LLM2LLM: Boosting LLMs with Novel Iterative Data Enhancement
摘要
预训练的大型语言模型(LLMs)目前是解决绝大多数自然语言处理任务的最新技术。尽管许多实际应用仍然需要微调以达到令人满意的性能水平,但许多应用处于低数据量状态,这使得微调变得具有挑战性。为了解决这个问题,我们提出了LLM2LLM,这是一种针对性和迭代式的数据增强策略,它使用教师LLM通过增加可用于特定任务微调的数据来增强小型种子数据集。LLM2LLM (1) 在初始种子数据上微调基线学生LLM,(2) 评估并提取模型出错的数据点,并 (3) 使用教师LLM基于这些错误数据点生成合成数据,然后将这些数据点重新添加到训练数据中。这种方法在训练期间通过LLM放大了错误预测数据点的信号,并将它们重新整合到数据集中,以便专注于LLM更具挑战性的例子。我们的结果表明,LLM2LLM显著提高了LLM在低数据量状态下的性能,超越了传统的微调和其他数据增强基线。LLM2LLM减少了对劳动密集型数据策划的依赖,为更可扩展和高性能的LLM解决方案铺平了道路,使我们能够处理数据受限的领域和任务。我们在低数据量状态下使用LLaMA2-7B学生模型,在GSM8K数据集上实现了高达24.2%的改进,在CaseHOLD上为32.6%,在SNIPS上为32.0%,在TREC上为52.6%,在SST-2上为39.8%,相比于常规微调。
核心方法
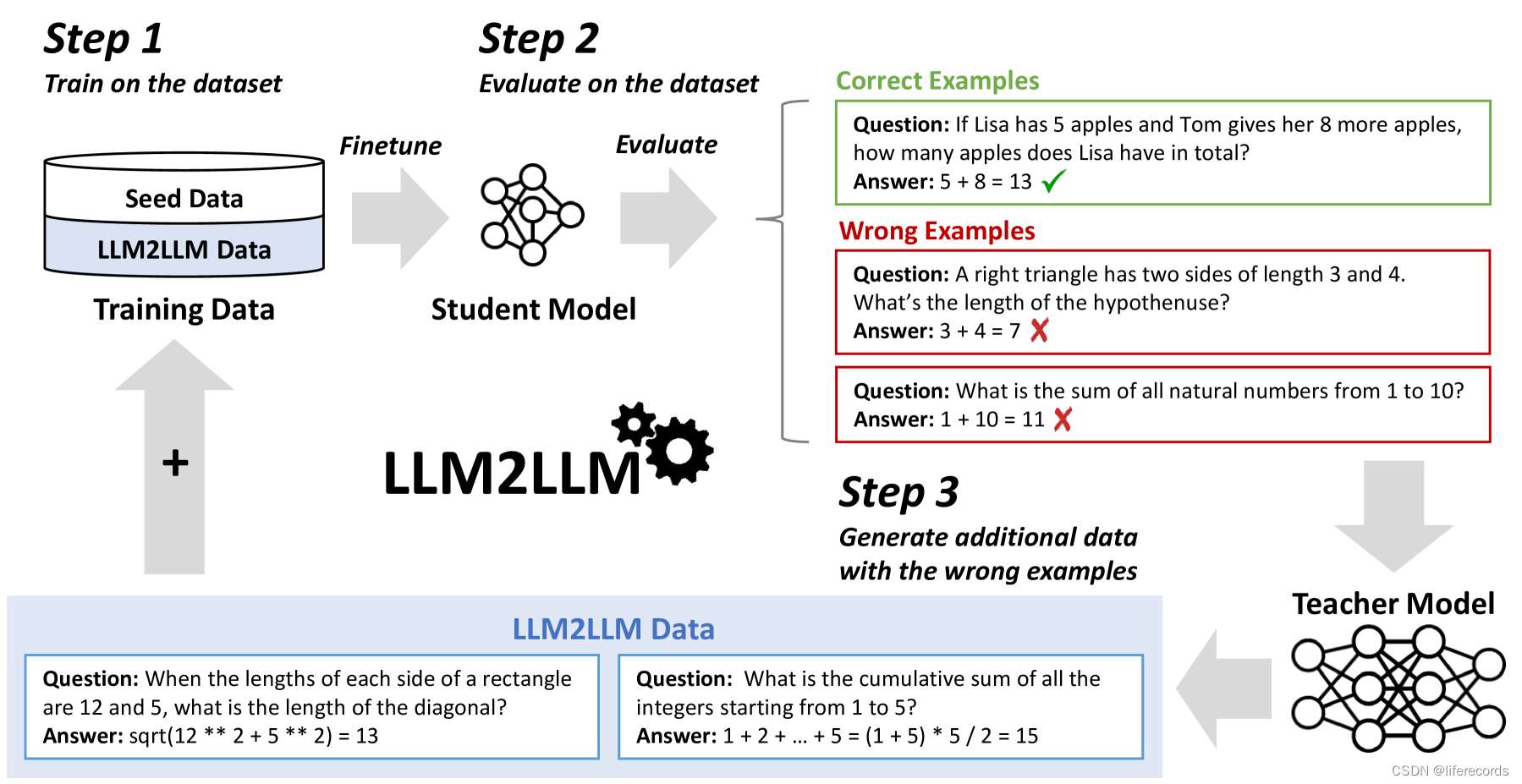
LLM2LLM的核心方法包括以下几个步骤:
- 微调学生模型:在初始种子数据上微调基线学生LLM。
- 评估和提取错误数据:评估学生模型在训练数据上的表现,并提取模型回答错误的数据点。
- 生成合成数据:使用教师LLM基于错误数据点生成新的合成数据,这些数据点在语义上与原始数据点相似但在表述上有所不同。
- 迭代数据增强:将生成的合成数据添加回训练集中,并在新的数据集上重复微调过程,以进一步提高模型性能。
实验说明
实验结果展示了LLM2LLM在不同数据集上的测试准确率提升情况。数据集包括GSM8K、CaseHOLD、SNIPS、TREC和SST-2,涵盖了从0.02%到50%的不同种子数据比例。实验中,我们使用了LLaMA2-7B作为学生模型,并以GPT-3.5作为教师模型。实验结果表明,LLM2LLM在低数据量状态下显著提高了模型性能,尤其是在数据量较少的情况下。
| 数据集 | 基线微调准确率 | LLM2LLM准确率 |
|---|---|---|
| GSM8K | 0.00% | 19.56% - 38.67% |
| CaseHOLD | 12.28% | 66.50% - 88.14% |
| SNIPS | 11.86% | 92.14% |
| TREC | 11.20% | 78.80% - 90.20% |
| SST-21 | 27.06% | 92.66% - 94.04% |
结论
我们介绍了LLM2LLM,这是一种自适应和迭代的基于LLM的数据增强框架,使用LLM来扩展较小的微调数据集,而不是手动生成更多数据。这种方法由于其迭代和针对性的本质而有效,它允许我们从LLM出错的数据点中增强信号。因此,我们能够在使用LLaMA-2-7B学生模型的低数据量状态下,在GSM8K、CaseHOLD、SNIPS、TREC和SST-2数据集上实现了显著的性能提升。未来的工作可以集中在调整我们框架的超参数上,以及将我们的方法与其他LLM技术(如提示调整和少样本学习)结合起来。









