
数据智能产业创新服务媒体
——聚焦数智 · 改变商业
ChatGPT引发了一次AI发展的高潮,并一定程度上让AI实现了破圈。目前,ChatGPT的全球用户已经超过1亿,在整个社会层面都引起了广泛的讨论。但同时,落地困难这个AI的老大难的问题,ChatGPT一样需要面对。探索垂直行业的应用场景,是ChatGPT实现商业化突破的一个重要方向。
一方面,ChatGPT产品需要强大的底层大规模预训练模型技术;另一方面,如何与具体的应用场景相结合,实现商业化价值。那么,有没有可能将这两个方面结合起来呢?
科技创新信息服务商智慧芽给出了一个解决方案——大模型技术+研发情报库,用AI技术赋能研发创新,实现“一石二鸟”。
数据猿专访了智慧芽副总裁屠昶旸,来探讨ChatGPT这类大模型应用与科技创新信息服务相结合的价值,以及具体的实现路径。
谁可以将ChatGPT引入科技创新信息服务领域?
用AI技术创新来赋能研发,给科技创新一个加速度,比单独的一项技术突破有更大的价值。但是,越有价值的事情,实现起来往往难度越大。
具体来看,要想将ChatGPT这类大模型技术引入研发情报服务领域,需要具备一系列的条件:
- 要有覆盖面足够广泛的研发数据库
要提供研发情报服务,最核心的资源就是相关的数据资源,比如专利、文献等。并且,数据覆盖面要足够广泛,不仅要有中国的全量数据,还要有全球其他国家的数据。此外,在生物、医学等专业性很强的领域,还需要建立专门的数据库。要将ChatGPT引入科技创新信息服务领域,最关键的动作就是用科技创新信息数据集来训练相关的模型。数据量越大、数据质量越高,最终训练出来的模型才越强大。相对于ChatGPT主要用公开的互联网数据集,专利、文献等专业数据的获取难度更大。可以说,数据资源是科技创新信息服务最核心的壁垒。
- 要有专门针对科技创新信息服务领域数据分析的算法模型
要让ChatGPT从一个通才,成长为在科技创新信息服务领域的专家,除了有专业数据集外,针对科技创新信息服务领域的算法调优和创新,也是关键的一步。
- 要有优秀的产品能力
用户直接面对的是产品,而不是技术。因此,要想将ChatGPT底层的大模型技术服务于科技创新,就必须要将技术封装成便于用户使用的产品。而且,针对不同的科技创新服务需求,要构建针对性的产品,进而形成相对完备的产品矩阵。以产品矩阵的方式,来为技术创新人员提供一站式服务。
作为领先的科技创新信息服务商,智慧芽很好的满足了上述条件,具体来看:
在数据层面,智慧芽有三类数据,分别是专利文献数据、科研信息数据、生物医药数据,具体涵盖:1.76亿+全球专利数据,1.6亿+科技文献数据;260万+科研资助信息、90万+市场报告、86万+投资信息、1000万+财务新闻;6.1万+全球新药数据、4.4万+靶点数据。这些数据,为智慧芽构建了坚实的竞争壁垒,也为其训练类ChatGPT大模型,奠定了很好的数据基础。

在算法层面,据智慧芽副总裁屠昶旸所说,智慧芽已经有比较深厚的AI技术积累,通过运用深度学习、自然语言处理(NLP)、计算机视觉以及预训练语言模型等AI技术,现已实现在海量全球多语言技术文本中进行自动化、智能化的数据分析与文本挖掘,并能进一步实现深层次语义分析,为用户提供更精准的语义检索服务。并且,基于这些AI技术智慧芽推出了“AI智能标题&摘要”、“AI机器学习标引”等独特功能。
尤其是在智慧芽自研预训练模型,在大模型领域已经有较强的技术积累。因此,此次智慧芽要打造的研发版ChatGPT,并不是简单地调取别人的API,而是基于开源大模型,融合智慧芽自身的AI技术,推演出多个垂直领域的成熟模型,满足专利、科技创新情报、生物医药等各垂直领域的专业领域需求。
在产品层面,智慧芽针对不同用户群体,构建了完善的产品矩阵,具体来看:针对研发和知识产权人群推出了专利数据库、知识产权管理系统、研发情报库、竞争情报库等产品;针对生物医药人群推出了新药情报库、生物序列数据库、化学结构数据库产品;针对政府、金融人群推出了科创力评估、产业技术链、专利价值分析产品等。通过这一系列产品矩阵,来为科技创新赋能。
为什么要打造研发版ChatGPT?
