Github主页: https://github.com/RUCAIBox/LLMSurvey
中文版v10:https://github.com/RUCAIBox/LLMSurvey/blob/main/assets/LLM_Survey_Chinese.pdf
英文版v13: https://arxiv.org/abs/2303.18223
解析:大语言模型LLM入门看完你就懂了(一) - SmallerFL的文章 - 知乎
LLMs 关键技术与概念:
大语言模型使用无标注语料库进行预训练,当模型大小达到一定数量,出现智能涌现,能够进行小模型不具备的能力:下文学习,在未经过特定任务微调的情况下能够理解并响应复杂指令**;以及对新任务的适应性,即基于给定的输入示例就能够推断出相应的输出模式
预训练技术:
LLMs 通常采用 Transformer 架构,并基于大规模无标注语料库进行预训练,利用自回归或双向预测的语言建模任务来捕捉语言规律。
分布式训练算法:
由于 LLMs 的参数数量巨大,需要采用高效的分布式训练策略和工具(如DeepSpeed 和 Megatron-LM)以实现模型的有效训练。
适应性调整:
为使预训练后的 LLMs 更好地服务于特定应用场景,采用诸如提示工程、链式思维提示、指令调优等方法挖掘和引导模型的潜在能力。
一致性和控制:
确保 LLMs 的行为符合人类价值观和伦理规范至关重要,因此研究领域也关注如何通过一致性微调、强化学习和人工反馈等方式来改进模型的输出质量,降低有害内容的生成风险。
缩放定律(Scaling Laws):
LLMs 的性能与模型大小、数据量以及计算资源之间存在着密切关系。研究人员发现,随着模型参数规模的增长,通过遵循一定的幂律关系(如 KM 缩放定律),模型性能可以显著提升。例如,GPT-3 和 PaLM 等模型分别扩展至1750亿和5400亿参数级别,以验证这种规模效应。研究者还探讨了如何在有限的计算预算下更高效地分配资源,比如 Chinchilla 模型通过增加训练数据量而非单纯增大模型尺寸来优化性能。
涌现能力(Emergent Abilities):
