
前言
好久不见(鞠躬最近处在转型期,每天忙到飞起,关注具体技术细节的精力自然就比较少了(上一篇许下的周更承诺也食言了 = =)。上周帮助他人快速解决了一个因误用Flink状态类型引发的性能问题,在这里做个quick notes,并简要介绍一下Flink状态序列化方面的基础知识。
问题及排查
上游部门同事反馈,一个计算逻辑并不复杂的多流join DataStream API作业频繁发生消费积压、checkpoint失败(现场截图已丢失)。作业拓扑如下图所示。

为了脱敏所以缩得很小 = =
按大状态作业的pattern对集群参数进行调优,未果。
通过Flink Web UI定位到问题点位于拓扑中倒数第二个算子,部分sub-task checkpoint总是过不去。观察Metrics面板,发现有少量数据倾斜,而上下游反压度量值全部为0。
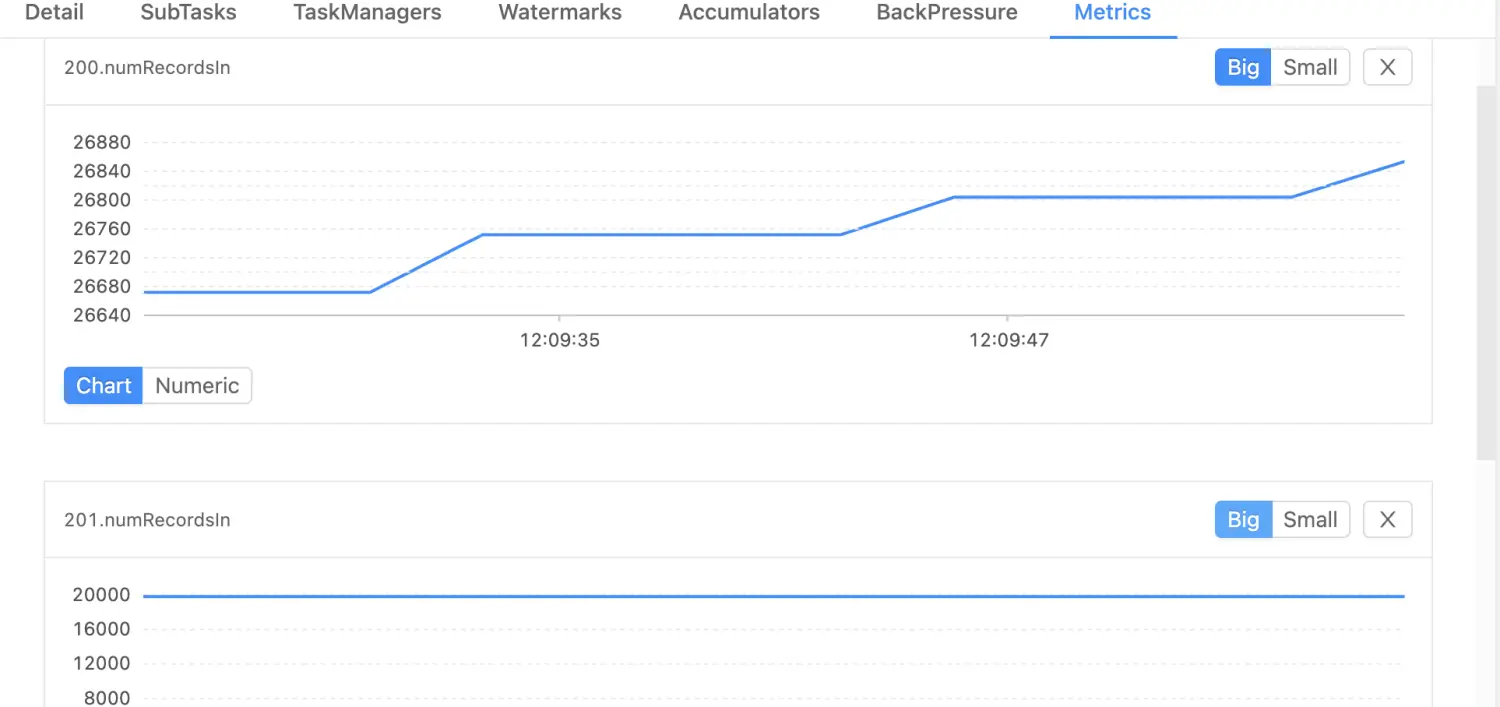
经过持续观察,存在倾斜的sub-task数据量最多只比其他sub-task多出10%~15%,按照常理不应引起如此严重的性能问题。遂找到对应的TaskManager pod打印火焰图,结果如下。

可见RocksDB状态读写的耗时极长,大部分时间花在了Kryo序列化上,说明状态内存储了Flink序列化框架原生不支持的对象。直接让相关研发同学show me the code,真相大白:
private transient MapState<String, HashSet<String>> state1;
private transient MapState<String, HashSet<String>> state2;
private transient ValueState<Map<String, String>> state3;
Flink序列化框架内并没有针对HashSet的序列化器,自然会fallback到Kryo。即使这些Set并不算大,状态操作的开销也会急剧上升。当然,ValueState<Map<String, String>>用法也是错误的,应改成MapState<String, String>。
最快的临时解决方法很简单:把所有状态内用到的HashSet全部改成Map<String, Boolean>,同样可以去重。虽然并不优雅,但因为有了原生MapSerializer支持,效率大幅提升。下面简要介绍Flink的状态序列化。
TypeSerializer
在我们创建状态句柄所需的描述符StateDescriptor时,要指定状态数据的类型,如:
ValueStateDescriptor<Integer> stateDesc = new ValueStateDescriptor<>("myState", Integer.class);
ValueState<Integer> state = this.getRuntimeContext().getState(stateDesc);
与此同时,也就指定了对应数据类型的Serializer。我们知道,TypeSerializer是Flink Runtime序列化机制的底层抽象,状态数据的序列化也不例外。以处理Map类型的MapSerializer为例,代码如下,比较清晰。
@Internal
public final class MapSerializer<K, V> extends TypeSerializer<Map<K, V>> {
private static final long serialVersionUID = -6885593032367050078L;
/** The serializer for the keys in the map */
private final TypeSerializer<K> keySerializer;
/** The serializer for the values in the map */
private final TypeSerializer<V> valueSerializer;
/**
* Creates a map serializer that uses the given serializers to serialize the key-value pairs in
* the map.
*
* @param keySerializer The serializer for the keys in the map
* @param valueSerializer The serializer for the values in the map
*/
public MapSerializer(TypeSerializer<K> keySerializer, TypeSerializer<V> valueSerializer) {
this.keySerializer =
Preconditions.checkNotNull(keySerializer, "The key serializer cannot be null");
this.valueSerializer =
