目录
6)通过 Elasticsearch-head 查看 Elasticsearch 信息
1)在 node1 服务器上安装 kibana,并设置开机启动。
2)设置 Kibana 的主配置文件/etc/kibana/kibana.yml。
5)配置 Apache 服务器,将 Apache 服务器的日志添加到 Elasticsearch 并通过 kibana 显示。
在大型运维环境当中,运维工程师或机房管理员通常需要面对大量的服务器等设备。在对于这些服务器维护时,有一个很重要的工作就是查看每台服务器的日志信息、分析日志信 息,而每天逐台检查的方式显然效率比较低下。传统的方式是通过搭建日志服务器,将所有服务器的日志收集到日志服务器统一查看。但是面对众多的日志数据很难去分析以及查找所需要的内容,即很难快速定位是否出现故障,以及哪些机器、哪些服务存在故障。而 ELK 可以很好地解决这一问题。
一、案例分析
1.1、案例概述
日志分析是运维工程师解决系统故障、发现问题的主要手段。日志包含多种类型,包括程序日志、Web 访问日志、系统日志以及安全日志等。通过对日志的分析,既可以未雨绸缪预防故障的发生,又可以在故障发生时寻找蛛丝马迹、快速定位故障点。机房管理员也可以通过日志了解服务器的软件信息、硬件信息、服务器负荷以及安全性相关的信息,如服务器是否被攻击、磁盘空间是否即将耗尽、内存是否严重不足等。通过这些分析,机房管理员可以及时采取措施。通常情况下,每台服务器或者客户端都产生日志,相对而言,服务器日志更加重要,因为它存放着企业的重要数据。同时作为服务提供者,一旦出现问题,将影响所有客户端的使用。
一些大型的机房或者数据中心一般不会给服务器配置显示设备,而逐台远程登录设备查看日志,需要每次系统认证成功后执行,且效率低下。普遍的做法是日志的集中管理,即将所有服务器的日志集中发送到日志服务器中,如开源的 Syslog。可以集中查看所有服务器日志,减轻了工作量,从安全性的角度来看,这种集中日志管理可以有效查询以及跟踪服务器被攻击的行为,因为黑客入侵的一瞬间,一些安全日志已经被发送到了日志服务器。正如 行的监控系统,窃贼一旦发现监控设备,即使立即破坏这些设备也于事无补,因为监控画面早已经发送至监控服务器中。采用集中化管理日志,也存在一些不足,如针对日志的分析以及查找将变得非常困难,对日志的逐条检查虽然可以获取到有价值的信息,但是工作量十分庞大。像 Apache 每天可能产生上万条日志,Linux 虽然也提供了文字编辑类的工具命令 (如 grep、awk、wc 等)可以快速查找问题,这些工具可以快速定位已知关键字的日志内容, 却无法快速定位未知错误日志。当面对更高要求的查询、排序、统计以及数据分析时,加之 庞大的机器数量,这些工具难免力不从心。开源实时日志分析 ELK 平台能够完美地解决上述问题。
ELK 由 ElasticSearch、Logstash 和 Kiabana 三个开源工具组成,其官方网站为 https://www.elastic.co/cn。
- Elasticsearch 是一个开源分布式实时分析搜索引擎,建立在全文搜索引擎库 Apache Lucene 基础上,同时隐藏了 Apache Lucene 的复杂性。Elasticsearch 将所有的功能打包成一个独立的服务,并提供了一个简单的 RESTful API 接口。它具有分布式、零 配置、自动发现、索引自动分片、索引副本机制、RESTful 风格接口、多数据源、自动 搜索负载等特点。
- Logstash 是一个完全开源的工具,主要用于日志收集,同时可以对数据处理,并输出给 Elasticsearch。
- Kibana 也是一个开源和免费的工具,Kibana 可以为 Logstash 和 ElasticSearch 提供图形化的日志分析 Web 界面,可以汇总、分析和搜索重要数据日志。
ELK 的工作原理如下图所示:
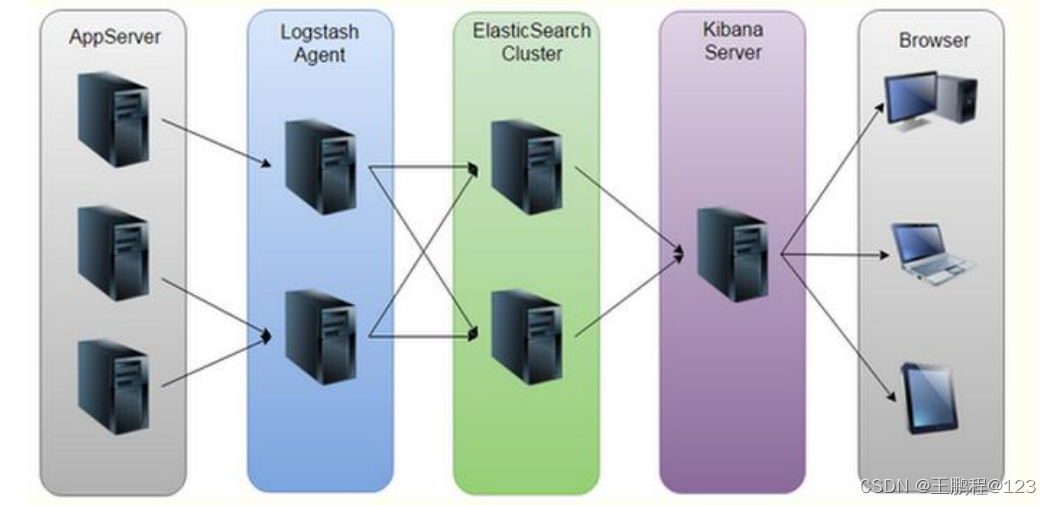
ELK 的工作原理
Logstash 收集 AppServer 产生的 Log,并存放到 ElasticSearch 群集中,而 Kibana 则从 ES 群集中查询数据生成图表,再返回给 Browser。简单来说,进行日志处理分析,一般需要经过以下几个步骤:
- 将日志进行集中化管理。
- 将日志格式化(Logstash)并输出到 Elasticsearch。
- 对格式化后的数据进行索引和存储(Elasticsearch)。
- 前端数据的展示(Kibana)。
1.2、案例前置知识点
1)Elasticsearch 介绍
Elasticsearch 是一个基于 Lucene 的搜索服务器。它稳定、可靠、快速,而且具有比较好的水平扩展能力,为分布式环境设计,在云计算中被广泛应用。Elasticsearch 提供了一 个分布式多用户能力的全文搜索引擎,基于 RESTful Web 接口。通过该接口,用户可以通过浏览器与 Elasticsearch 通信。Elasticsearch 是用 Java 开发的,并作为 Apache 许可条款下的开放源码发布,Wikipedia、Stack、Overflow、GitHub 等都基于 Elasticsearch 来构建搜索引擎,具有实时搜索、稳定、可靠、快速、安装使用方便等特点。
Elasticsearch 的基础核心概念。
- 接近实时(NRT):Elasticsearch 是一个搜索速度接近实时的搜索平台,响应速度非常快,从开始索引一个文档到这个文档能够被搜索到只有一个轻微的延迟(通常是 1s)。
- 群集(cluster):群集就是由一个或多个节点组织在一起,在所有节点上存放用户数据, 并一起提供索引和搜索功能。通过选举产生主节点,并提供跨节点的联合索引和搜索的功能。每个群集都有一个唯一标识的名称,默认是 Elasticsearch,每个节点是基于群集名字加入到群集中的。一个群集可以只有一个节点,为了具备更好的容错性,通常配置多个节点,在配置群集时,建议配置成群集模式。
- 节点(node):是指一台单一的服务器,多个节点组织为一个群集,每个节点都存储数据并参与群集的索引和搜索功能。和群集一样,节点也是通过名字来标识的,默认情况 下,在节点启动时会随机分配字符名,也可以自定义。通过指定群集名字,节点可以加入到群集中。默认情况,每个节点都已经加入 Elasticsearch 群集。如果群集中有多个节点,它们将会自动组建一个名为 Elasticsearch 的群集。
- 索引(index):类似于关系型数据库中的“库”。当索引一个文档后,就可以使用 Elasticsearch 搜索到该文档,也可以简单地将索引理解为存储数据的地方,可以方便地进行全文索引。在 index 下面包含存储数据的类型(Type),Type 类似于关系型数据库中的“表”,用来存放具体数据,而 Type 下面包含文档(Document),文档相当于关系型数据库的“记录”,一个文档是一个可被索引的基础信息单元。
- 分片和副本(shards & replicas):Elasticsearch 将索引分成若干个部分,每个部分称为一个分片,每个分片就是一个全功能的独立的索引。分片的数量一般在索引创建前指定,且创建索引后不能更改。分片的两个最主要原因如下。
一个好的数据存储方案要求无论何种故障(如节点不可用)下数据都可用,并且具有较高的存储效率。为此,Elasticsearch 将索引分片复制一份或多份,称为副本。副本是索引的另一个备份,用于数据冗余以及负载分担。默认情况下 Elasticsearch 自动对索引请求进行负载分担。
总之,索引可以被分为若干个分片。这些分片也可以被复制 0 次(意思是没有复制) 或多次。当有副本存在时,作为复制源的分片称为主分片,而作为复制目标的分片称为副本分片。分片和副本的数量可以在索引创建时指定。在索引创建之后,可以改变副本的数量, 但是不能改变分片的数量。默认情况下,Elasticsearch 中的每个索引被分片成 5 个主分片 和 1 个副本。在两个节点的场景中,每个索引将会有 5 个主分片和另外 5 个副本分片,每 个索引总共就有 10 个分片。
2)Logstash 介绍
Logstash 由 JRuby 语言编写,运行在 Java 虚拟机(JVM)上,是一款强大的数据处理工具,可以实现数据传输、格式处理、格式化输出。Logstash 具有强大的插件功能,常用于日志处理。Logstash 可配置单一的代理端,与其他开源软件结合,以实现不同的功能。
