相关参考地址:
https://github.com/prometheus-community/prometheus-operator.git
https://github.com/prometheus-community/helm-charts/tree/main/charts/kube-prometheus-stack
1.概述
Kube Prometheus Stack是一个基于Prometheus和Grafana的监控解决方案,用于监控Kubernetes集群中的各种资源和服务.
Prometheus Stack,通常指的是 Prometheus和Grafana 以及相关关联集成组件的统称。 在实际的业务场景中,Prometheus 和 Grafana 往往都是协同⼯作进⾏监控 渲染: Prometheus 负责作为数据源获取数据, 并将该数据提供给 Grafana,Grafana 则⽤于借助其吸引⼒的仪表板进⾏可视化数据展示.
2.prometheus-operator 解决问题
prometheus-operator使用K8s的CRD,简化了Prometheus、Alertmanager以及相关监控组件的部署和配置。
3.自定义CRD介绍
CustomResourceDefinitions
- Prometheus:定义了prometheus的部署
- Alertmanager:定义了Alertmanager的部署
- Probe:prometheus的采集规则,目标地址为静态,即地址写死到配置,用于采集集群外部服务
- ServiceMonitor:prometheus的采集规则,使用endpoints服务发现的方式找到目标地址,用于采集集群内部服务
- PodMonitor:prometheus的采集规则,使用pod服务发现的方式找到目标地址,用于采集集群内部服务
- PrometheusRule:prometheus的告警规则
- AlertmanagerConfig:alertmanager的配置
4.安装部署prometheus-stack
4.1 Prerequisites 环境依赖
Kubernetes 1.19+
Helm 3+
K8S实验环境: v1.26.0
4.2 添加helm 源
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update prometheus-communit4.3 Install Helm Chart (prometheus-stack)
注意:
1.域名配置依赖nginx-ingress 服务需要提前进行部署nginx-ingress (ingressClass不要修改)
部署nginx-ingress
kuebctl create ns ingress-nginx
helm install ingress-nginx ingress-nginx/ingress-nginx \
--namespace ingress-nginx \
--set controller.metrics.enabled=true \
--set controller.metrics.serviceMonitor.enabled=true# 查看定制特殊配置项
helm show values prometheus-community/kube-prometheus-stack
#创建监控指定ns
kubectl create ns monitoring
#helm 默认安装
helm install prometheus-stack prometheus-community/kube-prometheus-stack -n monitoring
#携带定制 配置项安装 检查语法参数 (开启相关ingress 域名并配置定制Http域名)
--dry-run=server --dry-run=client 检查语法
helm install test-stack -n monitoring prometheus-community/kube-prometheus-stack \
--set alertmanager.ingress.enabled=true
--set alertmanager.ingress.ingressClassName="nginx" \
--set alertmanager.ingress.hosts[0]=alertmanager.k8s.local \
--set grafana.ingress.enabled=true \
--set grafana.ingress.ingressClassName="nginx" \
--set grafana.adminPassword="admin" \
--set grafana.ingress.hosts[0]=grafana.k8s.local \
--set prometheus.ingress.enabled=true \
--set prometheus.ingress.ingressClassName="nginx" \
--set prometheus.ingress.hosts[0]=prometheus.k8s.local
#更多参数请参考
helm show values prometheus-community/kube-prometheus-stack4.4 安装后服务-验证检查
#helm 检查安装版本信息
[root@k8s]# helm list -n monitoring
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
