | 于三日后裁制完毕,并呈送将军府中。
- 王府饭店的设施 | 和 | 服务 | 是一流的。
如果不分词或者“和服务”分词有误,都会导致荒谬的检索结果。
- 文语转换
- 他们是来 | 查 | 金泰 | 撞人那件事的。(“查”读音为cha)
- 行侠仗义的 | 查金泰 | 远近闻名。(“查”读音为zha)
- 文本检索
2、分词规范
- 中国国家标准GB13715 刘源等《信息处理用现代汉语分词规范及自动分词方法》
- 分词规范内容实录
- 二字或三字词,以及结合紧密、使用稳定的
- 发展 可爱 红旗
- 对不起 自行车 青霉素
- 四字成语一律为分词单位,以及四字词或结合紧密、使用稳定的四字词组
- 胸有成竹 欣欣向荣
- 社会主义 春夏秋冬 由此可见
- 五字和五字以上的谚语、格言等,分开后如不违背原有组合的意义,应予切分
- 时间/就/是/生命/
- 失败/是/成功/之/母
- 二字或三字词,以及结合紧密、使用稳定的
3、分词的主要难点-切分歧义
如何排除切分歧义
利用词法信息
- 湖上有几只美丽的白/天鹅
- 加入规则:“如果交段与其后继字串组成名词,则将该歧义词首字单切,否则,确认该歧义词为词”。
利用句法信息
- 利用歧义字串与前趋字串和后继字串的搭配关系等句
法信息确定正确切分 - 例:一阵/风/吹/过来/了
- 加入规则:“如果歧义字段是量词且直接前趋字串是数词,那么歧义字段的首段单切,否则,该歧义字段成词”
利用语义信息
- 例:学生会兴奋得手舞足蹈
- 学生/会/兴奋/得/手舞足蹈
- 学生会/兴奋/得/手舞足蹈
- 加入规则:“如果歧义切分字段后继动词的义项中含有动作发出者为“人”这个义素,则歧义字段的尾字单切,否则该歧义字段成词”
利用语用、语境信息
- 日本保留和尚使用的古代庙宇已经不多了
- 乒乓球拍卖完了
4、分词的主要难点-未登录词
未登录词
- 就是在词典中没有登录过的人名(中国人名和外国人译名)、地名、机构名、新词语、缩略语等。当采用匹配的方法来切词时,由于词典中没有登录这些词,会引起自动切词的困难。
- 歧义切分字段在汉语书面文本中所占的比例并不很大,在实际的书面文本中,特别是在新闻类文本中,未登录词的处理是书面文本自动切分的一个十分突出的问题。这是汉语书面语自动切分的另一个难点。
如何识别未登录词
- 汉语自然语言处理的经典难题之一
- 人们探索了多种方法,如互信息、期望方差法、语言模型法等等
- 基于最大熵、马尔科夫模型等统计分类模型是比较常用的方法
三、分词的一般方法
1、基于词典的方法(又称机械分词方法)
本质上是字符串匹配的方法,将一串文本中的文字片段和已有的词典进行匹配,如果匹配到,则此文字片段就作为一个分词结果。
1)正向最大匹配法(从左到右的方向);
2)逆向最大匹配法(从右到左的方向);
3)最小切分(每一句中切出的词数最小)
4)双向最大匹配(进行从左到右、从右到左两次扫描
- 优点是速度快,时间复杂度可以保持在O(n),实现简单,效果尚可;
- 但对歧义和未登录词处理效果不佳
- 基本就是不处理~
1. 正向最大匹配算法
- 基于词典词汇切分中最大正向匹配是基于“每次从句子中切分出尽量长的词语”的原理。即一个词的长度越长,从这个词中所获取的信息就有可能更多,同时也更确切。
- 比如“王小花”,这是一个人名,假设其存在于词典中,而“王”、“小”、“花”三个也均为词典中存在的单字词,倘若我们将“王小花”分为“王/小/花”,这将让人不知所云,而使用最长匹配的方法将会匹配出“王小花”这个三字词。
ch_dict = ['基于', '解析', '语义解析', '方法', '逻辑', '逻辑形式', '产生','更可', '解释', '可解释', '推理过程']
sentence = '基于语义解析的方法由于逻辑形式而产生了更可解释的推理过程'
segment_list = [] # 存放分词后的分词词组
# print(sentence)
# 例句不为空时,循环地进行分词操作
while len(sentence) >= 1:
# 最大匹配单词的长度为5,当然实际意义从3开始即可,因为词典最大单词长度为3
max_match_len = 5
# 当匹配单词长度大于1时,循环判断分词
while max_match_len > 1:
# 判断前 max_match_len 个字符是否存在于字典
if sentence[0:max_match_len] in ch_dict:
segment_list.append(sentence[0:max_match_len]) # 追加到分词词组中
sentence = sentence[max_match_len:len(sentence)] # 将符合的词语从原例句中截取
# 退出循环,重新从max_match_len最长匹配数开始匹配截取
break
max_match_len -= 1 # max_match_len累减,开始匹配4个字符,3个字符,,,
# 只剩下一个汉字时,说明当前不再存在任何符合的词语,直接截取一个汉字作为词组
if max_match_len == 1:
segment_list.append(sentence[0:1]) # 追加单个汉字词语
sentence = sentence[1:len(sentence)] # 截取例句
# 输出进行分词后的例句
print('/'.join(segment_list))
基于/语义解析/的/方法/由/于/逻辑形式/而/产生/了/更可/解释/的/推理过程
2. 逆向最大匹配算法
- 从右到左取词,每次取尽可能长的词,匹配词典中的词语。
2、基于统计的分词方法
- 基于统计的分词方法是在给定大量已经分词的文本的前提下,利用统计机器学习模型学习词语切分的规律(称为训练),从而实现对未知文本的切分。例如最大概率分词方法和最大熵分词方法等。随着大规模语料库的建立,统计机器学习方法的研究和发展,基于统计的中文分词方法渐渐成为了主流方法。
- 主要的统计模型有:N元文法模型(N-gram),隐马尔可夫模型(Hidden Markov Model ,HMM),最大熵模型(ME),条件随机场模型(Conditional Random Fields,CRF)等
3、基于理解的分词方法
- 基于理解的分词方法是通过让计算机模拟人对句子的理解,达到识别词的效果。其基本思想就是在分词的同时进行句法、语义分析,利用句法信息和语义信息来处理歧义现象。
- 它通常包括三个部分:分词子系统、句法语义子系统、总控部分。在总控部分的协调下,语法子系统可以获得有关词、句子等的句法和语义信息来对分词歧义进行判断,即它模拟了人对句子的理解过程。
- 这种分词方法需要使用大量的语言知识和信息。由于汉语语言知识的笼统、复杂性,难以将各种语言信息组织成机器可直接读取的形式,因此目前基于理解的分词系统还处在试验阶段。
4、词典与统计相结合的词汇切分方法
利用词典匹配和统计模型的方法,结合了基于词典的规则和基于统计的概率模型,以提高分词准确性和效率。