Preconditions.checkNotNull(valueSerializer, "The value serializer cannot be null.");
}
// ------------------------------------------------------------------------
// MapSerializer specific properties
// ------------------------------------------------------------------------
public TypeSerializer<K> getKeySerializer() {
return keySerializer;
}
public TypeSerializer<V> getValueSerializer() {
return valueSerializer;
}
// ------------------------------------------------------------------------
// Type Serializer implementation
// ------------------------------------------------------------------------
@Override
public boolean isImmutableType() {
return false;
}
@Override
public TypeSerializer<Map<K, V>> duplicate() {
TypeSerializer<K> duplicateKeySerializer = keySerializer.duplicate();
TypeSerializer<V> duplicateValueSerializer = valueSerializer.duplicate();
return (duplicateKeySerializer == keySerializer)
&& (duplicateValueSerializer == valueSerializer)
? this
: new MapSerializer<>(duplicateKeySerializer, duplicateValueSerializer);
}
@Override
public Map<K, V> createInstance() {
return new HashMap<>();
}
@Override
public Map<K, V> copy(Map<K, V> from) {
Map<K, V> newMap = new HashMap<>(from.size());
for (Map.Entry<K, V> entry : from.entrySet()) {
K newKey = keySerializer.copy(entry.getKey());
V newValue = entry.getValue() == null ? null : valueSerializer.copy(entry.getValue());
newMap.put(newKey, newValue);
}
return newMap;
}
@Override
public Map<K, V> copy(Map<K, V> from, Map<K, V> reuse) {
return copy(from);
}
@Override
public int getLength() {
return -1; // var length
}
@Override
public void serialize(Map<K, V> map, DataOutputView target) throws IOException {
final int size = map.size();
target.writeInt(size);
for (Map.Entry<K, V> entry : map.entrySet()) {
keySerializer.serialize(entry.getKey(), target);
if (entry.getValue() == null) {
target.writeBoolean(true);
} else {
target.writeBoolean(false);
valueSerializer.serialize(entry.getValue(), target);
}
}
}
@Override
public Map<K, V> deserialize(DataInputView source) throws IOException {
final int size = source.readInt();
final Map<K, V> map = new HashMap<>(size);
for (int i = 0; i < size; ++i) {
K key = keySerializer.deserialize(source);
boolean isNull = source.readBoolean();
