七、使用 Keras:深入探讨
本章涵盖
-
使用
Sequential类、功能 API 和模型子类创建 Keras 模型 -
使用内置的 Keras 训练和评估循环
-
使用 Keras 回调函数自定义训练
-
使用 TensorBoard 监控训练和评估指标
-
从头开始编写训练和评估循环
您现在对 Keras 有了一些经验——您熟悉 Sequential 模型、Dense 层以及用于训练、评估和推断的内置 API——compile()、fit()、evaluate() 和 predict()。您甚至在第三章中学习了如何从 Layer 类继承以创建自定义层,以及如何使用 TensorFlow 的 GradientTape 实现逐步训练循环。
在接下来的章节中,我们将深入研究计算机视觉、时间序列预测、自然语言处理和生成式深度学习。这些复杂的应用将需要比 Sequential 架构和默认的 fit() 循环更多的内容。所以让我们首先把你变成一个 Keras 专家!在本章中,您将全面了解如何使用 Keras API:这是您将需要处理下一个遇到的高级深度学习用例的关键方法。
7.1 一系列工作流程
Keras API 的设计遵循“逐步揭示复杂性”的原则:使入门变得容易,同时使处理高复杂性用例成为可能,只需要在每一步进行增量学习。简单用例应该易于接近,任意高级工作流程应该是可能的:无论您想做多么小众和复杂的事情,都应该有一条明确的路径。这条路径建立在您从更简单工作流程中学到的各种东西之上。这意味着您可以从初学者成长为专家,仍然可以以不同的方式使用相同的工具。
因此,并没有一种“真正”的使用 Keras 的方式。相反,Keras 提供了一系列工作流程,从非常简单到非常灵活。有不同的构建 Keras 模型的方式,以及不同的训练方式,满足不同的需求。因为所有这些工作流程都基于共享的 API,如 Layer 和 Model,所以任何工作流程的组件都可以在任何其他工作流程中使用——它们可以相互通信。
7.2 构建 Keras 模型的不同方式
Keras 有三种构建模型的 API(见图 7.1):
-
Sequential 模型,最易接近的 API——基本上就是一个 Python 列表。因此,它仅限于简单的层堆叠。
-
功能 API 专注于类似图形的模型架构。它在可用性和灵活性之间找到了一个很好的中间点,因此它是最常用的模型构建 API。
-
模型子类化,一种低级选项,您可以从头开始编写所有内容。如果您想要对每一点都有完全控制,这是理想的选择。但是,您将无法访问许多内置的 Keras 功能,并且更容易出错。

图 7.1 逐步揭示模型构建的复杂性
7.2.1 Sequential 模型
构建 Keras 模型的最简单方法是使用已知的 Sequential 模型。
列表 7.1 Sequential 类
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Dense(64, activation="relu"),
layers.Dense(10, activation="softmax")
])
请注意,可以通过 add() 方法逐步构建相同的模型,这类似于 Python 列表的 append() 方法。
列表 7.2 逐步构建一个顺序模型
model = keras.Sequential()
model.add(layers.Dense(64, activation="relu"))
model.add(layers.Dense(10, activation="softmax"))
在第四章中,您看到层只有在第一次调用它们时才会构建(也就是说,创建它们的权重)。这是因为层的权重形状取决于它们的输入形状:在输入形状未知之前,它们无法被创建。
因此,前面的 Sequential 模型没有任何权重(列表 7.3),直到您实际在一些数据上调用它,或者使用输入形状调用其 build() 方法(列表 7.4)。
列表 7.3 尚未构建的模型没有权重
>>> model.weights # ❶
ValueError: Weights for model sequential_1 have not yet been created.
