搭建背景
最近工作中需要用上 Google SEO(搜索引擎优化),有了解过的朋友们应该都知道SEO必不可少的工作之一就是查询关键词的搜索排名。关键词少的时候可以一个一个去查没什么问题,但是到了后期,一个网站都有几百上千的关键词,你再去一个一个查,至少要花费数小时的时间。
虽然市面上有很多SEO免费或者收费工具,但免费的基本都不能批量查,网上免费的最多也就只能10个10个查询,而且查询速度很慢。收费的工具如Ahrefs、SEMrush等以月为单位收费最低也都要上百美刀/月,当然如果觉得价格合适也可以进行购买,毕竟这些工具的很多功能都很实用。今天我给大家分享的这个排名搜索工具基于python实现,当然肯定是不需要花费任何费用,装上python开发环境即可。
实现步骤
话不多说,上代码:
import requests
from bs4 import BeautifulSoup
首先我们导入requests和BeautifulSoup两个库,requests用于发送HTTP请求,BeautifulSoup用于解析HTML。
def get_google_rank(keyword, website):
try:
url = f"https://www.google.com/search?q={keyword}"
headers = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Mobile Safari/537.36'}
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
search_results = soup.find_all('div', class_='g')
for i, result in enumerate(search_results):
link = result.find('a')['href']
if website in link:
return i + 1 # 返回排名(从1开始)
return -1 # 如果未找到网站,返回-1
except requests.exceptions.RequestException as e:
print(f"An error occurred: {e}")
return None
上述代码定义了一个名为get_google_rank的函数,该函数接受两个参数:keyword(关键词)和website(网站域名)。函数的目标是获取指定关键词在谷歌搜索结果中的排名。
在函数内部,首先构建了一个URL,该URL使用指定的关键词进行谷歌搜索。然后设置了一个User-Agent头部,模拟一个浏览器的请求。使用requests.get方法发送HTTP请求,获取搜索结果页面的响应。response.raise_for_status()用于检查请求是否成功,如果返回的状态码不是200,会抛出一个异常。
接下来,使用BeautifulSoup库解析响应的HTML内容,创建一个BeautifulSoup对象,并使用html.parser解析器进行解析。然后通过find_all方法查找所有具有’class’属性为’g’的’div’元素,这些元素包含了搜索结果的信息。
接着使用enumerate函数遍历搜索结果列表,并使用result.find('a')['href']获取每个搜索结果中的链接。如果指定的网站域名出现在链接中,就返回当前的排名(从1开始计数)。
如果循环结束后未找到指定的网站域名,函数返回-1,表示未找到网站。
如果在请求过程中发生异常,会捕获requests.exceptions.RequestException异常,并打印错误消息,然后返回None。
# 示例用法
keywords = ['摸鱼小游戏','是男人就下100层','游戏']
website = 'haiyong.site'
for keyword in keywords:
rank = get_google_rank(keyword, website)
if rank is not None:
