第1关:逻辑回归核心思想
任务描述
本关任务:根据本节课所学知识完成本关所设置的编程题。
相关知识
为了完成本关任务,你需要掌握:
-
什么是逻辑回归;
-
sigmoid函数。
什么是逻辑回归
当一看到“回归”这两个字,可能会认为逻辑回归是一种解决回归问题的算法,然而逻辑回归是通过回归的思想来解决二分类问题的算法。
那么问题来了,回归的算法怎样解决分类问题呢?其实很简单,逻辑回归是将样本特征和样本所属类别的概率联系在一起,假设现在已经训练好了一个逻辑回归的模型为 f(x) ,模型的输出是样本 x 的标签是 1 的概率,则该模型可以表示, p^=f(x) 。若得到了样本 x 属于标签 1 的概率后,很自然的就能想到当 p^>0.5 时 x 属于标签 1 ,否则属于标签 0 。所以就有
y^={01p^<0.5p^>0.5
(其中 y^ 为样本 x 根据模型预测出的标签结果,标签 0 和标签 1 所代表的含义是根据业务决定的,比如在癌细胞识别中可以使 0 代表良性肿瘤, 1 代表恶性肿瘤)。
由于概率是 0 到 1 的实数,所以逻辑回归若只需要计算出样本所属标签的概率就是一种回归算法,若需要计算出样本所属标签,则就是一种二分类算法。
那么逻辑回归中样本所属标签的概率怎样计算呢?其实和线性回归有关系,学习了线性回归的同学肯定知道线性回归无非就是训练出一组参数 WT 和 b 来拟合样本数据,线性回归的输出为 y^=WTx+b 。不过 y^ 的值域是 (−∞,+∞) ,如果能够将值域为 (−∞,+∞) 的实数转换成 (0,1) 的概率值的话问题就解决了。要解决这个问题很自然地就能想到将线性回归的输出作为输入,输入到另一个函数中,这个函数能够进行转换工作,假设函数为 σ ,转换后的概率为 p^ ,则逻辑回归在预测时可以看成p^=σ(WTx+b) 。 σ 其实就是接下来要介绍的sigmoid函数。
sigmoid 函数
sigmoid函数的公式为:
σ(t)=1/(1+e−t)
函数图像如下图所示:
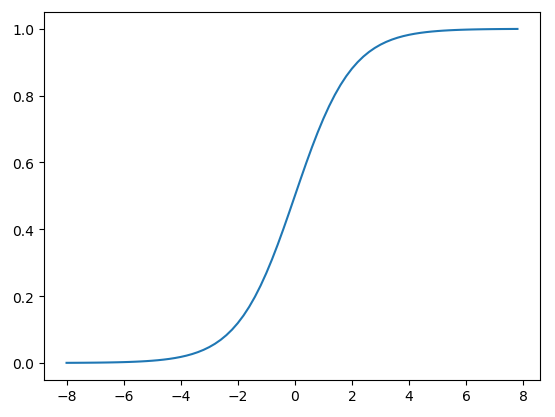
从sigmoid函数的图像可以看出当 t 趋近于 −∞ 时函数值趋近于 0 ,当 t 趋近于 +∞ 时函数值趋近于 1 。可见sigmoid函数的值域是 (0,1) ,满足我们要将 (−∞,+∞) 的实数转换成 (0,1) 的概率值的需求。因此逻辑回归在预测时可以看成
p^=1/(1+e−WTx+b)
编程要求
根据提示,在右侧编辑器补充 Python 代码,实现sigmoid函数。底层代码会调用您实现的sigmoid函数来进行测试。(提示: numpy.exp()函数可以实现 e 的幂运算)
测试说明
测试用例:
输入:1
预期输出:0.73105857863
输入:-2
预期输出:0.119202922022
#encoding=utf8
import numpy as np
def sigmoid(t):
'''
完成sigmoid函数计算
:param t: 负无穷到正无穷的实数
:return: 转换后的概率值
:可以考虑使用np.exp()函数
'''
#********** Begin **********#
return 1.0/(1+np.exp(-t))
#********** End **********#第2关:逻辑回归的损失函数
任务描述
本关任务:根据本节课所学知识完成本关所设置的选择题。
相关知识
为什么需要损失函数
训练逻辑回归模型的过程其实与之前学习的线性回归一样,就是去寻找合适的 WT 和 b 使得模型的预测结果与真实结果尽可能一致。所以就需要一个函数能够衡量模型拟合程度的好坏,也就是说当模型拟合误差越大的时候,函数值应该比较大,反之应该比较小,这就是损失函数。
逻辑回归的损失函数
根据上一关中所学习到的知识,我们已经知道了逻辑回归计算出的样本所属类别的概率 p^=σ(WTx+b) ,样本所属列表的判定条件为
y^={01p^<0.5p^>0.5
很明显,在预测样本属于哪个类别时取决于算出来的p^。从另外一个角度来说,假设现在有一个样本的真实类别为 1 ,模型预测样本为类别 1 的概率为 0.9 的话,就意味着这个模型认为当前样本的类别有 90% 的可能性为 1 ,有 10% 的可能性为0。所以从这个角度来看,逻辑回归的损失函数与 p^ 有关。
