第十五章:关于类型提示的更多内容
本章是第八章的续集,涵盖了更多关于 Python 渐进类型系统的内容。主要议题包括:
-
重载函数签名
-
typing.TypedDict用于对作为记录使用的dicts进行类型提示 -
类型转换
-
运行时访问类型提示
-
通用类型
-
声明一个通用类
-
变异:不变、协变和逆变类型
-
通用静态协议
-
本章的新内容
本章是《流畅的 Python》第二版中的新内容。让我们从重载开始。
重载签名
Python 函数可以接受不同组合的参数。@typing.overload装饰器允许对这些不同组合进行注释。当函数的返回类型取决于两个或更多参数的类型时,这一点尤为重要。
考虑内置函数sum。这是help(sum)的文本:
>>> help(sum)
sum(iterable, /, start=0)
Return the sum of a 'start' value (default: 0) plus an iterable of numbers
When the iterable is empty, return the start value.
This function is intended specifically for use with numeric values and may
reject non-numeric types.
内置函数sum是用 C 编写的,但typeshed为其提供了重载类型提示,在builtins.pyi中有:
@overload
def sum(__iterable: Iterable[_T]) -> Union[_T, int]: ...
@overload
def sum(__iterable: Iterable[_T], start: _S) -> Union[_T, _S]: ...
首先让我们看看重载的整体语法。这是存根文件(.pyi)中关于sum的所有代码。实现将在另一个文件中。省略号(...)除了满足函数体的语法要求外没有其他作用,类似于pass。因此,.pyi文件是有效的 Python 文件。
正如在“注释位置参数和可变参数”中提到的,__iterable中的两个下划线是 PEP 484 对位置参数的约定,由 Mypy 强制执行。这意味着你可以调用sum(my_list),但不能调用sum(__iterable = my_list)。
类型检查器尝试将给定的参数与每个重载签名进行匹配,按顺序。调用sum(range(100), 1000)不匹配第一个重载,因为该签名只有一个参数。但它匹配第二个。
你也可以在普通的 Python 模块中使用@overload,只需在函数的实际签名和实现之前写上重载的签名即可。示例 15-1 展示了如何在 Python 模块中注释和实现sum。
示例 15-1。mysum.py:带有重载签名的sum函数的定义
import functools
import operator
from collections.abc import Iterable
from typing import overload, Union, TypeVar
T = TypeVar('T')
S = TypeVar('S') # ①
@overload
def sum(it: Iterable[T]) -> Union[T, int]: ... # ②
@overload
def sum(it: Iterable[T], /, start: S) -> Union[T, S]: ... # ③
def sum(it, /, start=0): # ④
return functools.reduce(operator.add, it, start)
①
我们在第二个重载中需要这第二个TypeVar。
②
这个签名是针对简单情况的:sum(my_iterable)。结果类型可能是T——my_iterable产生的元素的类型,或者如果可迭代对象为空,则可能是int,因为start参数的默认值是0。
③
当给定start时,它可以是任何类型S,因此结果类型是Union[T, S]。这就是为什么我们需要S。如果我们重用T,那么start的类型将必须与Iterable[T]的元素类型相同。
④
实际函数实现的签名没有类型提示。
这是为了注释一行函数而写的很多行代码。我知道这可能有点过头了。至少这不是一个foo函数。
如果你想通过阅读代码了解@overload,typeshed有数百个示例。在typeshed上,Python 内置函数的存根文件在我写这篇文章时有 186 个重载——比标准库中的任何其他函数都多。
利用渐进类型
追求 100% 的注释代码可能会导致添加大量噪音但很少价值的类型提示。简化类型提示以简化重构可能会导致繁琐的 API。有时最好是务实一些,让一段代码没有类型提示。
我们称之为 Pythonic 的方便 API 往往很难注释。在下一节中,我们将看到一个例子:需要六个重载才能正确注释灵活的内置 max 函数。
Max Overload
给利用 Python 强大动态特性的函数添加类型提示是困难的。
在研究 typeshed 时,我发现了 bug 报告 #4051:Mypy 没有警告说将 None 作为内置 max() 函数的参数之一是非法的,或者传递一个在某个时刻产生 None 的可迭代对象也是非法的。在任一情况下,你会得到像这样的运行时异常:
TypeError: '>' not supported between instances of 'int' and 'NoneType'
max 的文档以这句话开头:
对我来说,这是一个非常直观的描述。
但如果我必须为以这些术语描述的函数注释,我必须问:它是哪个?一个可迭代对象还是两个或更多参数?
实际情况更加复杂,因为 max 还接受两个可选关键字参数:key 和 default。
我在 Python 中编写了 max 来更容易地看到它的工作方式和重载注释之间的关系(内置的 max 是用 C 编写的);参见 Example 15-2。
Example 15-2. mymax.py:max 函数的 Python 重写
# imports and definitions omitted, see next listing
MISSING = object()
EMPTY_MSG = 'max() arg is an empty sequence'
# overloaded type hints omitted, see next listing
def max(first, *args, key=None, default=MISSING):
if args:
series = args
candidate = first
else:
series = iter(first)
try:
candidate = next(series)
except StopIteration:
if default is not MISSING:
return default
raise ValueError(EMPTY_MSG) from None
if key is None:
for current in series:
if candidate < current:
candidate = current
else:
candidate_key = key(candidate)
for current in series:
current_key = key(current)
if candidate_key < current_key:
candidate = current
candidate_key = current_key
return candidate
这个示例的重点不是 max 的逻辑,所以我不会花时间解释它的实现,除了解释 MISSING。MISSING 常量是一个用作哨兵的唯一 object 实例。它是 default= 关键字参数的默认值,这样 max 可以接受 default=None 并仍然区分这两种情况:
-
用户没有为
default=提供值,因此它是MISSING,如果first是一个空的可迭代对象,max将引发ValueError。 -
用户为
default=提供了一些值,包括None,因此如果first是一个空的可迭代对象,max将返回该值。
为了修复 问题 #4051,我写了 Example 15-3 中的代码。²
Example 15-3. mymax.py:模块顶部,包括导入、定义和重载
from collections.abc import Callable, Iterable
from typing import Protocol, Any, TypeVar, overload, Union
class SupportsLessThan(Protocol):
def __lt__(self, other: Any) -> bool: ...
T = TypeVar('T')
LT = TypeVar('LT', bound=SupportsLessThan)
DT = TypeVar('DT')
MISSING = object()
EMPTY_MSG = 'max() arg is an empty sequence'
@overload
def max(__arg1: LT, __arg2: LT, *args: LT, key: None = ...) -> LT:
...
@overload
def max(__arg1: T, __arg2: T, *args: T, key: Callable[[T], LT]) -> T:
...
@overload
def max(__iterable: Iterable[LT], *, key: None = ...) -> LT:
...
@overload
def max(__iterable: Iterable[T], *, key: Callable[[T], LT]) -> T:
...
@overload
def max(__iterable: Iterable[LT], *, key: None = ...,
default: DT) -> Union[LT, DT]:
...
@overload
def max(__iterable: Iterable[T], *, key: Callable[[T], LT],
default: DT) -> Union[T, DT]:
...
我的 Python 实现的 max 与所有那些类型导入和声明的长度大致相同。由于鸭子类型,我的代码没有 isinstance 检查,并且提供了与那些类型提示相同的错误检查,但当然只在运行时。
@overload 的一个关键优势是尽可能精确地声明返回类型,根据给定的参数类型。我们将通过逐组一到两个地研究max的重载来看到这个优势。
实现了 SupportsLessThan 的参数,但未提供 key 和 default
@overload
def max(__arg1: LT, __arg2: LT, *_args: LT, key: None = ...) -> LT:
...
# ... lines omitted ...
@overload
def max(__iterable: Iterable[LT], *, key: None = ...) -> LT:
...
在这些情况下,输入要么是实现了 SupportsLessThan 的类型 LT 的单独参数,要么是这些项目的 Iterable。max 的返回类型与实际参数或项目相同,正如我们在 “Bounded TypeVar” 中看到的。
符合这些重载的示例调用:
max(1, 2, -3) # returns 2
max(['Go', 'Python', 'Rust']) # returns 'Rust'
提供了 key 参数,但没有提供 default
@overload
def max(__arg1: T, __arg2: T, *_args: T, key: Callable[[T], LT]) -> T:
...
# ... lines omitted ...
@overload
def max(__iterable: Iterable[T], *, key: Callable[[T], LT]) -> T:
...
输入可以是任何类型 T 的单独项目或单个 Iterable[T],key= 必须是一个接受相同类型 T 的参数并返回一个实现 SupportsLessThan 的值的可调用对象。max 的返回类型与实际参数相同。
符合这些重载的示例调用:
max(1, 2, -3, key=abs) # returns -3
max(['Go', 'Python', 'Rust'], key=len) # returns 'Python'
提供了 default 参数,但没有 key
@overload
def max(__iterable: Iterable[LT], *, key: None = ...,
default: DT) -> Union[LT, DT]:
...
输入是一个实现 SupportsLessThan 的类型 LT 的项目的可迭代对象。default= 参数是当 Iterable 为空时的返回值。因此,max 的返回类型必须是 LT 类型和 default 参数类型的 Union。
符合这些重载的示例调用:
max([1, 2, -3], default=0) # returns 2
max([], default=None) # returns None
提供了 key 和 default 参数
@overload
def max(__iterable: Iterable[T], *, key: Callable[[T], LT],
default: DT) -> Union[T, DT]:
...
输入是:
-
任何类型
T的项目的可迭代对象 -
接受类型为
T的参数并返回实现SupportsLessThan的类型LT的值的可调用函数 -
任何类型
DT的默认值
max的返回类型必须是类型T或default参数的类型的Union:
max([1, 2, -3], key=abs, default=None) # returns -3
max([], key=abs, default=None) # returns None
从重载max中得到的经验教训
类型提示允许 Mypy 标记像max([None, None])这样的调用,并显示以下错误消息:
mymax_demo.py:109: error: Value of type variable "_LT" of "max"
cannot be "None"
另一方面,为了维持类型检查器而写这么多行可能会阻止人们编写方便灵活的函数,如max。如果我不得不重新发明min函数,我可以重构并重用大部分max的实现。但我必须复制并粘贴所有重载的声明——尽管它们对于min来说是相同的,除了函数名称。
我的朋友 João S. O. Bueno——我认识的最聪明的 Python 开发者之一——在推特上发表了这篇推文:
现在让我们来研究TypedDict类型构造。一开始我认为它并不像我想象的那么有用,但它有其用途。尝试使用TypedDict来处理动态结构(如 JSON 数据)展示了静态类型处理的局限性。
TypedDict
警告
使用TypedDict来保护处理动态数据结构(如 JSON API 响应)中的错误是很诱人的。但这里的示例清楚地表明,对 JSON 的正确处理必须在运行时完成,而不是通过静态类型检查。要使用类型提示对类似 JSON 的结构进行运行时检查,请查看 PyPI 上的pydantic包。
Python 字典有时被用作记录,其中键用作字段名称,不同类型的字段值。
例如,考虑描述 JSON 或 Python 中的一本书的记录:
{"isbn": "0134757599",
"title": "Refactoring, 2e",
"authors": ["Martin Fowler", "Kent Beck"],
"pagecount": 478}
在 Python 3.8 之前,没有很好的方法来注释这样的记录,因为我们在“通用映射”中看到的映射类型限制所有值具有相同的类型。
这里有两个尴尬的尝试来注释类似前述 JSON 对象的记录:
Dict[str, Any]
值可以是任何类型。
Dict[str, Union[str, int, List[str]]]
难以阅读,并且不保留字段名称和其相应字段类型之间的关系:title应该是一个str,不能是一个int或List[str]。
PEP 589—TypedDict: 具有固定键集的字典的类型提示解决了这个问题。示例 15-4 展示了一个简单的TypedDict。
示例 15-4。books.py:BookDict定义
from typing import TypedDict
class BookDict(TypedDict):
isbn: str
title: str
authors: list[str]
pagecount: int
乍一看,typing.TypedDict可能看起来像是一个数据类构建器,类似于typing.NamedTuple—在第五章中介绍过。
语法上的相似性是误导的。TypedDict非常不同。它仅存在于类型检查器的利益,并且在运行时没有影响。
TypedDict提供了两个东西:
-
类似类的语法来注释每个“字段”的值的
dict类型提示。 -
一个构造函数,告诉类型检查器期望一个带有指定键和值的
dict。
在运行时,像BookDict这样的TypedDict构造函数是一个安慰剂:它与使用相同参数调用dict构造函数具有相同效果。
BookDict创建一个普通的dict也意味着:
-
伪类定义中的“字段”不会创建实例属性。
-
你不能为“字段”编写具有默认值的初始化程序。
-
不允许方法定义。
让我们在运行时探索一个BookDict的行为(示例 15-5)。
示例 15-5。使用BookDict,但并非完全按照预期
>>> from books import BookDict
>>> pp = BookDict(title='Programming Pearls', # ①
... authors='Jon Bentley', # ②
... isbn='0201657880',
... pagecount=256)