prometheus-stack monitoring 1 2024-04-06 23:30:19.93912561 +0800 CST deployed kube-prometheus-stack-57.2.1 v0.72.0
#检查安装服务启动
[root@k8s]# kubectl get all -n monitoring
NAME READY STATUS RESTARTS AGE
pod/alertmanager-prometheus-stack-kube-prom-alertmanager-0 2/2 Running 2 (59m ago) 19h
pod/prometheus-prometheus-stack-kube-prom-prometheus-0 2/2 Running 2 (59m ago) 19h
pod/prometheus-stack-grafana-b74597cd9-48r52 3/3 Running 3 (59m ago) 19h
pod/prometheus-stack-kube-prom-operator-5858d66594-t8zmg 1/1 Running 1 (59m ago) 19h
pod/prometheus-stack-kube-state-metrics-d99db88d-6z5gt 1/1 Running 2 (59m ago) 19h
pod/prometheus-stack-prometheus-node-exporter-8c4sz 1/1 Running 1 (59m ago) 19h
pod/prometheus-stack-prometheus-node-exporter-b9xgz 1/1 Running 1 (59m ago) 19h
pod/prometheus-stack-prometheus-node-exporter-cpjkz 1/1 Running 1 (59m ago) 19h
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 19h
service/kube-prometheus-stack-thanos-ruler ClusterIP 10.106.84.128 <none> 10902/TCP 19h
service/prometheus-operated ClusterIP None <none> 9090/TCP 19h
service/prometheus-stack-grafana ClusterIP 10.110.163.7 <none> 80/TCP 19h
service/prometheus-stack-kube-prom-alertmanager ClusterIP 10.110.156.128 <none> 9093/TCP,8080/TCP 19h
service/prometheus-stack-kube-prom-operator ClusterIP 10.96.22.11 <none> 443/TCP 19h
service/prometheus-stack-kube-prom-prometheus ClusterIP 10.102.162.149 <none> 9090/TCP,8080/TCP,10901/TCP 19h
service/prometheus-stack-kube-prom-thanos-discovery ClusterIP None <none> 10901/TCP,10902/TCP 19h
service/prometheus-stack-kube-prom-thanos-external LoadBalancer 10.103.11.172 <pending> 10901:31068/TCP,10902:30601/TCP 19h
service/prometheus-stack-kube-state-metrics ClusterIP 10.109.116.68 <none> 8080/TCP 19h
service/prometheus-stack-prometheus-node-exporter ClusterIP 10.96.201.211 <none> 9100/TCP 19h
service/thanos-ruler-operated ClusterIP None <none> 10902/TCP,10901/TCP 19h
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/prometheus-stack-prometheus-node-exporter 3 3 3 3 3 kubernetes.io/os=linux 19h
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/prometheus-stack-grafana 1/1 1 1 19h
deployment.apps/prometheus-stack-kube-prom-operator 1/1 1 1 19h
deployment.apps/prometheus-stack-kube-state-metrics 1/1 1 1 19h
NAME DESIRED CURRENT READY AGE
replicaset.apps/prometheus-stack-grafana-b74597cd9 1 1 1 19h
replicaset.apps/prometheus-stack-kube-prom-operator-5858d66594 1 1 1 19h
replicaset.apps/prometheus-stack-kube-state-metrics-d99db88d 1 1 1 19h
