增强语言模型Augmented Language Models
https://arxiv.org/abs/2208.03299
提前知识:
BERT(Bidirectional Encoder Representations from Transformers)是一种预训练语言模型,它通过在大规模文本数据上进行预训练,学习文本的双向表示,并在多种NLP任务中展现出卓越的性能。BERT的双向性意味着它能够同时考虑上下文中的前后信息,从而提高了语言理解的准确性。
预训练过程
Bert先是用Mask来提高视野范围的信息获取量,增加duplicate再随机Mask,这样跟RNN类方法依次训练预测没什么区别了除了mask不同位置外;
全局视野极大地降低了学习的难度,然后再用A+B/C来作为样本,这样每条样本都有50%的概率看到一半左右的噪声;
但直接学习Mask A+B/C是没法学习的,因为不知道哪些是噪声,所以又加上next_sentence预测任务,与MLM同时进行训练,这样用next来辅助模型对噪声/非噪声的辨识,用MLM来完成语义的大部分的学习。
BERT优点:
Transformer Encoder因为有Self-attention机制,因此BERT自带双向功能
因为双向功能以及多层Self-attention机制的影响,使得BERT必须使用Cloze版的语言模型Masked-LM来完成token级别的预训练
为了获取比词更高级别的句子级别的语义表征,BERT加入了Next Sentence Prediction来和Masked-LM一起做联合训练
为了适配多任务下的迁移学习,BERT设计了更通用的输入层和输出层
微调成本小
BERT缺点
task1的随机遮挡策略略显粗犷
[MASK]标记在实际预测中不会出现,训练时用过多[MASK]影响模型表现;
每个batch只有15%的token被预测,所以BERT收敛得比left-to-right模型要慢(它们会预测每个token)
BERT对硬件资源的消耗巨大(大模型需要16个tpu,历时四天;更大的模型需要64个tpu,历时四天。
ALM(Augmented Language Models)是对传统语言模型(如LLMs)的一种增强方法。它的目标是通过各种手段来提升语言模型的能力,包括信息获取、LLM Chains(通过LLM调用来增强context)以及各类外部工具的使用等。ALM的特点是具备和外部数据交互和多轮推理的能力,模型所需的信息不再完全依赖于模型参数。
ALM可以被应用于BERT这样的模型上,以进一步提升其在自然语言处理任务中的表现。
Few-shot Learning:就是使用很少的样本来进行分类或回归。让模型具有判断图片“异同”的能力,即让模型看到两张图片后,它能分别出这俩是不是一个类别。先用大的训练数据集训练出一个具备判断“异同”能力的模型,在测试阶段,再给一个小样本数据集(称为Support Set),里面会包含模型没见过的样本类别,然后让模型判断当前给的图片属于 Support Set 中的哪一个类别。Few-shot learning 是 Meta Learning 的 一种,Meta Leanring 就是去学习如何学习。手写字母识别、图片识别。
Few-shot Learning的基本思路(Basic Idea):
学习一个相似度函数(similarity function):sim ( x , x ′ ) 来判别样本的相似,相似度越高,表示这两个样本越可能是同一个类别。例如,可以通过一个很大的数据集学习出一个相似度函数,然后用该函数进行预测。
MMLU大规模多任务语言理解 基准:用于衡量文本模型的多任务准确性。该测试涵盖了57个任务,包括基本数学、美国历史、计算机科学、法律等多个领域。为了在这个测试中获得高准确性,模型必须具备广泛的世界知识和问题解决能力 旨在通过仅在零样本和少样本设置下评估模型来衡量预训练期间获得的知识
背景:
目前为止检索增强模型还没有展示出令人信服的小样本学习能力。论文中,来自 Meta AI Research 等机构的研究者提出小样本学习是否需要模型在其参数中存储大量信息,以及存储是否可以与泛化解耦。他们提出 Atlas,其是检索增强语言模型的一种,拥有很强的小样本学习能力,即使参数量低于目前其它强大的小样本学习模型
atlas在预训练自然语言表征时,增加模型大小一般是可以提升模型在下游任务中的性能。但是这种纯粹依赖模型尺寸进而期望大力出奇迹的想法在未来会越发困难。进一步增加模型大小将带来以下困难:
- GPU/TPU内存不足
- 训练时间会更长
- 模型退化。
两种参数精简技术来降低内存消耗,加快BERT的训练速度