V value = isNull ? null : valueSerializer.deserialize(source);
map.put(key, value);
}
return map;
}
@Override
public Map<K, V> deserialize(Map<K, V> reuse, DataInputView source) throws IOException {
return deserialize(source);
}
@Override
public void copy(DataInputView source, DataOutputView target) throws IOException {
final int size = source.readInt();
target.writeInt(size);
for (int i = 0; i < size; ++i) {
keySerializer.copy(source, target);
boolean isNull = source.readBoolean();
target.writeBoolean(isNull);
if (!isNull) {
valueSerializer.copy(source, target);
}
}
}
@Override
public boolean equals(Object obj) {
return obj == this
|| (obj != null
&& obj.getClass() == getClass()
&& keySerializer.equals(((MapSerializer<?, ?>) obj).getKeySerializer())
&& valueSerializer.equals(
((MapSerializer<?, ?>) obj).getValueSerializer()));
}
@Override
public int hashCode() {
return keySerializer.hashCode() * 31 + valueSerializer.hashCode();
}
// --------------------------------------------------------------------------------------------
// Serializer configuration snapshotting
// --------------------------------------------------------------------------------------------
@Override
public TypeSerializerSnapshot<Map<K, V>> snapshotConfiguration() {
return new MapSerializerSnapshot<>(this);
}
}
总结:
- 序列化和反序列化本质上都是对
MemorySegment的操作,通过DataOutputView写出二进制数据,通过DataInputView读入二进制数据; - 对于复合数据类型,也应嵌套定义并调用内部元素类型的
TypeSerializer; - 必须要有对应的
TypeSerializerSnapshot。该组件定义了TypeSerializer本身及其所包含的元数据(即state schema)的序列化方式,这些信息会存储在快照中。可见,通过TypeSerializerSnapshot可以判断状态恢复时数据的兼容性,是Flink实现state schema evolution特性的关键所在。
TypeSerializerSnapshot
TypeSerializerSnapshot接口有以下几个重要的方法。注释写得很清晰,不再废话了(实际是因为懒而且累 = =
/**
* Returns the version of the current snapshot's written binary format.
*
* @return the version of the current snapshot's written binary format.
*/
int getCurrentVersion();
/**
* Writes the serializer snapshot to the provided {@link DataOutputView}. The current version of
* the written serializer snapshot's binary format is specified by the {@link
* #getCurrentVersion()} method.
*
* @param out the {@link DataOutputView} to write the snapshot to.
* @throws IOException Thrown if the snapshot data could not be written.