NAME READY AGE
statefulset.apps/alertmanager-prometheus-stack-kube-prom-alertmanager 1/1 19h
statefulset.apps/prometheus-prometheus-stack-kube-prom-prometheus 1/1 19h
#域名检查
[root8s]# kubectl get ing -n monitoring |grep -E "grafana.k8s.local|alertmanager.k8s.local|prometheus.k8s.local"
prometheus-stack-grafana nginx grafana.k8s.local 80 19h
prometheus-stack-kube-prom-alertmanager nginx alertmanager.k8s.local 80 19h
prometheus-stack-kube-prom-prometheus nginx prometheus.k8s.local 80 19h
#检查生成的CRD资源
[root@]# kubectl get crd |grep monitoring
alertmanagerconfigs.monitoring.coreos.com 2024-04-06T15:29:53Z
alertmanagers.monitoring.coreos.com 2024-04-06T15:29:53Z
podmonitors.monitoring.coreos.com 2024-04-06T15:29:53Z
probes.monitoring.coreos.com 2024-04-06T15:29:53Z
prometheusagents.monitoring.coreos.com 2024-04-06T15:29:53Z
prometheuses.monitoring.coreos.com 2024-04-06T15:29:53Z
prometheusrules.monitoring.coreos.com 2024-04-06T15:29:53Z
scrapeconfigs.monitoring.coreos.com 2024-04-06T15:29:53Z
servicemonitors.monitoring.coreos.com 2024-04-06T15:29:53Z
thanosrulers.monitoring.coreos.com 2024-04-06T15:29:53Z
#检查集群生成的资源对象清单
[root@]# kubectl api-resources |grep -E "alertmanagerconfigs|alertmanagers|podmonitors|probes|prometheusagents|prometheuses|prometheusrules|scrapeconfigs|servicemonitors"
alertmanagerconfigs amcfg monitoring.coreos.com/v1alpha1 true AlertmanagerConfig
alertmanagers am monitoring.coreos.com/v1 true Alertmanager
podmonitors pmon monitoring.coreos.com/v1 true PodMonitor
probes prb monitoring.coreos.com/v1 true Probe
prometheusagents promagent monitoring.coreos.com/v1alpha1 true PrometheusAgent
prometheuses prom monitoring.coreos.com/v1 true Prometheus
prometheusrules promrule monitoring.coreos.com/v1 true PrometheusRule
scrapeconfigs scfg monitoring.coreos.com/v1alpha1 true ScrapeConfig
servicemonitors smon monitoring.coreos.com/v1 true ServiceMonitor4.5 查看监控面板
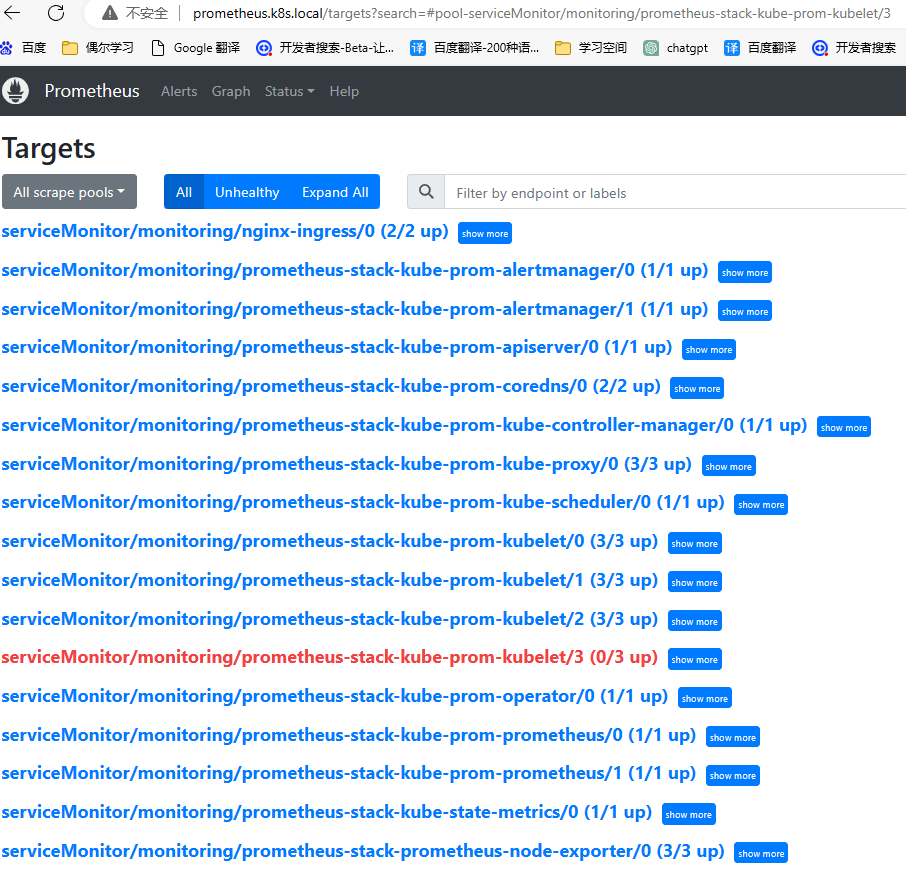
5.配置probe (监控nginx-ingress)
5.1 Probe 外部方式(选择1)
#外部方式
prometheus的采集规则,目标地址为静态,即地址写死到配置,用于采集集群外部服务
apiVersion: monitoring.coreos.com/v1
kind: Probe
metadata:
labels:
app: nginx-ingress
release: prometheus-stack
name: nginx-ingress
namespace: ingress-nginx
spec:
prober:
url: "10.0.0.12:10254"
scheme: http
path: "/metrics"
targets:
staticConfig:
static: ["10.0.0.12:10254", "10.0.0.13:10254"]5.2 ServiceMonitor 采集集群内部服务(选择2)
#监控内部Service 服务
prometheus的采集规则,
使用endpoints服务发现的方式找到目标地址,用于采集集群内部服务.
