为什么要进行量化部署
因为大模型在部署时面临以下困难
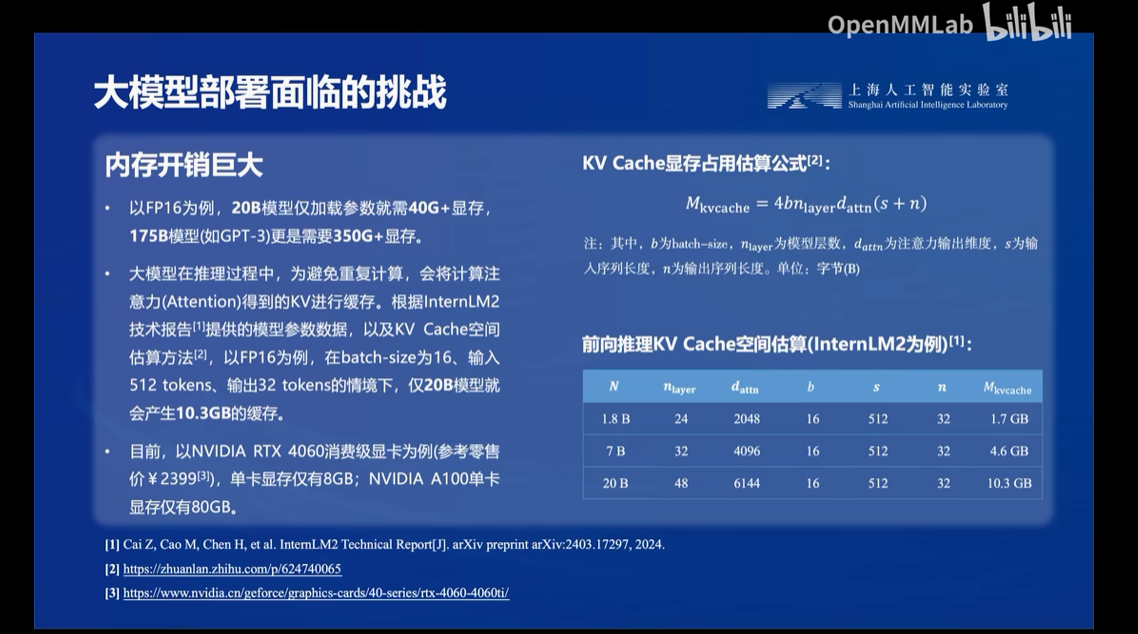
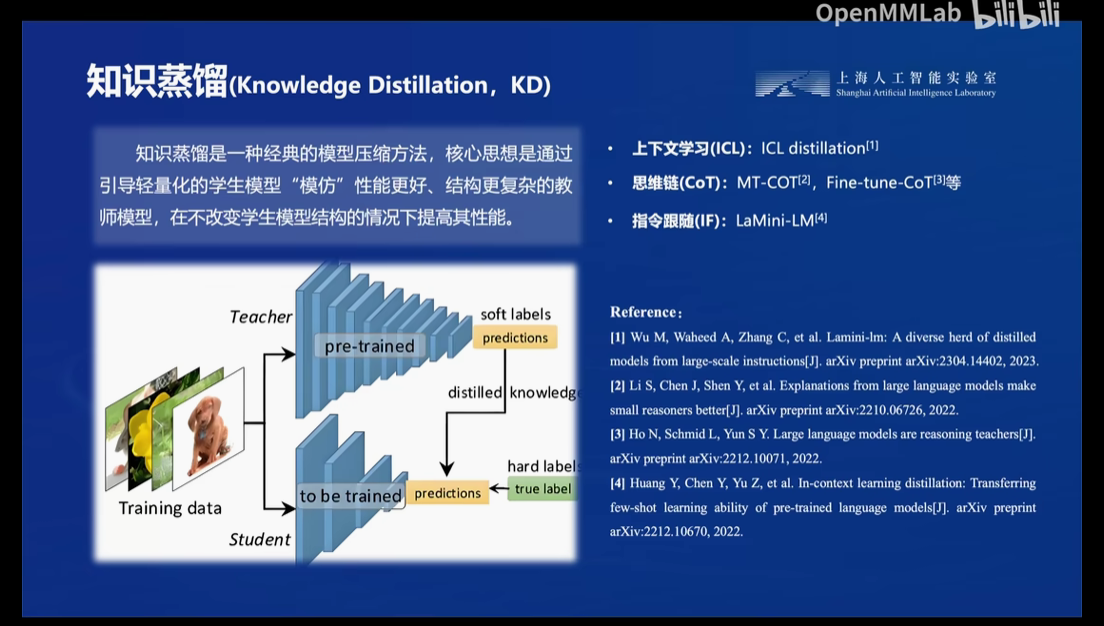
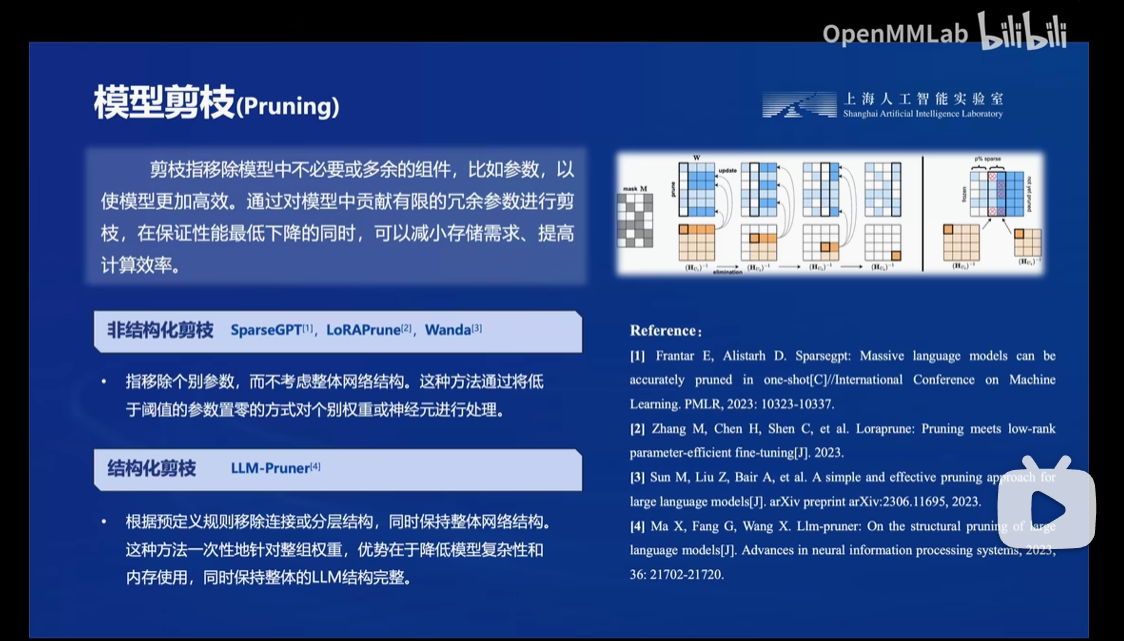
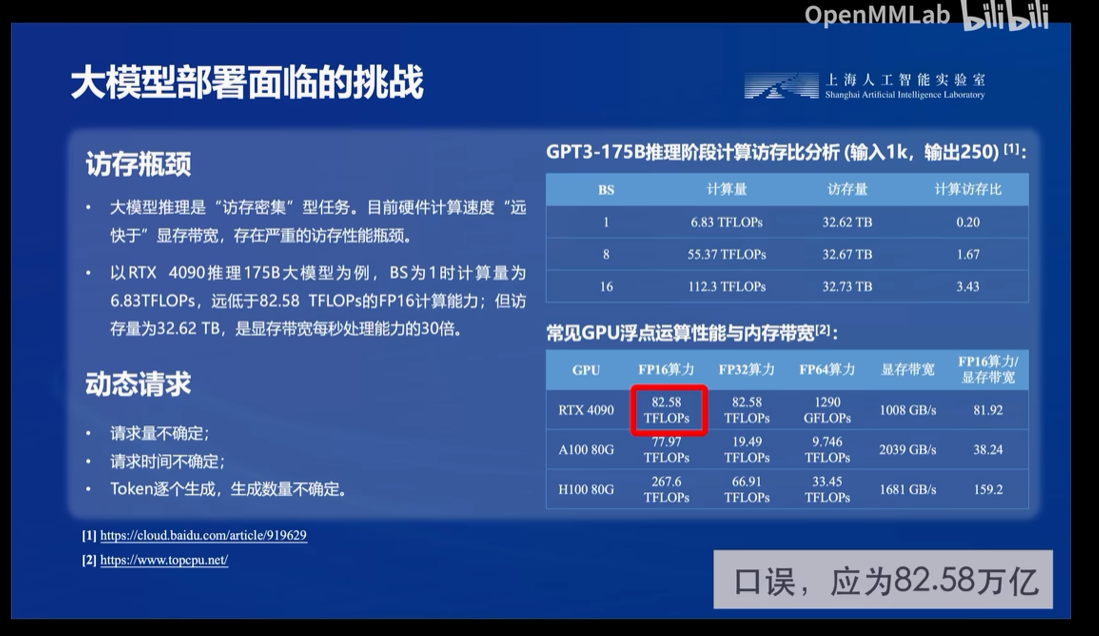 而业内常见的解决方法有模型剪枝,知识蒸馏还有本节讲的量化
而业内常见的解决方法有模型剪枝,知识蒸馏还有本节讲的量化
LMDeploy的优势

LMDeploy部署
步骤依旧是创建虚拟环境,安装LMDeploy,然后是下载模型,这里先是transformer的库运行模型,然后才是用LMDeploy来运行,通过比较这两个模型的运行速度,但感知不太明显
LMDeploy模型量化(lite)
常见的 LLM 模型由于 Decoder Only 架构的特性,实际推理时大多数的时间都消耗在了逐 Token 生成阶段(Decoding 阶段),是典型的访存密集型场景。 那么,如何优化 LLM 模型推理中的访存密集问题呢? 我们可以使用KV8量化和W4A16量化。KV8量化是指将逐 Token(Decoding)生成过程中的上下文 K 和 V 中间结果进行 INT8 量化(计算时再反量化),以降低生成过程中的显存占用。W4A16 量化,将 FP16 的模型权重量化为 INT4,Kernel 计算时,访存量直接降为 FP16 模型的 1/4,大幅降低了访存成本。Weight Only 是指仅量化权重,数值计算依然采用 FP16(需要将 INT4 权重反量化)
设置最大KV Cache缓存大小和使用W4A16量化
通过调整--cache-max-entry-count的参数可以很明显观察到显存占用的变化,但这样会导致推理速度因此发生变化
lmdeploy chat /root/internlm2-chat-1_8b --cache-max-entry-count 0.5
/root/internlm2-chat-1_8b \
--calib-dataset 'ptb' \
--calib-samples 128 \
--calib-seqlen 1024 \
--w-bits 4 \
--w-group-size 128 \
--work-dir /root/internlm2-chat-1_8b-4bit
LMDeploy服务(serve)
在生产环境下,我们有时会将大模型封装为API接口服务,供客户端访问。
步骤依次是启动api 服务器,使用命令行客户端连接服务器,运行后可以直接与它进行对话