* @see #writeVersionedSnapshot(DataOutputView, TypeSerializerSnapshot)
*/
void writeSnapshot(DataOutputView out) throws IOException;
/**
* Reads the serializer snapshot from the provided {@link DataInputView}. The version of the
* binary format that the serializer snapshot was written with is provided. This version can be
* used to determine how the serializer snapshot should be read.
*
* @param readVersion version of the serializer snapshot's written binary format
* @param in the {@link DataInputView} to read the snapshot from.
* @param userCodeClassLoader the user code classloader
* @throws IOException Thrown if the snapshot data could be read or parsed.
* @see #readVersionedSnapshot(DataInputView, ClassLoader)
*/
void readSnapshot(int readVersion, DataInputView in, ClassLoader userCodeClassLoader)
throws IOException;
/**
* Recreates a serializer instance from this snapshot. The returned serializer can be safely
* used to read data written by the prior serializer (i.e., the serializer that created this
* snapshot).
*
* @return a serializer instance restored from this serializer snapshot.
*/
TypeSerializer<T> restoreSerializer();
/**
* Checks a new serializer's compatibility to read data written by the prior serializer.
*
* <p>When a checkpoint/savepoint is restored, this method checks whether the serialization
* format of the data in the checkpoint/savepoint is compatible for the format of the serializer
* used by the program that restores the checkpoint/savepoint. The outcome can be that the
* serialization format is compatible, that the program's serializer needs to reconfigure itself
* (meaning to incorporate some information from the TypeSerializerSnapshot to be compatible),
* that the format is outright incompatible, or that a migration needed. In the latter case, the
* TypeSerializerSnapshot produces a serializer to deserialize the data, and the restoring
* program's serializer re-serializes the data, thus converting the format during the restore
* operation.
*
* @param newSerializer the new serializer to check.
* @return the serializer compatibility result.
*/
TypeSerializerSchemaCompatibility<T> resolveSchemaCompatibility(
TypeSerializer<T> newSerializer);
特别注意,在状态恢复时,state schema的兼容性判断结果TypeSerializerSchemaCompatibility有4种:
COMPATIBLE_AS_IS:兼容,可以直接使用新Serializer;COMPATIBLE_AFTER_MIGRATION:兼容,但需要用快照中的旧Serializer反序列化一遍数据,再将数据用新Serializer重新序列化。最常见的场景如状态POJO中增加或删除字段,详情可以参考PojoSerializerSnapshot类的相关代码;COMPATIBLE_WITH_RECONFIGURED_SERIALIZER:兼容,但需要将新Serializer重新配置之后再使用。此类场景不太常见,举例如状态POJO的类继承关系发生变化;INCOMPATIBLE:不兼容,无法恢复。例如,更改POJO中的一个简单类型字段的type(e.g. String → Integer),由于负责处理简单数据类型的SimpleTypeSerializerSnapshot不支持此类更改,就会抛出异常:
@Override
public TypeSerializerSchemaCompatibility<T> resolveSchemaCompatibility(
TypeSerializer<T> newSerializer) {
return newSerializer.getClass() == serializerSupplier.get().getClass()
? TypeSerializerSchemaCompatibility.compatibleAsIs()
: TypeSerializerSchemaCompatibility.incompatible();
}
显然,对于复合类型(如List、Map),需要先判断外部容器Serializer的兼容性,再判断嵌套Serializer的兼容性。详情可以参考Flink内部专门为此定义的CompositeTypeSerializerSnapshot抽象类,该类比较复杂,在此按下不表。
The End
在一些特殊的场景下,我们需要自定义Serializers来实现更好的状态序列化(例如用RoaringBitmap代替Set在状态中进行高效的去重),今天时间已经很晚,暂时不给出具体实现了。关于自定义状态序列化器的更多细节,请看官参见官方文档<<Custom Serialization for Managed State>>一章。