Logstash 的理念很简单,它只做三件事情:数据输入、数据加工(如过滤,改写等) 以及数据输出。通过组合输入和输出,可以实现多种需求。Logstash 处理日志时,典型的部署架构下图所示。

部署架构图
LogStash 的主要组件如下。
- Shipper:日志收集者。负责监控本地日志文件的变化,及时收集最新的日志文件内容。通常远程代理端(agent)只需要运行这个组件即可。
- Indexer:日志存储者。负责接收日志并写入到本地文件。
- Broker:日志 Hub。负责连接多个 Shipper 和 Index。
- Search and Storage:允许对事件进行搜索和存储。
- Web Interface:基于 Web 的展示界面。
正是由于以上组件在 LogStash 架构中可独立部署,才提供了更好的群集扩展性。
Logstash 使用管道方式进行日志的搜集处理和输出。有点类似 Linux 系统的管道命令,将前一个流程的处理结果发送到后一个流程继续处理。在 Logstash 中,包括了三个阶段, 分别是输入(Input )、处理(Filter,非必需)和输出(Output),其关系如下图所示。
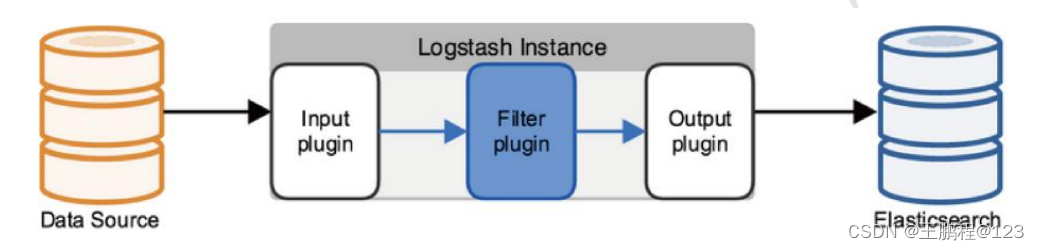 Logstash 处理数据流程图
Logstash 处理数据流程图
在上图中,整个流程为 Input 收集数据,Filter 处理数据,Output 输出数据。每个阶段也可以指定多种方式,如输出既可以输出到 Elasticsearch 中,也可以指定到 stdout 在控制台打印。这种插件式的组织方式,使得 Logstash 的扩展和定制非常方便。
3)Kinaba 介绍
Kibana 是一个针对 Elasticsearch 的开源分析及可视化平台,主要设计用来和 Elasticsearch 一起工作,可以搜索、查看存储在 Elasticsearch 索引中的数据,并通过各种图表进行高级数据分析及展示。Kibana 可以让数据看起来一目了然。它操作简单,基于浏览器的用户界面可以让用户在任何位置都可以实时浏览。Kibana 可以快速创建仪表板 (dashboard)实时显示 Elasticsearch 查询动态。Kibana 使用非常简单,只需要添加索引就 可以监测 Elasticsearch 索引数据。
Kibana 的主要功能如下。
- Elasticsearch 无缝之集成。Kibana 架构是为 Elasticsearch 定制的,可以将任何(结构化和非结构化)数据加入 Elasticsearch 索引。Kibana 还充分利用了 Elasticsearch 强大的搜索和分析功能。
- 整合数据。Kibana 可以让海量数据变得更容易理解,根据数据内容可以创建形象的柱形图、折线图、散点图、直方图、饼图和地图,以方便用户查看。
- 复杂数据分析。Kibana 提升了 Elasticsearch 的分析能力,能够更加智能地分析数据, 执行数据转换并且根据要求对数据切割分块。
- 让更多团队成员受益。强大的数据库可视化接口让各业务岗位都能够从数据集合受益。
- 接口灵活,分享更容易。使用 Kibana 可以更加方便地创建、保存、分享数据,并将可视化数据快速交流。
- 配置简单。Kibana 的配置和启用非常简单,用户体验非常友好。Kibana 自带 Web 服 务,可以快速启动运行。
- 可视化多数据源。Kibana 可以非常方便地把来自 Logstash、ES-Hadoop、Beats 或第三方技术的数据整合到 Elasticsearch,支持的第三方技术包括 Apache Flume、Fluentd 等。
- 简单数据导出。Kibana 可以方便地导出感兴趣的数据,与其他数据整合并融合后快速建模分析,发现新结果。
1.3、案例环境
1)本案例环境
本案例环境如下表所示。准备三台虚拟机,分别根据下表配置网络参数,关闭防火墙和 Selinux。其中 Node1 节点和 Node2 节点分配 4GB(>2GB)内存,Apache 节点分配 1GB 内存。各节点通过 VMware 虚拟网络 Vmnet8 连接。
| 主机 | 操作系统 | 主机名 / IP地址 | 主要软件 |
| 服务器 | CentOS 7.6 | node1 / 192.168.23.213 | Elasticsearch、Kibana |
| 服务器 | CentOS 7.6 | node2 / 192.168.23.214 | Elasticsearch |
| 服务器 | CentOS 7.6 | Apache / 192.168.23.215 | Apache |
2) 案例拓扑
本案例用到的 RPM 包以及源码包都是相对较新的版本,用户可以自行去官网下载最新版本,但不同版本之间在配置上有些许差异。建议使用相同版本实施该案例。
创建如下图所示的案例环境,其中包含两个 Elasticsearch 节点,用来监控 Apache 服务器日志。
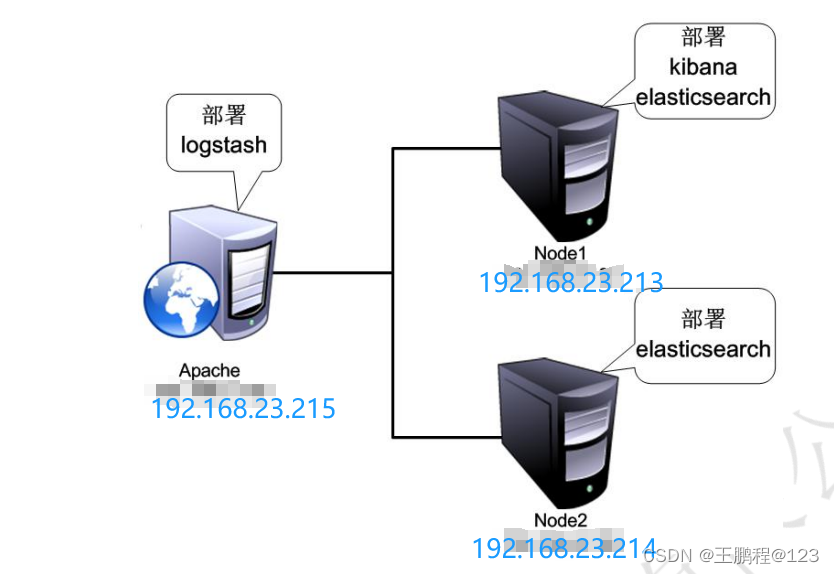 案例拓扑图
案例拓扑图
3)案例需求
- 配置 ELK 日志分析群集。
- 使用 Logstash 收集日志。
- 使用 Kibana 查看分析日志。
4)问题分析
创建多台 Elasticsearch 节点的目的是存放数据的多个副本。在实际生产环境中,节点的数量可能更多。在本案例中,Elasticsearch 和 Kibana 集中部署在 Node1 节点上。当然 Elasticsearch 和 Kibana 也可以采用分布式部署,即 Logstash、Elasticsearch 和 Kibana 分 别部署在不同的服务器中。
二、案例实施
2.1、环境准备
在两个 ELK 节点上配置域名解析,通过本地/etc/hosts 文件实现。node1 上的配置如下所示。
[root@node1 ~]# hostname
node1
[root@node1 ~]# vim /etc/hosts
......//省略部分内容
192.168.23.213 node1
192.168.23.214 node2
Node2 上的配置如下所示。
[root@node2 ~]# hostname
node2
[root@node2 ~]# vim /etc/hosts
......//省略部分内容
192.168.23.213 node1
192.168.23.214 node2安装 Java
node1 配置如下。
[root@node1 ~]# yum -y install java-1.8.0
[root@node1 ~]# java -version
openjdk version "1.8.0_402"
OpenJDK Runtime Environment (build 1.8.0_402-b06)
OpenJDK 64-Bit Server VM (build 25.402-b06, mixed mode)node2 配置如下。
[root@node2 ~]# yum -y install java-1.8.0
[root@node2 ~]# java -version
openjdk version "1.8.0_402"
OpenJDK Runtime Environment (build 1.8.0_402-b06)
OpenJDK 64-Bit Server VM (build 25.402-b06, mixed mode)2.2、部署 Elasticsearch 软件
在 node1 和 node2 节点上都需要部署 Elasticsearch 软件,下面以 node1 节点为例进行讲解,node2 节点的配置与 node1 节点相同。
1)安装 Elasticsearch 软件
Elasticsearch 软件可以通过 RPM 安装、YUM 安装或者源码包安装,生产环境中用户可以根据实际情况进行安装方式的选择。本章将通过 RPM 进行安装。
[root@node1 ~]# rpm -ivh elasticsearch-5.5.0.rpm
警告:elasticsearch-5.5.0.rpm: 头V4 RSA/SHA512 Signature, 密钥 ID d88e42b4: NOKEY
准备中... ################################# [100%]
Creating elasticsearch group... OK
Creating elasticsearch user... OK
正在升级/安装...
