大模型隐私主要分为训练阶段、推理阶段以及用户与大模型交互过程中的隐私泄露,目前的研究重点在大模型训练阶段。传统隐私保护技术主要包括联邦学习、差分隐私、同态加密等,这些技术在大模型背景下的应用挑战不断加剧:(1)联邦学习应用于大模型中时更注重使用多个小模型来训练性能更强的大模型,对隐私的关注有所减少;(2)差分隐私应用于大模型中更加爱庞大的数据量和模型参数时,加剧了数据的可用性损失;(3)同态加密因其复杂度很难独立地应用于大模型全局的隐私保护,通常需要结合其他技术或应用于局部隐私保护。大模型的记忆能力带来的隐私泄露风险是大模型中特有的,缓解大模型的记忆能力对于隐私保护具有重要意义。除保护大模型本身的隐私问题以外,使用大模型用于隐私保护(比如AIGC for Privacy、用大模型覆盖数据隐私信息等)等工作也不断发展.
1. Navigating Data Privacy and Analytics: The Role of Large Language Models in Masking conversational data in data platforms

论文链接:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=10433801
这项工作利用LLM进行实时实体识别和替换,有效地屏蔽敏感信息,同时遵守隐私法规。这种方法特别适用于处理来自各种来源的会话数据的第三方分析提供商。利用LLM识别潜在的个人身份信息(PII)或敏感数据点,并用匿名占位符替换,保持数据的结构和上下文完整性。医疗保健场景展示了该方法在外部数据分析提供商的现实环境中的实际应用和效果。
● 方法
作者首先对数据建立基线,提取关键隐私指标(常见症状、患者情绪或医疗查询的趋势),用LLM掩盖敏感信息,确保仅更改数据的个人身份或敏感部分,数据的整体结构和本质保持不变,为实现在对话中保持历史背景(指向同一含义的不同token),方案中使用外部存储,将已识别的PII映射到其匿名对应项。最后对屏蔽数据集进行分析,旨在评估隐私保护后的数据效能是否与保护前相同。
● 实验
数据:ChatGPT3.5提示生成1000名病人、20名医生之间的大约10,000行对话,涉及100种疾病

图1 生成的对话数据
隐私信息处理:GPT-4 Turbo
实验结果(屏蔽效果):谈话中提到的所有姓名、电子邮件地址、医疗记录号码、电话号码、地址、疾病等都被完全屏蔽,但症状并没有被掩盖;
屏蔽后是否能得到相同的数据分析结果(屏蔽对数据效能的影响):每个医生的患者数比较、诊断为特定疾病的患者数量、医生之间的疾病分布
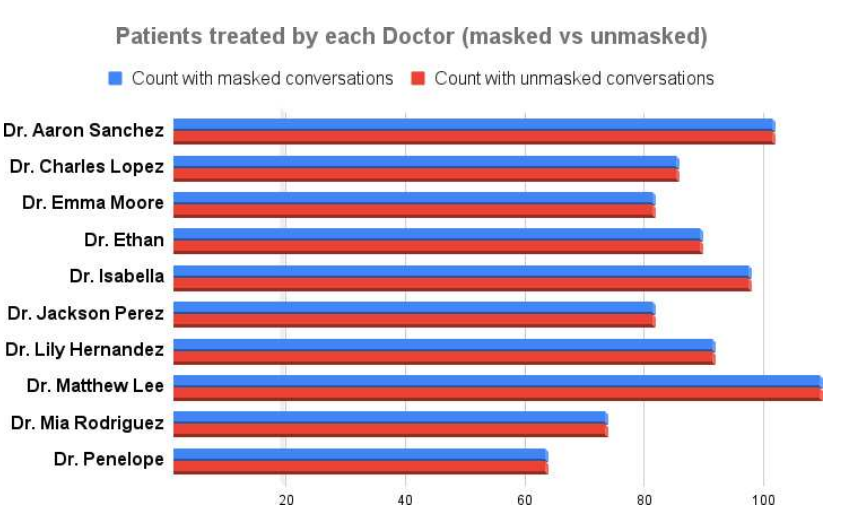
图2 数据被处理前后每个医生的患者数比较
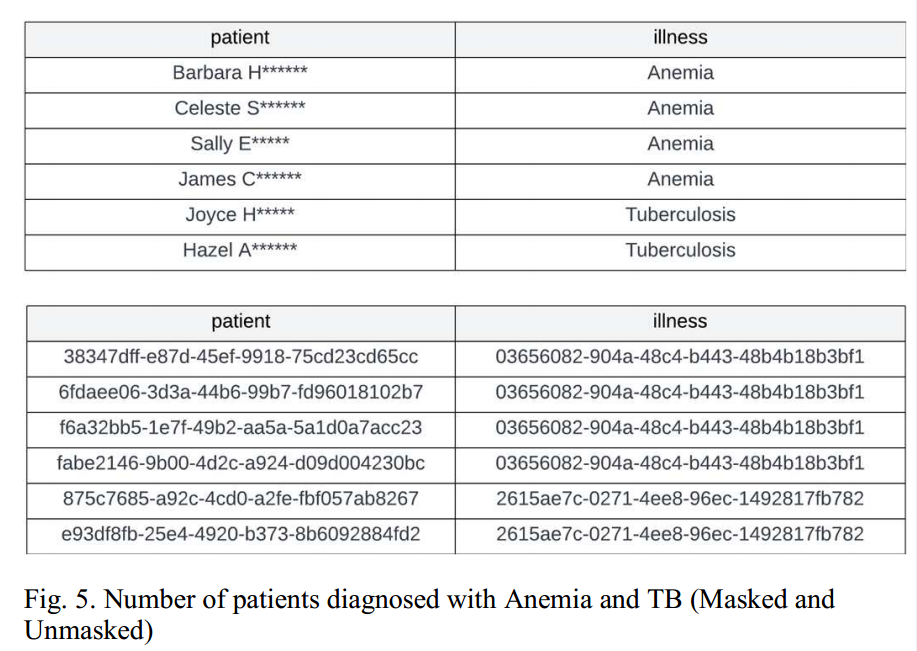
图3 数据被处理前后诊断为特定疾病的患者数量
● 缺点
首先,实验在有限的数据集上进行,可扩展性不强;其次,未开发参数调优,OpenAI提供了各种调优参数来微调模型,这些参数在实验中没有使用;再次,确保跨对话的上下文一致性是一项复杂的任务,这对实现精确的分析一致性提出了挑战。管理上下文一致性所涉及的复杂性需要仔细考虑更准确和可靠的结果;最后,在利用大型语言模型(LLM)进行数据屏蔽时,必须承认LLM方面潜在数据泄漏的固有风险。尽管LLM提供商保证数据安全,但数据泄漏的可能性仍然是一个值得注意的问题。
● 总结
这篇论文介绍了LLM用于隐私保护新用途,通过智能制作的提示,为各个部门量身定制实时识别和掩盖PII。这种方法确保在数据传输到第三方之前删除敏感信息,同时保留数据的分析效用。进入门槛低,而且OpenAI等平台的api易于访问,这使得这种方法具备可行性,在医疗保健部门提出一个假设的案例研究和实验结果中证明了方法的有效性。
大模型用于隐私保护时,首先,大模型本身的隐私问题导致出现更复杂的隐私问题;其次,大模型用于隐私保护的能力本质上还是用户数据赋予的,因此需要有准确的定义与范畴。