主要内容:
● 首先通过已有的 BERT 运算慢等等问题提出 Atlas , 一种检索增强语言模型,它在知识任务上表现出很强的少数镜头性能,并在预训练和微调期间使用检索 一个检索器与一个语言模型 ( the retriever and the language model ) 。
● 然后 研究了不同技术对训练 Atlas 在一系列下游任务(包括问答和事实检查)上的小样本数据集性能的影响
● 通过 KILT 、 MMLU 、 Additional benchmark 、 消融研究 得出: 带检索的预训练模型对于在少量任务中获得良好的性能是非常重要的
● 最后总结分析 Atlas 模型的优势:保持最新、可控、快速、 在广泛的知识密集型任务 ( 包括 NaturalQuestions 、 TriviaQA 、 FEVER 、 8 KILT 任务和 57MMLU 任务 ) 上具有很强的 few-shot 学习能力
模型:
Atlas是一种检索增强语言模型,它在知识任务上表现出很强的少数镜头性能,并在预训练和微调期间使用检索 一个检索器与一个语言模型。当面对一个任务时,Atlas 依据输入的问题使用检索器从大量语料中生成出最相关的 top-k 个文档,之后将这些文档与问题 query 一同放入语言模型之中,进而产生出所需的输出

● 检索器 基于 Contriever 设计, Contriever 通过无监督数据进行预训练,使用两层编码器, query 与 document 被独立的编码入编码器中,并通过相应输出的点乘获得 query 与 document 的相似度。这种设计使得 Atlas 可以在没有文档标注的情况下,使用对比学习预训练检索器,从而显著降低内存需求 。
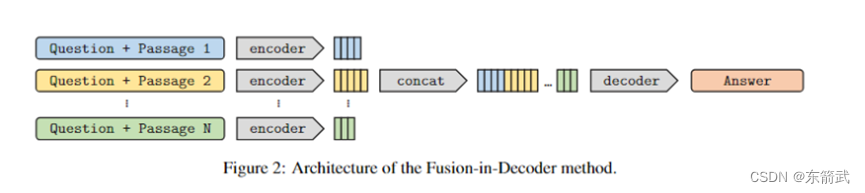
● 语言模型 基于 T5 (encoder-decoder 架构 ) 进行训练,将检索回来的每个 passage 都与 question 拼接为 <question, passage> ,通过 encoder 分别编码,然后 concat 在一起输入 decoder 进行 Cross-Attention ,生成最终的回复。 这种 Fusion-in-Decoder 的方法有利于 Atlas 有效的适应文档数量的扩展 。
● retriever 和 语言模型 LM : 如果语言模型在生成输出时发现有用的文档,则检索器目标应鼓励检索者对所述文档进行更高的排名 。基于这种想法,论文设计 了四 种不同的损失函数 : ADist EMDR2 loop pdIST
创新点:
● 原始的 BERT 模型以及各种依据 Transformer 的预训连语言模型都有一个共同特点,即 E=H , 其中 E 指的是 Embedding Dimension , H 指的是 Hidden Dimension 。这就会导致一个问题,当提升 Hidden Dimension 时, Embedding Dimension 也需要提升,最终会导致参数量呈平方级的 增加。 ALBERT 的作者将 E 和 H 进行解绑 ,具体的操作就是 在 Embedding 后面加入一个矩阵进行维度 变换
● 传统 Transformer 的每一层参数都是独立的,包括各层的 self-attention 、全连接 。 作者尝试将所有层的 参数进行共享 ,相当于 只学习第一层的参数,并在剩下的所有层中重用该层的 参数 , 参数共享可以有效的提升模型 稳定性
● BERT 引入了一个叫做 下一个句子预测 的二分类问题 。 ( NSP ) ALBERT 提出了另一个任务 —— 句子顺序 预测 (SOP) 1. 从 同一个文档中取两个连续的句子作为一个正 样本 2. 交换 这两个句子的顺序,并使用它作为一个负 样本。 SOP 提高了下游多种 任务的表现

模型优势:
● 检索模型的优势:
● 1 . Interpretability and Leakage: 像 Atlas 这样的半参数模型的一个优点是能够检查检索到的项目以帮助可解释性
● 2. Temporal Sensitivity and Updateability: 检索增强模型的一个好处是,它们可以通过在测试时更新或交换索引来保持最新,而无需重新训练。零更新 zero-shot updateability 机制具有保持最新的有用属性,而不需要最新的注释数据或连续的 数据
3. 可控: 通过人为剔除可能会发生泄露的语料信息后,模型正确率从 56.4% 下降到了 55.8% ,仅仅下降 0.6% ,可以看出检索增强的方法可以有效的规避模型作弊的风险