1:elasticsearch-0:5.5.0-1 ################################# [100%]
### NOT starting on installation, please execute the following statements to configure elasticsearch service to start automatically using systemd
sudo systemctl daemon-reload
sudo systemctl enable elasticsearch.service
### You can start elasticsearch service by executing
sudo systemctl start elasticsearch.service
2)加载系统服务
执行加载系统服务的命令如下:
[root@node1 ~]# systemctl daemon-reload
[root@node1 ~]# systemctl enable elasticsearch
Created symlink from /etc/systemd/system/multi-user.target.wants/elasticsearch.service to /usr/lib/systemd/system/elasticsearch.service.3)更改 Elasticsearch 主配置文件
[root@node1 ~]# grep -v "^#" /etc/elasticsearch/elasticsearch.yml
cluster.name: my-elk-cluster //群集名字
node.name: node1 //节点名字
path.data: /data/elk_data //数据存放路径
path.logs: /var/log/elasticsearch/ //日志存放路径
bootstrap.memory_lock: false //在启动的时候不锁定内存
network.host: 0.0.0.0 //提供服务绑定的 IP 地址,0.0.0.0 代表所有地址
http.port: 9200 //侦听端口为 9200
discovery.zen.ping.unicast.hosts: ["node1", "node2"] //群集发现通过单播实现
4) 创建数据存放路径并授权
创建数据存放路径并授权的命令如下:
[root@node1 ~]# mkdir -p /data/elk_data
[root@node1 ~]# chown elasticsearch:elasticsearch /data/elk_data/
5)启动 Elasticsearch
启动时间稍长,约 30 秒左右
[root@node1 ~]# systemctl start elasticsearch
[root@node1 ~]# ss -anpt | grep 9200
LISTEN 0 128 [::]:9200 [::]:* users:(("java",pid=1482,fd=135))
6)查看节点信息
在宿主机上,打开 Web 链接 http://192.168.23.213:9200,可以查看节点 node1 的信息,如下图所示。
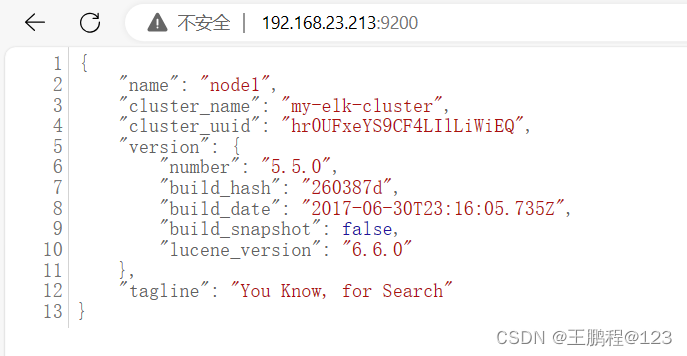
查看节点 node1 信息
在宿主机上,打开 Web 链接 http://192.168.23.214:9200,可以查看节点 node2 的信息,如下图所示。
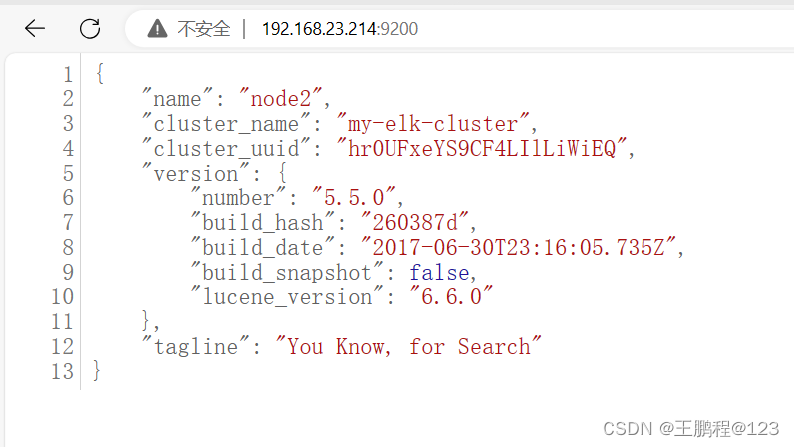 查看节点 node1 信息
查看节点 node1 信息
通过在浏览器中输入 http://192.168.23.213:9200/_cluster/health?pretty 查看群集的健康情况,可以看到 status 值为 green(绿色),表示节点健康运行,如下图所示 。
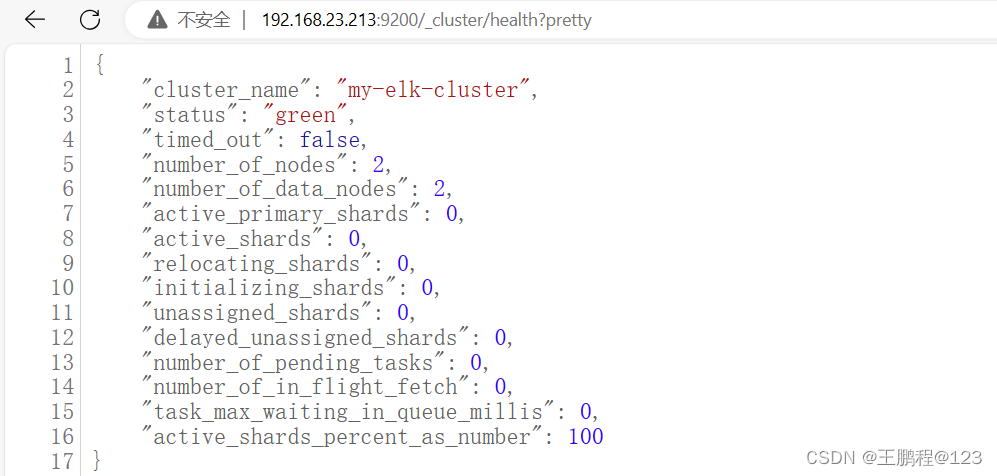
查看群集的健康情况
通过在浏览器中输入 http://192.168.23.213:9200/_cluster/state?pretty 查看群集的状态信息,如下图所示。
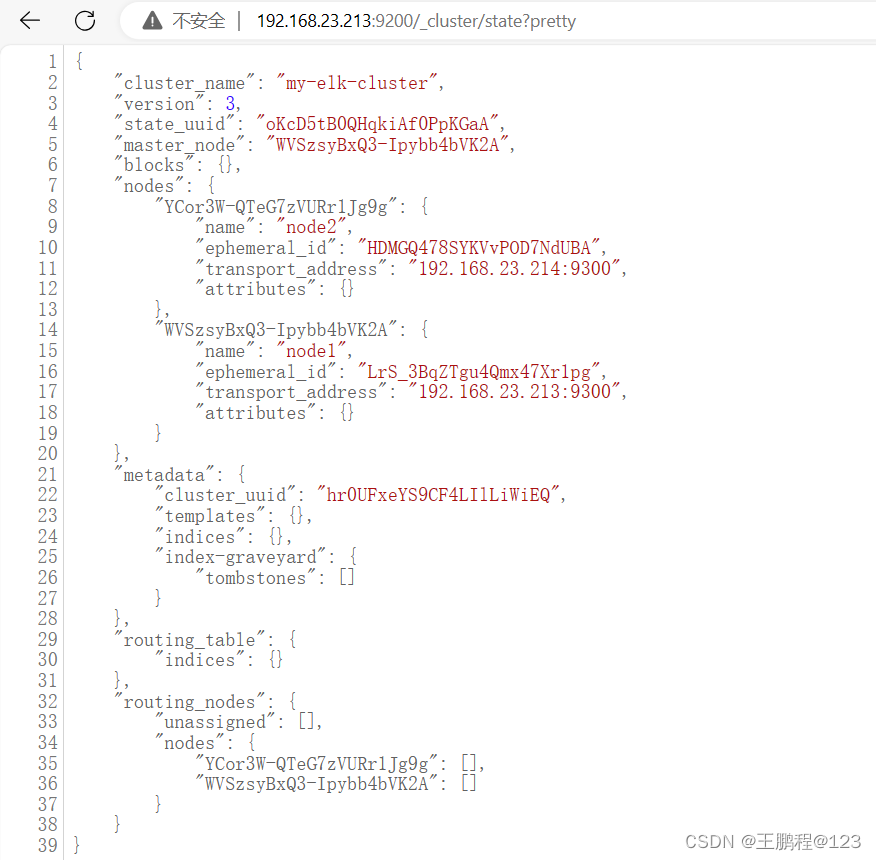
查看群集的状态信息
使用上述方式查看群集的状态对用户并不友好,可以通过安装 Elasticsearch-head 插件, 可以更方便地管理群集。
2.3、安装 Elasticsearch-head 插件
Elasticsearch 在 5.0 版本后,Elasticsearch-head 插件需要作为独立服务进行安装,需要 npm 命令。安装 Elasticsearch-head 需要提前安装 node 和 phantomjs。其中,前者是一 个基于 Chrome V8 引擎的 JavaScript 运行环境,而 phantomjs 是一个基于 webkit 的 JavaScriptAPI,可以理解为一个隐形的浏览器,任何基于 webkit 浏览器做的事情,它都可以做到。
下面是安装 Elasticsearch-head 插件的步骤
以下在 node1 上面操作
1)编译安装 node
编译安装 node 耗时较长,大约 40min,根据机器的配置可能略有不同,请耐心等待。
[root@node1 ~]# tar zxf node-v8.2.1.tar.gz -C /usr/src/ //解压后的目录不能有中文路径
[root@node1 ~]# cd /usr/src/node-v8.2.1/
[root@node1 node-v8.2.1]# ./configure
[root@node1 node-v8.2.1]# make //此步骤约 40 分钟
