1.redis是一种高级的key:value存储系统,其中value支持五种数据类型:
1.1 字符串(strings)
1.2 字符串列表(lists)
1.3 字符串集合(sets)
1.4 有序字符串集合(sorted sets)
1.5 哈希(hashes)
2.redis的持久化:RDB(Redis Database)和AOF(Append Only File)
RDB:在不同的时间点,将redis存储的数据生成快照,并且存储到磁盘等介质上
AOF:将redis执行过的所有指令记录下来,下次redis重新自动的时候,会把这些指令从前到后执行一遍即可,redis重启后,优先使用AOF方式来进行数据恢复,这种方式数据恢复完整度较高
3.redis的主从:主从结构一个是为了冗余备份,另一个是为了提升读性能例如消耗性能的sort就可以由从服务器来承担
主从架构中,关闭主服务器的数据持久化功能,只打开从服务器的数据持久化功能,可以提高主服务器的处理性能
主从架构中,从服务器一般只设置为只读模式,可以避免从服务器的数据被修改
主从架构:

4.redis的哨兵模式:哨兵是一个独立的进程,其原理是哨兵通过发送命令,等待redis服务器响应,从而监控运行的多个redis实例
redis sentinel集群是由若干个sentinel节点组成的分布式集群,可以实现故障发现,故障自动转移,配置中心和客户端通知。
redis sentinel节点数量要满足2n+1(n>=1)的奇数个。
集群监控:负责监控redis master和slave进程是否正常工作
消息通知:如果某个redis有故障,哨兵负责发送消息作为报警通知给管理员
故障转移:如果master node发生故障后,服务会自动转移到slave node上
配置中心:如果故障转移发生后,通知client客户端新的master node地址
原理:每隔1s每隔哨兵会向整个集群:mster+slave+sentinel进程,发送一次ping命令作为一次心跳检测

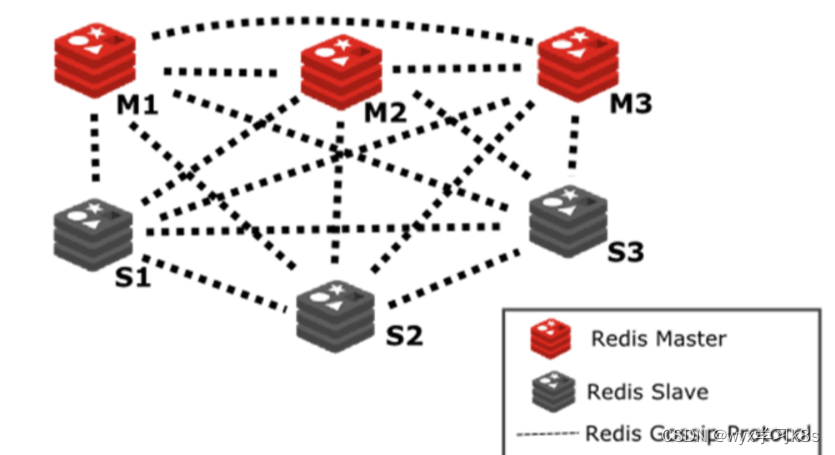
5.redis的集群:redis-master节点一般用于接收读写,而redis-slave节点则一般只用于备份, 其与对应的master拥有相同的slot集合,若某个redis-master意外失效,则再将其对应的slave进行升级为临时redis-master,数量最好使用3主3从
mysql和redis复制区别_Mysql主从复制和Redis主从复制的区别:
复制时机:mysql的主从复制是从数据库接入后开始复制,而redis的主从复制是从头开始,主机之前的数据,从机也会获得
复制原理:
mysql:1.master将记录提交到二进制日志binary log2.slave将master的binary log读取后写到中继日志relay log3.slave读取中级日志的事件,将改变应用到自己的数据库中
redis: 1.slave启动成功会给master发送一个SYNC的命令2.master接受到命令后开始在后台保存快照(即RDB持久化过程)并将保存快照期间接受到的修改命令缓存起来,当快照完成后3.并将保存快照期间接受到的修改命令缓存起来,当快照完成后
全量复制:slave服务在接收到数据库文件数据后,将其存盘并加载到内存中。(刚开始从机连接主机,主机一次给,是全量复制的过程)。