>>> pp # ③
{'title': 'Programming Pearls', 'authors': 'Jon Bentley', 'isbn': '0201657880',
'pagecount': 256} >>> type(pp)
<class 'dict'> >>> pp.title # ④
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'dict' object has no attribute 'title'
>>> pp['title']
'Programming Pearls' >>> BookDict.__annotations__ # ⑤
{'isbn': <class 'str'>, 'title': <class 'str'>, 'authors': typing.List[str],
'pagecount': <class 'int'>}
①
你可以像使用dict构造函数一样调用BookDict,使用关键字参数,或传递一个dict参数,包括dict文字。
②
糟糕…我忘记了 authors 接受一个列表。但渐进式类型意味着在运行时没有类型检查。
③
调用 BookDict 的结果是一个普通的 dict…
④
…因此您不能使用 object.field 记法读取数据。
⑤
类型提示位于 BookDict.__annotations__ 中,而不是 pp。
没有类型检查器,TypedDict 就像注释一样有用:它可以帮助人们阅读代码,但仅此而已。相比之下,来自 第五章 的类构建器即使不使用类型检查器也很有用,因为在运行时它们会生成或增强一个自定义类,您可以实例化。它们还提供了 表 5-1 中列出的几个有用的方法或函数。
示例 15-6 构建了一个有效的 BookDict,并尝试对其进行一些操作。这展示了 TypedDict 如何使 Mypy 能够捕获错误,如 示例 15-7 中所示。
示例 15-6. demo_books.py: 在 BookDict 上进行合法和非法操作
from books import BookDict
from typing import TYPE_CHECKING
def demo() -> None: # ①
book = BookDict( # ②
isbn='0134757599',
title='Refactoring, 2e',
authors=['Martin Fowler', 'Kent Beck'],
pagecount=478
)
authors = book['authors'] # ③
if TYPE_CHECKING: # ④
reveal_type(authors) # ⑤
authors = 'Bob' # ⑥
book['weight'] = 4.2
del book['title']
if __name__ == '__main__':
demo()
①
记得添加返回类型,这样 Mypy 不会忽略函数。
②
这是一个有效的 BookDict:所有键都存在,并且具有正确类型的值。
③
Mypy 将从 BookDict 中 'authors' 键的注释中推断出 authors 的类型。
④
typing.TYPE_CHECKING 仅在程序进行类型检查时为 True。在运行时,它始终为 false。
⑤
前一个 if 语句阻止了在运行时调用 reveal_type(authors)。reveal_type 不是运行时 Python 函数,而是 Mypy 提供的调试工具。这就是为什么没有为它导入的原因。在 示例 15-7 中查看其输出。
⑥
demo 函数的最后三行是非法的。它们会在 示例 15-7 中导致错误消息。
对 demo_books.py 进行类型检查,来自 示例 15-6,我们得到 示例 15-7。
示例 15-7. 对 demo_books.py 进行类型检查
…/typeddict/ $ mypy demo_books.py
demo_books.py:13: note: Revealed type is 'built-ins.list[built-ins.str]' # ①
demo_books.py:14: error: Incompatible types in assignment
(expression has type "str", variable has type "List[str]") # ②
demo_books.py:15: error: TypedDict "BookDict" has no key 'weight' # ③
demo_books.py:16: error: Key 'title' of TypedDict "BookDict" cannot be deleted # ④
Found 3 errors in 1 file (checked 1 source file)
①
这个注释是 reveal_type(authors) 的结果。
②
authors 变量的类型是从初始化它的 book['authors'] 表达式的类型推断出来的。您不能将 str 赋给类型为 List[str] 的变量。类型检查器通常不允许变量的类型更改。³
③
无法为不属于 BookDict 定义的键赋值。
④
无法删除属于 BookDict 定义的键。
现在让我们看看在函数签名中使用 BookDict,以进行函数调用的类型检查。
想象一下,你需要从书籍记录生成类似于这样的 XML:
<BOOK>
<ISBN>0134757599</ISBN>
<TITLE>Refactoring, 2e</TITLE>
<AUTHOR>Martin Fowler</AUTHOR>
<AUTHOR>Kent Beck</AUTHOR>
<PAGECOUNT>478</PAGECOUNT>
</BOOK>
如果您正在编写要嵌入到微型微控制器中的 MicroPython 代码,您可能会编写类似于 示例 15-8 中所示的函数。⁴
示例 15-8. books.py: to_xml 函数
AUTHOR_ELEMENT = '<AUTHOR>{}</AUTHOR>'
def to_xml(book: BookDict) -> str: # ①
elements: list[str] = [] # ②
for key, value in book.items():
if isinstance(value, list): # ③
elements.extend(
AUTHOR_ELEMENT.format(n) for n in value) # ④
else:
tag = key.upper()
elements.append(f'<{tag}>{value}</{tag}>')
xml = '\n\t'.join(elements)
return f'<BOOK>\n\t{xml}\n</BOOK>'
①
示例的整个重点:在函数签名中使用 BookDict。
②
经常需要注释开始为空的集合,否则 Mypy 无法推断元素的类型。⁵
③
Mypy 理解 isinstance 检查,并在此块中将 value 视为 list。
④
当我将key == 'authors'作为if条件来保护这个块时,Mypy 在这一行发现了一个错误:““object"没有属性"iter””,因为它推断出从book.items()返回的value类型为object,而object不支持生成器表达式所需的__iter__方法。通过isinstance检查,这可以工作,因为 Mypy 知道在这个块中value是一个list。
示例 15-9(#from_json_any_ex)展示了一个解析 JSON str并返回BookDict的函数。
示例 15-9. books_any.py:from_json函数
def from_json(data: str) -> BookDict:
whatever = json.loads(data) # ①
return whatever # ②
①
json.loads()的返回类型是Any。⁶
②
我可以返回whatever—类型为Any—因为Any与每种类型都一致,包括声明的返回类型BookDict。
示例 15-9 的第二点非常重要要记住:Mypy 不会在这段代码中标记任何问题,但在运行时,whatever中的值可能不符合BookDict结构—实际上,它可能根本不是dict!
如果你使用--disallow-any-expr运行 Mypy,它会抱怨from_json函数体中的两行代码:
…/typeddict/ $ mypy books_any.py --disallow-any-expr
books_any.py:30: error: Expression has type "Any"
books_any.py:31: error: Expression has type "Any"
Found 2 errors in 1 file (checked 1 source file)
前一段代码中提到的第 30 行和 31 行是from_json函数的主体。我们可以通过在whatever变量初始化时添加类型提示来消除类型错误,就像示例 15-10 中那样。
示例 15-10. books.py:带有变量注释的from_json函数。
def from_json(data: str) -> BookDict:
whatever: BookDict = json.loads(data) # ①
return whatever # ②
①
当将类型为Any的表达式立即分配给带有类型提示的变量时,--disallow-any-expr不会导致错误。
②
现在whatever的类型是BookDict,即声明的返回类型。
警告
不要被示例 15-10 的虚假类型安全感所蒙蔽!从静态代码看,类型检查器无法预测json.loads()会返回任何类似于BookDict的东西。只有运行时验证才能保证这一点。
静态类型检查无法防止与本质上动态的代码出现错误,比如json.loads(),它在运行时构建不同类型的 Python 对象,正如示例 15-11、15-12 和 15-13 所展示的。
示例 15-11. demo_not_book.py:from_json返回一个无效的BookDict,而to_xml接受它
from books import to_xml, from_json
from typing import TYPE_CHECKING
def demo() -> None:
NOT_BOOK_JSON = """
{"title": "Andromeda Strain",
"flavor": "pistachio",
"authors": true}
"""
not_book = from_json(NOT_BOOK_JSON) # ①
if TYPE_CHECKING: # ②
reveal_type(not_book)
reveal_type(not_book['authors'])
print(not_book) # ③
print(not_book['flavor']) # ④
xml = to_xml(not_book) # ⑤
print(xml) # ⑥
if __name__ == '__main__':
demo()
①
这行代码不会产生有效的BookDict—查看NOT_BOOK_JSON的内容。
②
让我们揭示一些类型。
③
这不应该是问题:print可以处理object和其他任何类型。
④
BookDict没有'flavor'键,但 JSON 源有…会发生什么?
⑤
记住签名:def to_xml(book: BookDict) -> str:
⑥
XML 输出会是什么样子?
现在我们用 Mypy 检查demo_not_book.py(示例 15-12)。
示例 15-12. demo_not_book.py的 Mypy 报告,为了清晰起见重新格式化
…/typeddict/ $ mypy demo_not_book.py
demo_not_book.py:12: note: Revealed type is
'TypedDict('books.BookDict', {'isbn': built-ins.str,
'title': built-ins.str,
'authors': built-ins.list[built-ins.str],
'pagecount': built-ins.int})' # ①
demo_not_book.py:13: note: Revealed type is 'built-ins.list[built-ins.str]' # ②
demo_not_book.py:16: error: TypedDict "BookDict" has no key 'flavor' # ③
Found 1 error in 1 file (checked 1 source file)
①
显式类型是名义类型,而不是not_book的运行时内容。
②
同样,这是not_book['authors']的名义类型,如BookDict中定义的那样。而不是运行时类型。
③
这个错误是针对print(not_book['flavor'])这一行的:该键在名义类型中不存在。
现在让我们运行demo_not_book.py,并在示例 15-13 中显示输出。
示例 15-13. 运行 demo_not_book.py 的输出
…/typeddict/ $ python3 demo_not_book.py
{'title': 'Andromeda Strain', 'flavor': 'pistachio', 'authors': True} # ①
pistachio # ②
<BOOK> # ③
<TITLE>Andromeda Strain</TITLE>
<FLAVOR>pistachio</FLAVOR>
<AUTHORS>True</AUTHORS>
</BOOK>
①
这实际上不是一个 BookDict。
②
not_book['flavor'] 的值。
③
to_xml 接受一个 BookDict 参数,但没有运行时检查:垃圾进,垃圾出。
示例 15-13 显示 demo_not_book.py 输出了无意义的内容,但没有运行时错误。在处理 JSON 数据时使用 TypedDict 并没有提供太多类型安全性。
如果你通过鸭子类型的视角查看示例 15-8 中to_xml的代码,那么参数book必须提供一个返回类似(key, value)元组可迭代对象的.items()方法,其中:
-
key必须有一个.upper()方法 -
value可以是任何东西
这个演示的重点是:当处理具有动态结构的数据,比如 JSON 或 XML 时,TypedDict 绝对不能替代运行时的数据验证。为此,请使用pydantic。
TypedDict 具有更多功能,包括支持可选键、有限形式的继承以及另一种声明语法。如果您想了解更多,请查看 PEP 589—TypedDict: Type Hints for Dictionaries with a Fixed Set of Keys。
现在让我们将注意力转向一个最好避免但有时不可避免的函数:typing.cast。
类型转换
没有完美的类型系统,静态类型检查器、typeshed 项目中的类型提示或具有类型提示的第三方包也不是完美的。
typing.cast() 特殊函数提供了一种处理类型检查故障或代码中不正确类型提示的方法。Mypy 0.930 文档解释:
在运行时,typing.cast 绝对不起作用。这是它的实现:
def cast(typ, val):
"""Cast a value to a type.
This returns the value unchanged. To the type checker this
signals that the return value has the designated type, but at
runtime we intentionally don't check anything (we want this
to be as fast as possible).
"""
return val
PEP 484 要求类型检查器“盲目相信”cast 中声明的类型。PEP 484 的“Casts”部分提供了一个需要 cast 指导的示例:
from typing import cast
def find_first_str(a: list[object]) -> str:
index = next(i for i, x in enumerate(a) if isinstance(x, str))
# We only get here if there's at least one string
return cast(str, a[index])
对生成器表达式的 next() 调用将返回 str 项的索引或引发 StopIteration。因此,如果没有引发异常,find_first_str 将始终返回一个 str,而 str 是声明的返回类型。
但如果最后一行只是 return a[index],Mypy 将推断返回类型为 object,因为 a 参数声明为 list[object]。因此,需要 cast() 来指导 Mypy。⁷
这里是另一个使用 cast 的示例,这次是为了纠正 Python 标准库中过时的类型提示。在示例 21-12 中,我创建了一个 asyncio Server 对象,并且我想获取服务器正在侦听的地址。我编写了这行代码:
addr = server.sockets[0].getsockname()
但 Mypy 报告了这个错误:
Value of type "Optional[List[socket]]" is not indexable
2021 年 5 月 typeshed 中 Server.sockets 的类型提示对 Python 3.6 是有效的,其中 sockets 属性可以是 None。但在 Python 3.7 中,sockets 变成了一个始终返回 list 的属性,如果服务器没有 sockets,则可能为空。自 Python 3.8 起,getter 返回一个 tuple(用作不可变序列)。
由于我现在无法修复 typeshed,⁸ 我添加了一个 cast,就像这样:
from asyncio.trsock import TransportSocket
from typing import cast
# ... many lines omitted ...
socket_list = cast(tuple[TransportSocket, ...], server.sockets)
addr = socket_list[0].getsockname()
在这种情况下使用 cast 需要花费几个小时来理解问题,并阅读 asyncio 源代码以找到正确的 sockets 类型:来自未记录的 asyncio.trsock 模块的 TransportSocket 类。我还必须添加两个 import 语句和另一行代码以提高可读性。⁹ 但代码更安全。
细心的读者可能会注意到,如果 sockets 为空,sockets[0] 可能会引发 IndexError。但就我对 asyncio 的理解而言,在 示例 21-12 中不会发生这种情况,因为 server 在我读取其 sockets 属性时已准备好接受连接,因此它不会为空。无论如何,IndexError 是一个运行时错误。Mypy 甚至在像 print([][0]) 这样的简单情况下也无法发现问题。
警告
不要过于依赖 cast 来消除 Mypy 的警告,因为当 Mypy 报告错误时,通常是正确的。如果你经常使用 cast,那是一个代码异味。你的团队可能在误用类型提示,或者你的代码库中可能存在低质量的依赖项。
尽管存在缺点,cast 也有其有效用途。以下是 Guido van Rossum 关于它的一些观点:
完全禁止使用 cast 是不明智的,特别是因为其他解决方法更糟糕:
-
# type: ignore提供的信息较少。¹¹ -
使用
Any是具有传染性的:由于Any与所有类型一致,滥用它可能通过类型推断产生级联效应,削弱类型检查器在代码其他部分检测错误的能力。
当然,并非所有类型错误都可以使用 cast 修复。有时我们需要 # type: ignore,偶尔需要 Any,甚至可以在函数中不留类型提示。
接下来,让我们谈谈在运行时使用注释。
在运行时读取类型提示
在导入时,Python 读取函数、类和模块中的类型提示,并将它们存储在名为 __annotations__ 的属性中。例如,考虑 示例 15-14 中的 clip 函数。¹²
示例 15-14. clipannot.py:clip 函数的带注释签名
def clip(text: str, max_len: int = 80) -> str:
类型提示存储为函数的 __annotations__ 属性中的 dict:
>>> from clip_annot import clip
>>> clip.__annotations__
{'text': <class 'str'>, 'max_len': <class 'int'>, 'return': <class 'str'>}
'return' 键映射到 -> 符号后的返回类型提示,在 示例 15-14 中。
请注意,注释在导入时由解释器评估,就像参数默认值也会被评估一样。这就是为什么注释中的值是 Python 类 str 和 int,而不是字符串 'str' 和 'int'。注释的导入时评估是 Python 3.10 的标准,但如果 PEP 563 或 PEP 649 成为标准行为,这可能会改变。
运行时的注释问题
类型提示的增加使用引发了两个问题:
-
当使用许多类型提示时,导入模块会消耗更多的 CPU 和内存。
-
引用尚未定义的类型需要使用字符串而不是实际类型。
这两个问题都很重要。第一个问题是因为我们刚刚看到的:注释在导入时由解释器评估并存储在 __annotations__ 属性中。现在让我们专注于第二个问题。
有时需要将注释存储为字符串,因为存在“前向引用”问题:当类型提示需要引用在同一模块下定义的类时。然而,在源代码中问题的常见表现根本不像前向引用:当方法返回同一类的新对象时。由于在 Python 完全评估类体之前类对象未定义,类型提示必须使用类名作为字符串。以下是一个示例:
class Rectangle:
# ... lines omitted ...
def stretch(self, factor: float) -> 'Rectangle':
return Rectangle(width=self.width * factor)
将前向引用类型提示写为字符串是 Python 3.10 的标准和必需做法。静态类型检查器从一开始就设计用于处理这个问题。
但在运行时,如果编写代码读取 stretch 的 return 注释,你将得到一个字符串 'Rectangle' 而不是实际类型,即 Rectangle 类的引用。现在你的代码需要弄清楚那个字符串的含义。
typing模块包括三个函数和一个分类为内省助手的类,其中最重要的是typing.get_type_hints。其部分文档如下:
get_type_hints(obj, globals=None, locals=None, include_extras=False)
[…] 这通常与obj.__annotations__相同。此外,以字符串文字编码的前向引用通过在globals和locals命名空间中评估来处理。[…]
警告
自 Python 3.10 开始,应该使用新的inspect.get_annotations(…)函数,而不是typing.get_type_hints。然而,一些读者可能尚未使用 Python 3.10,因此在示例中我将使用typing.get_type_hints,自从typing模块在 Python 3.5 中添加以来就可用。
PEP 563—注释的延迟评估已经获得批准,使得不再需要将注释写成字符串,并减少类型提示的运行时成本。其主要思想在“摘要”的这两句话中描述:
从 Python 3.7 开始,这就是在任何以此import语句开头的模块中处理注释的方式:
from __future__ import annotations
为了展示其效果,我将与顶部的__future__导入行相同的clip函数的副本放在了一个名为clip_annot_post.py的模块中。
在控制台上,当我导入该模块并读取clip的注释时,这是我得到的结果:
>>> from clip_annot_post import clip
>>> clip.__annotations__
{'text': 'str', 'max_len': 'int', 'return': 'str'}
如您所见,所有类型提示现在都是普通字符串,尽管它们在clip的定义中并非作为引号字符串编写(示例 15-14)。
typing.get_type_hints函数能够解析许多类型提示,包括clip中的类型提示:
>>> from clip_annot_post import clip
>>> from typing import get_type_hints
>>> get_type_hints(clip)
{'text': <class 'str'>, 'max_len': <class 'int'>, 'return': <class 'str'>}
调用get_type_hints会给我们真实的类型,即使在某些情况下原始类型提示是作为引号字符串编写的。这是在运行时读取类型提示的推荐方式。
PEP 563 的行为原计划在 Python 3.10 中成为默认行为,无需__future__导入。然而,FastAPI 和 pydantic 的维护者发出警告,称这一变化将破坏依赖运行时类型提示的代码,并且无法可靠使用get_type_hints。
在 python-dev 邮件列表上的讨论中,PEP 563 的作者 Łukasz Langa 描述了该函数的一些限制:
Python 的指导委员会决定将 PEP 563 的默认行为推迟到 Python 3.11 或更高版本,以便开发人员有更多时间提出解决 PEP 563 试图解决的问题的解决方案,而不会破坏运行时类型提示的广泛使用。PEP 649—使用描述符推迟评估注释正在考虑作为可能的解决方案,但可能会达成不同的妥协。
总结一下:截至 Python 3.10,运行时读取类型提示并不是 100%可靠的,可能会在 2022 年发生变化。
注意
在大规模使用 Python 的公司中,他们希望获得静态类型的好处,但不想在导入时评估类型提示的代价。静态检查发生在开发人员的工作站和专用 CI 服务器上,但在生产容器中,模块的加载频率和数量要高得多,这种成本在规模上是不可忽略的。
这在 Python 社区中引发了紧张气氛,一方面是希望类型提示仅以字符串形式存储,以减少加载成本,另一方面是希望在运行时也使用类型提示的人,比如 pydantic 和 FastAPI 的创建者和用户,他们更希望将类型对象存储起来,而不是评估这些注释,这是一项具有挑战性的任务。
处理问题
鉴于目前的不稳定局势,如果您需要在运行时阅读注释,我建议:
-
避免直接读取
__annotations__;而是使用inspect.get_annotations(从 Python 3.10 开始)或typing.get_type_hints(自 Python 3.5 起)。 -
编写自己的自定义函数,作为
inspect.get_annotations或typing.get_type_hints周围的薄包装,让您的代码库的其余部分调用该自定义函数,以便将来的更改局限于单个函数。
为了演示第二点,这里是在 示例 24-5 中定义的Checked类的前几行,我们将在 第二十四章 中学习:
class Checked:
@classmethod
def _fields(cls) -> dict[str, type]:
return get_type_hints(cls)
# ... more lines ...
Checked._fields 类方法保护模块的其他部分不直接依赖于typing.get_type_hints。如果get_type_hints在将来发生变化,需要额外的逻辑,或者您想用inspect.get_annotations替换它,更改将局限于Checked._fields,不会影响程序的其余部分。
警告
鉴于关于运行时检查类型提示的持续讨论和提出的更改,官方的“注释最佳实践”文档是必读的,并且可能会在通往 Python 3.11 的道路上进行更新。这篇指南是由 Larry Hastings 撰写的,他是 PEP 649—使用描述符延迟评估注释 的作者,这是一个解决由 PEP 563—延迟评估注释 提出的运行时问题的替代提案。
本章的其余部分涵盖了泛型,从如何定义一个可以由用户参数化的泛型类开始。
实现一个通用类
在 示例 13-7 中,我们定义了Tombola ABC:一个类似于宾果笼的接口。来自 示例 13-10 的LottoBlower 类是一个具体的实现。现在我们将研究一个通用版本的LottoBlower,就像在 示例 15-15 中使用的那样。
示例 15-15. generic_lotto_demo.py:使用通用抽奖机类
from generic_lotto import LottoBlower
machine = LottoBlowerint) # ①
first = machine.pick() # ②
remain = machine.inspect() # ③
①
要实例化一个通用类,我们给它一个实际的类型参数,比如这里的int。
②
Mypy 将正确推断first是一个int…
③
… 而remain是一个整数的元组。
此外,Mypy 还报告了参数化类型的违规情况,并提供了有用的消息,就像 示例 15-16 中显示的那样。
示例 15-16. generic_lotto_errors.py:Mypy 报告的错误
from generic_lotto import LottoBlower
machine = LottoBlowerint
## error: List item 1 has incompatible type "float"; # ①
## expected "int"
machine = LottoBlowerint)
machine.load('ABC')
## error: Argument 1 to "load" of "LottoBlower" # ②
## has incompatible type "str";
## expected "Iterable[int]"
## note: Following member(s) of "str" have conflicts:
## note: Expected:
## note: def __iter__(self) -> Iterator[int]
## note: Got:
## note: def __iter__(self) -> Iterator[str]
①
在实例化LottoBlower[int]时,Mypy 标记了float。
②
在调用.load('ABC')时,Mypy 解释了为什么str不行:str.__iter__返回一个Iterator[str],但LottoBlower[int]需要一个Iterator[int]。
示例 15-17 是实现。
示例 15-17. generic_lotto.py:一个通用的抽奖机类
import random
from collections.abc import Iterable
from typing import TypeVar, Generic
from tombola import Tombola
T = TypeVar('T')
class LottoBlower(Tombola, Generic[T]): # ①
def __init__(self, items: Iterable[T]) -> None: # ②
self._balls = listT
def load(self, items: Iterable[T]) -> None: # ③
self._balls.extend(items)
def pick(self) -> T: # ④
try:
position = random.randrange(len(self._balls))
except ValueError:
raise LookupError('pick from empty LottoBlower')
return self._balls.pop(position)
def loaded(self) -> bool: # ⑤
return bool(self._balls)
def inspect(self) -> tuple[T, ...]: # ⑥
return tuple(self._balls)
①
泛型类声明通常使用多重继承,因为我们需要子类化Generic来声明形式类型参数——在本例中为T。
②
__init__中的items参数的类型为Iterable[T],当实例声明为LottoBlower[int]时,变为Iterable[int]。
③
load方法也受到限制。
④
T的返回类型现在在LottoBlower[int]中变为int。
⑤
这里没有类型变量。
⑥
最后,T设置了返回的tuple中项目的类型。
提示
typing模块文档中的“用户定义的泛型类型”部分很简短,提供了很好的例子,并提供了一些我这里没有涵盖的更多细节。
现在我们已经看到如何实现泛型类,让我们定义术语来谈论泛型。
泛型类型的基本术语
这里有几个我在学习泛型时发现有用的定义:¹⁴
泛型类型
声明有一个或多个类型变量的类型。
例子:LottoBlower[T],abc.Mapping[KT, VT]
形式类型参数
出现在泛型类型声明中的类型变量。
例子:前面例子abc.Mapping[KT, VT]中的KT和VT
参数化类型
声明为具有实际类型参数的类型。
例子:LottoBlower[int],abc.Mapping[str, float]
实际类型参数
在声明参数化类型时给定的实际类型。
例子:LottoBlower[int]中的int
下一个主题是如何使泛型类型更灵活,引入协变、逆变和不变的概念。
方差
注意
根据您在其他语言中对泛型的经验,这可能是本书中最具挑战性的部分。方差的概念是抽象的,严谨的表述会使这一部分看起来像数学书中的页面。
在实践中,方差主要与想要支持新的泛型容器类型或提供基于回调的 API 的库作者有关。即使如此,通过仅支持不变容器,您可以避免许多复杂性——这基本上是我们现在在 Python 标准库中所拥有的。因此,在第一次阅读时,您可以跳过整个部分,或者只阅读关于不变类型的部分。
我们首次在“可调用类型的方差”中看到了方差的概念,应用于参数化泛型Callable类型。在这里,我们将扩展这个概念,涵盖泛型集合类型,使用“现实世界”的类比使这个抽象概念更具体。
想象一下学校食堂有一个规定,只能安装果汁分配器。只有果汁分配器是被允许的,因为它们可能提供被学校董事会禁止的苏打水。¹⁵¹⁶
不变的分配器
让我们尝试用一个可以根据饮料类型进行参数化的泛型BeverageDispenser类来模拟食堂场景。请参见例 15-18。
例 15-18. invariant.py:类型定义和install函数
from typing import TypeVar, Generic
class Beverage: # ①
"""Any beverage."""
class Juice(Beverage):
"""Any fruit juice."""
class OrangeJuice(Juice):
"""Delicious juice from Brazilian oranges."""
T = TypeVar('T') # ②
class BeverageDispenser(Generic[T]): # ③
"""A dispenser parameterized on the beverage type."""
def __init__(self, beverage: T) -> None:
self.beverage = beverage
def dispense(self) -> T:
return self.beverage
def install(dispenser: BeverageDispenser[Juice]) -> None: # ④
"""Install a fruit juice dispenser."""
①
Beverage、Juice和OrangeJuice形成一个类型层次结构。
②
简单的TypeVar声明。
③
BeverageDispenser的类型参数化为饮料的类型。
④
install是一个模块全局函数。它的类型提示强制执行只有果汁分配器是可接受的规则。
鉴于例 15-18 中的定义,以下代码是合法的:
juice_dispenser = BeverageDispenser(Juice())
install(juice_dispenser)
然而,这是不合法的:
beverage_dispenser = BeverageDispenser(Beverage())
install(beverage_dispenser)
## mypy: Argument 1 to "install" has
## incompatible type "BeverageDispenser[Beverage]"
## expected "BeverageDispenser[Juice]"
任何饮料的分配器都是不可接受的,因为食堂需要专门用于果汁的分配器。
令人惊讶的是,这段代码也是非法的:
orange_juice_dispenser = BeverageDispenser(OrangeJuice())
install(orange_juice_dispenser)
## mypy: Argument 1 to "install" has
## incompatible type "BeverageDispenser[OrangeJuice]"
## expected "BeverageDispenser[Juice]"
专门用于橙汁的分配器也是不允许的。只有BeverageDispenser[Juice]才行。在类型术语中,我们说BeverageDispenser(Generic[T])是不变的,当BeverageDispenser[OrangeJuice]与BeverageDispenser[Juice]不兼容时——尽管OrangeJuice是Juice的子类型。
Python 可变集合类型——如list和set——是不变的。来自示例 15-17 的LottoBlower类也是不变的。
一个协变分配器
如果我们想更灵活地建模分配器作为一个通用类,可以接受某种饮料类型及其子类型,我们必须使其协变。示例 15-19 展示了如何声明BeverageDispenser。
示例 15-19. covariant.py:类型定义和install函数
T_co = TypeVar('T_co', covariant=True) # ①
class BeverageDispenser(Generic[T_co]): # ②
def __init__(self, beverage: T_co) -> None:
self.beverage = beverage
def dispense(self) -> T_co:
return self.beverage
def install(dispenser: BeverageDispenser[Juice]) -> None: # ③
"""Install a fruit juice dispenser."""