当然逻辑回归的损失函数不仅仅与 p^ 有关,它还与真实类别有关。假设现在有两种情况,情况A:现在有个样本的真实类别是 0 ,但是模型预测出来该样本是类别 1 的概率是 0.7 (也就是说类别 0 的概率为 0.3 );情况B:现在有个样本的真实类别是 0 ,但是模型预测出来该样本是类别 1 的概率是 0.6 (也就是说类别 0 的概率为 0.4 );请你思考 2 秒钟,AB两种情况哪种情况的误差更大?很显然,情况A的误差更大!因为情况A中模型认为样本是类别 0 的可能性只有 30% ,而B有 40% 。
假设现在又有两种情况,情况A:现在有个样本的真实类别是 0 ,但是模型预测出来该样本是类别 1 的概率是 0.7 (也就是说类别 0 的概率为 0.3 );情况B:现在有个样本的真实类别是 1 ,但是模型预测出来该样本是类别 1 的概率是 0.3 (也就是说类别 0 的概率为 0.7 );请你再思考 2 秒钟,AB两种情况哪种情况的误差更大?很显然,一样大!
所以逻辑回归的损失函数如下,其中 cost 表示损失函数的值, y 表示样本的真实类别:
cost=−ylog(p^)−(1−y)log(1−p^)
这个式子其实很好理解,当样本的真实类别为 1 时,式子就变成了 cost=−log(p^)。此时函数图像如下:

从图像能看出当样本的真实类别为1的前提下,p^ 越大,损失函数值就越小。因为 p^ 越大就越说明模型越认为该样本的类别为 1 。
当样本的真实类别为 0 时,式子就变成了 cost=−log(1−p^) 。此时函数图像如下:

从图像能看出当样本的真实类别为 0 的前提下,hatp 越大,损失函数值就越大。因为 p^ 越大就越说明模型越认为该样本的类别为 1 。
cost=−ylog(p^)−(1−y)log(1−p^) 是一个样本的损失计算公式,但是在一般情况下需要计算的是 m 条样本数据的平均损失值,所以损失函数的最终形态如下,其中 m 表示数据集中样本的数量, i 表示数据集中第 i 个样本:
cost=−m1sumi=0my(i)log(p^(i))−(1−y(i))log(1−p^(i))
知道了逻辑回归的损失函数之后,逻辑回归的训练流程就很明显了,就是寻找一组合适的 WT 和 b ,使得损失值最小。找到这组参数后模型就确定下来了。
编程要求
根据相关知识,按照要求完成右侧选择题任务,包含单选题和多选题。
测试说明
平台会对你选择的答案进行判断,全对则通过测试。
1、
逻辑回归的损失函数可以写成如下形式 (A)
^
−log( p ) y=1
cost={
^
−log(1− p y=0
A、对
B、错
2、下列说法正确的是 (A、C、D)
A、损失值能够衡量模型在训练数据集上的拟合程度
B、sigmoid函数不可导
C、sigmoid函数的输入越大,输出就越大
D、训练的过程,就是寻找合适的参数使得损失函数值最小的过程
3、sigmoid函数(对数几率函数)相对于单位阶跃函数有哪些好处? (A、B)
A、sigmoid函数可微分
B、sigmoid函数处处连续
C、sigmoid函数不是单调的
D、sigmoid函数最多计算二阶导
4、逻辑回归的优点有哪些? (D)
A、需要事先对数据的分布做假设
B、可以得到“类别”的真正的概率预测
C、可以用闭式解求解
D、可以用现有的数值优化算法求解第3关:梯度下降
任务描述
本关任务:用 Python 构建梯度下降算法,并求取目标函数最小值。
相关知识
为了完成本关任务,你需要掌握:梯度下降算法。
什么是梯度
梯度:梯度的本意是一个向量,由函数对每个参数的偏导组成,表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向变化最快,变化率最大。

梯度下降算法原理
算法思想:梯度下降是一种非常通用的优化算法,能够为大范围的问题找到最优解。梯度下降的中心思想就是迭代地调整参数从而使损失函数最小化。假设你迷失在山上的迷雾中,你能感觉到的只有你脚下路面的坡度。快速到达山脚的一个策略就是沿着最陡的方向下坡。这就是梯度下降的做法:通过测量参数向量 θ 相关的损失函数的局部梯度,并不断沿着降低梯度的方向调整,直到梯度降为 0 ,达到最小值。