[root@node1 node-v8.2.1]# make install
2)安装 phantomjs
安装 phantomjs 的命令如下:
[root@node1 ~]# tar xjf phantomjs-2.1.1-linux-x86_64.tar.bz2 -C /usr/src/
[root@node1 ~]# cd /usr/src/phantomjs-2.1.1-linux-x86_64/bin/
[root@node1 bin]# cp phantomjs /usr/local/bin/
3)安装 Elasticsearch-head
安装 Elasticsearch-head 的命令如下:
[root@node1 ~]# tar zxf elasticsearch-head.tar.gz -C /usr/src/
[root@node1 ~]# cd /usr/src/elasticsearch-head/
[root@node1 elasticsearch-head]# npm install //安装依赖包
npm WARN optional SKIPPING OPTIONAL DEPENDENCY: fsevents@^1.0.0 (node_modules/karma/node_modules/chokidar/node_modules/fsevents):
npm WARN network SKIPPING OPTIONAL DEPENDENCY: request to https://registry.npmjs.org/fsevents failed, reason: getaddrinfo ENOTFOUND registry.npmjs.org registry.npmjs.org:443
npm WARN elasticsearch-head@0.0.0 license should be a valid SPDX license expression
up to date in 15.685s
4)修改 Elasticsearch 主配置文件
修改 Elasticsearch 主配置文件的命令如下:
[root@node1 ~]# vim /etc/elasticsearch/elasticsearch.yml
......//省略部分内容
# Require explicit names when deleting indices:
#
#action.destructive_requires_name: true
http.cors.enabled: true //开启跨域访问支持,默认为 false
http.cors.allow-origin: "*" //跨域访问允许的域名地址
[root@node1 ~]# systemctl restart elasticsearch //重启服务
5)启动服务
必须在解压后的 elasticsearch-head 目录下启动服务,进程会读取该目录下的 gruntfile.js 文件,否则可能启动失败。elasticsearch-head 监听的端口是 9100,通过该端口是否监听来判断服务是否正常开启。
[root@node1 ~]# cd /usr/src/elasticsearch-head/
[root@node1 elasticsearch-head]# npm run start & //前台启动,一旦关闭中断,服务也将随之关闭
[1] 61584
[root@node1 elasticsearch-head]#
> elasticsearch-head@0.0.0 start /usr/src/elasticsearch-head
> grunt server
Running "connect:server" (connect) task
Waiting forever...
Started connect web server on http://localhost:9100
[root@node1 elasticsearch-head]# ss -anpt | grep 9100
LISTEN 0 128 *:9100 *:* users:(("grunt",pid=61594,fd=12))
[root@node1 elasticsearch-head]# ss -anpt | grep 9200
LISTEN 0 128 [::]:9200 [::]:* users:(("java",pid=61513,fd=161))
6)通过 Elasticsearch-head 查看 Elasticsearch 信息
通过浏览器访问 http://192.168.23.213:9100/地址并连接群集。可以看到群集很健康,健康值为 green 绿色,如下图所示。
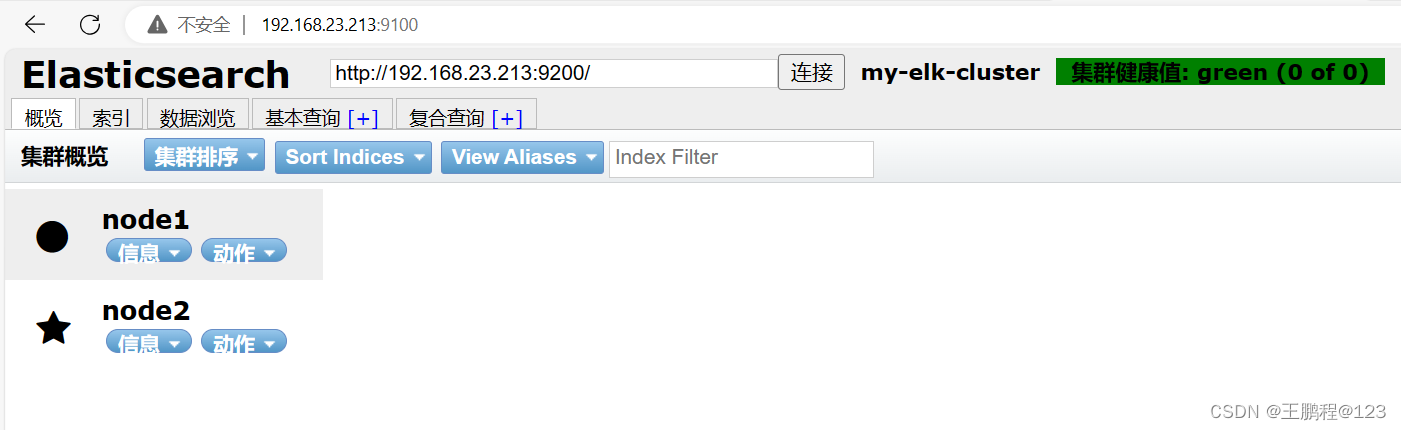
查看群集信息
2.4、Logstash 安装及使用方法
Logstash 一般部署在需要监控其日志的服务器。在本案例中,Logstash 部署在 Apache 服务器上,用于收集 Apache 服务器的日志信息并发送到 Elasticsearch。在正式部署之前, 先在 node1 上部署 Logstash,以熟悉 Logstash 的使用方法。Logstash 也需要 Java 环境, 所以安装之前也要检查当前机器的 Java 环境是否存在。
按下面的步骤完成 Logstash 的安装和使用。
1)在 node1 上安装 Logstash。
安装 Logstash 的命令如下所示:
[root@node1 ~]# rpm -ivh logstash-5.5.1.rpm
警告:logstash-5.5.1.rpm: 头V4 RSA/SHA512 Signature, 密钥 ID d88e42b4: NOKEY
准备中... ################################# [100%]
正在升级/安装...
