文章目录
【原文链接】: BERT: Pre-training of Deep Bidirectional Transformers for
Language Understanding
【本文参考链接】
- The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning)
- 【NLP从入门到大模型】5.图解Bert
【其他值得关注的预训练+微调范式模型】
- 【深度学习】GPT-1
- GPT系列:GPT-2详解
- RoBERTa 详解(Bert改进模型)
- XLNet模型(Bert改进模型)
- ALBert 详解(Bert改进模型)
OpenAI Transformer
OpenAI Transformer(OpenAI的Transformer模型)是在2017年底提出的。它是由OpenAI团队提出的一种基于Transformer架构的语言模型,用于处理自然语言处理任务。OpenAI Transformer是一个堆叠的12层Decoder结构(Decoder-Only),在解码器的注意力模块中,由于没有Encoder,所以就不是Cross-Attention,改为self-attention+mask的方式。

整个训练过程是无监督的,使用大量的未标记数据集训练,将预测下一个词汇作为模型的预测目标。然后预训练好的Transformer结构(Decoder-Only)后面再加上简单的网络结构进行参数调整,并设定目标场景的预测结果,就实现了通过微调去适应下游任务。

ELMo
ELMo(Embedding for Language Model)是由斯坦福大学的研究团队在2018年提出的,是一种基于双向 LSTM(长短期记忆)模型的语言表示方法,通过在大规模语料库上训练的双向 LSTM 模型来生成深度上下文相关的词向量。
大语言模型通过海量数据训练出来的Tokenizer可直接用于文本向量化,开源的大模型Tokenizer使得大家能通过下载已经开源的词嵌入模型来完成NLP的任务。Word2vec是将单词固定为指定长度的向量,和以往的经典词嵌入模型不同的是,ELMo则是在为每个单词分配词向量之前先查看整个句子,然后使用bi-LSTM结合上下文语境来训练它对应的词向量。

ELMo会训练一个模型,这个模型接受一个句子或者单词的输入,输出最有可能出现在后面的一个单词,采用海量语料进行无监督训练。ELMo通过下图的方式将hidden states的状态组合起来提炼出具有语境意义的词嵌入方式(全连接后加权求和)。
ULM-FiT
ULM-FiT(Universal Language Model Fine-tuning)是一种用于迁移学习的技术,由 Jeremy Howard 和 Sebastian Ruder 在2018年提出。它基于递归神经网络(RNN)构建的语言模型,并使用了一系列创新的技术来提高迁移学习的效果。
ULM-FiT 的核心思想是首先在大规模的通用语料库上训练一个通用的语言模型,然后通过微调(Fine-tuning)的方式,将这个通用模型应用于特定的任务。具体来说,ULM-FiT 包含以下几个关键步骤:
预训练通用语言模型:首先,在大规模的通用语料库上训练一个通用的语言模型,比如基于AWD-LSTM(ASGD Weight-Dropped LSTM)的语言模型。这个通用模型可以捕捉语言的一般规律和语义信息。
微调:接下来,将预训练的通用模型在特定任务的数据集上进行微调,以适应特定任务的语言模式和特征。微调的过程包括在任务数据上进行进一步的训练,并对模型进行调整以提高任务性能。
多阶段微调策略:ULM-FiT 提出了一种多阶段微调的策略,其中包括逐层解冻和差异学习率调整等技术,以提高微调的效果。这种策略可以使模型逐步适应新任务的特征,从而更好地利用预训练的知识。
ULM-FiT 已经在许多自然语言处理任务中取得了显著的成功,包括文本分类、命名实体识别、情感分析等。它的主要优势在于通过预训练通用模型和微调的方式,能够在少量标注数据的情况下快速有效地解决特定任务。
Bert

基础结构
Bert的基础架构是一个堆叠多层的Encoder架构,参数量更大的Bert就是对应的层数更多(如:Bert-base有12层Encoder,Bert-Large共24层Encoder),Bert就是一种Encoder-Only的架构。
BERT与Transformer 的编码方式一样。将固定长度的字符串作为输入,数据由下而上传递计算,每一层都用到了self attention,并通过前馈神经网络传递其结果,将其交给下一个编码器。
每个位置返回的输出都是一个隐藏层大小的向量(Base版本BERT为768),该输出向量可以作为下游微调任务的输入向量,在论文中指出使用单层神经网络作为分类器就可以取得很好的效果。
