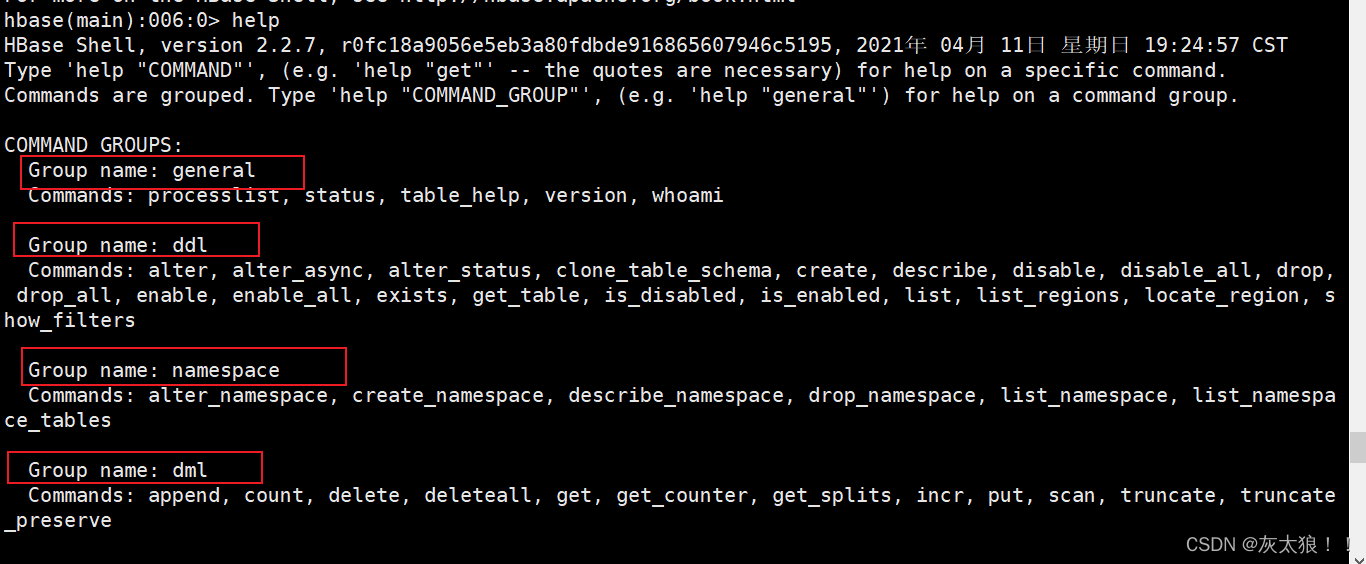
一、help
1.help
显示命名的分组情况
2.help '命令名称'
查看命令的具体使用,包括命令的作用和用法。
举例:help 'list'
二、general 组(普通命令组)
命令 描述 格式

三、命名空间(namespace)
命名空间是HBase中的一个逻辑概念,用于对表进行逻辑分组,类似于关系型数据库中的数据库概念。
1.创建命名空间:
create_namespace '命名空间名称'
2.列举命名空间
list_namespace
3.获取命名空间描述
describe_namespace '命名空间名称'
4.查看命名空间下的所有表
list_namespace_tables '命名空间名称'
5.删除命名空间
drop_namespace '命名空间名称'
四、DDL组(与表相关的命令)
1. 创建表create
在创建一个表的时候,列族必须作为模式定义的一部分预先给出,而列族是支持动态扩展的,也就是列族成员可以随后按需加入,既创建表时只需要指定列族名称,不需要指定列名。
2.修改(添加、删除)表结构Schema alter
3.表的基本操作
3.1获取表的描述
语法:describe '表名'
3.2列举所有表(所有的命名空间下所有的表)
语法:list
3.3查看表是否存在
语法:exists
3.4启用表和禁用表
通过enable和disable来启用/禁用这个表,相应的可以通过is_enabled和is_disabled来检查表是否被禁用
(1)启用表:enable '表名'
(2)查看表是否被启用:is_enabled '表名'
(3)禁用表:disable '表名'
(4)查看表是否被禁用:is_disabled '表名'
3.4.1禁用满足正则表达式的所有表(disable_all )
-
.匹配除“\n”和"\r"之外的任何单个字符
-
*匹配前面的子表达式任意次
3.4.2启用满足正则表达式的所有表(enable_all )enable_all 't.*'
enable_all 'ns:t.*'
enable_all 'ns:.*'
3.5 修改表可以存储多个版本
语法:alter '表名',NAME=>'列簇名',VERSIONS=>版本数量
3.6 删除表
需要先禁用表,然后再删除表,启用的表是不允许删除的
语法1:删除单张表
disable '表名'
drop '表名'
语法2:删除满足正则表达式的所有表
drop_all 't.*' //删除t开头的所有表(默认命名空间下)
drop_all 'ns:t.*' //删除ns命名空间下t开头的所有表
drop_all 'ns:.*' //删除ns命名空间下的所有表
3.7 获取某个表赋值给一个变量(get_table)
通过 var = get_table ‘表名’ 赋值给一个变量对象,然后对象.来调用,就像面向对象编程一样,通过对象.方法来调用,这种方式在操作某个表时就不必每次列举表名了。