当LLMs达到一定规模后,它们展现出了一些小型模型所不具备的特殊能力。这些“涌现”能力包括上下文学习,在未经过特定任务微调的情况下能够理解并响应复杂指令;以及对新任务的适应性,即基于给定的输入示例就能够推断出相应的输出模式。这表明大模型可能具有更强的泛化能力和生成多样、准确文本的能力。这种能力并非线性或连续地随模型尺度扩大而出现,而是当模型超过某个阈值时突然展现出显著超越小型模型的新技能。LLMs 所展示的三种典型新兴能力如下:
上下文学习(In-context Learning):GPT-3 首次正式引入了这一概念,当向语言模型提供自然语言指令和/或多个任务示例后,即使没有进行额外训练或梯度更新,该模型也能通过完成输入文本的词序列生成测试实例的预期输出。
例如,在 GPT 系列模型中,参数规模达到1750亿的 GPT-3 在一般任务上表现出了强大的上下文学习能力,而较小规模的 GPT-1 和 GPT-2 则不具备这种能力。同时,不同任务对上下文学习的要求程度不一,如 GPT-3 在解决简单的算术任务时表现出色,但在处理特定复杂任务(如波斯语问答任务)时可能效果不佳。
指令跟随(Instruction following):
通过使用多任务数据集并以自然语言描述的方式进行微调,LLMs 能够在新任务中遵循给出的指令执行任务,并且在没有显式示例的情况下展现出更好的泛化能力。实验表明,像 LaMDA-PT 这样的模型经过指令调优后,当模型大小达到 68B 时,其在未见过的任务上的性能显著优于未经调优的版本,而对于更小规模如 8B 以下的模型,则无法观察到同样的优势。
分步推理(Step-by-step reasoning):
小型语言模型通常难以处理涉及多个推理步骤的复杂任务,比如数学文字问题。然而,通过采用链式思维(chain-of-thought, CoT)提示策略,LLMs 能够利用中间推理步骤的提示机制来解决此类任务。CoT 策略使得大模型(如超过60B参数的 PaLM 和LaMDA 变体)在执行需要逐步推理的问题时获得性能提升,尤其在参数量级超过100B时,相较于标准提示的优势更加明显。