Embedding
BERT 模型中的词向量(Word Embedding)、位置编码(Positional Encoding)、以及段落编码(Segment Embedding)是通过一系列的处理步骤得到的:
- 词向量(Word Embedding):
BERT 使用了 WordPiece 或 Byte-Pair Encoding(BPE)等分词算法将输入文本序列分割成词语或子词(subwords)。然后,每个词语或子词都被映射为一个固定长度的向量,这个过程就是词向量。BERT 模型使用了多层的词向量表示,其中包括 WordPiece Embeddings 和 Token Type Embeddings。WordPiece Embeddings 将每个词语或子词映射为一个固定长度的向量,而 Token Type Embeddings 用于区分不同句子之间的关系(同Transformer)。 - 位置编码(Positional Encoding):
在 BERT 模型中,位置编码用于向词向量中添加关于词语或子词在序列中位置的信息。BERT 使用了一种特殊的位置编码方法,通常是通过加法或者叠加来将位置编码添加到词向量中。这种位置编码能够为模型提供关于词语在序列中相对位置的信息,从而帮助模型理解文本的顺序关系(同Transformer)。 - 段落编码(Segment Embedding):
在一些需要处理多个句子的任务中,BERT 还会添加段落编码以区分不同句子之间的关系。段落编码通常是一个固定长度的向量,用于区分不同句子所属的段落或者句子之间的关系。在输入序列中,通过在句子的开头添加特殊的标记(比如 [CLS] 标记)来表示句子的开始,然后添加段落编码来区分不同句子之间的关系(如:第一个句子编码段落token全为0,第二个全为1)。
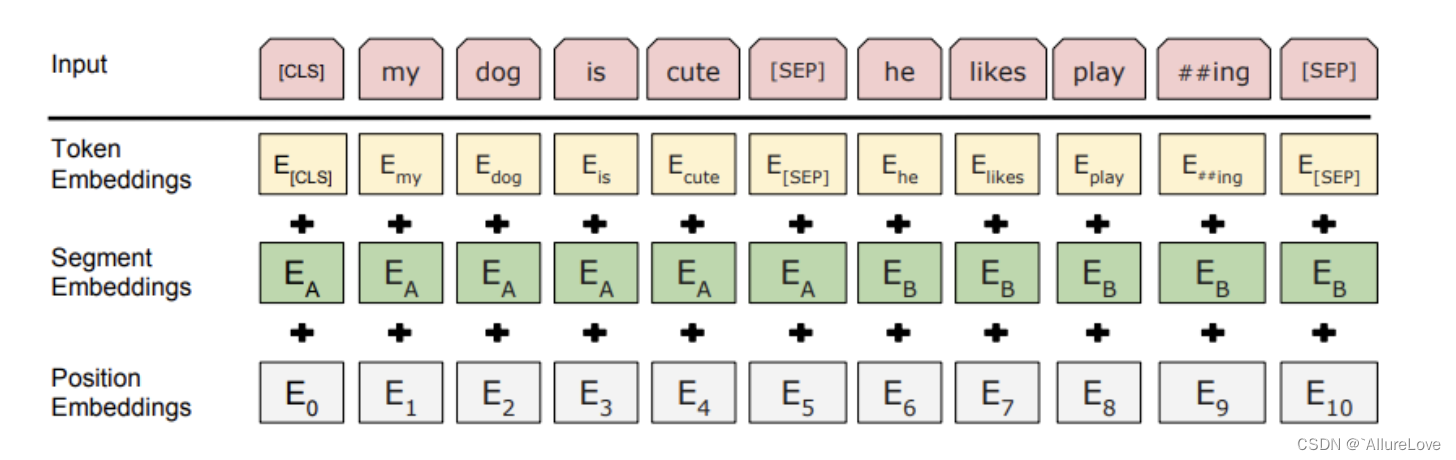
预训练&微调
前面有说过Bert的模式也是预训练+下游任务微调,如下图所示:
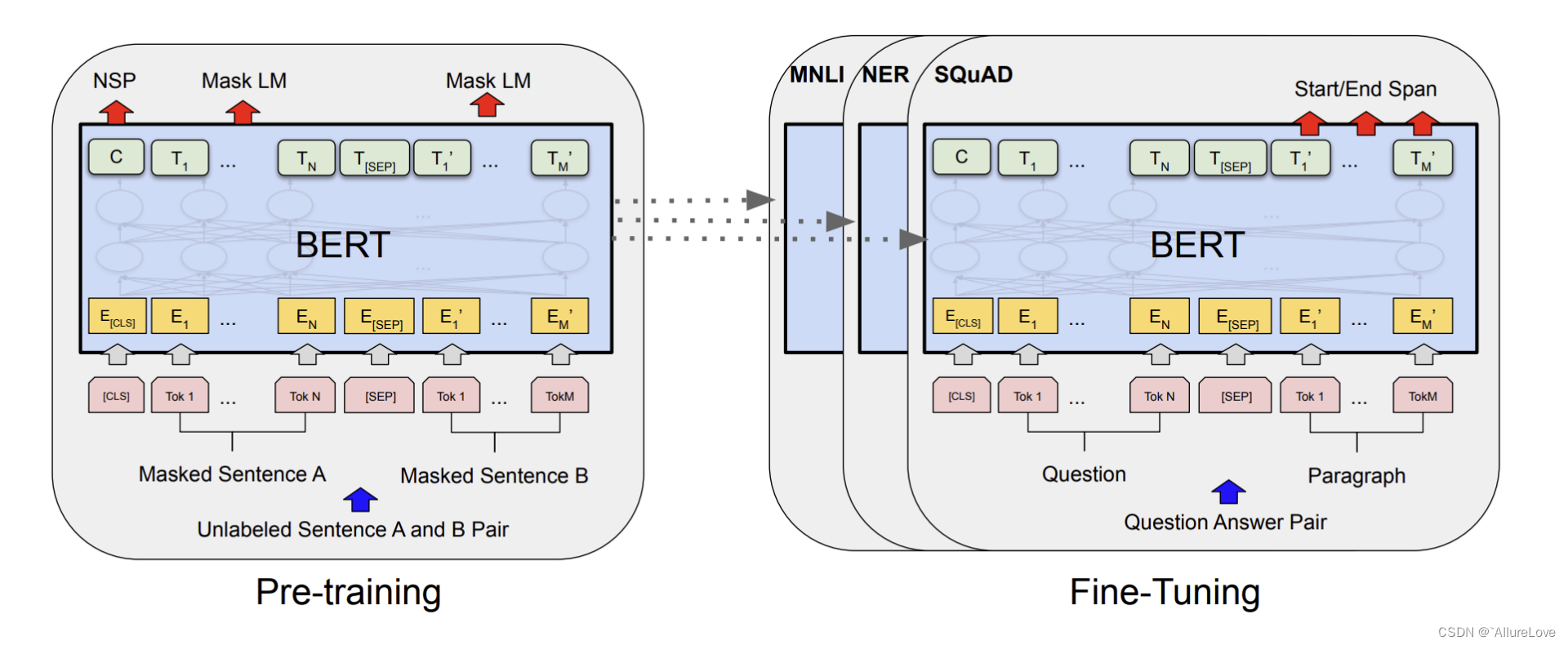
- 预训练
- Masked Language Modeling(MLM):通过随机掩盖序列中的一些token,让模型去预测被掩盖的token是什么。如在训练过程中随机mask 15%的token,其中80%的序列我们用[MASK]去取代要掩码的token,10%的序列我们将待掩码token随机替换为其他token,10%的序列保持不变,最终的损失函数只计算被mask掉的那个token。
- Next Sentence Prediction(NSP):让模型理解两个句子之间的联系。训练的输入是句子A和B,B有一半的几率是A的下一句,输入这两个句子,模型预测B是不是A的下一句。预训练的时候可以达到97-98%的准确度。
模型地址:https://huggingface.co/google-bert/bert-base-chinese
# 安装新版本(>=4.0)的transformer,内置bert
from transformers import AutoTokenizer, AutoModelForMaskedLM
# 加载Tokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-chinese")
# 加载模型
model = AutoModelForMaskedLM.from_pretrained("bert-base-chinese")
# MLM任务测试
# BERT 在预训练中引入了 [CLS] 和 [SEP] 标记句子的开头和结尾,准备输入模型的语句
text = '中国的首都是哪里? 北京是 [MASK] 国的首都。'
inputs = tokenizer(text, return_tensors='pt')
# 获取MASK的位置
mask_position = inputs["input_ids"].tolist()[0].index(tokenizer.mask_token_id)
print("tokenized txt: {}".format(inputs))
# 使用模型进行预测
with torch.no_grad():
outputs = bert_model(**inputs).logits
# 获取MASK位置的预测分数,并找到预测得分最高的token
predicted_token_idx = outputs[0, mask_position].argmax().item()
predicted_token = tokenizer.convert_ids_to_tokens([predicted_token_idx])[0]