梯度下降公式如下:

对应到每个权重公式为:
其中 η 为学习率,是 0 到 1 之间的值,是个超参数,需要我们自己来确定大小。
算法原理: 在传统机器学习中,损失函数通常为凸函数,假设此时只有一个参数,则损失函数对参数的梯度即损失函数对参数的导数。如果刚开始参数初始在最优解的左边,

很明显,这个时候损失函数对参数的导数是小于 0 的,而学习率是一个 0 到 1 之间的数,此时按照公式更新参数,初始的参数减去一个小于 0 的数是变大,也就是在坐标轴上往右走,即朝着最优解的方向走。同样的,如果参数初始在最优解的右边,
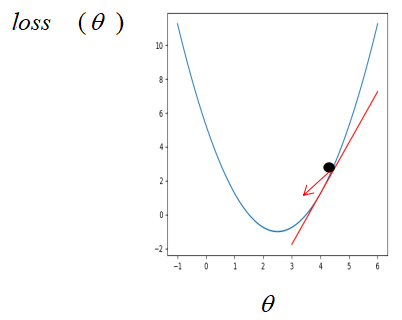
此时按照公式更新,参数将会朝左走,即最优解的方向。所以,不管刚开始参数初始在何位置,按着梯度下降公式不断更新,参数都会朝着最优解的方向走。 #####梯度下降算法流程
- 随机初始参数;
- 确定学习率;
- 求出损失函数对参数梯度;
- 按照公式更新参数;
- 重复 3 、 4 直到满足终止条件(如:损失函数或参数更新变化值小于某个阈值,或者训练次数达到设定阈值)。
编程要求
根据提示,使用 Python 实现梯度下降算法,并损失函数最小值时对应的参数theta,theta会返回给外部代码,由外部代码来判断theta是否正确。
测试说明
损失函数为:loss=2∗(θ−3) 最优参数为:3.0 你的答案跟最优参数的误差低于0.0001才能通关。
# -*- coding: utf-8 -*-
import numpy as np
import warnings
warnings.filterwarnings("ignore")
def gradient_descent(initial_theta,eta=0.05,n_iters=1000,epslion=1e-8):
'''
梯度下降
:param initial_theta: 参数初始值,类型为float
:param eta: 学习率,类型为float
:param n_iters: 训练轮数,类型为int
:param epslion: 容忍误差范围,类型为float
:return: 训练后得到的参数
'''
# 请在此添加实现代码 #
#********** Begin *********#
theta = initial_theta
i_iter = 0
while i_iter < n_iters:
gradient = 2*(theta-3)
last_theta = theta
theta = theta - eta*gradient
if(abs(theta-last_theta)<epslion):
break
i_iter +=1
return theta
#********** End **********#第4关:动手实现逻辑回归 - 癌细胞精准识别
任务描述
本关任务:使用逻辑回归算法建立一个模型,并通过梯度下降算法进行训练,得到一个能够准确对癌细胞进行识别的模型。
相关知识
为了完成本关任务,你需要掌握:
- 逻辑回归算法流程;
- 逻辑回归中的梯度下降。
数据集介绍
乳腺癌数据集,其实例数量是 569 ,实例中包括诊断类和属性,帮助预测的属性一共 30 个,各属性包括为 radius 半径(从中心到边缘上点的距离的平均值), texture 纹理(灰度值的标准偏差)等等,类包括: WDBC-Malignant 恶性和 WDBC-Benign 良性。用数据集的 80% 作为训练集,数据集的 20% 作为测试集,训练集和测试集中都包括特征和类别。其中特征和类别均为数值类型,类别中 0 代表良性, 1 代表恶性。
构建逻辑回归模型
由数据集可以知道,每一个样本有 30 个特征和 1 个标签,而我们要做的事就是通过这 30 个特征来分析细胞是良性还是恶性(其中标签 y=0 表示是良性, y=1 表示是恶性)。逻辑回归算法正好是一个二分类模型,我们可以构建一个逻辑回归模型,来对癌细胞进行识别。模型如下:
z=b+w1x1+w2x2+...+wnxn
y=1+e−z1
其中 xi表示第 i 个特征,wi表示第 i 个特征对应的权重,b表示偏置。 为了方便,我们稍微将模型进行变换:
z=w0x0+w1x1+w2x2+...+wnxn
其中x0等于 1 。
Z=heta.X
heta=(w0,w1,...,wn)
X=(1,x1,...,xn)
y=1+e−θ.X1
我们将一个样本输入模型,如果预测值大于等于 0.5 则判定为 1 类别,如果小于 0.5 则判定为 0 类别。
训练逻辑回归模型
我们已经知道如何构建一个逻辑回归模型,但是如何得到一个能正确对癌细胞进行识别的模型呢?通常,我们先将数据输入到模型,从而得到一个预测值,再将预测值与真实值结合,得到一个损失函数,最后用梯度下降的方法来优化损失函数,从而不断的更新模型的参数 θ ,最后得到一个能够正确对良性细胞和癌细胞进行分类的模型。

在上一节中,我们知道要使用梯度下降算法首先要知道损失函数对参数的梯度,即损失函数对每个参数的偏导,求解步骤如下:
loss=−ylna−(1−y)ln(1−a)
∂w∂loss=∂a∂loss.∂z∂a.∂w∂z
∂a∂loss=−ay−1−a1−y(−1)=a(1−a)a−y
∂z∂a=(1+e−z)2e−z=a.(1−a)
∂w∂z=x
∂w∂loss=(a−y)x
其中a为预测值,y为真实值。 于是,在逻辑回归中的梯度下降公式如下:
wi=wi−η(a−y)xi
训练流程:
同梯度下降算法流程:请参见上一关卡。
编程要求
根据提示,在右侧编辑器Begin-End处补充 Python 代码,构建一个逻辑回归模型,并对其进行训练,最后将得到的逻辑回归模型对癌细胞进行识别。
测试说明
只需返回预测结果即可,程序内部会检测您的代码,预测正确率高于 95% 视为过关。
提示:构建模型时 x0 是添加在数据的左边,请根据提示构建模型,且返回theta形状为(n,),n为特征个数。
# -*- coding: utf-8 -*-
import numpy as np
import warnings
warnings.filterwarnings("ignore")
def sigmoid(x):
'''
sigmoid函数
:param x: 转换前的输入
:return: 转换后的概率
'''
return 1/(1+np.exp(-x))
def fit(x,y,eta=1e-3,n_iters=10000):
'''
训练逻辑回归模型
:param x: 训练集特征数据,类型为ndarray
:param y: 训练集标签,类型为ndarray
:param eta: 学习率,类型为float
:param n_iters: 训练轮数,类型为int
:return: 模型参数,类型为ndarray
'''
# 请在此添加实现代码 #
#********** Begin *********#
theta = np.zeros(x.shape[1])
i_iter = 0
while i_iter < n_iters:
gradient = (sigmoid(x.dot(theta))-y).dot(x)
theta = theta -eta*gradient
i_iter += 1
return theta
#********** End **********#第5关:手写数字识别
任务描述
本关任务:使用sklearn中的LogisticRegression类完成手写数字识别任务。
相关知识
为了完成本关任务,你需要掌握如何使用sklearn提供的LogisticRegression类。
数据简介
本关使用的是手写数字数据集,该数据集有 1797 个样本,每个样本包括 8*8 像素(实际上是一条样本有 64 个特征,每个像素看成是一个特征,每个特征都是float类型的数值)的图像和一个 [0, 9] 整数的标签。比如下图的标签是 2 :

sklearn为该数据集提供了接口,若想使用该数据集,代码如下:
from sklearn import datasetsimport matplotlib.pyplot as plt#加载数据集digits = datasets.load_digits()#X表示图像数据,y表示标签X = digits.datay = digits.target#将第233张手写数字可视化plt.imshow(digits.images[232])