增量复制:Master继续将新的所有收集到的修改命令依次传给slave,完成同步 (主机修改了数据会给予从机修改的数据同步,叫做增量复制)。
etcd:是coreos基于raft协议开发的分布式key-value存储,可用于服务发现、共享配置以及一致性保障性。
核心就是raft协议,只要分为三个部分:选主,日志复制,安全性
1.选主:
raft协议是用于维护一组服务节点数据一致性的协议。这一组服务节点构成一个集群,并且有一个主节点来对外提供服务。当集群初始化或者主节点挂掉后,面临一个选主问题。集群中的每个节点,在任意时刻都处于Leader,Follower,Candidate这三个角色。特点如下:
-
当集群初始化时候,每个节点都是Follower角色
-
当集群存在至多1个有效的主节点,通过心跳与其他节点同步数据
-
当Follower在一定时间内没有收到来自主节点的心跳,会将自己角色变为Candiadate,并发起一次选主投票;当收到包括自己在内超过半数节点赞成后,选举成功,成为主节点,当收到票数不足半数选举失败,或者选举超市,若本轮未选出主节点,将进行下一轮选举(一般出现这种情况都是由于多个节点同时选举,所有节点均未获得过半选票)
-
Candidate节点收到来自主节点的信息后,会立即终止选举过程,进入Follower角色。为了避免陷入选举失败循环,每个节点未收到心跳发起选举的时间是一定范围内的随机值,这样能够避免2个节点同时发起选主
2.日志复制:是指主节点每次操作形成的日志条目,并持久化到本地磁盘,然后通过网络IO发送到其他节点上去。其他节点通过日志的逻辑时钟(TERM)和日志编号(INDEX)来判断是否将该日志记录持久化到本地,当主节点收到包括自己在内超过半数的节点成功返回, 那么认为该日志是可提交的(committed),并将日志输入到状态机,将结果返回给客户端。
3.安全性:
截止此刻,选主以及日志复制并不能保证节点间数据一致。试想,当一个某个节点挂掉了,一段时间后再次重启,并当选为主节点。而在其挂掉这段时间内,集群若有超过半数节点存活,集群会正常工作,那么会有日志提交。这些提交的日志无法传递给挂掉的节点。当挂掉的节点再次当选主节点,它将缺失部分已提交的日志。在这样场景下,按Raft协议,它将自己日志复制给其他节点,会将集群已经提交的日志给覆盖掉。
这显然是不可接受的。
其他协议解决这个问题的办法是,新当选的主节点会询问其他节点,和自己数据对比,确定出集群已提交数据,然后将缺失的数据同步过来。这个方案有明显缺陷,增加了集群恢复服务的时间(集群在选举阶段不可服务),并且增加了协议的复杂度。
Raft解决的办法是,在选主逻辑中,对能够成为主的节点加以限制,确保选出的节点已定包含了集群已经提交的所有日志。如果新选出的主节点已经包含了集群所有提交的日志,那就不需要从和其他节点比对数据了。简化了流程,缩短了集群恢复服务的时间。
这里存在一个问题,加以这样限制之后,还能否选出主呢?答案是:只要仍然有超过半数节点存活,这样的主一定能够选出。因为已经提交的日志必然被集群中超过半数节点持久化,显然前一个主节点提交的最后一条日志也被集群中大部分节点持久化。当主节点挂掉后,集群中仍有大部分节点存活,那这存活的节点中一定存在一个节点包含了已经提交的日志了。
至此,关于Raft协议的简介就全部结束了










