文章目录
简介
llama2.c是一个极简的Llama 2 LLM全栈工具,使用一个简单的 700 行 C 文件 ( run.c ) 对其进行推理。llama2.c涉及LLM微调、模型构建、推理端末部署(量化、硬件加速)等众多方面,是学习研究Open LLM的很好切入点。

Github
- https://github.com/karpathy/llama2.c
文档
- https://llama.meta.com/
克隆源码
git clone https://github.com/karpathy/llama2.c.git
英文模型
- https://huggingface.co/datasets/roneneldan/TinyStories
# 15M参数模型
wget https://huggingface.co/karpathy/tinyllamas/resolve/main/stories15M.bin
# 42M参数模型
wget https://huggingface.co/karpathy/tinyllamas/resolve/main/stories42M.bin
# 110M参数模型
wget https://huggingface.co/karpathy/tinyllamas/resolve/main/stories110M.bin
编译运行
make run
# 15M参数模型
./run stories15M.bin
# 42M参数模型,运行并输入提示词
./run stories42M.bin -i "One day, Lily met a Shoggoth"
中文模型(280M)
- https://huggingface.co/flyingfishinwater/chinese-baby-llama2
# 下载模型
git clone https://huggingface.co/flyingfishinwater/chinese-baby-llama2
- 安装 python 相关依赖
pip3 install numpy
pip3 install torch torchvision torchaudio
pip3 install transformers
- 将模型hf格式转换为bin格式
# 将hf模型文件转换成.bin文件
python export.py ./chinese-baby-llama2.bin --hf ./chinese-baby-llama2
- 修改 llama2.c/run.c
// 将 main() 中的 tokenizer.bin 改为 chinese-baby-llama2 目录下的tokenizer.bin
char *tokenizer_path = "chinese-baby-llama2/tokenizer.bin";
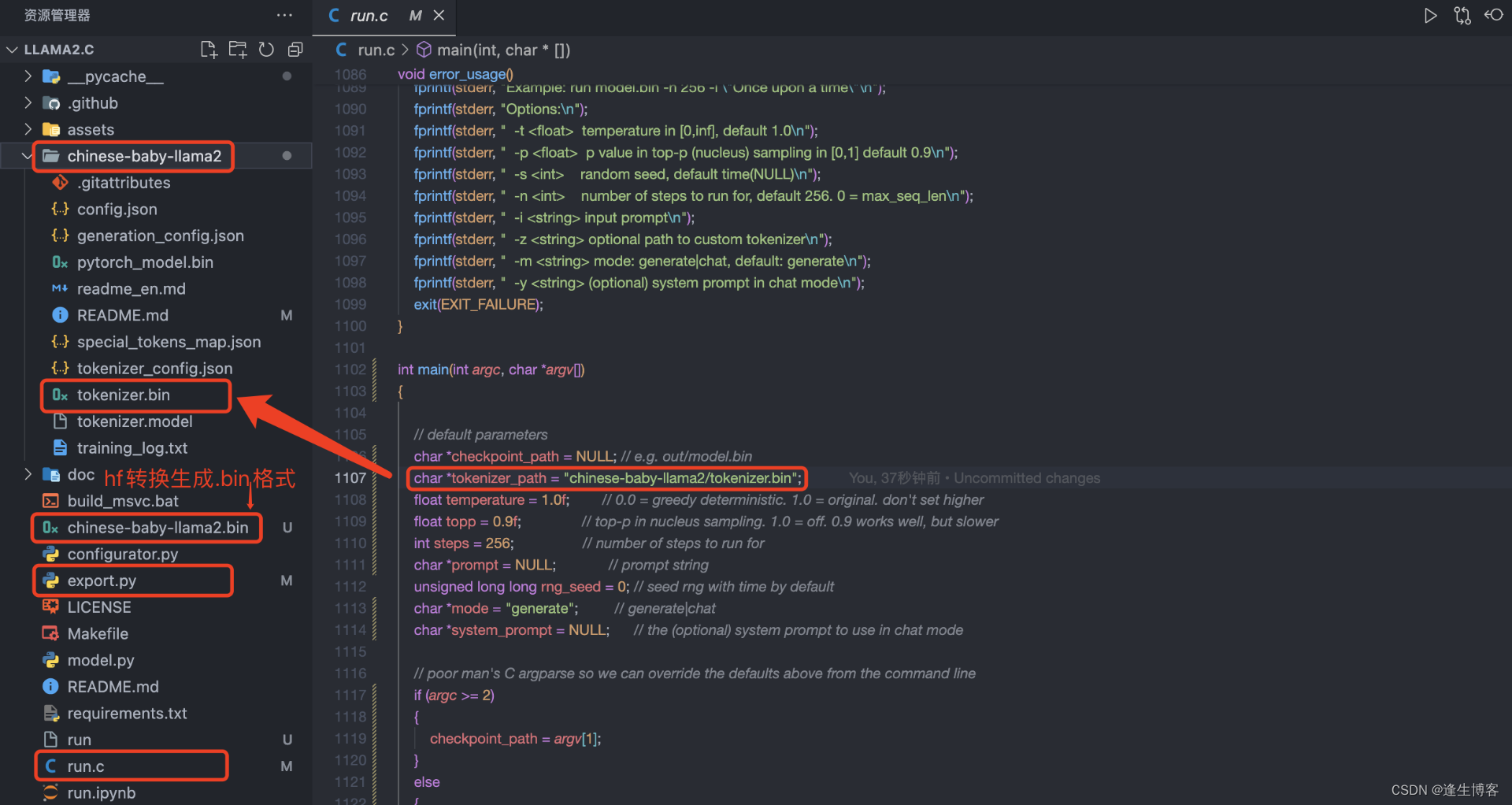
- 编译 c
make run
- 运行并输入提示词
./run chinese-baby-llama2.bin -i "今天是武林大会,我是武林盟主"

main函数
- 默认参数设置: 定义了一些默认参数值,例如模型路径、分词器路径、温度、top-p 值、步数等。
- 命令行参数解析: 通过检查命令行参数,更新默认参数值。命令行参数的格式为 flag value,例如 -t 0.5 表示设置温度为 0.5。
- 参数验证和覆盖: 对解析后的参数进行验证和覆盖。例如,确保随机数种子大于 0、温度在合理范围内、步数为非负数等。
- 构建 Transformer 模型: 使用给定的模型文件构建 Transformer 模型,并根据需要调整步数。
- 构建 Tokenizer: 使用给定的分词器文件构建 Tokenizer。
- 构建 Sampler: 构建 Sampler,并设置相应的参数,如词汇表大小、温度、top-p 值等。
- 执行功能: 根据模式选择执行生成或者聊天功能。如果模式是 generate,则执行生成功能;如果是 chat,则执行聊天功能。
- 内存和文件句柄清理: 释放动态分配的内存和关闭文件句柄,确保程序执行结束时资源被正确释放。