LogisticRegression
LogisticRegression中默认实现了 OVR ,因此LogisticRegression可以实现多分类。LogisticRegression的构造函数中有三个常用的参数可以设置:
-
solver:{'newton-cg' , 'lbfgs', 'liblinear', 'sag', 'saga'}, 分别为几种优化算法。默认为liblinear; -
C:正则化系数的倒数,默认为 1.0 ,越小代表正则化越强; -
max_iter:最大训练轮数,默认为 100 。
和sklearn中其他分类器一样,LogisticRegression类中的fit函数用于训练模型,fit函数有两个向量输入:
-
X:大小为 [样本数量,特征数量] 的ndarray,存放训练样本; -
Y:值为整型,大小为 [样本数量] 的ndarray,存放训练样本的分类标签。
LogisticRegression类中的predict函数用于预测,返回预测标签,predict函数有一个向量输入:
X:大小为[样本数量,特征数量]的ndarray,存放预测样本。
LogisticRegression的使用代码如下:
logreg = LogisticRegression(solver='lbfgs',max_iter =10,C=10)logreg.fit(X_train, Y_train)result = logreg.predict(X_test)
编程要求
填写digit_predict(train_sample, train_label, test_sample)函数完成手写数字识别任务,其中:
-
train_image:训练集图像,类型为ndarray,shape=[-1, 8, 8]; -
train_label:训练集标签,类型为ndarray; -
test_image:测试集图像,类型为ndarray。
测试说明
只需返回预测结果即可,程序内部会检测您的代码,预测正确率高于 0.97 视为过关。
from sklearn.linear_model import LogisticRegression
def digit_predict(train_image, train_label, test_image):
'''
实现功能:训练模型并输出预测结果
:param train_sample: 包含多条训练样本的样本集,类型为ndarray,shape为[-1, 8, 8]
:param train_label: 包含多条训练样本标签的标签集,类型为ndarray
:param test_sample: 包含多条测试样本的测试集,类型为ndarry
:return: test_sample对应的预测标签
'''
#************* Begin ************#
flat_train_image = train_image.reshape((-1, 64))
# 训练集标准化
train_min = flat_train_image.min()
train_max = flat_train_image.max()
flat_train_image = (flat_train_image-train_min)/(train_max-train_min)
# 测试集变形
flat_test_image = test_image.reshape((-1, 64))
# 测试集标准化
test_min = flat_test_image.min()
test_max = flat_test_image.max()
flat_test_image = (flat_test_image - test_min) / (test_max - test_min)
# 训练--预测
rf = LogisticRegression(C=4.0)
rf.fit(flat_train_image, train_label)
return rf.predict(flat_test_image)
#************* End **************#