if rank == -1:
print(f"{keyword}没有排名")
else:
print(f"{keyword}排名第{rank}")
最后是一个示例用法的代码。定义了一个包含多个关键词的列表keywords和一个指定的网站域名website。
通过for循环遍历关键词列表,调用get_google_rank函数获取每个关键词在谷歌搜索结果中的排名。如果返回的排名不为None,则根据排名的值进行条件判断,如果排名为-1,打印关键词没有排名的消息,否则打印关键词的排名信息。
以上就是整段代码的含义和逻辑。该代码实现了获取指定关键词在谷歌搜索结果中的排名,并通过示例展示了如何使用这个函数。
完整代码
import requests
from bs4 import BeautifulSoup
def get_google_rank(keyword, website):
try:
url = f"https://www.google.com.hk/search?q={keyword}"
headers = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Mobile Safari/537.36'}
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
search_results = soup.find_all('div', class_='g')
for i, result in enumerate(search_results):
link = result.find('a')['href']
if website in link:
return i + 1 # 返回排名(从1开始)
return -1 # 如果未找到网站,返回-1
except requests.exceptions.RequestException as e:
print(f"An error occurred: {e}")
return None
# 示例用法
keywords = ['摸鱼小游戏','是男人就下100层','游戏']
website = 'haiyong.site'
for keyword in keywords:
rank = get_google_rank(keyword, website)
if rank is not None:
if rank == -1:
print(f"{keyword}没有排名")
else:
print(f"{keyword}排名第{rank}")
放个必应上查询的截图吧。
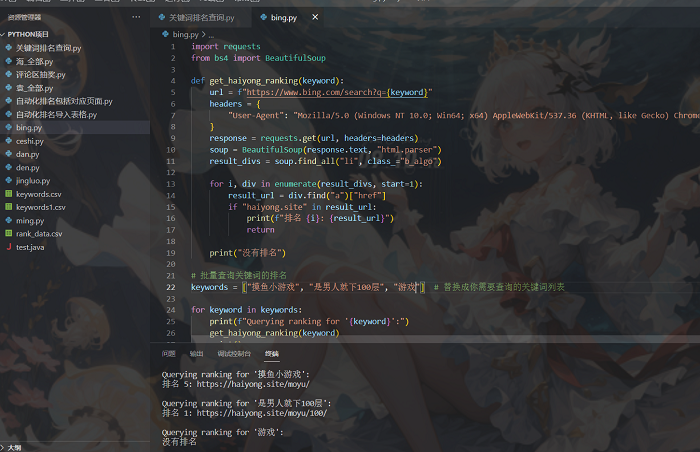
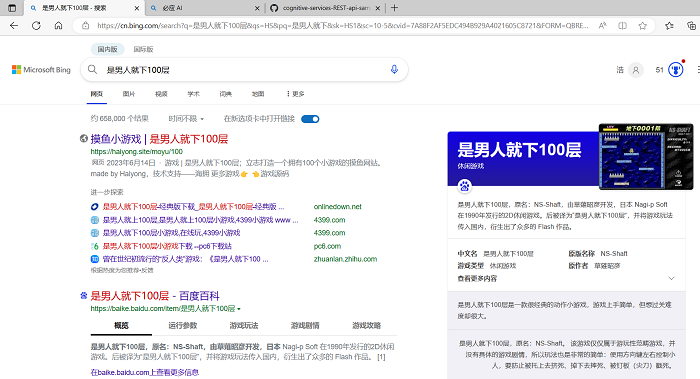
另外,需要注意的是,频繁的使用爬虫程序进行搜索引擎结果的抓取可能导致IP被谷歌封锁。
解决ip封锁问题
当我们查询很多次排名之后,会出现类似下图这种报错:
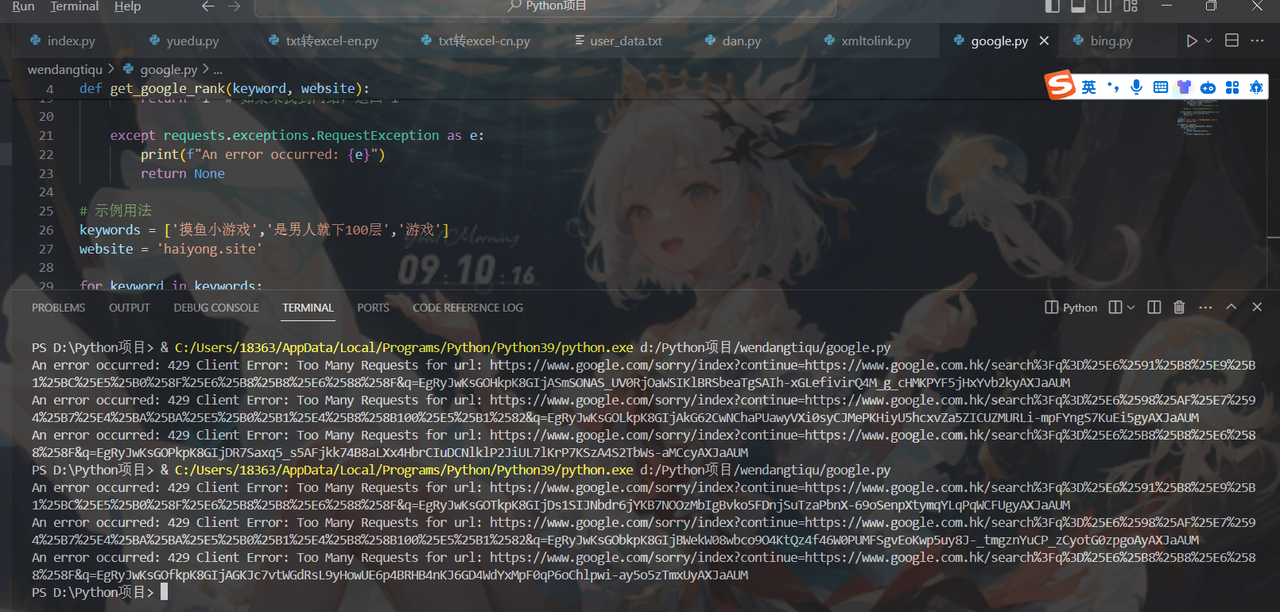
这个错误消息表明在向谷歌服务器发送请求时遇到了问题。具体来说,它显示了一个名为“429 Client Error”的错误,表明由于发送了过多的请求而被服务器拒绝。
HTTP状态码429表示“太多请求”,意味着你发送的请求过于频繁,超出了服务器允许的限制。当服务器检测到某个IP地址或用户发送过多请求时,会返回这个状态码以示警告或拒绝服务。
所以为了避免这种情况,可以考虑使用代理IP来分散请求,降低被封锁的风险。这里我推荐一款好用的代理IP服务商:亮数据,我也是在寻找数据挖掘工具的过程中了解到这个平台,选择代理ip进行关键词排名查询可以有效地规避被封锁的问题。

亮数据的IP代理服务产品优点包括:
- 匿名性:通过使用代理网络,用户可以隐藏自身的IP,使目标网站无法检测到用户的真实身份,从而获取真实可靠的信息。
- 合法性:使用代理网络访问公开开源数据是完全合法的,因为用户访问的是公开数据而非私人内容。