①
在声明类型变量时,设置covariant=True;_co是typeshed上协变类型参数的常规后缀。
②
使用T_co来为Generic特殊类进行参数化。
③
对于install的类型提示与示例 15-18 中的相同。
以下代码有效,因为现在Juice分配器和OrangeJuice分配器都在协变BeverageDispenser中有效:
juice_dispenser = BeverageDispenser(Juice())
install(juice_dispenser)
orange_juice_dispenser = BeverageDispenser(OrangeJuice())
install(orange_juice_dispenser)
但是,任意饮料的分配器也是不可接受的:
beverage_dispenser = BeverageDispenser(Beverage())
install(beverage_dispenser)
## mypy: Argument 1 to "install" has
## incompatible type "BeverageDispenser[Beverage]"
## expected "BeverageDispenser[Juice]"
这就是协变性:参数化分配器的子类型关系与类型参数的子类型关系方向相同变化。
逆变垃圾桶
现在我们将模拟食堂设置垃圾桶的规则。让我们假设食物和饮料都是用生物降解包装,剩菜剩饭以及一次性餐具也是生物降解的。垃圾桶必须适用于生物降解的废物。
注意
为了这个教学示例,让我们做出简化假设,将垃圾分类为一个整洁的层次结构:
-
废物是最一般的垃圾类型。所有垃圾都是废物。 -
生物降解是一种可以随时间被生物分解的垃圾类型。一些废物不是生物降解的。 -
可堆肥是一种特定类型的生物降解垃圾,可以在堆肥桶或堆肥设施中高效地转化为有机肥料。在我们的定义中,并非所有生物降解垃圾都是可堆肥的。
为了模拟食堂中可接受垃圾桶的规则,我们需要通过一个示例引入“逆变性”概念,如示例 15-20 所示。
示例 15-20. contravariant.py:类型定义和install函数
from typing import TypeVar, Generic
class Refuse: # ①
"""Any refuse."""
class Biodegradable(Refuse):
"""Biodegradable refuse."""
class Compostable(Biodegradable):
"""Compostable refuse."""
T_contra = TypeVar('T_contra', contravariant=True) # ②
class TrashCan(Generic[T_contra]): # ③
def put(self, refuse: T_contra) -> None:
"""Store trash until dumped."""
def deploy(trash_can: TrashCan[Biodegradable]):
"""Deploy a trash can for biodegradable refuse."""
①
垃圾的类型层次结构:废物是最一般的类型,可堆肥是最具体的。
②
T_contra是逆变类型变量的常规名称。
③
TrashCan在废物类型上是逆变的。
根据这些定义,以下类型的垃圾桶是可接受的:
bio_can: TrashCan[Biodegradable] = TrashCan()
deploy(bio_can)
trash_can: TrashCan[Refuse] = TrashCan()
deploy(trash_can)
更一般的TrashCan[Refuse]是可接受的,因为它可以接受任何类型的废物,包括生物降解。然而,TrashCan[Compostable]不行,因为它不能接受生物降解:
compost_can: TrashCan[Compostable] = TrashCan()
deploy(compost_can)
## mypy: Argument 1 to "deploy" has
## incompatible type "TrashCan[Compostable]"
## expected "TrashCan[Biodegradable]"
让我们总结一下我们刚刚看到的概念。
变异回顾
变异是一个微妙的属性。以下部分总结了不变、协变和逆变类型的概念,并提供了一些关于它们推理的经验法则。
不变类型
当两个参数化类型之间没有超类型或子类型关系时,泛型类型 L 是不变的,而不管实际参数之间可能存在的关系。换句话说,如果 L 是不变的,那么 L[A] 不是 L[B] 的超类型或子类型。它们在两个方面都不一致。
如前所述,Python 的可变集合默认是不变的。list 类型是一个很好的例子:list[int] 与 list[float] 不一致,反之亦然。
一般来说,如果一个形式类型参数出现在方法参数的类型提示中,并且相同的参数出现在方法返回类型中,那么为了确保在更新和读取集合时的类型安全,该参数必须是不变的。
例如,这是 list 内置的类型提示的一部分typeshed:
class list(MutableSequence[_T], Generic[_T]):
@overload
def __init__(self) -> None: ...
@overload
def __init__(self, iterable: Iterable[_T]) -> None: ...
# ... lines omitted ...
def append(self, __object: _T) -> None: ...
def extend(self, __iterable: Iterable[_T]) -> None: ...
def pop(self, __index: int = ...) -> _T: ...
# etc...
注意 _T 出现在 __init__、append 和 extend 的参数中,以及 pop 的返回类型中。如果 _T 在 _T 中是协变或逆变的,那么没有办法使这样的类类型安全。
协变类型
考虑两种类型 A 和 B,其中 B 与 A 一致,且它们都不是 Any。一些作者使用 <: 和 :> 符号来表示这样的类型关系:
A :> B
A 是 B 的超类型或相同。
B <: A
B 是 A 的子类型或相同。
给定 A :> B,泛型类型 C 在 C[A] :> C[B] 时是协变的。
注意 :> 符号的方向在 A 在 B 的左侧时是相同的。协变泛型类型遵循实际类型参数的子类型关系。
不可变容器可以是协变的。例如,typing.FrozenSet 类是如何 文档化 作为一个协变的,使用传统名称 T_co 的类型变量:
class FrozenSet(frozenset, AbstractSet[T_co]):
将 :> 符号应用于参数化类型,我们有:
float :> int
frozenset[float] :> frozenset[int]
迭代器是协变泛型的另一个例子:它们不是只读集合,如 frozenset,但它们只产生输出。任何期望一个产生浮点数的 abc.Iterator[float] 的代码可以安全地使用一个产生整数的 abc.Iterator[int]。Callable 类型在返回类型上是协变的,原因类似。
逆变类型
给定 A :> B,泛型类型 K 在 K[A] <: K[B] 时是逆变的。
逆变泛型类型颠倒了实际类型参数的子类型关系。
TrashCan 类是一个例子:
Refuse :> Biodegradable
TrashCan[Refuse] <: TrashCan[Biodegradable]
逆变容器通常是一个只写数据结构,也称为“接收器”。标准库中没有这样的集合的例子,但有一些具有逆变类型参数的类型。
Callable[[ParamType, …], ReturnType] 在参数类型上是逆变的,但在 ReturnType 上是协变的,正如我们在 “Callable 类型的方差” 中看到的。此外,Generator、Coroutine 和 AsyncGenerator 有一个逆变类型参数。Generator 类型在 “经典协程的泛型类型提示” 中有描述;Coroutine 和 AsyncGenerator 在 第二十一章 中有描述。
对于关于方差的讨论,主要观点是逆变的形式参数定义了用于调用或发送数据到对象的参数类型,而不同的协变形式参数定义了对象产生的输出类型——产生类型或返回类型,取决于对象。 “发送” 和 “产出” 的含义在 “经典协程” 中有解释。
我们可以从这些关于协变输出和逆变输入的观察中得出有用的指导方针。
协变的经验法则
最后,以下是一些关于推理方差时的经验法则:
-
如果一个形式类型参数定义了从对象中输出的数据类型,那么它可以是协变的。
-
如果形式类型参数定义了一个类型,用于在对象初始构建后进入对象的数据,它可以是逆变的。
-
如果形式类型参数定义了一个用于从对象中提取数据的类型,并且同一参数定义了一个用于将数据输入对象的类型,则它必须是不变的。
-
为了保险起见,使形式类型参数不变。
Callable[[ParamType, …], ReturnType]展示了规则#1 和#2:ReturnType是协变的,而每个ParamType是逆变的。
默认情况下,TypeVar创建的形式参数是不变的,这就是标准库中的可变集合是如何注释的。
“经典协程的通用类型提示”继续讨论关于方差的内容。
接下来,让我们看看如何定义通用的静态协议,将协变的思想应用到几个新的示例中。
实现通用的静态协议
Python 3.10 标准库提供了一些通用的静态协议。其中之一是SupportsAbs,在typing 模块中实现如下:
@runtime_checkable
class SupportsAbs(Protocol[T_co]):
"""An ABC with one abstract method __abs__ that is covariant in its
return type."""
__slots__ = ()
@abstractmethod
def __abs__(self) -> T_co:
pass
T_co根据命名约定声明:
T_co = TypeVar('T_co', covariant=True)
由于SupportsAbs,Mypy 将此代码识别为有效,如您在示例 15-21 中所见。
示例 15-21。abs_demo.py:使用通用的SupportsAbs协议
import math
from typing import NamedTuple, SupportsAbs
class Vector2d(NamedTuple):
x: float
y: float
def __abs__(self) -> float: # ①
return math.hypot(self.x, self.y)
def is_unit(v: SupportsAbs[float]) -> bool: # ②
"""'True' if the magnitude of 'v' is close to 1."""
return math.isclose(abs(v), 1.0) # ③
assert issubclass(Vector2d, SupportsAbs) # ④
v0 = Vector2d(0, 1) # ⑤
sqrt2 = math.sqrt(2)
v1 = Vector2d(sqrt2 / 2, sqrt2 / 2)
v2 = Vector2d(1, 1)
v3 = complex(.5, math.sqrt(3) / 2)
v4 = 1 # ⑥
assert is_unit(v0)
assert is_unit(v1)
assert not is_unit(v2)
assert is_unit(v3)
assert is_unit(v4)
print('OK')
①
定义__abs__使Vector2d与SupportsAbs一致。
②
使用float参数化SupportsAbs确保…
③
…Mypy 接受abs(v)作为math.isclose的第一个参数。
④
在SupportsAbs的定义中,感谢@runtime_checkable,这是一个有效的运行时断言。
⑤
剩下的代码都通过了 Mypy 检查和运行时断言。
⑥
int类型也与SupportsAbs一致。根据typeshed,int.__abs__返回一个int,这与is_unit类型提示中为v参数声明的float类型参数一致。
类似地,我们可以编写RandomPicker协议的通用版本,该协议在示例 13-18 中介绍,该协议定义了一个返回Any的单个方法pick。
示例 15-22 展示了如何使通用的RandomPicker在pick的返回类型上具有协变性。
示例 15-22。generic_randompick.py:定义通用的RandomPicker
from typing import Protocol, runtime_checkable, TypeVar
T_co = TypeVar('T_co', covariant=True) # ①
@runtime_checkable
class RandomPicker(Protocol[T_co]): # ②
def pick(self) -> T_co: ... # ③
①
将T_co声明为协变。
②
这使RandomPicker具有协变的形式类型参数。
③
使用T_co作为返回类型。
通用的RandomPicker协议可以是协变的,因为它的唯一形式参数用于返回类型。
有了这个,我们可以称之为一个章节。
章节总结
章节以一个简单的使用@overload的例子开始,接着是一个我们详细研究的更复杂的例子:正确注释max内置函数所需的重载签名。
接下来是typing.TypedDict特殊构造。我选择在这里介绍它,而不是在第五章中看到typing.NamedTuple,因为TypedDict不是一个类构建器;它只是一种向需要具有特定一组字符串键和每个键特定类型的dict添加类型提示的方式——当我们将dict用作记录时,通常在处理 JSON 数据时会发生这种情况。该部分有点长,因为使用TypedDict可能会给人一种虚假的安全感,我想展示在尝试将静态结构化记录转换为本质上是动态的映射时,运行时检查和错误处理是不可避免的。
接下来我们讨论了typing.cast,这是一个旨在指导类型检查器工作的函数。仔细考虑何时使用cast很重要,因为过度使用会妨碍类型检查器。
接下来是运行时访问类型提示。关键点是使用typing.get_type_hints而不是直接读取__annotations__属性。然而,该函数可能对某些注解不可靠,我们看到 Python 核心开发人员仍在努力找到一种方法,在减少对 CPU 和内存使用的影响的同时使类型提示在运行时可用。
最后几节是关于泛型的,首先是LottoBlower泛型类——我们后来了解到它是一个不变的泛型类。该示例后面是四个基本术语的定义:泛型类型、形式类型参数、参数化类型和实际类型参数。
接下来介绍了主题的主要内容,使用自助餐厅饮料分配器和垃圾桶作为不变、协变和逆变通用类型的“现实生活”示例。接下来,我们对 Python 标准库中的示例进行了复习、形式化和进一步应用这些概念。
最后,我们看到了如何定义通用的静态协议,首先考虑typing.SupportsAbs协议,然后将相同的思想应用于RandomPicker示例,使其比第十三章中的原始协议更加严格。
注意
Python 的类型系统是一个庞大且快速发展的主题。本章不是全面的。我选择关注那些广泛适用、特别具有挑战性或在概念上重要且因此可能长期相关的主题。
进一步阅读
Python 的静态类型系统最初设计复杂,随着每年的发展变得更加复杂。表 15-1 列出了截至 2021 年 5 月我所知道的所有 PEP。要覆盖所有内容需要一整本书。
表 15-1。关于类型提示的 PEP,标题中带有链接。带有*号的 PEP 编号在typing文档的开头段落中提到。Python 列中的问号表示正在讨论或尚未实施的 PEP;“n/a”出现在没有特定 Python 版本的信息性 PEP 中。
| PEP | 标题 | Python | 年份 |
|---|---|---|---|
| 3107 | 函数注解 | 3.0 | 2006 |