此外,对于不同的任务类型,CoT 带来的性能改善程度也会有所不同,例如在某些数学问题解答基准(如 GSM8K、MAWPS 和 SWAMP)上表现各异。这些能力可能与大规模模型在训练过程中接触到大量代码相关联,从而获得了相应的技能。
图2 语言模型的发展过程
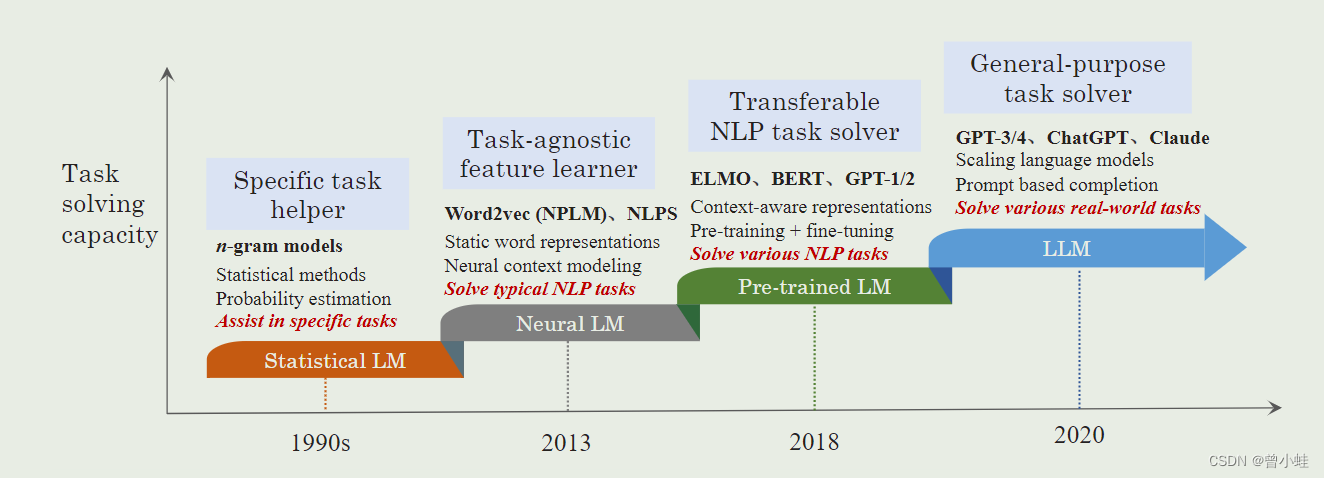
图3 现有大型语言模型的时间线
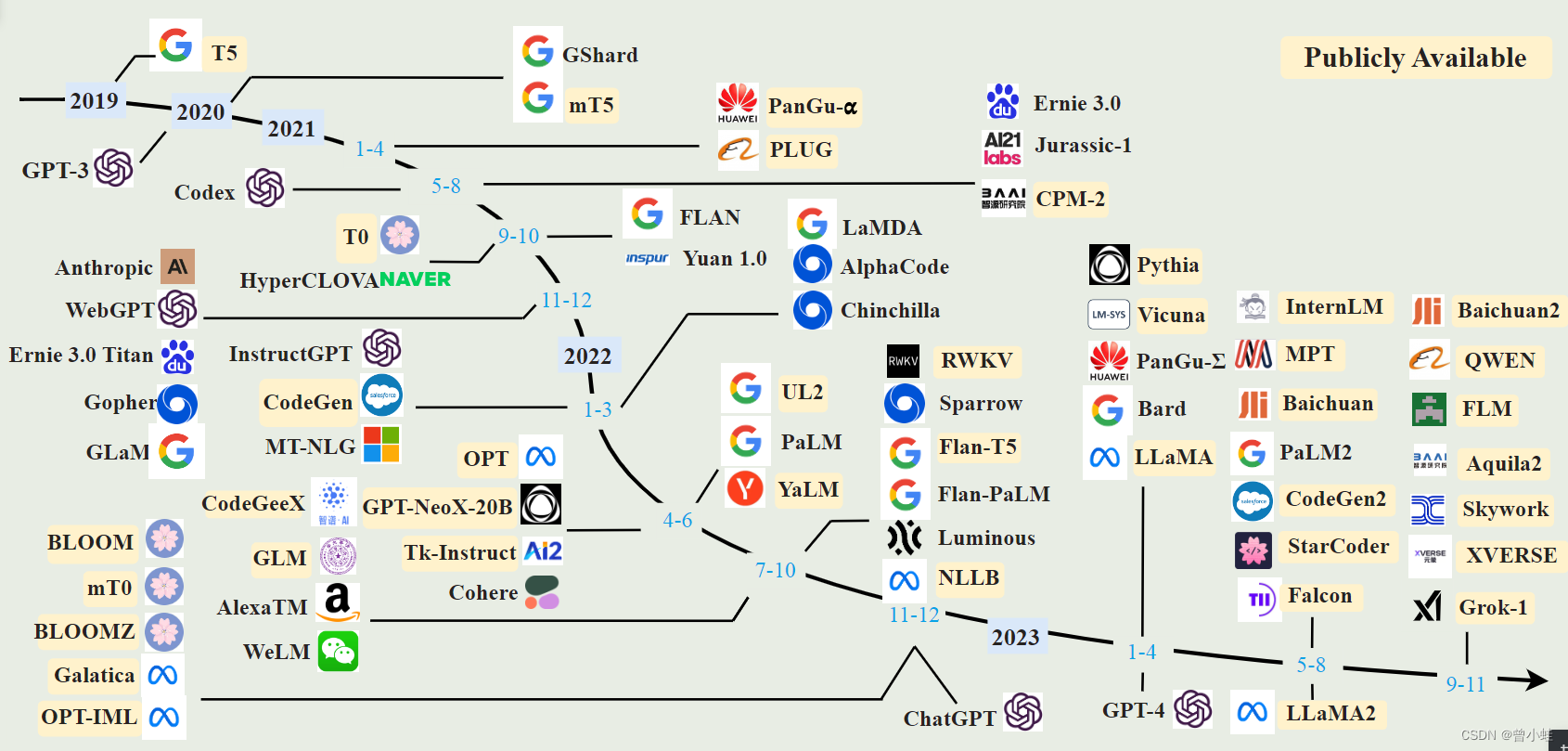
图4: OpenAI的GPT系列
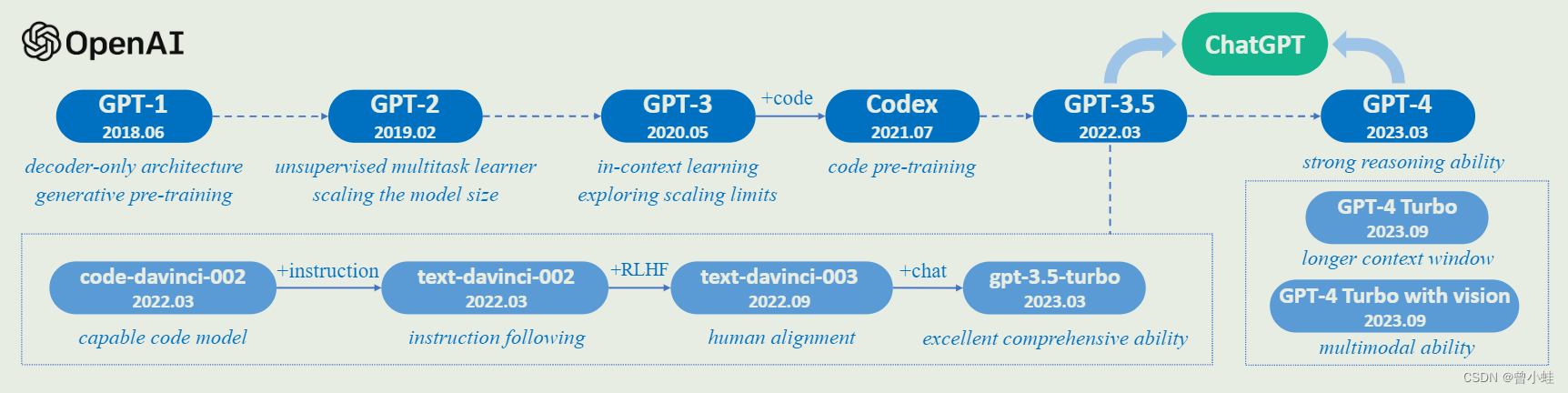
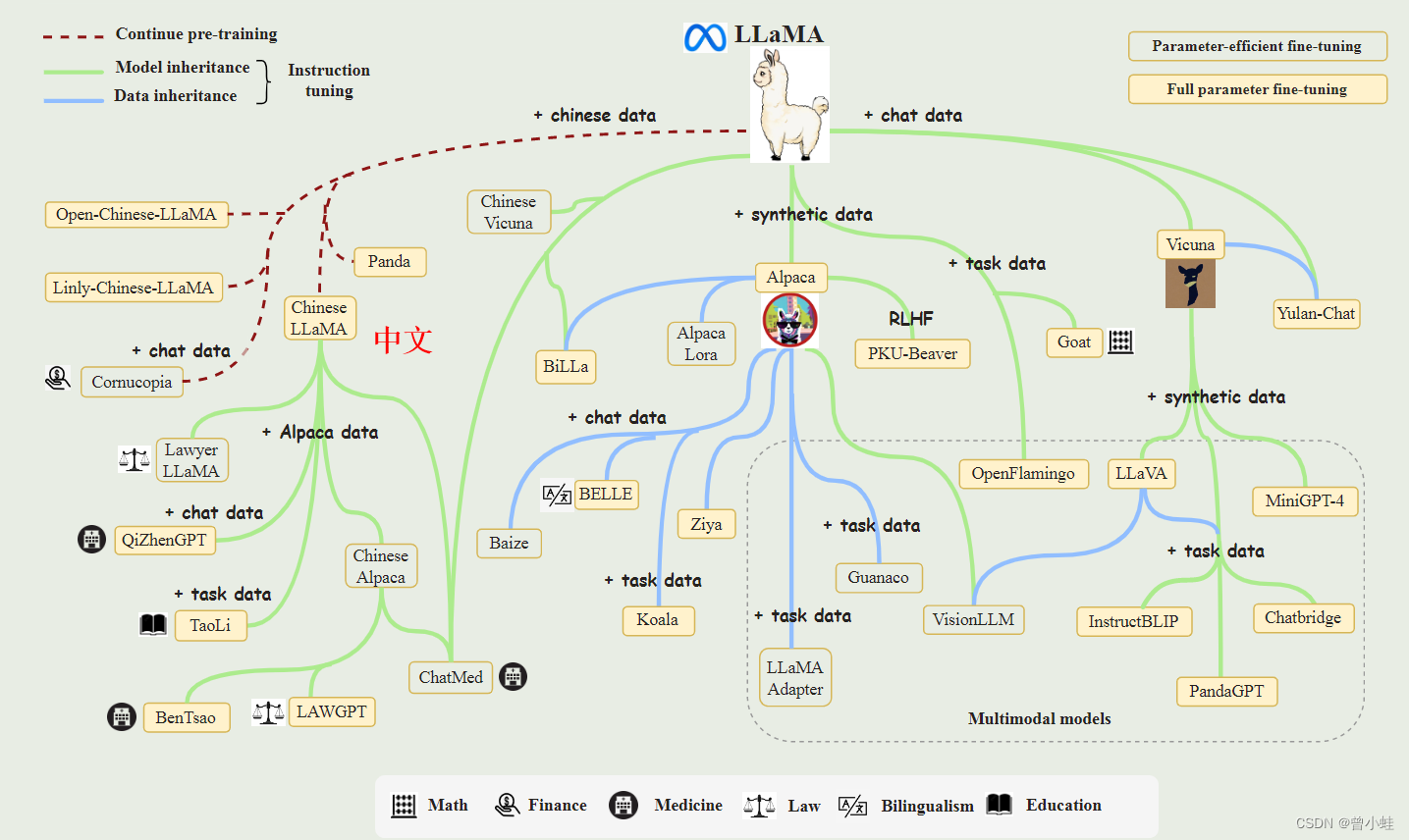
图5 开源的LLaMA 的相关模型
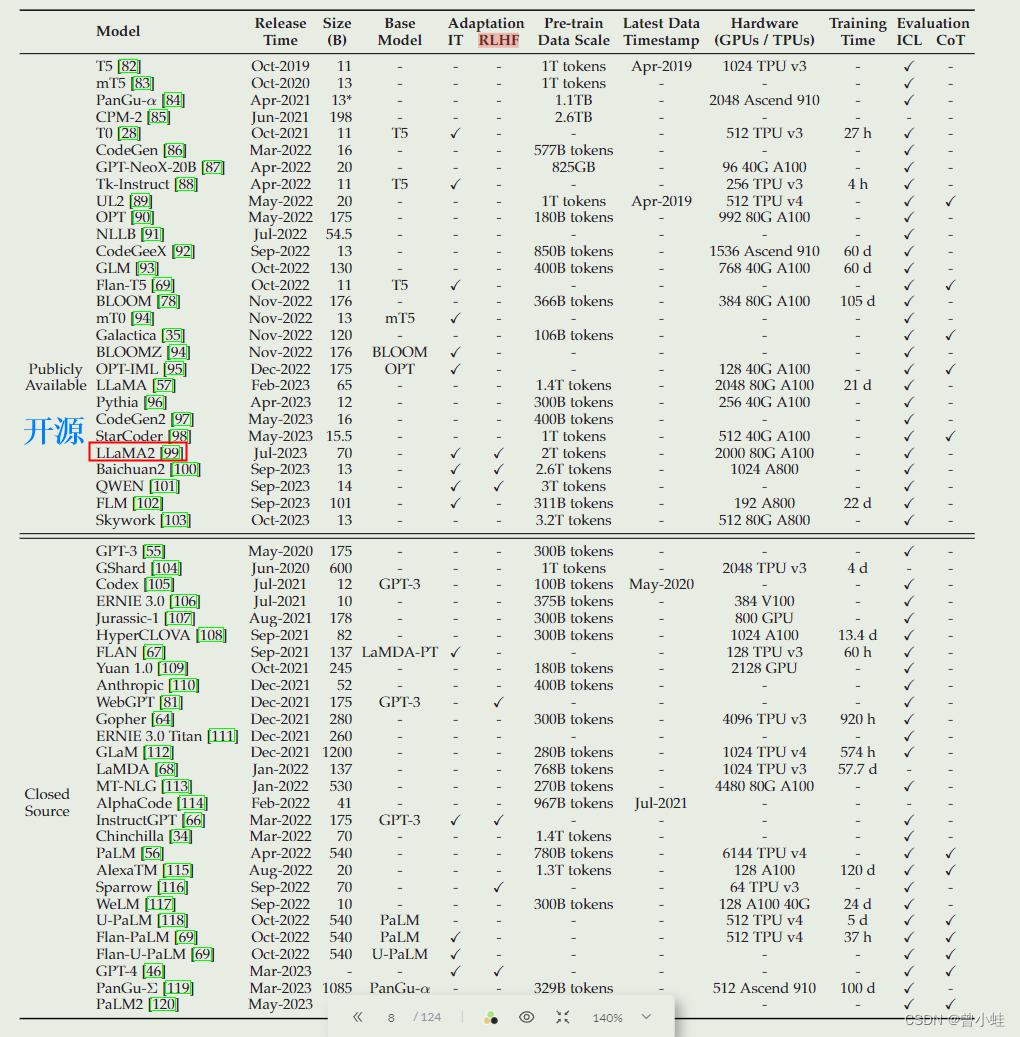
原文表1 大型语言模型(本次调查中大小为 10B)的统计数据,
包括容量评估、预训练数据规模(令牌或存储大小的数量)和硬件资源成本。