1:logstash-1:5.5.1-1 ################################# [100%]
Using provided startup.options file: /etc/logstash/startup.options
Successfully created system startup script for Logstash
[root@node1 ~]# systemctl start logstash
[root@node1 ~]# ln -s /usr/share/logstash/bin/logstash /usr/local/bin/
2)Logstash 配置文件
Logstash 配置文件基本由三部分组成:input、output 以及 filter(根据需要)。因此标准的配置文件格式如下所示。
在每个部分中,也可以指定多个访问方式。例如,若要指定两个日志来源文件,则格式如下所示。
下面通过修改 Logstash 配置文件,让其收集系统日志/var/log/messages,并将其输出到 elasticsearch 中。
[root@node1 ~]# chmod o+r /var/log/messages //让 Logstash 可以读取日志
[root@node1 ~]# ll /var/log/messages
-rw----r--. 1 root root 440040 4月 6 13:40 /var/log/messages
[root@node1 ~]# touch /etc/logstash/conf.d/system.conf
[root@node1 ~]# vim /etc/logstash/conf.d/system.conf
input {
file {
path => "/var/log/messages"
type => "system"
start_position => "beginning"
}
}
output {
elasticsearch {
hosts => ["192.168.23.213:9200"]
index => "system-%{+YYYY.MM.dd}"
}
}
[root@node1 ~]# systemctl restart logstash //重启 logstash 服务
[root@node1 ~]# logstash -f /etc/logstash/conf.d/system.conf完成后,通过浏览器查看 Elasticsearch 的信息,如下图所示。
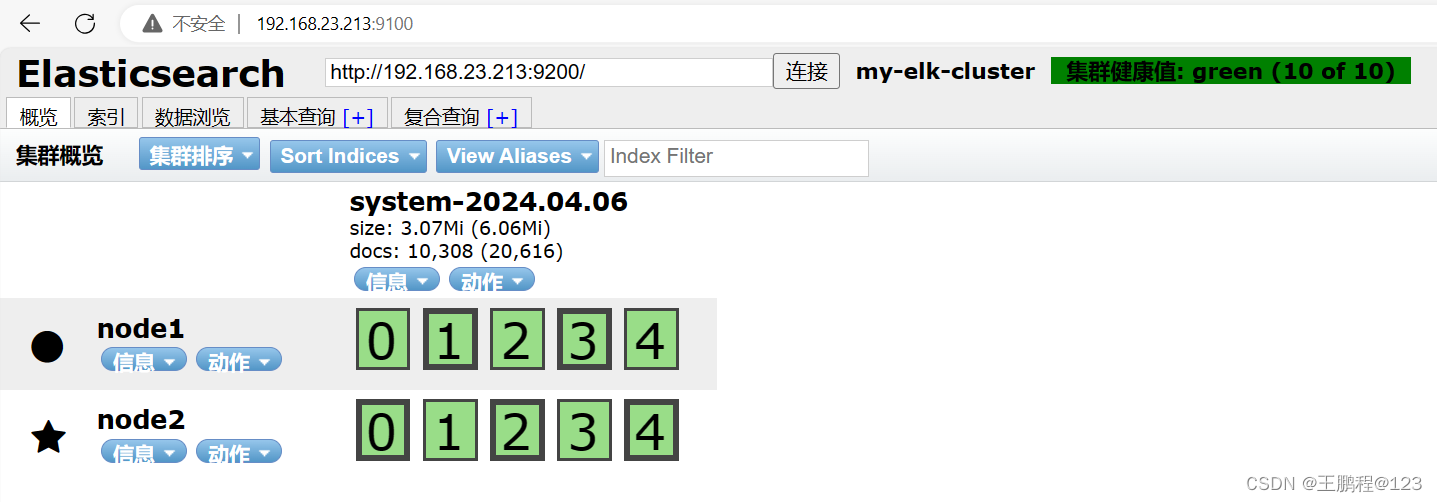
查看 Elasticsearch 信息
查看索引下的日志信息,如下图所示
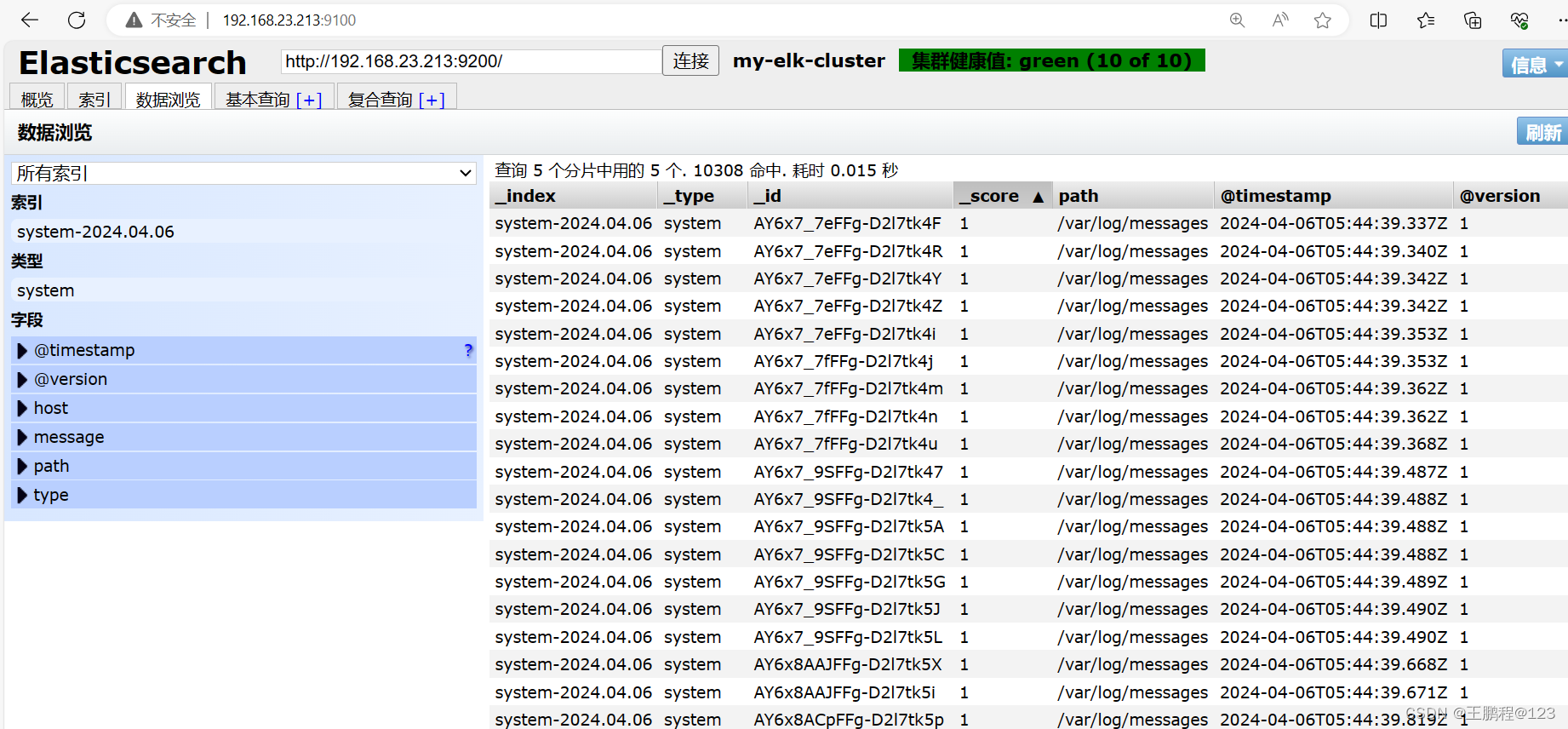 查看索引下的日志信息
查看索引下的日志信息
2.5、安装 Kibana
下面是安装 Kibana 的步骤
1)在 node1 服务器上安装 kibana,并设置开机启动。
安装 Kibana 的命令如下:
[root@node1 ~]# cd /usr/local/src/
[root@node1 src]# ls
kibana-5.5.1-x86_64.rpm
[root@node1 src]# rpm -ivh kibana-5.5.1-x86_64.rpm
警告:kibana-5.5.1-x86_64.rpm: 头V4 RSA/SHA512 Signature, 密钥 ID d88e42b4: NOKEY
准备中... ################################# [100%]
正在升级/安装...
1:kibana-5.5.1-1 ################################# [100%]
[root@node1 src]# systemctl enable kibana
Created symlink from /etc/systemd/system/multi-user.target.wants/kibana.service to /etc/systemd/system/kibana.service.