- 多样性:代理类型丰富,包括数据中心代理、静态住宅代理、动态住宅代理、手机移动代理以及代理组合,以满足不同需求。
除了IP代理服务,还有网络爬虫及解锁工具:
- 网络爬虫:网络爬虫技术可以帮助用户从目标网站上获取所需数据和信息,用于数据收集、分析等用途。
- 解锁工具:解锁工具可以帮助用户突破地理位置限制或竞争信息屏蔽,确保能够从目标网站获取信息而不被屏蔽或误导商业决策。
亮数据为粉丝提供了10美金的抵用券,成功注册账户,并登录后在用户界面里输入折扣代码即可享受抵扣!
折扣代码:haiyong
访问页面:https://www.bright.cn/use-cases/serp/?utm_source=brand&utm_campaign=brnd-mkt_cn_csdn_haiyong&promo=haiyong
如有问题,可以关“Bright_Data”注亮数据官微,联系后台客服。
这些工具在不同场景下都发挥着重要作用,包括广告验证、旅游情报、品牌保护等,为用户提供了访问全球重要地区及重要站点的通行证,并助力数据采集工作。
下面是一个修改后的示例,演示了如何在函数中使用代理IP:
import requests
from bs4 import BeautifulSoup
# 代理IP地址,替换成你自己的代理IP
proxy = {
'http': 'http://your_proxy_ip:port',
'https': 'https://your_proxy_ip:port'
}
def get_google_rank(keyword, website):
try:
url = f"https://www.google.com.hk/search?q={keyword}"
headers = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Mobile Safari/537.36'}
response = requests.get(url, headers=headers, proxies=proxy) # 使用代理IP发送请求
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
search_results = soup.find_all('div', class_='g')
for i, result in enumerate(search_results):
link = result.find('a')['href']
if website in link:
return i + 1 # 返回排名(从1开始)
return -1 # 如果未找到网站,返回-1
except requests.exceptions.RequestException as e:
print(f"An error occurred: {e}")
return None
# 示例用法
keywords = ['摸鱼小游戏','是男人就下100层','游戏']
website = 'haiyong.site'
for keyword in keywords:
rank = get_google_rank(keyword, website)
if rank is not None:
if rank == -1:
print(f"{keyword}没有排名")
else:
print(f"{keyword}排名第{rank}")
在这个修改后的示例中,我们添加了一个名为proxy的字典,其中包含了HTTP和HTTPS协议的代理IP地址。然后,在调用requests.get方法时,通过proxies参数将代理IP传递给请求。这样就能够使用代理IP发送请求,帮助降低被封锁的风险。
记得将’your_proxy_ip:port’替换成你自己的代理IP地址和端口即可。
到此我们就已经完成了用 Python 制作的一个批量查询搜索排名的SEO工具,当然,如果大家有什么更好的建议也可以在评论中指出,感谢大家的阅读。