正如科技创新永无止境一样,为科技创新提供信息服务的创新也永无止境。需要指出的是,不要为了创新而创新,创新是为了更好的解决目前还存在的各项问题。那么,目前科技创新信息服务领域还存在哪些显著的问题和需求痛点呢?具体来看,主要表现在两个方面:
- 用户还停留在关键词搜索阶段,系统还不能很好理解用户复杂的业务需求。
以专利数据库为例,目前大部分专利数据库产品本质上就是专利领域的搜索引擎,用户通过关键词,在专利数据库里搜索对应的专利或者文献信息,较很难表述出用户复杂、结构化的需求。
以目前大火的ChatGPT为例,ChatGPT背后的技术是AI大模型,用户如果要想了解大规模预训练模型的相关技术,用目前的产品一般是输入“大模型”、“预训练模型”等关键词,然后系统返回跟这个技术相关的大量专利、文献。如果用户想知道ChatGPT有哪些技术,大模型又有哪些核心技术,这些技术之间有什么样的关系,不同的技术在ChatGPT的最终表现方面分别发挥什么样的作用?类似这些更深入的信息,简单的搜索或检索信息就很难满足需求。即使能实现需求,也需要用户本身就具备相关的专业知识,并能熟练掌握专利相关高级功能,经过多步相对繁琐的操作,最终才能得到关于大模型更深入、完善的信息。但这对于绝大多数普通用户而言,使用门槛过高,不利于在更广泛的范围内提升科技创新效率。
- 搜索引擎模式,返回的是大量技术文档,而不是直接的答案。
跟搜索引擎类似,用户搜索相应关键词后,返回的是大量的技术文档。如果是热门的技术领域,则可能有成千上万的文献,如此巨大的阅读量对于研发人员而言是一个不小的负担。系统虽然返回了最相关的文档,但评估每篇文献的价值,理解每篇文献的主要内容,这些工作大多还是需要用户自己去完成。专业技术文献的阅读难度本身就很高,如果要在短时间内阅读大量文献才能知道想要的结果,无疑是一个非常低效的方式。这样的科技创新信息服务,还停留在工具阶段,不能称之为强大的助手。
ChatGPT+研发情报库,智慧芽要变革科技创新信息服务方式
为了有效解决上述问题,进一步提升科技创新信息服务的效率,智慧芽在业界首次将将大模型引入科技创新信息服务领域,打造ChatGPT+研发情报库的融合解决方案,研发版ChatGPT将于年内推出。
据屠昶旸向数据猿透露,智慧芽早在2年前就已启动相关技术布局,Demo版产品已在路上。相比以往科技创新信息服务产品,智慧芽打造的研发版ChatGPT将在以下三个方面实现革命性体验:
- 实现用自然语言交互,系统可以理解用户的复杂需求。
用户要查询专利、技术、企业数据,不再局限于关键词,而是可以用一段自然语言的方式,来表述自己的需求,这大大降低用户门槛。例如,当用户想要了解ChatGPT背后的大模型技术,可以用一段话来完整的描述自己的需求,“我要想了解ChatGPT背后的技术,尤其是大规模预训练模型的技术。帮我查一查相关的技术专利和论文。依据技术的不同对结果进行分类,每项核心技术返回我10项影响力最大的专利和论文。分析一下这些技术专利都来自于哪些公司和机构,其中,中国公司又有多少技术专利和有影响力的论文。”系统可以从用户的描述中完整的理解其需求,并将需求“解构”成对应的指令。
这种方式,当用户在寻求科技创新信息服务时,面对的系统就像是一个专业的科研助手,而不是一个只能听懂只言片语的冰冷机器。用户可以像跟人交流一样,以自己舒服的方式来说出自己的需求,系统可以像人类助手一样从用户的描述中去“理解”真实的需求。
- 返回用户期望的答案,而不是技术文档。
系统根据用户需求,替用户阅度大量的专利、技术文档,然后将自己整理、“思考”之后的结果呈现给用户。这种情况下,用户得到的不再是一堆技术文档,而是一个答案。
为了给出一个简单明确的答案,系统在背后要为用户做大量的工作:文献搜索,系统利用专利和论文数据库的搜索引擎获取相关的专利和论文;单篇文献阅读,系统借助文本挖掘、机器学习、文本聚类、文本分类、实体识别等一系列技术,来帮助用户“阅读”文献,并从中提炼总结出核心内容;多篇文献内容总结,在单篇文章阅读理解的基础上,系统会根据每篇文章的核心内容,来从大量的文献资料中总结用户所想要的答案;结构化结果呈现,系统不仅会给出一个答案,还可以依据用户需求进行一系列操作,比如对专利、论文进行分类,依据其影响力进行排名,对多项技术专利的关联度进行分析,依据公司发布的专利数量和质量来评估该公司在特定领域的技术实力等。
- 多轮问答,针对特定技术领域进行深入探索。
多轮对话能力的突破,是ChatGPT优于以往对话式AI的一大亮点。借助这一能力,科技创新信息服务系统可以引导用户通过多轮对话的方式,一步步进行更深入的分析。在多轮对话中,用户可以在已经得到的结果基础上,发布新的需求。在很多时候,用户可能并不清楚自己想要查些什么内容,当看到相关内容之后,会“激发”用户的灵感,从而问出更深入的问题。这种方式,系统不仅是助手,还可以是“导师”,循循善诱的引导用户自己去寻求答案。