2)设置 Kibana 的主配置文件/etc/kibana/kibana.yml。
在主配置文件/etc/kibana/kibana.yml 中设置 Kibana 的命令如下:
[root@node1 src]# vim /etc/kibana/kibana.yml
[root@node1 src]# grep -v "^#" /etc/kibana/kibana.yml | grep -v "^$"
server.port: 5601 //kibana 打开的端口
server.host: "0.0.0.0" //kibana 侦听的地址
elasticsearch.url: "http://192.168.23.213:9200" //和 Elasticsearch 建立连接的地址
kibana.index: ".kibana" //在 Elasticsearch 中添加 .kibana 索引3)启动 kibana 服务
使用如下命令启动 Kibana 服务:
[root@node1 src]# systemctl start kibana
4)验证 kibana
通过浏览器访问 http://192.168.23.213:5601,第一次登录需要添加一个 Elasticsearch 索引,添加前面创建的索引 system-2017.09.11,如下图所示。
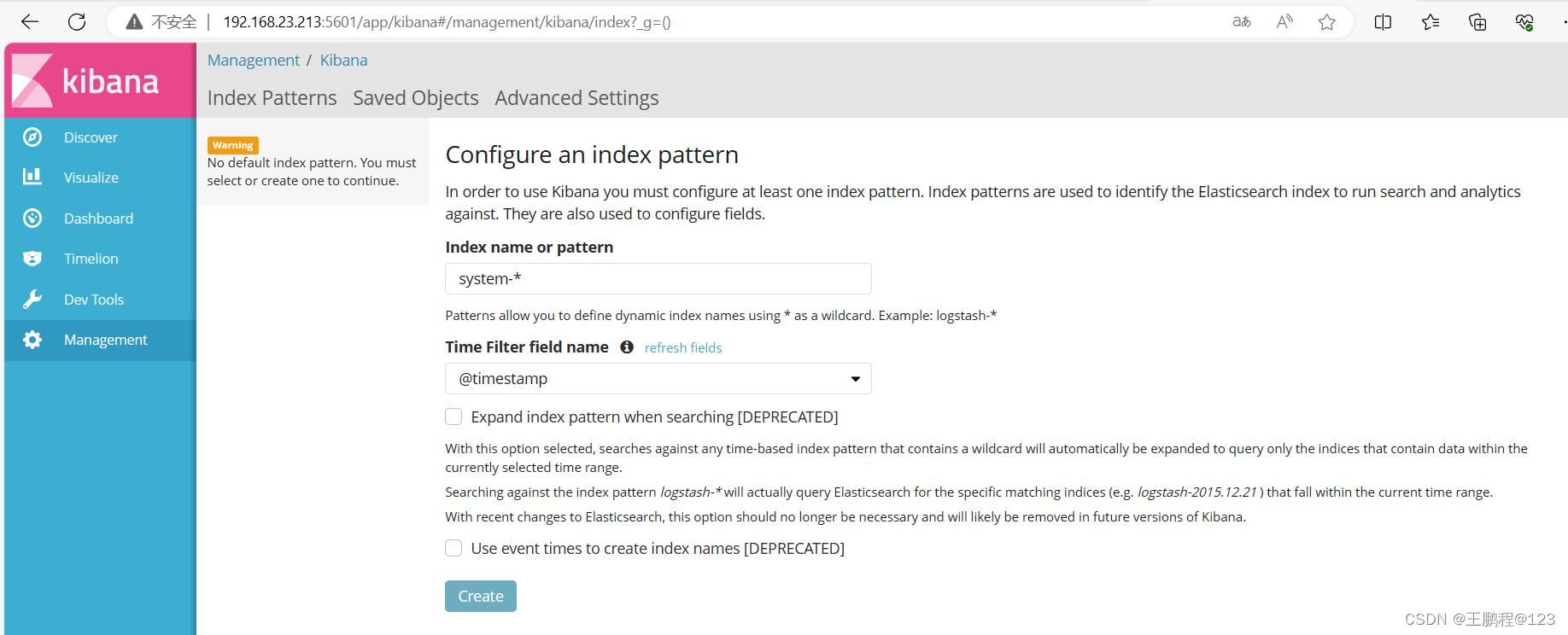
添加索引
查看索引的默认字段,如下图所示。
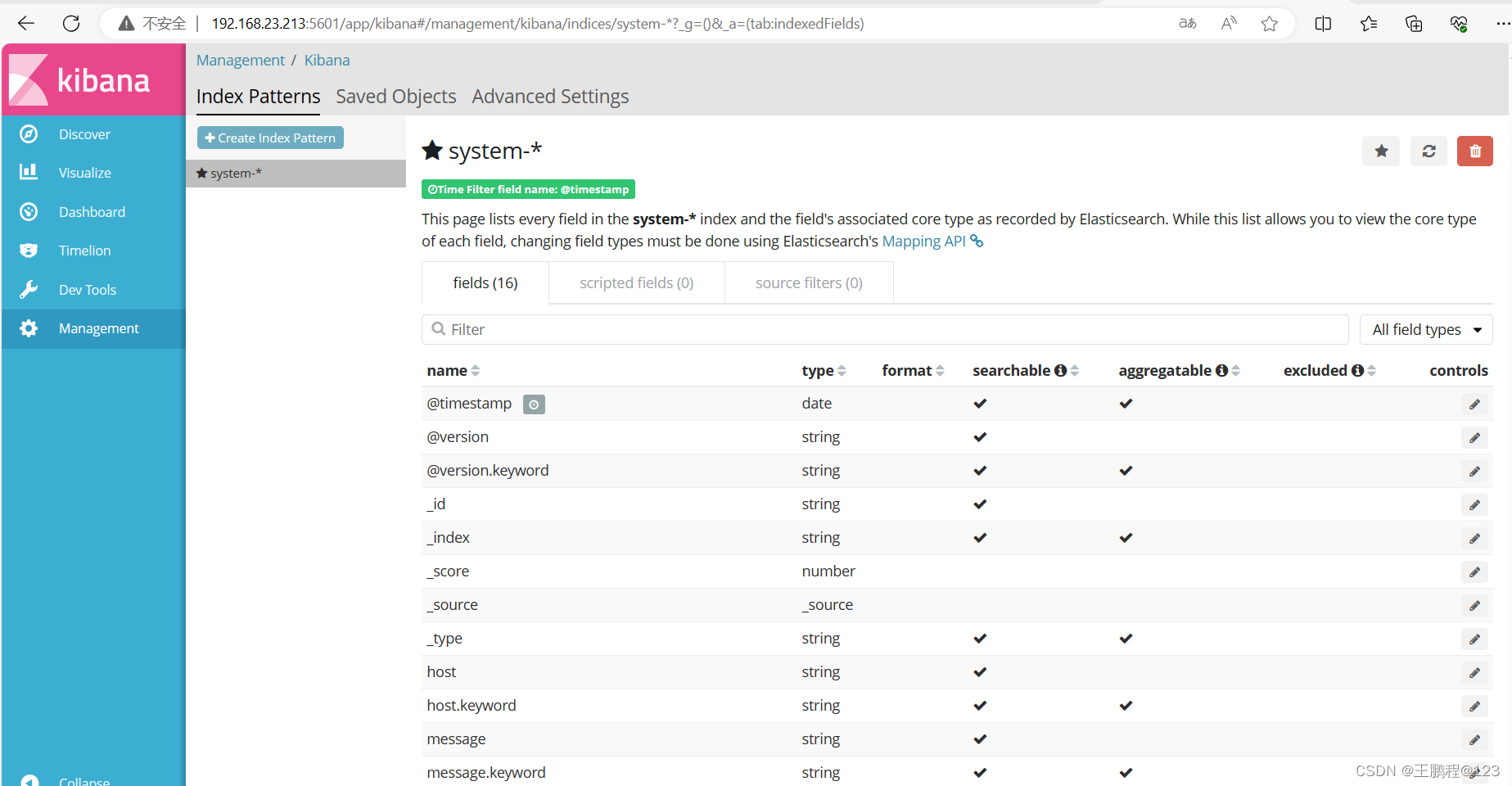 查看索引的默认字段
查看索引的默认字段
单击“Discover”按钮查看图表信息及日志信息,如下图所示
查看图表信息及日志信息
数据展示可以分类显示,使鼠标指针悬停在“Available Fields”中的“host”, 然后单击 “add”按钮,可以看到按照“host”筛选后的结果,如下图所示
 分类显示结果
分类显示结果
5)配置 Apache 服务器,将 Apache 服务器的日志添加到 Elasticsearch 并通过 kibana 显示。
[root@apache ~]# yum -y install httpd java-1.8.0
[root@apache ~]# systemctl start httpd
[root@apache ~]# systemctl enable httpd
Created symlink from /etc/systemd/system/multi-user.target.wants/httpd.service to /usr/lib/systemd/system/httpd.service.