print(f"The masked token in '{text}' is predicted as '{predicted_token}'")
# NSP任务测试
model_path = 'bert-base-chinese'
tokenizer = BertTokenizer.from_pretrained(model_path)
model = BertForNextSentencePrediction.from_pretrained(model_path)
sen_code1 = tokenizer.encode_plus('今天天气怎么样', '今天天气很好')
sen_code2 = tokenizer.encode_plus('小明今年几岁了', '今天天空很蓝')
tokens_tensor = torch.tensor([sen_code1['input_ids'], sen_code2['input_ids']])
model.eval()
outputs = model(tokens_tensor)
seq_relationship_scores = outputs[0] # seq_relationship_scores.shape= torch.Size([2, 2])
sample = seq_relationship_scores.detach().numpy() # sample.shape = (2, 2)
pred = np.argmax(sample, axis=1)
print(pred)
# [0 1] 0表示是上下句,1表示不是上下句
- 微调
Bert可以实现的几种微调任务:短文本相似 、文本分类、QA机器人、语义标注等微调任务,下面以一个任务为例:
# 下载文本分类数据集
wget http://github.com/skdjfla/toutiao-text-classfication-dataset/raw/master/toutiao_cat_data.txt.zip
import codecs
import json
import torch
from sklearn.model_selection import train_test_split
from torch.utils.data import Dataset, DataLoader
import numpy as np
from transformers import BertTokenizer
from transformers import BertForSequenceClassification, get_linear_schedule_with_warmup
class NewsDataset(Dataset):
"""
新闻分类数据集
"""
def __init__(self, encodings, labels):
self.encodings = encodings
self.labels = labels
# 读取单个样本
def __getitem__(self, idx):
item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
item['labels'] = torch.tensor(int(self.labels[idx]))
return item
def __len__(self):
return len(self.labels)
class NewsClassifier(object):
"""
新闻分类器
"""
@classmethod
def finetuning(cls):
"""
微调新闻分类器
"""
model_path = 'bert-base-chinese'
# 加载预训练的向量化模型
tokenizer = BertTokenizer.from_pretrained(model_path)
# 加载预训练的分类模型
model = BertForSequenceClassification.from_pretrained(model_path, num_labels=17)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# 加载数据集
train_dataset, test_dataset = cls.load_dataset(tokenizer)
# 单个读取到批量读取
train_loader = DataLoader(train_dataset, batch_size=16, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=16, shuffle=True)