以下是我们用ChatGPT模拟的一个用专利数据库分析大模型技术情况的案例,结果如下:



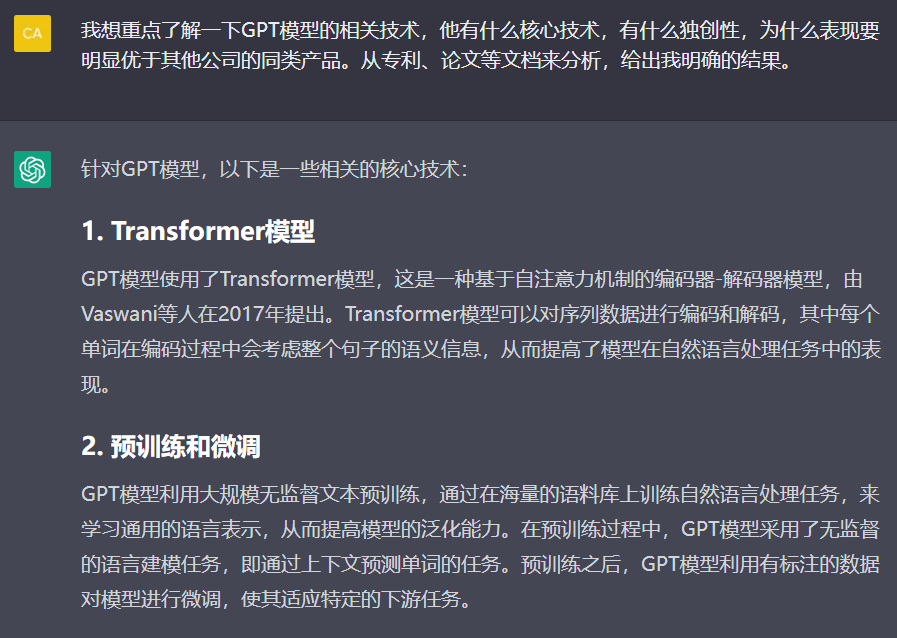




从以上的模拟案例来看,ChatGPT给出的答案比较好的满足了上面的三个诉求,即用自然语言描述复杂需求、返回答案而不是一堆文档、多轮交互后的深入分析。但是,单凭ChatGPT,会存在两个明显的缺陷:缺乏专业的数据库支持,ChatGPT搜索的专利、论文大多来源于公开的互联网或专利数据库,而构建高质量的专利、文献数据库是一件困难的事情,一些高质量、商业化的专利数据库可能并不对其开放。如果缺乏专业数据库的支持,ChatGPT后续的一些分析都是空中楼阁;只能返回文本内容,形式单一。要获得更深刻的洞见,就需要进行一些数据分析,并以丰富的图表来呈现分析的结果。单凭ChatGPT,是很难做到这一点的。
智慧芽正好可以弥补ChatGPT的上述缺陷,既可以提供专业的数据库,还能提供多样化的分析结果。
我们简单以大规模预训练模型中的“自然语言处理”这个技术分支通过智慧芽研发情报库的关键词搜索,显示有近19.3万条技术数据,其中微软拥有超过4600条技术数据。
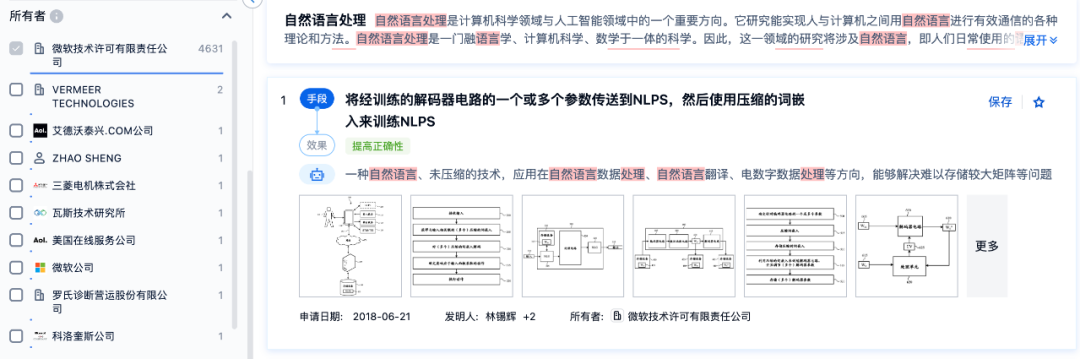
图源:智慧芽研发情报库
甚至,仅用一张比亚迪最新发布的仰望U8搭载的“易四方”动力系统照片,也能简单快速搜索出该产品的核心技术介绍。
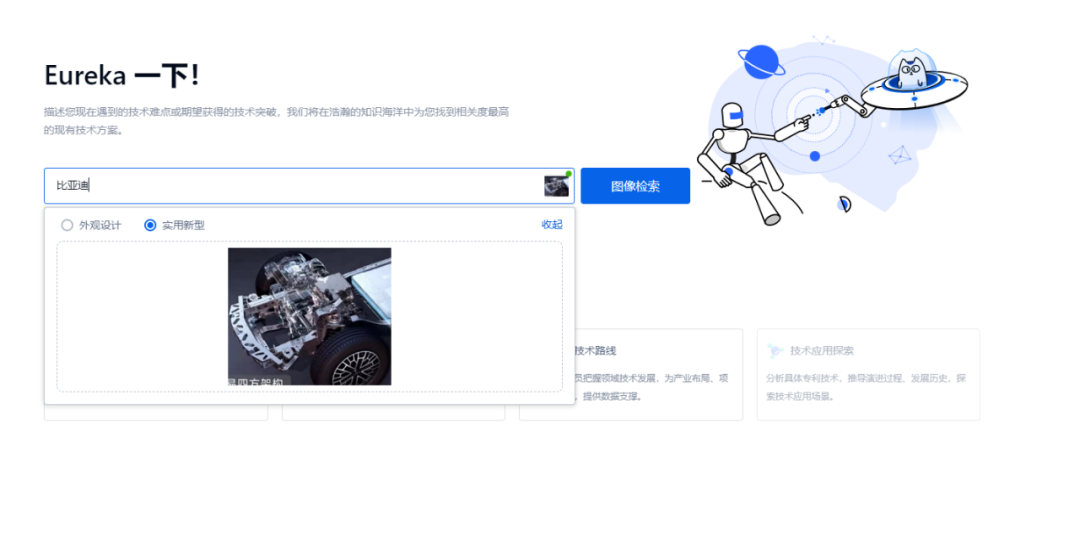
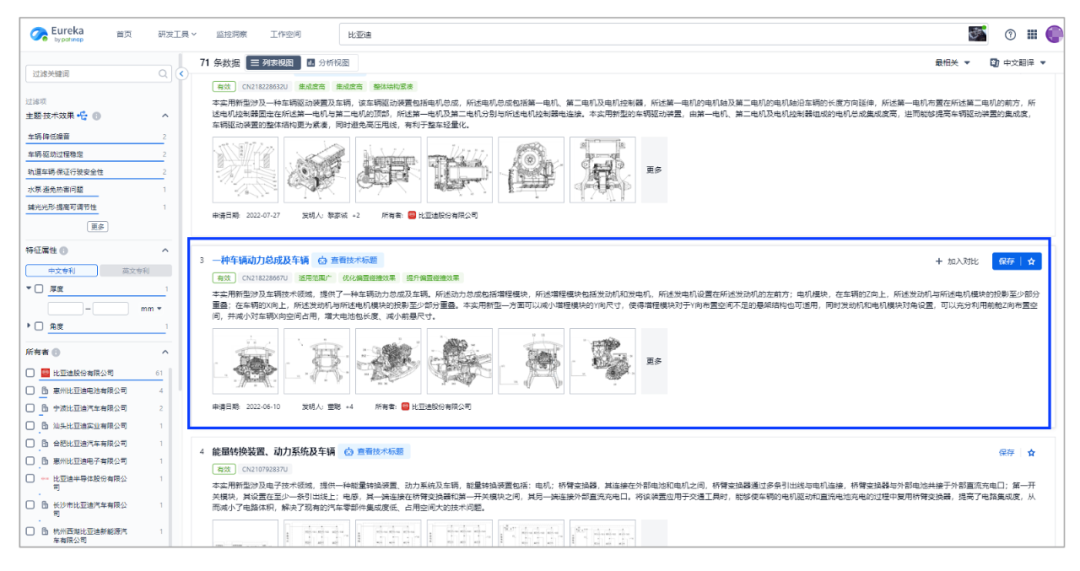
图源:智慧芽研发情报库
试想一下,如果将智慧芽的产品,融入ChatGPT的能力,将对科技创新信息服务带来多么巨大的变革!
正如智慧芽副总裁屠昶旸所言,“我们的理想形态是‘AIGC+搜索引擎’的模式。当用户提出问题后,该应用可快速理解用户意图,并从相关搜索结果中给出润色过的总结性回答。未来,只要用户输入问题就能得到想要的答案,仅需通过一个聊天框或者其他形式,即可调用智慧芽底层的产品能力。”
以下是智慧芽的新产品Demo,让我们先睹为快。
文:月满西楼 / 数据猿