| 483* | 类型提示理论 | n/a | 2014 |
| 484* | 类型提示 | 3.5 | 2014 |
| 482 | 类型提示文献综述 | n/a | 2015 |
| 526* | 变量注解的语法 | 3.6 | 2016 |
| 544* | 协议:结构子类型(静态鸭子类型) | 3.8 | 2017 |
| 557 | 数据类 | 3.7 | 2017 |
| 560 | 类型模块和泛型类型的核心支持 | 3.7 | 2017 |
| 561 | 分发和打包类型信息 | 3.7 | 2017 |
| 563 | 注解的延迟评估 | 3.7 | 2017 |
| 586* | 字面类型 | 3.8 | 2018 |
| 585 | 标准集合中的泛型类型提示 | 3.9 | 2019 |
| 589* | TypedDict:具有固定键集的字典的类型提示 | 3.8 | 2019 |
| 591* | 向 typing 添加 final 修饰符 | 3.8 | 2019 |
| 593 | 灵活的函数和变量注释 | ? | 2019 |
| 604 | 将联合类型写为 X | Y | 3.10 | 2019 |
| 612 | 参数规范变量 | 3.10 | 2019 |
| 613 | 显式类型别名 | 3.10 | 2020 |
| 645 | 允许将可选类型写为 x? | ? | 2020 |
| 646 | 可变泛型 | ? | 2020 |
| 647 | 用户定义的类型守卫 | 3.10 | 2021 |
| 649 | 使用描述符延迟评估注释 | ? | 2021 |
| 655 | 将个别 TypedDict 项目标记为必需或可能缺失 | ? | 2021 |
Python 的官方文档几乎无法跟上所有内容,因此Mypy 的文档是一个必不可少的参考。强大的 Python 作者:帕特里克·维亚福雷(O’Reilly)是我知道的第一本广泛涵盖 Python 静态类型系统的书籍,于 2021 年 8 月出版。你现在可能正在阅读第二本这样的书籍。
关于协变的微妙主题在 PEP 484 的章节中有专门讨论,同时也在 Mypy 的“泛型”页面以及其宝贵的“常见问题”页面中有涵盖。
阅读值得的PEP 362—函数签名对象,如果你打算使用补充typing.get_type_hints函数的inspect模块。
如果你对 Python 的历史感兴趣,你可能会喜欢知道,Guido van Rossum 在 2004 年 12 月 23 日发布了“向 Python 添加可选静态类型”。
“Python 3 中的类型在野外:两种类型系统的故事” 是由 Rensselaer Polytechnic Institute 和 IBM TJ Watson 研究中心的 Ingkarat Rak-amnouykit 等人撰写的研究论文。该论文调查了 GitHub 上开源项目中类型提示的使用情况,显示大多数项目并未使用它们,而且大多数具有类型提示的项目显然也没有使用类型检查器。我发现最有趣的是对 Mypy 和 Google 的 pytype 不同语义的讨论,他们得出结论称它们“本质上是两种不同的类型系统”。
两篇关于渐进式类型的重要论文是吉拉德·布拉查的“可插入式类型系统”,以及埃里克·迈杰和彼得·德雷顿撰写的“可能时使用静态类型,需要时使用动态类型:编程语言之间的冷战结束”¹⁷
通过阅读其他语言实现相同思想的一些书籍的相关部分,我学到了很多:
-
原子 Kotlin 作者:布鲁斯·埃克尔和斯维特兰娜·伊萨科娃(Mindview)
-
Effective Java,第三版 作者:乔舒亚·布洛克(Addison-Wesley)
-
使用类型编程:TypeScript 示例 作者:弗拉德·里斯库蒂亚(Manning)
-
编程 TypeScript 作者:鲍里斯·切尔尼(O’Reilly)
-
Dart 编程语言 作者:吉拉德·布拉查(Addison-Wesley)¹⁸
对于一些关于类型系统的批判观点,我推荐阅读维克多·尤代肯的文章“类型理论中的坏主意”和“类型有害 II”。
最后,我惊讶地发现了 Ken Arnold 的“泛型有害论”,他是 Java 的核心贡献者,也是官方Java 编程语言书籍(Addison-Wesley)前四版的合著者之一——与 Java 的首席设计师 James Gosling 合作。
遗憾的是,Arnold 的批评也适用于 Python 的静态类型系统。在阅读许多有关类型提示 PEP 的规则和特例时,我不断想起 Gosling 文章中的这段话:
幸运的是,Python 比 Java 和 C++有一个关键优势:可选的类型系统。当类型提示变得太繁琐时,我们可以关闭类型检查器并省略类型提示。
¹ 来自 YouTube 视频“语言创作者对话:Guido van Rossum、James Gosling、Larry Wall 和 Anders Hejlsberg”,于 2019 年 4 月 2 日直播。引用开始于1:32:05,经过简化编辑。完整的文字记录可在https://github.com/fluentpython/language-creators找到。
² 我要感谢 Jelle Zijlstra——一个typeshed的维护者——教会了我很多东西,包括如何将我最初的九个重载减少到六个。
³ 截至 2020 年 5 月,pytype 允许这样做。但其常见问题解答中表示将来会禁止这样做。请参见 pytype常见问题解答中的“为什么 pytype 没有捕捉到我更改了已注释变量的类型?”问题。
⁴ 我更喜欢使用lxml包来生成和解析 XML:它易于上手,功能齐全且速度快。不幸的是,lxml 和 Python 自带的ElementTree不适用于我假想的微控制器的有限 RAM。
⁵ Mypy 文档在其“常见问题和解决方案”页面中讨论了这个问题,在“空集合的类型”一节中有详细说明。
⁶ Brett Cannon、Guido van Rossum 等人自 2016 年以来一直在讨论如何为json.loads()添加类型提示,在Mypy 问题#182:定义 JSON 类型中。
⁷ 示例中使用enumerate旨在混淆类型检查器。Mypy 可以正确分析直接生成字符串而不经过enumerate索引的更简单的实现,因此不需要cast()。
⁸ 我报告了typeshed的问题#5535,“asyncio.base_events.Server sockets 属性的错误类型提示”,Sebastian Rittau 很快就修复了。然而,我决定保留这个例子,因为它展示了cast的一个常见用例,而我写的cast是无害的。
⁹ 老实说,我最初在带有server.sockets[0]的行末添加了一个# type: ignore注释,因为经过一番调查,我在asyncio 文档和一个测试用例中找到了类似的行,所以我怀疑问题不在我的代码中。
¹⁰ 2020 年 5 月 19 日消息发送至 typing-sig 邮件列表。
¹¹ 语法# type: ignore[code]允许您指定要消除的 Mypy 错误代码,但这些代码并不总是容易解释。请参阅 Mypy 文档中的“错误代码”。
¹² 我不会详细介绍 clip 的实现,但如果你感兴趣,可以阅读 clip_annot.py 中的整个模块。
¹³ 2021 年 4 月 16 日发布的信息 “PEP 563 in light of PEP 649”。
¹⁴ 这些术语来自 Joshua Bloch 的经典著作 Effective Java,第三版(Addison-Wesley)。定义和示例是我自己的。
¹⁵ 我第一次看到 Erik Meijer 在 Gilad Bracha 的 The Dart Programming Language 一书(Addison-Wesley)的 前言 中使用自助餐厅类比来解释方差。
¹⁶ 比禁书好多了!
¹⁷ 作为脚注的读者,你可能记得我将 Erik Meijer 归功于用自助餐厅类比来解释方差。
¹⁸ 那本书是为 Dart 1 写的。Dart 2 有重大变化,包括类型系统。尽管如此,Bracha 是编程语言设计领域的重要研究者,我发现这本书对 Dart 的设计视角很有价值。
¹⁹ 参见 PEP 484 中 “Covariance and Contravariance” 部分的最后一段。
第十六章:运算符重载
在 Python 中,你可以使用以下公式计算复利:
interest = principal * ((1 + rate) ** periods - 1)
出现在操作数之间的运算符,如 1 + rate,是中缀运算符。在 Python 中,中缀运算符可以处理任意类型。因此,如果你处理真实货币,你可以确保 principal、rate 和 periods 是精确的数字 —— Python decimal.Decimal 类的实例 —— 并且该公式将按照写入的方式工作,产生精确的结果。
但是在 Java 中,如果你从 float 切换到 BigDecimal 以获得精确的结果,你就不能再使用中缀运算符了,因为它们只适用于原始类型。这是在 Java 中使用 BigDecimal 数字编写的相同公式:
BigDecimal interest = principal.multiply(BigDecimal.ONE.add(rate)
.pow(periods).subtract(BigDecimal.ONE));
显然,中缀运算符使公式更易读。运算符重载是支持用户定义或扩展类型的中缀运算符表示法的必要条件,例如 NumPy 数组。在一个高级、易于使用的语言中具有运算符重载可能是 Python 在数据科学领域取得巨大成功的关键原因,包括金融和科学应用。
在“模拟数值类型”(第一章)中,我们看到了一个简单的 Vector 类中运算符的实现。示例 1-2 中的 __add__ 和 __mul__ 方法是为了展示特殊方法如何支持运算符重载,但是它们的实现中存在一些微妙的问题被忽略了。此外,在示例 11-2 中,我们注意到 Vector2d.__eq__ 方法认为这是 True:Vector(3, 4) == [3, 4] ——这可能有或没有意义。我们将在本章中解决这些问题,以及:
-
中缀运算符方法应如何表示无法处理操作数
-
使用鸭子类型或鹅类型处理各种类型的操作数
-
丰富比较运算符的特殊行为(例如,
==,>,<=等) -
增强赋值运算符(如
+=)的默认处理方式,以及如何对其进行重载
本章的新内容
鹅类型是 Python 的一个关键部分,但 numbers ABCs 在静态类型中不受支持,因此我改变了示例 16-11 以使用鸭子类型而不是针对 numbers.Real 的显式 isinstance 检查。²
我在第一版的 Fluent Python 中介绍了 @ 矩阵乘法运算符,当 3.5 版本还处于 alpha 阶段时,它被视为即将到来的变化。因此,该运算符不再是一个旁注,而是在“使用 @ 作为中缀运算符”的章节流中整合了进去。我利用鹅类型使 __matmul__ 的实现比第一版更安全,而不会影响灵活性。
“进一步阅读” 现在有几个新的参考资料 —— 包括 Guido van Rossum 的一篇博客文章。我还添加了两个展示运算符重载在数学领域之外有效使用的库:pathlib 和 Scapy。
运算符重载 101
运算符重载允许用户定义的对象与中缀运算符(如 + 和 |)或一元运算符(如 - 和 ~)进行交互。更一般地说,函数调用(())、属性访问(.)和项目访问/切片([])在 Python 中也是运算符,但本章涵盖一元和中缀运算符。
运算符重载在某些圈子里名声不佳。这是一种语言特性,可能会被滥用,导致程序员困惑、错误和意外的性能瓶颈。但如果使用得当,它会导致愉快的 API 和可读的代码。Python 在灵活性、可用性和安全性之间取得了良好的平衡,通过施加一些限制:
-
我们不能改变内置类型的运算符的含义。
-
我们不能创建新的运算符,只能重载现有的运算符。
-
有一些运算符无法重载:
is,and,or,not(但位运算符&,|,~可以)。
在第十二章中,我们已经在Vector中有一个中缀运算符:==,由__eq__方法支持。在本章中,我们将改进__eq__的实现,以更好地处理除Vector之外的类型的操作数。然而,富比较运算符(==,!=,>,<,>=,<=)是运算符重载中的特殊情况,因此我们将从重载Vector中的四个算术运算符开始:一元-和+,然后是中缀+和*。
让我们从最简单的话题开始:一元运算符。
一元运算符
Python 语言参考,“6.5. 一元算术和位运算”列出了三个一元运算符,这里显示它们及其相关的特殊方法:
-,由__neg__实现
算术一元取反。如果x是-2,那么-x == 2。
+,由__pos__实现
算术一元加号。通常x == +x,但也有一些情况不成立。如果你感兴趣,可以查看“当 x 和 +x 不相等时”。
~,由__invert__实现
位取反,或整数的位反,定义为~x == -(x+1)。如果x是2,那么~x == -3。³
Python 语言参考的“数据模型”章节还将abs()内置函数列为一元运算符。相关的特殊方法是__abs__,正如我们之前看到的。
支持一元运算符很容易。只需实现适当的特殊方法,该方法只接受一个参数:self。在类中使用适当的逻辑,但遵循运算符的一般规则:始终返回一个新对象。换句话说,不要修改接收者(self),而是创建并返回一个适当类型的新实例。
对于-和+,结果可能是与self相同类的实例。对于一元+,如果接收者是不可变的,则应返回self;否则,返回self的副本。对于abs(),结果应该是一个标量数字。
至于~,如果不处理整数中的位,很难说会得到什么合理的结果。在pandas数据分析包中,波浪线对布尔过滤条件取反;请参阅pandas文档中的“布尔索引”以获取示例。
正如之前承诺的,我们将在第十二章的Vector类上实现几个新的运算符。示例 16-1 展示了我们已经在示例 12-16 中拥有的__abs__方法,以及新添加的__neg__和__pos__一元运算符方法。
示例 16-1. vector_v6.py:一元运算符 - 和 + 添加到示例 12-16
def __abs__(self):
return math.hypot(*self)
def __neg__(self):
return Vector(-x for x in self) # ①
def __pos__(self):
return Vector(self) # ②
①
要计算-v,构建一个新的Vector,其中包含self的每个分量的取反。
②
要计算+v,构建一个新的Vector,其中包含self的每个分量。
请记住,Vector实例是可迭代的,Vector.__init__接受一个可迭代的参数,因此__neg__和__pos__的实现简洁明了。
我们不会实现__invert__,因此如果用户在Vector实例上尝试~v,Python 将引发TypeError并显示清晰的消息:“一元~的错误操作数类型:'Vector'。”
以下侧边栏涵盖了一个关于一元+的好奇心,也许有一天可以帮你赢得一次赌注。
重载 + 实现向量加法
Vector类是一个序列类型,在官方 Python 文档的“数据模型”章节中的“3.3.6. 模拟容器类型”部分指出,序列应该支持+运算符进行连接和*进行重复。然而,在这里我们将实现+和*作为数学向量运算,这有点困难,但对于Vector类型更有意义。
提示
如果用户想要连接或重复Vector实例,他们可以将其转换为元组或列表,应用运算符,然后再转换回来——这要归功于Vector是可迭代的,并且可以从可迭代对象构建:
>>> v_concatenated = Vector(list(v1) + list(v2))
>>> v_repeated = Vector(tuple(v1) * 5)
将两个欧几里德向量相加会得到一个新的向量,其中的分量是操作数的分量的成对相加。举例说明:
>>> v1 = Vector([3, 4, 5])
>>> v2 = Vector([6, 7, 8])
>>> v1 + v2
Vector([9.0, 11.0, 13.0])
>>> v1 + v2 == Vector([3 + 6, 4 + 7, 5 + 8])
True
如果我们尝试将长度不同的两个Vector实例相加会发生什么?我们可以引发一个错误,但考虑到实际应用(如信息检索),最好是用零填充最短的Vector。这是我们想要的结果:
>>> v1 = Vector([3, 4, 5, 6])
>>> v3 = Vector([1, 2])
>>> v1 + v3
Vector([4.0, 6.0, 5.0, 6.0])
鉴于这些基本要求,我们可以像示例 16-4 中那样实现__add__。
示例 16-4. Vector.__add__ 方法,第一种情况
# inside the Vector class
def __add__(self, other):
pairs = itertools.zip_longest(self, other, fillvalue=0.0) # ①
return Vector(a + b for a, b in pairs) # ②
①
pairs是一个生成器,产生元组(a, b),其中a来自self,b来自other。如果self和other的长度不同,fillvalue会为最短的可迭代对象提供缺失值。
②
从生成器表达式构建一个新的Vector,为pairs中的每个(a, b)执行一次加法。
注意__add__如何返回一个新的Vector实例,并且不改变self或other。
警告
实现一元或中缀运算符的特殊方法永远不应更改操作数的值。带有这些运算符的表达式预期通过创建新对象来产生结果。只有增强赋值运算符可以更改第一个操作数(self),如“增强赋值运算符”中所讨论的。
示例 16-4 允许将Vector添加到Vector2d,以及将Vector添加到元组或任何产生数字的可迭代对象,正如示例 16-5 所证明的那样。
示例 16-5. Vector.__add__ 第一种情况也支持非Vector对象
>>> v1 = Vector([3, 4, 5])
>>> v1 + (10, 20, 30)
Vector([13.0, 24.0, 35.0])
>>> from vector2d_v3 import Vector2d
>>> v2d = Vector2d(1, 2)
>>> v1 + v2d
Vector([4.0, 6.0, 5.0])
示例 16-5 中+的两种用法都有效,因为__add__使用了zip_longest(…),它可以消耗任何可迭代对象,并且用于构建新Vector的生成器表达式仅执行zip_longest(…)产生的对中的a + b,因此产生任意数量项的可迭代对象都可以。
然而,如果我们交换操作数(示例 16-6),混合类型的加法会失败。
示例 16-6. Vector.__add__ 第一种情况在非Vector左操作数上失败
>>> v1 = Vector([3, 4, 5])
>>> (10, 20, 30) + v1
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: can only concatenate tuple (not "Vector") to tuple
>>> from vector2d_v3 import Vector2d
>>> v2d = Vector2d(1, 2)
>>> v2d + v1
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unsupported operand type(s) for +: 'Vector2d' and 'Vector'
为了支持涉及不同类型对象的操作,Python 为中缀运算符特殊方法实现了一种特殊的调度机制。给定表达式a + b,解释器将执行以下步骤(也参见图 16-1):
-
如果
a有__add__,则调用a.__add__(b)并返回结果,除非它是NotImplemented。 -
如果
a没有__add__,或者调用它返回NotImplemented,则检查b是否有__radd__,然后调用b.__radd__(a)并返回结果,除非它是NotImplemented。 -
如果
b没有__radd__,或者调用它返回NotImplemented,则引发TypeError,并显示不支持的操作数类型消息。
提示
__radd__方法被称为__add__的“反射”或“反转”版本。我更喜欢称它们为“反转”特殊方法。⁴
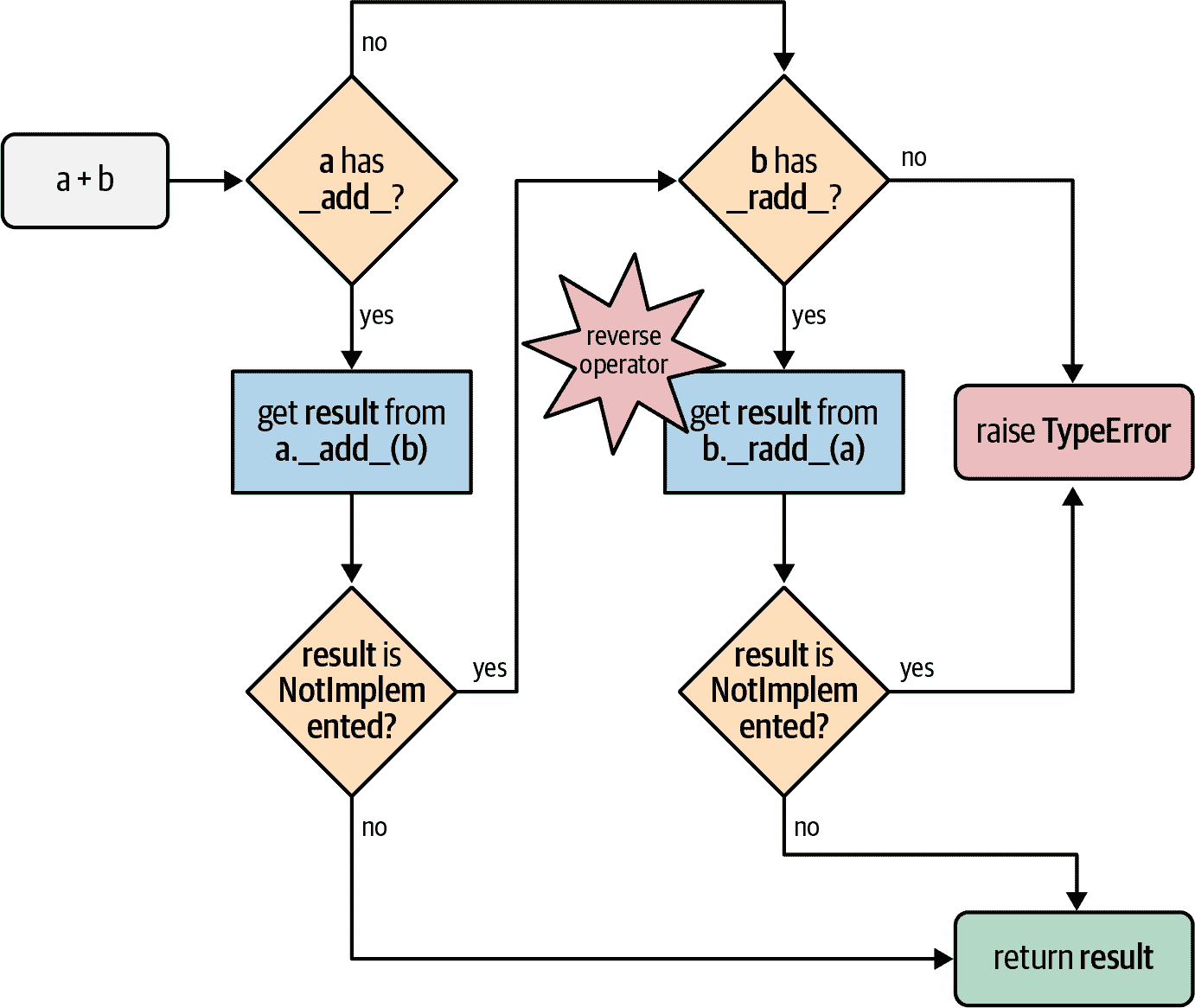
图 16-1. 使用__add__和__radd__计算a + b的流程图。
因此,为了使示例 16-6 中的混合类型加法起作用,我们需要实现Vector.__radd__方法,如果左操作数不实现__add__,或者实现了但返回NotImplemented以表示不知道如何处理右操作数,则 Python 将调用它作为后备。
警告
不要混淆NotImplemented和NotImplementedError。第一个NotImplemented是一个特殊的单例值,中缀运算符特殊方法应该返回以告诉解释器它无法处理给定的操作数。相反,NotImplementedError是一个异常,抽象类中的存根方法可能会引发以警告子类必须实现它们。
__radd__的最简单的工作实现在示例 16-7 中显示。
示例 16-7. Vector方法__add__和__radd__
# inside the Vector class
def __add__(self, other): # ①
pairs = itertools.zip_longest(self, other, fillvalue=0.0)
return Vector(a + b for a, b in pairs)
def __radd__(self, other): # ②
return self + other
①
与示例 16-4 中的__add__没有变化;这里列出是因为__radd__使用它。
②
__radd__只是委托给__add__。
__radd__通常很简单:只需调用适当的运算符,因此在这种情况下委托给__add__。这适用于任何可交换的运算符;当处理数字或我们的向量时,+是可交换的,但在 Python 中连接序列时不是可交换的。
如果__radd__简单地调用__add__,那么这是实现相同效果的另一种方法:
def __add__(self, other):
pairs = itertools.zip_longest(self, other, fillvalue=0.0)
return Vector(a + b for a, b in pairs)
__radd__ = __add__
示例 16-7 中的方法适用于Vector对象,或具有数字项的任何可迭代对象,例如Vector2d,一组整数的tuple,或一组浮点数的array。但如果提供了一个不可迭代的对象,__add__将引发一个带有不太有用消息的异常,就像示例 16-8 中一样。
示例 16-8. Vector.__add__方法需要一个可迭代的操作数
>>> v1 + 1
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "vector_v6.py", line 328, in __add__
pairs = itertools.zip_longest(self, other, fillvalue=0.0)
TypeError: zip_longest argument #2 must support iteration
更糟糕的是,如果一个操作数是可迭代的,但其项无法添加到Vector中的float项中,则会得到一个误导性的消息。请参见示例 16-9。
示例 16-9. Vector.__add__方法需要具有数字项的可迭代对象
>>> v1 + 'ABC'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "vector_v6.py", line 329, in __add__
return Vector(a + b for a, b in pairs)
File "vector_v6.py", line 243, in __init__
self._components = array(self.typecode, components)
File "vector_v6.py", line 329, in <genexpr>
return Vector(a + b for a, b in pairs)
TypeError: unsupported operand type(s) for +: 'float' and 'str'
我尝试添加Vector和一个str,但消息抱怨float和str。
示例 16-8 和 16-9 中的问题实际上比晦涩的错误消息更深:如果一个运算符特殊方法由于类型不兼容而无法返回有效结果,它应该返回NotImplemented而不是引发TypeError。通过返回NotImplemented,您为另一个操作数类型的实现者留下了机会,在 Python 尝试调用反向方法时执行操作。
符合鸭子类型的精神,我们将避免测试other操作数的类型,或其元素的类型。我们将捕获异常并返回NotImplemented。如果解释器尚未颠倒操作数,则将尝试这样做。如果反向方法调用返回NotImplemented,那么 Python 将引发TypeError,并显示标准错误消息,如“不支持的操作数类型:Vector和str”。
Vector加法的特殊方法的最终实现在示例 16-10 中。
示例 16-10. vector_v6.py:向 vector_v5.py 添加了运算符+方法(示例 12-16)
def __add__(self, other):
try:
pairs = itertools.zip_longest(self, other, fillvalue=0.0)
return Vector(a + b for a, b in pairs)
except TypeError:
return NotImplemented
def __radd__(self, other):
return self + other
注意,__add__现在捕获TypeError并返回NotImplemented。
警告
如果中缀运算符方法引发异常,则会中止运算符分派算法。在TypeError的特定情况下,通常最好捕获它并返回 NotImplemented。这允许解释器尝试调用反向运算符方法,如果它们是不同类型的,则可能正确处理交换操作数的计算。
到目前为止,我们已经通过编写__add__和__radd__安全地重载了+运算符。现在我们将处理另一个中缀运算符:*。
为标量乘法重载*
Vector([1, 2, 3]) * x是什么意思?如果x是一个数字,那将是一个标量乘积,结果将是一个每个分量都乘以x的新Vector——也被称为逐元素乘法:
>>> v1 = Vector([1, 2, 3])
>>> v1 * 10
Vector([10.0, 20.0, 30.0])
>>> 11 * v1
Vector([11.0, 22.0, 33.0])
注意
涉及Vector操作数的另一种产品类型将是两个向量的点积,或者矩阵乘法,如果你将一个向量视为 1×N 矩阵,另一个向量视为 N×1 矩阵。我们将在我们的Vector类中实现该运算符,详见“使用@作为中缀运算符”。
再次回到我们的标量乘积,我们从可能起作用的最简单的__mul__和__rmul__方法开始:
# inside the Vector class
def __mul__(self, scalar):
return Vector(n * scalar for n in self)
def __rmul__(self, scalar):
return self * scalar
这些方法确实有效,除非提供了不兼容的操作数。scalar参数必须是一个数字,当乘以一个float时产生另一个float(因为我们的Vector类在内部使用float数组)。因此,一个complex数是不行的,但标量可以是一个int、一个bool(因为bool是int的子类),甚至是一个fractions.Fraction实例。在示例 16-11 中,__mul__方法没有对scalar进行显式类型检查,而是将其转换为float,如果失败则返回NotImplemented。这是鸭子类型的一个明显例子。
示例 16-11. vector_v7.py:添加*方法
class Vector:
typecode = 'd'
def __init__(self, components):
self._components = array(self.typecode, components)
# many methods omitted in book listing, see vector_v7.py
# in https://github.com/fluentpython/example-code-2e
def __mul__(self, scalar):
try:
factor = float(scalar)
except TypeError: # ①
return NotImplemented # ②
return Vector(n * factor for n in self)
def __rmul__(self, scalar):
return self * scalar # ③
①
如果scalar无法转换为float…
②
…我们不知道如何处理它,所以我们返回NotImplemented,让 Python 尝试在scalar操作数上执行__rmul__。
③
在这个例子中,__rmul__通过执行self * scalar来正常工作,委托给__mul__方法。
通过示例 16-11,我们可以将Vectors乘以通常和不太常见的数值类型的标量值:
>>> v1 = Vector([1.0, 2.0, 3.0])
>>> 14 * v1
Vector([14.0, 28.0, 42.0])
>>> v1 * True
Vector([1.0, 2.0, 3.0])
>>> from fractions import Fraction
>>> v1 * Fraction(1, 3)
Vector([0.3333333333333333, 0.6666666666666666, 1.0])
现在我们可以将Vector乘以标量,让我们看看如何实现Vector乘以Vector的乘积。
注意
在Fluent Python的第一版中,我在示例 16-11 中使用了鹅类型:我用isinstance(scalar, numbers.Real)检查了__mul__的scalar参数。现在我避免使用numbers ABCs,因为它们不受 PEP 484 支持,而且在运行时使用无法静态检查的类型对我来说似乎不是一个好主意。
或者,我可以针对我们在“运行时可检查的静态协议”中看到的typing.SupportsFloat协议进行检查。在那个示例中,我选择了鸭子类型,因为我认为精通 Python 的人应该对这种编码模式感到舒适。
另一方面,在示例 16-12 中的__matmul__是鹅类型的一个很好的例子,这是第二版中新增的。
使用@作为中缀运算符
@符号众所周知是函数装饰器的前缀,但自 2015 年以来,它也可以用作中缀运算符。多年来,在 NumPy 中,点积被写为numpy.dot(a, b)。函数调用符号使得从数学符号到 Python 的长公式更难以转换,因此数值计算社区游说支持PEP 465—用于矩阵乘法的专用中缀运算符,这在 Python 3.5 中实现。今天,你可以写a @ b来计算两个 NumPy 数组的点积。
@运算符由特殊方法__matmul__、__rmatmul__和__imatmul__支持,命名为“矩阵乘法”。这些方法目前在标准库中没有被使用,但自 Python 3.5 以来,解释器已经认可它们,因此 NumPy 团队——以及我们其他人——可以在用户定义的类型中支持@运算符。解析器也已更改以处理新运算符(在 Python 3.4 中,a @ b是语法错误)。
这些简单的测试展示了@应该如何与Vector实例一起工作:
>>> va = Vector([1, 2, 3])
>>> vz = Vector([5, 6, 7])
>>> va @ vz == 38.0 # 1*5 + 2*6 + 3*7
True
>>> [10, 20, 30] @ vz
380.0
>>> va @ 3
Traceback (most recent call last):
...