3.8 获取rowKey所在的区( locate_region)
语法:locate_region '表名', '行键'

3.9 显示hbase所支持的所有过滤器(show_filters)
过滤器用于get和scan命令中作为筛选数据的条件,类型关系型数据库中的where的作用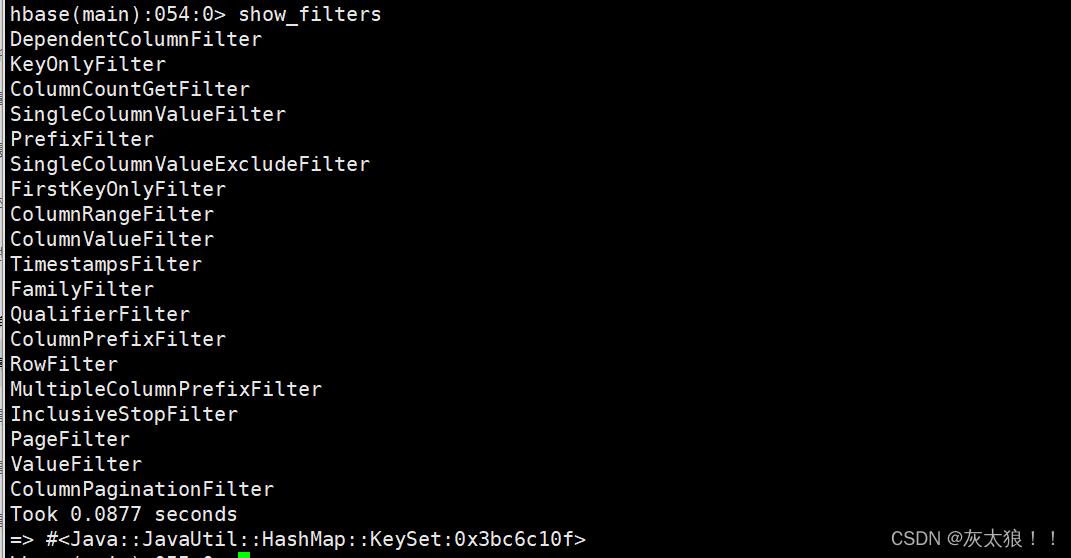
五、DML(数据操作组)
1.插入或者修改数据put

2.全表扫描scan
(效果类似于sql语句中select * from xxx)
2.2查询完整数据

注意:Table中的所有行都是按照row key的字典排序的
2.3 查询某个列簇数据

2.4 查询某个列簇下的某个列数据

3.获取数据
4.删除数据
4.1删除某个列簇中的某个列(delete)
语法:delete '表名', '行键', '列族名:列名'
4.2删除某行数据(deleteall)
语法:deleteall '表名', '行键'
5.清空表数据
语法:truncate '表名'
6.自增与计数器
6.1自增(incr)

6.2计数器(get_counter )
7.修饰词过滤
7.1 COLUMNS(与列簇列名相关)
语法:scan '表名', {COLUMNS => [ '列族名1:列名1', '列族名1:列名2', ...]}
示例:scan 'tal_users',{COLUMNS=> ['info:name','info:id']}

7.2TIMESTAMP( 指定时间戳)
语法:scan '表名',{TIMERANGE=>[timestamp1, timestamp2]}
注意:区间取得值为[ ,),右边的值取不到
7.3 VERSIONS(版本号)
默认情况下一个列只能存储一个数据,后面如果修改数据就会将原来的覆盖掉,可以通过指定VERSIONS使HBase一列能存储多个值。
示例:
7.4 STARTROW
ROWKEY起始行。会先根据这个key定位到region,再向后扫描
语法:scan '表名', { STARTROW => '行键名'}
示例:
scan 'tal_users', { STARTROW => 'rk1003'}

7.5 STOPROW
截止到STOPROW行之前的数据,不包括STOPROW这行数据
语法:scan '表名', { STOPROW=> '行键名'}
示例:
scan 'tal_users', { STOPROW=> 'rk1003'}

将 STARTROW与STOPROW结合使用:左闭右开
scan 'tal_users', { STARTROW=>'rk1001',STOPROW=> 'rk1003'}

7.6 LIMIT
语法1:返回限制的行数(从前往后)
scan '表名', { LIMIT => 行数}
语法2:返回限制的行数(从后往前)
scan '表名',{LIMIT=>行数,REVERSED=>true}
六、FILTER条件过滤器
1、ValueFilter 值过滤器
啊
2、ColumnPrefixFilter 列名前缀过滤器
七、与region有关的命令
1.查看表的所有region
list_regions '表名'
2.强制将表切分出来一个region
split '表名','行键'
示例:split 'tal_users','rk1003'
切分前:

切分后:
注意:此时切分后的形成的两个region并不是在同一台机器上,而是一个region在node1,一个在node2,这是因为底层中Hmaster对RegionServer上的region作负载均衡才导致这个现象

3. 查看某一行在哪个region中
语法: locate_region '表名','行键'
4.查看region中的某列簇数据
语法:hbase hfile -p -f 'hdfs中存放列簇数据的目录'
注意:不是在客户端使用此命令

5.获取region的分割点,清除数据,快照