[root@apache ~]# java -version
openjdk version "1.8.0_402"
OpenJDK Runtime Environment (build 1.8.0_402-b06)
OpenJDK 64-Bit Server VM (build 25.402-b06, mixed mode)
在 Apache 服务器上安装 Logstash,以便将收集的日志发送到 Elasticsearch 中。
[root@apache ~]# systemctl daemon-reload
[root@apache ~]# systemctl enable logstash
Created symlink from /etc/systemd/system/multi-user.target.wants/logstash.service to /etc/systemd/system/logstash.service.编写 Logstash 配置文件 apache_log.conf 如下所示。
[root@apache ~]# cd /etc/logstash/conf.d/
[root@apache conf.d]# touch apache_log.conf
[root@apache conf.d]# vim apache_log.conf
input {
file {
path => "/etc/httpd/logs/access_log" //收集 Apache 访问日志
type => "access" //类型指定为 access
start_position => "beginning" //从开始处收集
}
file {
path => "/etc/httpd/logs/error_log" //收集 Apache 错误日志
type => "error" //类型指定为 error
start_position => "beginning" //从开始处收集
}
}
output {
if [type] == "access" { //如果类型为 access,即 Apache 访问日志
elasticsearch { //输出到elasticsearch
hosts => ["192.168.23.213:9200"] //elasticsearch 监听地址及端口
index => "apache_access-%{+YYYY.MM.dd}" //指定索引格式
}
}
if [type] == "error" { //如果类型为 error,即 Apache 错误日志
elasticsearch { //输出到 elasticsearch
hosts => ["192.168.23.213:9200"] //elasticsearch 监听地址及端口
index => "apache_error-%{+YYYY.MM.dd}" //指定索引格式
}
}
}
[root@apache conf.d]# /usr/share/logstash/bin/logstash -f apache_log.conf
通过浏览器访问 http://192.168.23.213:9100 查看索引是否创建,如下图所示。
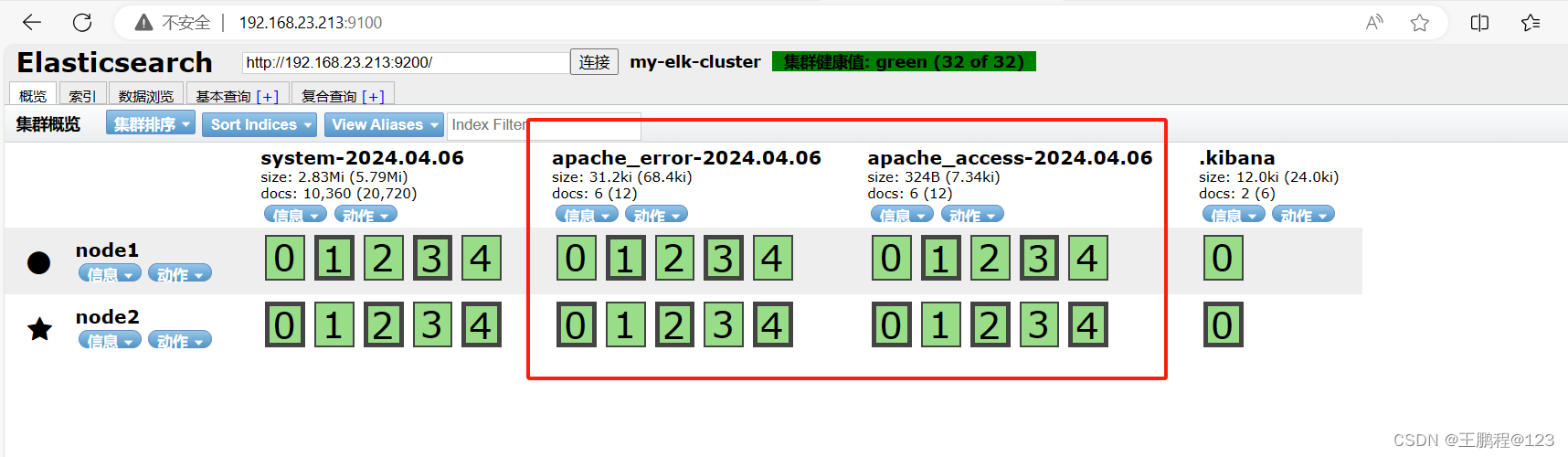 查看是否创建索引
查看是否创建索引
登录 Kibana,单击“Create Index Pattern”按钮添加索引,如下图所示
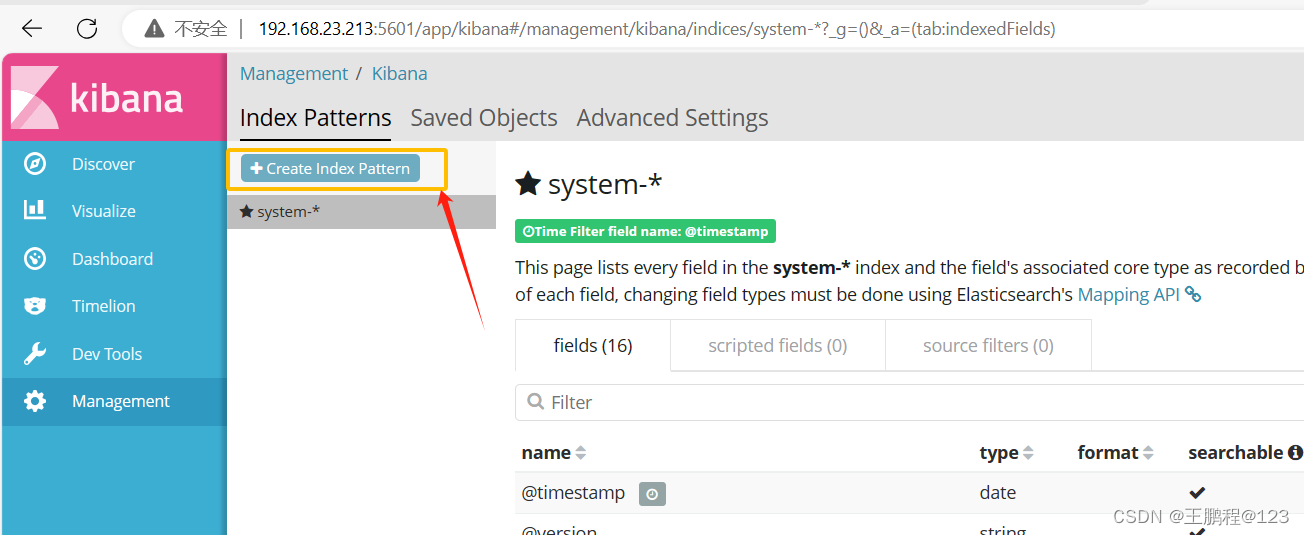
添加索引
在索引名中输入之前配置的 Output 前缀“apache_access”,并单击“Create”按钮,如下图所示。
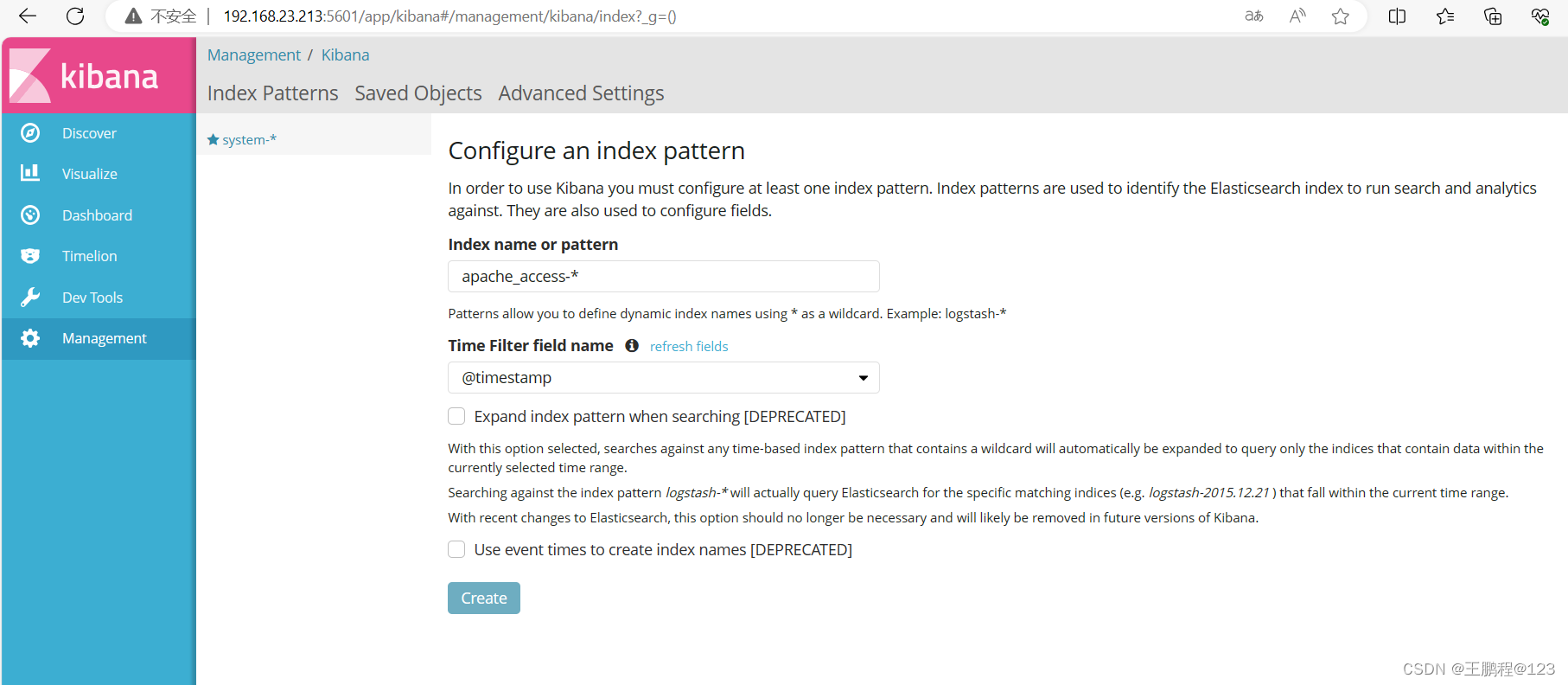 添加索引字段
添加索引字段
用相同的方法添加 apache_error-*索引,如下图所示
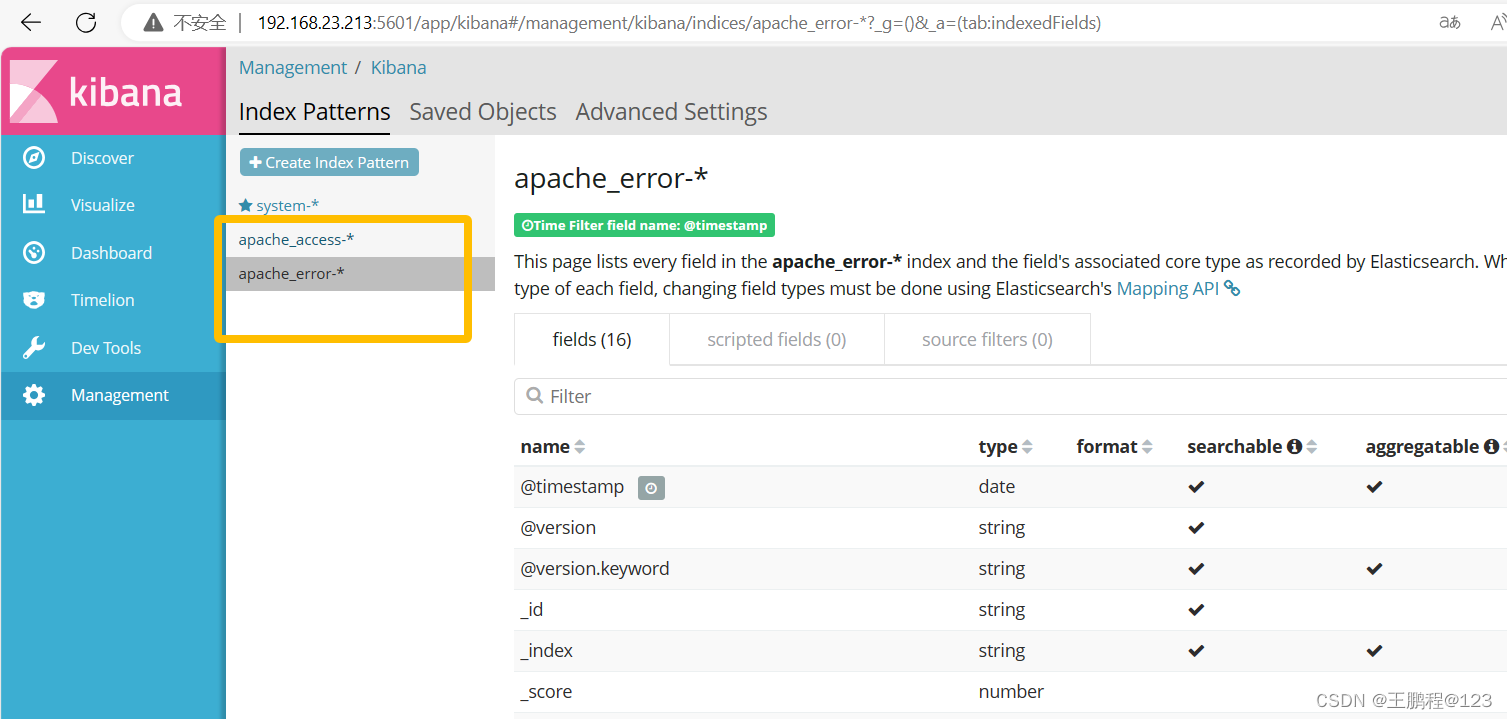 添加apache_error-*索引
添加apache_error-*索引
选择“Discover”选项卡,在中间下拉列表中选择刚添加的 apache_access-*索引,可以查看相应的图表及日志信息,还可以根据 Fields 进行归类显示,如下图所示。
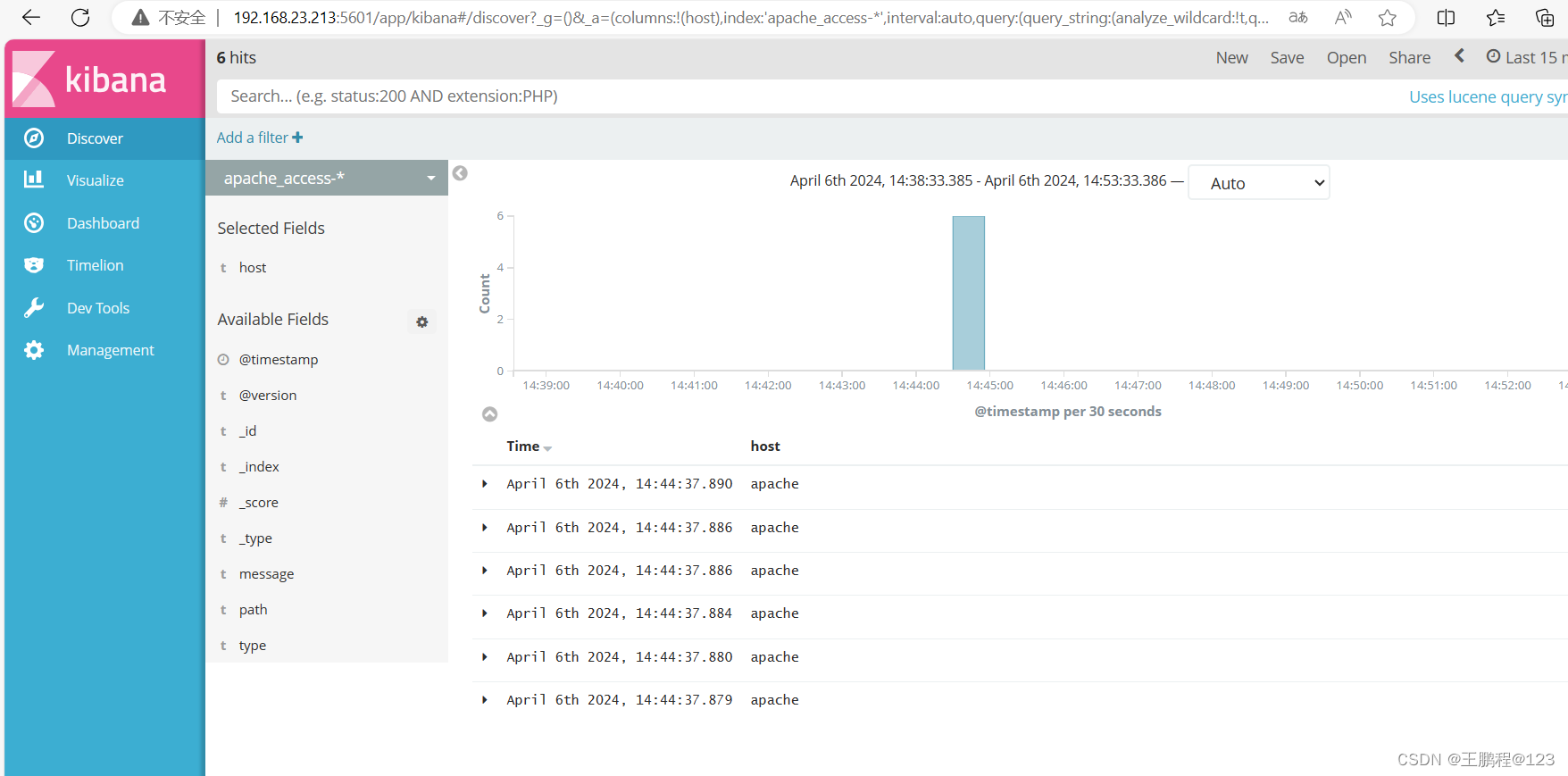 根据 Fields 进行归类
根据 Fields 进行归类