TypeError: unsupported operand type(s) for @: 'Vector' and 'int'
示例 16-12 展示了相关特殊方法的代码。
示例 16-12. vector_v7.py:操作符@方法
class Vector:
# many methods omitted in book listing
def __matmul__(self, other):
if (isinstance(other, abc.Sized) and # ①
isinstance(other, abc.Iterable)):
if len(self) == len(other): # ②
return sum(a * b for a, b in zip(self, other)) # ③
else:
raise ValueError('@ requires vectors of equal length.')
else:
return NotImplemented
def __rmatmul__(self, other):
return self @ other
①
两个操作数必须实现__len__和__iter__…
②
…并且具有相同的长度以允许…
③
…sum、zip和生成器表达式的一个美妙应用。
Python 3.10 中的新 zip() 特性
zip 内置函数自 Python 3.10 起接受一个strict关键字参数。当strict=True时,当可迭代对象的长度不同时,函数会引发ValueError。默认值为False。这种新的严格行为符合 Python 的快速失败哲学。在示例 16-12 中,我会用try/except ValueError替换内部的if,并在zip调用中添加strict=True。
示例 16-12 是实践中鹅类型的一个很好的例子。如果我们将other操作数与Vector进行测试,我们将剥夺用户使用列表或数组作为@操作数的灵活性。只要一个操作数是Vector,我们的@实现就支持其他操作数是abc.Sized和abc.Iterable的实例。这两个 ABC 都实现了__subclasshook__,因此任何提供__len__和__iter__的对象都满足我们的测试——无需实际子类化这些 ABC,甚至无需向它们注册,如“使用 ABC 进行结构化类型检查”中所解释的那样。特别是,我们的Vector类既不是abc.Sized的子类,也不是abc.Iterable的子类,但它通过了对这些 ABC 的isinstance检查,因为它具有必要的方法。
在深入讨论“富比较运算符”的特殊类别之前,让我们回顾一下 Python 支持的算术运算符。
算术运算符总结
通过实现+、*和@,我们看到了编写中缀运算符的最常见模式。我们描述的技术适用于表 16-1 中列出的所有运算符(就地运算符将在“增强赋值运算符”中介绍)。
表 16-1. 中缀运算符方法名称(就地运算符用于增强赋值;比较运算符在表 16-2 中)
| 运算符 | 正向 | 反向 | 就地 | 描述 |
|---|---|---|---|---|
+ | __add__ | __radd__ | __iadd__ | 加法或连接 |
- | __sub__ | __rsub__ | __isub__ | 减法 |
* | __mul__ | __rmul__ | __imul__ | 乘法或重复 |
/ | __truediv__ | __rtruediv__ | __itruediv__ | 真除法 |
// | __floordiv__ | __rfloordiv__ | __ifloordiv__ | 地板除法 |
% | __mod__ | __rmod__ | __imod__ | 取模 |
divmod() | __divmod__ | __rdivmod__ | __idivmod__ | 返回地板除法商和模数的元组 |
**, pow() | __pow__ | __rpow__ | __ipow__ | 指数运算^(a) |
@ | __matmul__ | __rmatmul__ | __imatmul__ | 矩阵乘法 |
& | __and__ | __rand__ | __iand__ | 位与 |
| | | __or__ | __ror__ | __ior__ | 位或 |
^ | __xor__ | __rxor__ | __ixor__ | 位异或 |
<< | __lshift__ | __rlshift__ | __ilshift__ | 位左移 |
>> | __rshift__ | __rrshift__ | __irshift__ | 位右移 |
^(a) pow 接受一个可选的第三个参数,modulo:pow(a, b, modulo),在直接调用时也由特殊方法支持(例如,a.__pow__(b, modulo))。 |
富比较运算符使用不同的规则。
富比较运算符
Python 解释器对富比较运算符==、!=、>、<、>=和<=的处理与我们刚才看到的类似,但在两个重要方面有所不同:
-
在前向和反向运算符调用中使用相同的方法集。规则总结在表 16-2 中。例如,在
==的情况下,前向和反向调用都调用__eq__,只是交换参数;前向调用__gt__后跟着反向调用__lt__,参数交换。 -
在
==和!=的情况下,如果缺少反向方法,或者返回NotImplemented,Python 会比较对象 ID 而不是引发TypeError。
表 16-2. 富比较运算符:当初始方法调用返回NotImplemented时调用反向方法
| 组 | 中缀运算符 | 前向方法调用 | 反向方法调用 | 回退 |
|---|---|---|---|---|
| 相等性 | a == b | a.__eq__(b) | b.__eq__(a) | 返回id(a) == id(b) |
a != b | a.__ne__(b) | b.__ne__(a) | 返回not (a == b) | |
| 排序 | a > b | a.__gt__(b) | b.__lt__(a) | 引发TypeError |
a < b | a.__lt__(b) | b.__gt__(a) | 引发TypeError | |
a >= b | a.__ge__(b) | b.__le__(a) | 引发TypeError | |
a <= b | a.__le__(b) | b.__ge__(a) | 引发TypeError |
鉴于这些规则,让我们审查并改进Vector.__eq__方法的行为,该方法在vector_v5.py中编码如下(示例 12-16):
class Vector:
# many lines omitted
def __eq__(self, other):
return (len(self) == len(other) and
all(a == b for a, b in zip(self, other)))
该方法产生了示例 16-13 中的结果。
示例 16-13. 将Vector与Vector、Vector2d和tuple进行比较
>>> va = Vector([1.0, 2.0, 3.0])
>>> vb = Vector(range(1, 4))
>>> va == vb # ①
True >>> vc = Vector([1, 2])
>>> from vector2d_v3 import Vector2d
>>> v2d = Vector2d(1, 2)
>>> vc == v2d # ②
True >>> t3 = (1, 2, 3)
>>> va == t3 # ③
True
①
具有相等数值组件的两个Vector实例比较相等。
②
如果它们的组件相等,Vector和Vector2d也相等。
③
Vector也被视为等于包含相同数值的tuple或任何可迭代对象。
示例 16-13 中的结果可能不理想。我们真的希望Vector被视为等于包含相同数字的tuple吗?我对此没有硬性规定;这取决于应用上下文。《Python 之禅》说:
在评估操作数时过于宽松可能导致令人惊讶的结果,程序员讨厌惊喜。
借鉴于 Python 本身,我们可以看到[1,2] == (1, 2)是False。因此,让我们保守一点并进行一些类型检查。如果第二个操作数是Vector实例(或Vector子类的实例),那么使用与当前__eq__相同的逻辑。否则,返回NotImplemented并让 Python 处理。参见示例 16-14。
示例 16-14. vector_v8.py:改进了Vector类中的__eq__
def __eq__(self, other):
if isinstance(other, Vector): # ①
return (len(self) == len(other) and
all(a == b for a, b in zip(self, other)))
else:
return NotImplemented # ②
①
如果other操作数是Vector的实例(或Vector子类的实例),则像以前一样执行比较。
②
否则,返回NotImplemented。
如果您使用来自示例 16-14 的新Vector.__eq__运行示例 16-13 中的测试,现在得到的结果如示例 16-15 所示。
示例 16-15. 与示例 16-13 相同的比较:最后结果改变
>>> va = Vector([1.0, 2.0, 3.0])
>>> vb = Vector(range(1, 4))
>>> va == vb # ①
True >>> vc = Vector([1, 2])
>>> from vector2d_v3 import Vector2d
>>> v2d = Vector2d(1, 2)
>>> vc == v2d # ②
True >>> t3 = (1, 2, 3)
>>> va == t3 # ③
False
①
与预期一样,与之前相同的结果。
②
与之前相同的结果,但为什么?解释即将到来。
③
不同的结果;这就是我们想要的。但是为什么会起作用?继续阅读…
在 示例 16-15 中的三个结果中,第一个不是新闻,但最后两个是由 示例 16-14 中的 __eq__ 返回 NotImplemented 导致的。以下是在一个 Vector 和一个 Vector2d 的示例中发生的情况,vc == v2d,逐步进行:
-
要评估
vc == v2d,Python 调用Vector.__eq__(vc, v2d)。 -
Vector.__eq__(vc, v2d)验证v2d不是Vector并返回NotImplemented。 -
Python 得到
NotImplemented的结果,因此尝试Vector2d.__eq__(v2d, vc)。 -
Vector2d.__eq__(v2d, vc)将两个操作数转换为元组并进行比较:结果为True(Vector2d.__eq__的代码在 示例 11-11 中)。
至于比较 va == t3,在 示例 16-15 中的 Vector 和 tuple 之间,实际步骤如下:
-
要评估
va == t3,Python 调用Vector.__eq__(va, t3)。 -
Vector.__eq__(va, t3)验证t3不是Vector并返回NotImplemented。 -
Python 得到
NotImplemented的结果,因此尝试tuple.__eq__(t3, va)。 -
tuple.__eq__(t3, va)不知道什么是Vector,所以返回NotImplemented。 -
在
==的特殊情况下,如果反向调用返回NotImplemented,Python 将比较对象 ID 作为最后的手段。
对于 != 我们不需要为 __ne__ 实现,因为从 object 继承的 __ne__ 的后备行为适合我们:当 __eq__ 被定义且不返回 NotImplemented 时,__ne__ 返回该结果的否定。
换句话说,给定我们在 示例 16-15 中使用的相同对象,!= 的结果是一致的:
>>> va != vb
False
>>> vc != v2d
False
>>> va != (1, 2, 3)
True
从 object 继承的 __ne__ 的工作方式如下代码所示——只是原始代码是用 C 编写的:⁶
def __ne__(self, other):
eq_result = self == other
if eq_result is NotImplemented:
return NotImplemented
else:
return not eq_result
在介绍了中缀运算符重载的基本知识之后,让我们转向另一类运算符:增强赋值运算符。
增强赋值运算符
我们的 Vector 类已经支持增强赋值运算符 += 和 *=。这是因为增强赋值对于不可变接收者通过创建新实例并重新绑定左侧变量来工作。
示例 16-16 展示了它们的运行方式。
示例 16-16. 使用 += 和 *= 与 Vector 实例
>>> v1 = Vector([1, 2, 3])
>>> v1_alias = v1 # ①
>>> id(v1) # ②
4302860128 >>> v1 += Vector([4, 5, 6]) # ③
>>> v1 # ④
Vector([5.0, 7.0, 9.0]) >>> id(v1) # ⑤
4302859904 >>> v1_alias # ⑥
Vector([1.0, 2.0, 3.0]) >>> v1 *= 11 # ⑦
>>> v1 # ⑧
Vector([55.0, 77.0, 99.0]) >>> id(v1)
4302858336
①
创建一个别名,以便稍后检查 Vector([1, 2, 3]) 对象。
②
记住绑定到 v1 的初始 Vector 的 ID。
③
执行增强加法。
④
预期的结果…
⑤
…但是创建了一个新的 Vector。
⑥
检查 v1_alias 以确认原始的 Vector 没有被改变。
⑦
执行增强乘法。
⑧
再次,预期的结果,但是创建了一个新的 Vector。
如果一个类没有实现 Table 16-1 中列出的原地操作符,增强赋值运算符将作为语法糖:a += b 将被完全解释为 a = a + b。这是对于不可变类型的预期行为,如果你有 __add__,那么 += 将可以工作而无需额外的代码。
然而,如果你实现了一个原地操作符方法,比如 __iadd__,那么该方法将被调用来计算 a += b 的结果。正如其名称所示,这些操作符预期会就地更改左操作数,并且不会像结果那样创建一个新对象。
警告
不可变类型如我们的 Vector 类不应该实现原地特殊方法。这是相当明显的,但无论如何值得声明。
为了展示就地运算符的代码,我们将扩展BingoCage类,从示例 13-9 实现__add__和__iadd__。
我们将子类称为AddableBingoCage。示例 16-17 是我们想要+运算符的行为。
示例 16-17。+运算符创建一个新的AddableBingoCage实例
>>> vowels = 'AEIOU'
>>> globe = AddableBingoCage(vowels) # ①
>>> globe.inspect()
('A', 'E', 'I', 'O', 'U')
>>> globe.pick() in vowels # ②
True
>>> len(globe.inspect()) # ③
4
>>> globe2 = AddableBingoCage('XYZ') # ④
>>> globe3 = globe + globe2
>>> len(globe3.inspect()) # ⑤
7
>>> void = globe + [10, 20] # ⑥
Traceback (most recent call last):
...