# 优化方法
optim = torch.optim.AdamW(model.parameters(), lr=2e-5)
total_steps = len(train_loader) * 1
scheduler = get_linear_schedule_with_warmup(optim,
num_warmup_steps=0, # Default value in run_glue.py
num_training_steps=total_steps)
for epoch in range(1):
print("------------Epoch: %d ----------------" % epoch)
cls.train(model, train_loader, optim, device, scheduler, epoch)
cls.validation(model, test_dataloader, device)
model.save_pretrained("output/bert-news-clf")
tokenizer.save_vocabulary("output/bert-news-clf")
@classmethod
def train(cls, model, train_loader, optim, device, scheduler, epoch):
"""
训练函数
"""
model.train()
total_train_loss = 0
iter_num = 0
total_iter = len(train_loader)
for batch in train_loader:
# 正向传播
optim.zero_grad()
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
outputs = model(input_ids, attention_mask=attention_mask, labels=labels)
loss = outputs[0]
total_train_loss += loss.item()
# 反向梯度信息
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
# 参数更新
optim.step()
scheduler.step()
iter_num += 1
if iter_num % 100 == 0:
print("epoth: %d, iter_num: %d, loss: %.4f, %.2f%%" % (
epoch, iter_num, loss.item(), iter_num / total_iter * 100))
print("Epoch: %d, Average training loss: %.4f" % (epoch, total_train_loss / len(train_loader)))
@classmethod
def flat_accuracy(cls, preds, labels):
"""
计算准确率
"""
pred_flat = np.argmax(preds, axis=-1).flatten()
labels_flat = labels.flatten()
return np.sum(pred_flat == labels_flat) / len(labels_flat)
@classmethod
def validation(cls, model, test_dataloader, device):
"""
验证函数
"""
model.eval()
total_eval_accuracy = 0
total_eval_loss = 0
for batch in test_dataloader:
with torch.no_grad():
# 正常传播
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
outputs = model(input_ids, attention_mask=attention_mask, labels=labels)
loss = outputs[0]
logits = outputs[1]
total_eval_loss += loss.item()
logits = logits.detach().cpu().numpy()
label_ids = labels.to('cpu').numpy()
total_eval_accuracy += cls.flat_accuracy(logits, label_ids)
avg_val_accuracy = total_eval_accuracy / len(test_dataloader)
