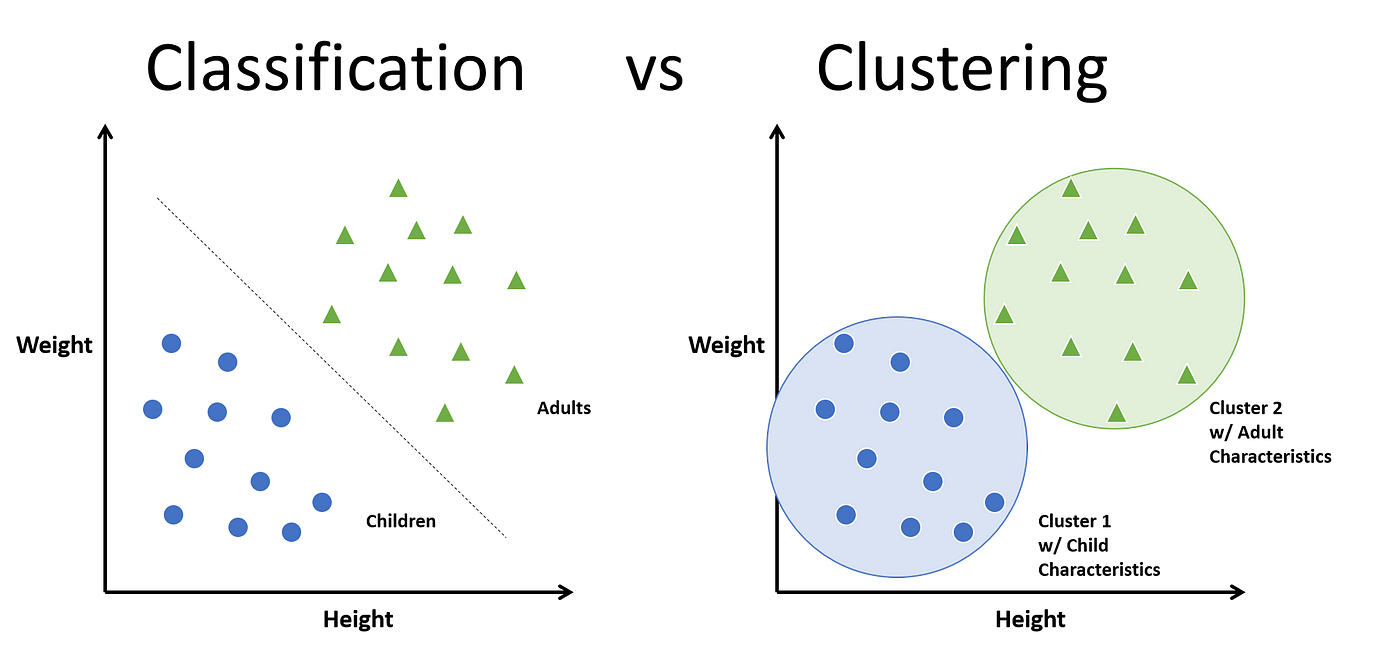
聚类和分类是两种不同的机器学习方法,它们在处理数据时有着不同的目的和应用场景。
-
分类:分类是一种监督学习方法,它需要已标记的训练数据集。在分类中,算法会学习如何将输入数据映射到预定义的类别中。例如,给定一组包含猫和狗图片的数据集,分类算法可以学习如何将新的图片分为猫和狗两类。
-
聚类:聚类是一种无监督学习方法,它不需要预先标记的训练数据集。聚类算法会将数据集中的样本划分为若干个组或簇,使得同一簇内的样本相似度高,而不同簇之间的样本相似度低。聚类的目标是发现数据中的内在结构,并将相似的样本归为一类,而不需要事先知道类别标签。
- 分类适用于有明确类别标签的数据集,目标是预测新数据的类别。
- 聚类适用于无标签数据或者探索性分析,目标是发现数据中的内在结构或者将相似的数据聚集在一起。
总结
聚类并不能完全代替分类。虽然聚类和分类都是数据挖掘和机器学习中常用的技术,但它们有着各自的特点和适用场景。
聚类是一种无监督学习方法,它根据数据的内在结构和相似性将数据划分为不同的组或簇。聚类的目的是发现数据中的隐藏模式或结构,而不需要预先定义类别标签。聚类方法通常基于距离、密度或其他相似性度量来划分数据。
分类则是一种有监督学习方法,它使用带有标签的训练数据集来训练模型,以便将新数据分配到预定义的类别中。分类方法需要已知一定数量的样本及其对应的类别标签,通过学习这些样本的特征和标签之间的关系来建立分类模型。
虽然聚类可以在一定程度上揭示数据的结构和关系,但它无法提供明确的类别标签。聚类结果通常是一组没有具体含义的簇,需要后续的解释和分析才能理解其含义。相比之下,分类方法可以直接输出数据的类别标签,更适用于需要明确分类结果的场景。
此外,聚类和分类在处理复杂和大规模数据集时也可能存在不同的挑战。聚类算法可能需要处理高维数据、噪声数据或不同密度的簇,而分类算法则需要处理不平衡类别、噪声标签或高度复杂的类别边界等问题。
因此,聚类和分类是互补而非替代的关系。在实际应用中,可以根据问题的具体需求和数据的特点选择合适的方法。有时,聚类可以作为分类的预处理步骤,用于发现数据的潜在结构和特征;有时,分类可以用于验证聚类的结果,将簇与已知类别进行比较。