---
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: nginx-ingress
namespace: monitoring
labels:
release: prometheus-stack
app.kubernetes.io/component: controller
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
app.kubernetes.io/version: 1.10.0
helm.sh/chart: ingress-nginx-4.10.0
spec:
jobLabel: app.kubernetes.io/component
endpoints:
- port: metrics
path: /metrics
interval: 10s
selector:
matchLabels:
app.kubernetes.io/component: controller
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/name: ingress-nginx
namespaceSelector:
any: true5.3 采集集群内部服务-验证

5.4 查看验证nginx-ingress 指标
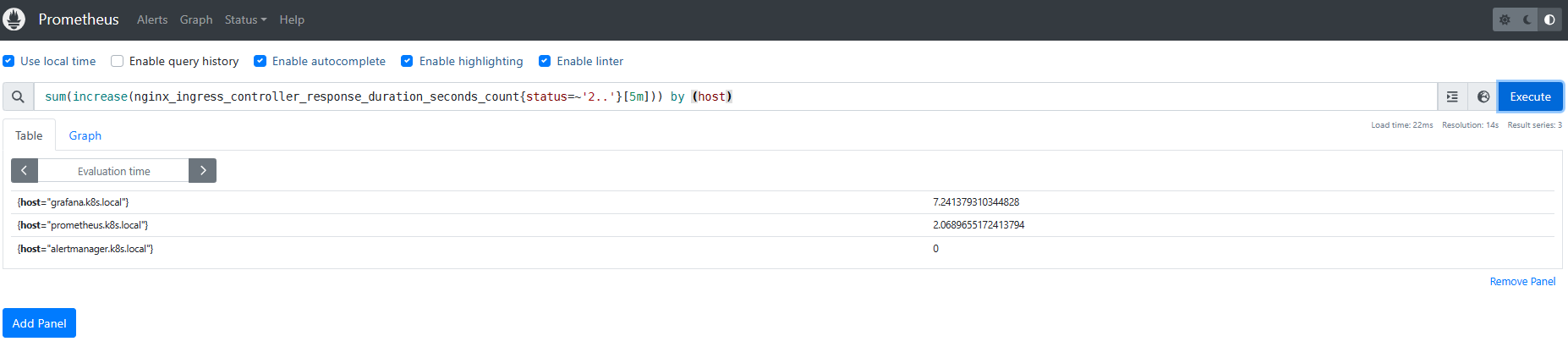
#nginx 统计5分钟域名访问2xx状态码
sum(increase(nginx_ingress_controller_response_duration_seconds_count{status=~'2..'}[5m])) by (host)
#nginx 统计5分钟域名访问5xx状态码