print("Accuracy: %.4f" % avg_val_accuracy)
print("Average testing loss: %.4f" % (total_eval_loss / len(test_dataloader)))
print("-------------------------------")
@classmethod
def load_dataset(cls, tokenizer):
"""
加载新闻分类数据集
"""
data_path = 'dataset/toutiao_cat_data.txt'
# 标签
news_label = [int(x.split('_!_')[1]) - 100 for x in codecs.open(data_path)]
# 存储标签
label_text_json = {}
for x in codecs.open(data_path):
groups = x.split('_!_')
label_text_json[int(x.split('_!_')[1]) - 100] = groups[2]
with open('output/news_label.json', 'w') as file_obj:
json.dump(label_text_json, file_obj, indent=4)
# 文本
news_text = [x.strip().split('_!_')[-1] if x.strip()[-3:] != '_!_' else x.strip().split('_!_')[-2]
for x in codecs.open(data_path)]
# 划分为训练集和验证集
# stratify 按照标签进行采样,训练集和验证部分同分布
x_train, x_test, train_label, test_label = train_test_split(news_text[:50000],
news_label[:50000],
test_size=0.2,
stratify=news_label[:50000])
train_encoding = tokenizer(x_train, truncation=True, padding=True, max_length=64)
test_encoding = tokenizer(x_test, truncation=True, padding=True, max_length=64)
train_dataset = NewsDataset(train_encoding, train_label)
test_dataset = NewsDataset(test_encoding, test_label)
return train_dataset, test_dataset
@classmethod
def predict(cls):
"""
微调后的模型预测函数
"""
s = '金价下跌预示着什么?'
model_path = 'output/bert-news-clf'
tokenizer = BertTokenizer.from_pretrained(model_path)
model = BertForSequenceClassification.from_pretrained(model_path, num_labels=17)
sen_code = tokenizer.encode_plus(s)
tokens_tensor = torch.tensor([sen_code['input_ids']])
attention_mask = torch.tensor([sen_code['attention_mask']])
model.eval()
outputs = model(tokens_tensor, attention_mask)
outputs = outputs[0].detach().numpy()
print(outputs)
outputs = outputs[0].argmax(0)
print(outputs)
# 4
with open('output/news_label.json') as file_obj:
news_label_json = json.load(file_obj)
print(news_label_json[str(outputs)])
# news_finance
if __name__ == '__main__':
# 微调
NewsClassifier.finetuning()
# 调用微调的模型进行预测
NewsClassifier.predict()