TypeError: unsupported operand type(s) for +: 'AddableBingoCage' and 'list'
①
创建一个具有五个项目(每个vowels)的globe实例。
②
弹出其中一个项目,并验证它是否是vowels之一。
③
确认globe只剩下四个项目。
④
创建第二个实例,有三个项目。
⑤
通过将前两个实例相加创建第三个实例。这个实例有七个项目。
⑥
尝试将AddableBingoCage添加到list中会导致TypeError。当我们的__add__方法返回NotImplemented时,Python 解释器会产生该错误消息。
因为AddableBingoCage是可变的,示例 16-18 展示了当我们实现__iadd__时它将如何工作。
示例 16-18。现有的AddableBingoCage可以使用+=加载(继续自示例 16-17)
>>> globe_orig = globe # ①
>>> len(globe.inspect()) # ②
4
>>> globe += globe2 # ③
>>> len(globe.inspect())
7
>>> globe += ['M', 'N'] # ④
>>> len(globe.inspect())
9
>>> globe is globe_orig # ⑤
True
>>> globe += 1 # ⑥
Traceback (most recent call last):
...
TypeError: right operand in += must be 'Tombola' or an iterable
①
创建一个别名,以便稍后检查对象的标识。
②
这里的globe有四个项目。
③
一个AddableBingoCage实例可以接收来自同一类的另一个实例的项目。
④
+=的右操作数也可以是任何可迭代对象。
⑤
在整个示例中,globe一直指的是与globe_orig相同的对象。
⑥
尝试将不可迭代的内容添加到AddableBingoCage中会失败,并显示适当的错误消息。
注意+=运算符相对于第二个操作数更加宽松。对于+,我们希望两个操作数的类型相同(在这种情况下为AddableBingoCage),因为如果我们接受不同类型,可能会导致对结果类型的混淆。对于+=,情况更加清晰:左侧对象在原地更新,因此对结果的类型没有疑问。
提示
通过观察list内置类型的工作方式,我验证了+和+=的对比行为。编写my_list + x,你只能将一个list连接到另一个list,但如果你写my_list += x,你可以使用右侧的任何可迭代对象x扩展左侧的list。这就是list.extend()方法的工作方式:它接受任何可迭代的参数。
现在我们清楚了AddableBingoCage的期望行为,我们可以查看其在示例 16-19 中的实现。回想一下,BingoCage,来自示例 13-9,是TombolaABC 的具体子类,来自示例 13-7。
示例 16-19。bingoaddable.py:AddableBingoCage扩展BingoCage以支持+和+=
from tombola import Tombola
from bingo import BingoCage
class AddableBingoCage(BingoCage): # ①
def __add__(self, other):
if isinstance(other, Tombola): # ②
return AddableBingoCage(self.inspect() + other.inspect())
else:
return NotImplemented
def __iadd__(self, other):
if isinstance(other, Tombola):
other_iterable = other.inspect() # ③
else:
try:
other_iterable = iter(other) # ④
except TypeError: # ⑤
msg = ('right operand in += must be '
"'Tombola' or an iterable")
raise TypeError(msg)
self.load(other_iterable) # ⑥
return self # ⑦
①
AddableBingoCage扩展BingoCage。
②
我们的__add__只能与Tombola的实例作为第二个操作数一起使用。
③
在__iadd__中,从other中检索项目,如果它是Tombola的实例。
④
否则,尝试从other中获取一个迭代器。⁷
⑤
如果失败,引发一个解释用户应该做什么的异常。 在可能的情况下,错误消息应明确指导用户解决方案。
⑥
如果我们走到这一步,我们可以将 other_iterable 加载到 self 中。
⑦
非常重要:可变对象的增强赋值特殊方法必须返回 self。 这是用户的期望。
我们可以通过对比在示例 16-19 中产生结果的 __add__ 和 __iadd__ 中的 return 语句来总结就地运算符的整个概念:
__add__
通过调用构造函数 AddableBingoCage 来生成结果以构建一个新实例。
__iadd__
通过修改后返回 self 生成结果。
结束这个示例时,对示例 16-19 的最后观察:按设计,AddableBingoCage 中没有编写 __radd__,因为没有必要。 前向方法 __add__ 仅处理相同类型的右操作数,因此如果 Python 尝试计算 a + b,其中 a 是 AddableBingoCage 而 b 不是,则返回 NotImplemented—也许 b 的类可以使其工作。 但是如果表达式是 b + a 而 b 不是 AddableBingoCage,并且返回 NotImplemented,那么最好让 Python 放弃并引发 TypeError,因为我们无法处理 b。
提示
一般来说,如果一个前向中缀运算符方法(例如 __mul__)设计为仅与与 self 相同类型的操作数一起使用,那么实现相应的反向方法(例如 __rmul__)是没有用的,因为根据定义,只有在处理不同类型的操作数时才会调用它。
我们的 Python 运算符重载探索到此结束。
章节总结
我们从回顾 Python 对运算符重载施加的一些限制开始:不能在内置类型本身中重新定义运算符,重载仅限于现有运算符,有一些运算符被排除在外(is、and、or、not)。
我们从一元运算符入手,实现了 __neg__ 和 __pos__。 接下来是中缀运算符,从 + 开始,由 __add__ 方法支持。 我们看到一元和中缀运算符应通过创建新对象来生成结果,并且永远不应更改其操作数。 为了支持与其他类型的操作,我们返回 NotImplemented 特殊值—而不是异常—允许解释器通过交换操作数并调用该运算符的反向特殊方法(例如 __radd__)再次尝试。 Python 用于处理中缀运算符的算法在图 16-1 中总结。
混合操作数类型需要检测我们无法处理的操作数。 在本章中,我们以两种方式实现了这一点:在鸭子类型方式中,我们只是继续尝试操作,如果发生 TypeError 异常,则捕获它;稍后,在 __mul__ 和 __matmul__ 中,我们通过显式的 isinstance 测试来实现。 这些方法各有利弊:鸭子类型更灵活,但显式类型检查更可预测。
一般来说,库应该利用鸭子类型——打开对象的大门,无论它们的类型如何,只要它们支持必要的操作即可。然而,Python 的运算符分发算法可能在与鸭子类型结合时产生误导性的错误消息或意外的结果。因此,在编写用于运算符重载的特殊方法时,使用isinstance调用 ABCs 进行类型检查的纪律通常是有用的。这就是亚历克斯·马特利所称的鹅类型技术,我们在“鹅类型”中看到了。鹅类型是灵活性和安全性之间的一个很好的折衷方案,因为现有或未来的用户定义类型可以声明为 ABC 的实际或虚拟子类。此外,如果一个 ABC 实现了__subclasshook__,那么对象通过提供所需的方法可以通过该 ABC 的isinstance检查—不需要子类化或注册。
我们接下来讨论的话题是丰富的比较运算符。我们用__eq__实现了==,并发现 Python 在object基类中提供了一个方便的!=实现,即__ne__。Python 评估这些运算符的方式与>, <, >=, 和 <=略有不同,对于选择反向方法有特殊逻辑,并且对于==和!=有后备处理,因为 Python 比较对象 ID 作为最后的手段,从不生成错误。
在最后一节中,我们专注于增强赋值运算符。我们看到 Python 默认将它们处理为普通运算符后跟赋值的组合,即:a += b被完全解释为a = a + b。这总是创建一个新对象,因此适用于可变或不可变类型。对于可变对象,我们可以实现就地特殊方法,比如__iadd__用于+=,并改变左操作数的值。为了展示这一点,我们放下了不可变的Vector类,开始实现一个BingoCage子类,支持+=用于向随机池添加项目,类似于list内置支持+=作为list.extend()方法的快捷方式。在这个过程中,我们讨论了+相对于接受的类型更为严格的问题。对于序列类型,+通常要求两个操作数是相同类型,而+=通常接受任何可迭代对象作为右操作数。
进一步阅读
Guido van Rossum 在“为什么运算符有用”中写了一篇很好的运算符重载辩护。Trey Hunner 在博客“Python 中的元组排序和深度比较”中辩称,Python 中的丰富比较运算符比程序员从其他语言转换过来时可能意识到的更灵活和强大。
运算符重载是 Python 编程中一个常见的地方,其中isinstance测试很常见。围绕这些测试的最佳实践是鹅类型,详见“鹅类型”。如果你跳过了这部分,请确保阅读一下。
运算符特殊方法的主要参考是 Python 文档中的“数据模型”章节。另一个相关阅读是Python 标准库中numbers模块的“9.1.2.2. 实现算术运算”。
一个聪明的运算符重载例子出现在 Python 3.4 中添加的pathlib包中。它的Path类重载了/运算符,用于从字符串构建文件系统路径,如文档中所示的示例:
>>> p = Path('/etc')
>>> q = p / 'init.d' / 'reboot'
>>> q
PosixPath('/etc/init.d/reboot')
另一个非算术运算符重载的例子是Scapy库,用于“发送、嗅探、解剖和伪造网络数据包”。在 Scapy 中,/运算符通过堆叠来自不同网络层的字段来构建数据包。详见“堆叠层”。
如果你即将实现比较运算符,请研究functools.total_ordering。这是一个类装饰器,可以自动生成定义了至少一些富比较运算符的类中的所有富比较运算符的方法。请参考functools 模块文档。
如果你对动态类型语言中的运算符方法分派感兴趣,两篇开创性的文章是 Dan Ingalls(原 Smalltalk 团队成员)的“处理多态的简单技术”,以及 Kurt J. Hebel 和 Ralph Johnson(Johnson 因为是原始《设计模式》书籍的作者之一而出名)的“Smalltalk-80 中的算术和双重分派”。这两篇论文深入探讨了动态类型语言(如 Smalltalk、Python 和 Ruby)中多态的强大之处。Python 不使用这些文章中描述的双重分派来处理运算符。Python 算法使用前向和后向运算符对于用户定义的类来说更容易支持,但需要解释器进行特殊处理。相比之下,经典的双重分派是一种通用技术,你可以在 Python 或任何面向对象的语言中使用,超越了中缀运算符的特定上下文,事实上,Ingalls、Hebel 和 Johnson 使用非常不同的例子来描述它。
文章“C 语言家族:与丹尼斯·里奇、比雅尼·斯特劳斯特鲁普和詹姆斯·高斯林的访谈”,我引用了本章前言中的摘录,发表于Java Report,2000 年 7 月,第 5 卷第 7 期,以及C++ Report,2000 年 7 月/8 月,第 12 卷第 7 期,还有本章“讲台”中使用的另外两个片段。如果你对编程语言设计感兴趣,请务必阅读该访谈。
¹ 来源:“C 语言家族:与丹尼斯·里奇、比雅尼·斯特劳斯特鲁普和詹姆斯·高斯林的访谈”。
² Python 标准库中剩余的 ABC 对于鹅类型和静态类型仍然有价值。numbers ABC 的问题在“数字 ABC 和数值协议”中有解释。
³ 请参考https://en.wikipedia.org/wiki/Bitwise_operation#NOT解释按位非操作。
⁴ Python 文档同时使用这两个术语。“数据模型”章节使用“reflected”,但numbers模块文档中的“9.1.2.2. 实现算术运算”提到“forward”和“reverse”方法,我认为这个术语更好,因为“forward”和“reversed”清楚地命名了每个方向,而“reflected”没有明显的对应词。
⁵ 请参考“讲台”讨论该问题。
⁶ object.__eq__和object.__ne__的逻辑在 CPython 源代码的Objects/typeobject.c中的object_richcompare函数中。
⁷ iter内置函数将在下一章中介绍。在这里,我可以使用tuple(other),它也可以工作,但会建立一个新的tuple,而所有.load(…)方法需要的只是对其参数进行迭代。