sum(increase(nginx_ingress_controller_response_duration_seconds_count{status=~'2..'}[5m])) by (host)
#nginx/请求P 99/P95 P50延迟
histogram_quantile(0.99,sum(rate(nginx_ingress_controller_request_duration_seconds_bucket{}[2m])) by (le,host))
histogram_quantile(0.90,sum(rate(nginx_ingress_controller_request_duration_seconds_bucket{}[2m])) by (le,host))
histogram_quantile(0.50,sum(rate(nginx_ingress_controller_request_duration_seconds_bucket{}[2m])) by (le,host))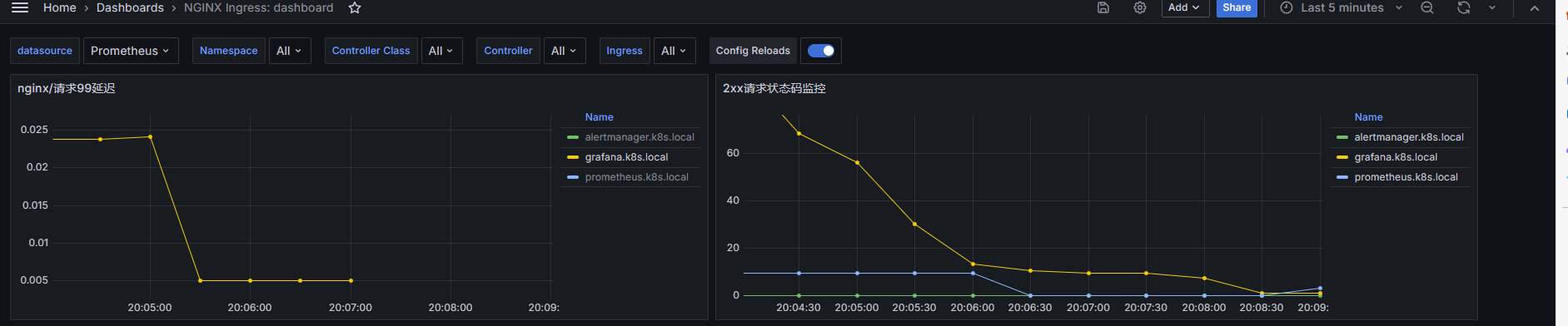
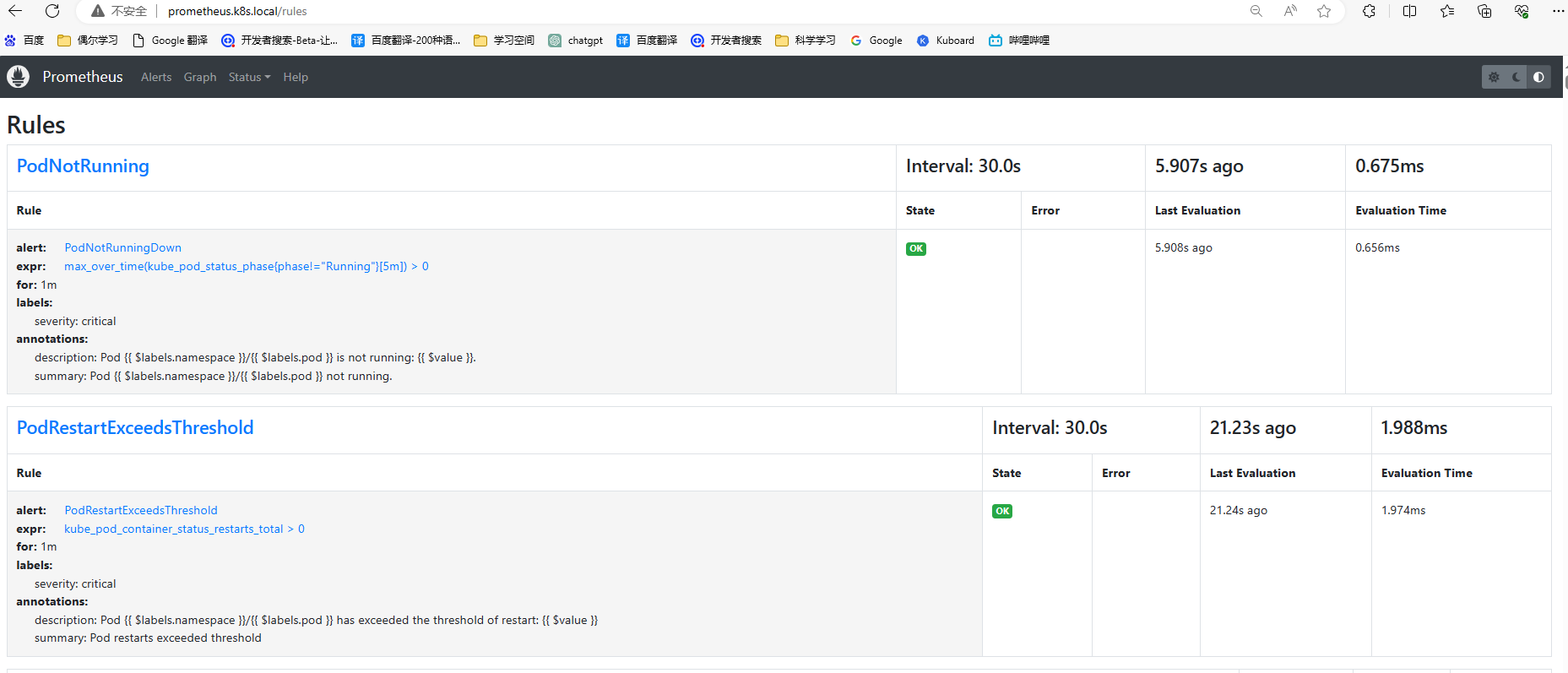
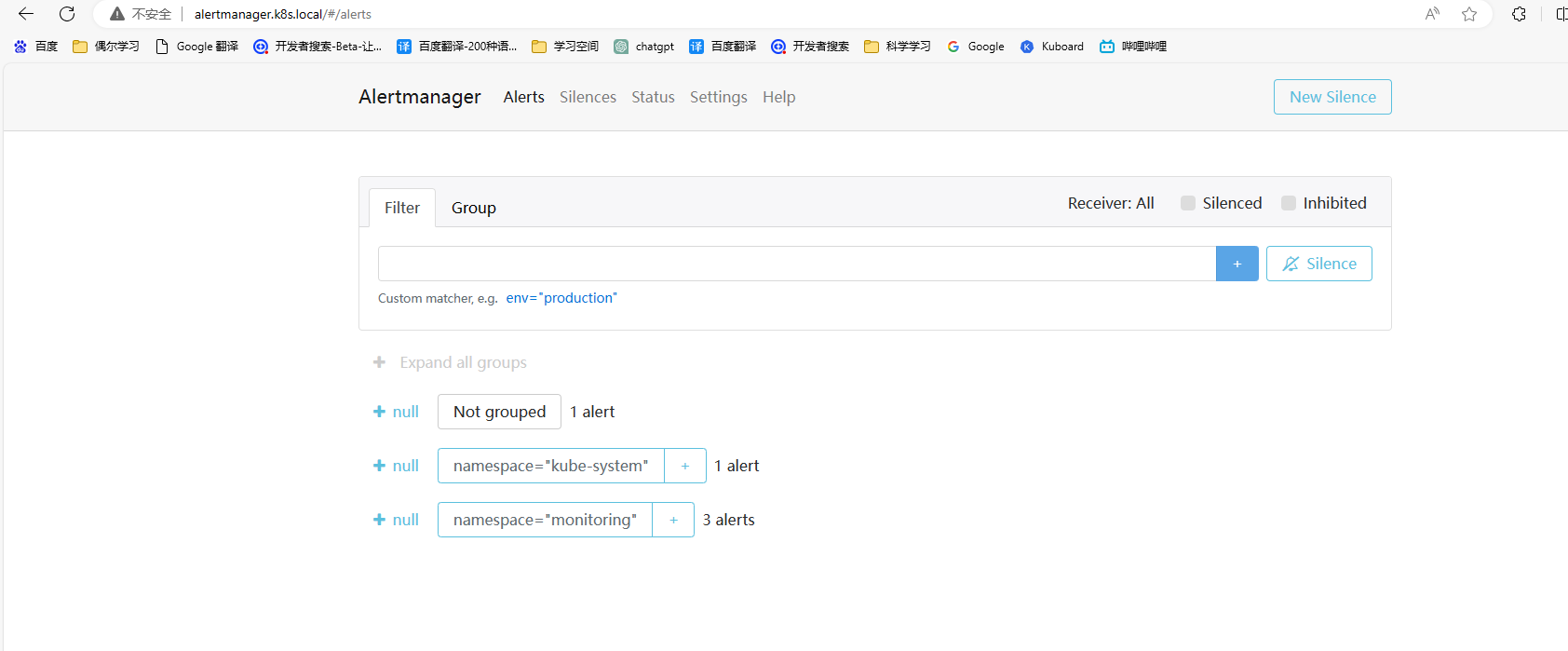
6.配置prometheus告警规则
6.1 配置pod 告警规则
6.1.1 pod 非运行状态/重启次数告警
---
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
release: prometheus-stack
name: prometheus-kube-podnotrunning-rele
namespace: monitoring
spec:
groups:
- name: PodNotRunning
rules:
- alert: PodNotRunningDown
annotations:
description: 'Pod {{ $labels.namespace }}/{{ $labels.pod }} is not running: {{ $value }}.'
summary: 'Pod {{ $labels.namespace }}/{{ $labels.pod }} not running.'
expr: |-
max_over_time(kube_pod_status_phase{phase!="Running"}[5m]) > 0
for: 1m
labels:
severity: critical
---
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
release: prometheus-stack
name: prometheus-pod-restart-exceeds-threshold
namespace: monitoring
spec:
groups:
- name: PodRestartExceedsThreshold
rules:
- alert: PodRestartExceedsThreshold
annotations:
description: "Pod {{ $labels.namespace }}/{{ $labels.pod }} has exceeded the threshold of restart: {{ $value }}"
summary: "Pod restarts exceeded threshold"
expr: |-
kube_pod_container_status_restarts_total
> 0
for: 1m
labels:
severity: critical6.1.2 验证规则是否生效