❶ 在那时,模型尚未构建。
列表 7.4 第一次调用模型以构建它
>>> model.build(input_shape=(None, 3)) # ❶
>>> model.weights # ❷
[<tf.Variable "dense_2/kernel:0" shape=(3, 64) dtype=float32, ... >,
<tf.Variable "dense_2/bias:0" shape=(64,) dtype=float32, ... >
<tf.Variable "dense_3/kernel:0" shape=(64, 10) dtype=float32, ... >,
<tf.Variable "dense_3/bias:0" shape=(10,) dtype=float32, ... >]
❶ 构建模型 - 现在模型将期望形状为(3,)的样本。输入形状中的 None 表示批次大小可以是任意值。
❷ 现在你可以检索模型的权重。
模型构建完成后,你可以通过summary()方法显示其内容,这对调试很有帮助。
列表 7.5 summary()方法
>>> model.summary()
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_2 (Dense) (None, 64) 256
_________________________________________________________________
dense_3 (Dense) (None, 10) 650
=================================================================
Total params: 906
Trainable params: 906
Non-trainable params: 0
_________________________________________________________________
如你所见,这个模型恰好被命名为“sequential_1”。你可以为 Keras 中的所有内容命名 - 每个模型,每个层。
列表 7.6 使用name参数为模型和层命名
>>> model = keras.Sequential(name="my_example_model")
>>> model.add(layers.Dense(64, activation="relu", name="my_first_layer"))
>>> model.add(layers.Dense(10, activation="softmax", name="my_last_layer"))
>>> model.build((None, 3))
>>> model.summary()
Model: "my_example_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
my_first_layer (Dense) (None, 64) 256
_________________________________________________________________
my_last_layer (Dense) (None, 10) 650
=================================================================
Total params: 906
Trainable params: 906
Non-trainable params: 0
_________________________________________________________________
逐步构建 Sequential 模型时,能够在添加每个层后打印当前模型的摘要非常有用。但在构建模型之前无法打印摘要!实际上,有一种方法可以让你的Sequential动态构建:只需提前声明模型输入的形状即可。你可以通过Input类实现这一点。
列表 7.7 预先指定模型的输入形状
model = keras.Sequential()
model.add(keras.Input(shape=(3,))) # ❶
model.add(layers.Dense(64, activation="relu"))
❶ 使用 Input 声明输入的形状。请注意,shape 参数必须是每个样本的形状,而不是一个批次的形状。
现在你可以使用summary()来跟踪模型输出形状随着添加更多层而变化的情况:
>>> model.summary()
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_4 (Dense) (None, 64) 256
=================================================================
Total params: 256
Trainable params: 256
Non-trainable params: 0
_________________________________________________________________
>>> model.add(layers.Dense(10, activation="softmax"))
>>> model.summary()
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_4 (Dense) (None, 64) 256
_________________________________________________________________
dense_5 (Dense) (None, 10) 650
=================================================================
Total params: 906
Trainable params: 906
Non-trainable params: 0
_________________________________________________________________
处理转换输入的层(如第八章中将学习的卷积层)时,这是一个相当常见的调试工作流程。
7.2.2 功能 API
Sequential 模型易于使用,但其适用性极为有限:它只能表达具有单个输入和单个输出的模型,按顺序一个接一个地应用各个层。实际上,很常见遇到具有多个输入(例如图像及其元数据)、多个输出(关于数据的不同预测)或非线性拓扑的模型。
在这种情况下,你将使用功能 API 构建模型。这是你在实际应用中遇到的大多数 Keras 模型所使用的方法。它既有趣又强大,感觉就像玩乐高积木一样。
一个简单的例子
让我们从一些简单的东西开始:我们在上一节中使用的两个层的堆叠。其功能 API 版本如下列表所示。
列表 7.8 具有两个Dense层的简单功能模型
inputs = keras.Input(shape=(3,), name="my_input")
features = layers.Dense(64, activation="relu")(inputs)
outputs = layers.Dense(10, activation="softmax")(features)
model = keras.Model(inputs=inputs, outputs=outputs)
让我们一步一步地过一遍这个过程。
我们首先声明了一个Input(请注意,你也可以为这些输入对象命名,就像其他所有内容一样):
inputs = keras.Input(shape=(3,), name="my_input")
这个inputs对象保存了关于模型将处理的数据形状和 dtype 的信息:
>>> inputs.shape
(None, 3) # ❶
>>> inputs.dtype # ❷
float32
❶ 模型将处理每个样本形状为(3,)的批次。每批次的样本数量是可变的(由 None 批次大小表示)。
❷ 这些批次将具有 dtype float32。
我们称这样的对象为符号张量。它不包含任何实际数据,但它编码了模型在使用时将看到的实际数据张量的规格。它代表未来的数据张量。
接下来,我们创建了一个层并在输入上调用它:
features = layers.Dense(64, activation="relu")(inputs)
所有 Keras 层都可以在实际数据张量和这些符号张量上调用。在后一种情况下,它们将返回一个新的符号张量,带有更新的形状和 dtype 信息:
>>> features.shape
(None, 64)
在获得最终输出后,我们通过在Model构造函数中指定其输入和输出来实例化模型:
outputs = layers.Dense(10, activation="softmax")(features)
model = keras.Model(inputs=inputs, outputs=outputs)
这是我们模型的摘要:
>>> model.summary()
Model: "functional_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
my_input (InputLayer) [(None, 3)] 0
_________________________________________________________________
dense_6 (Dense) (None, 64) 256
_________________________________________________________________
dense_7 (Dense) (None, 10) 650
=================================================================
Total params: 906
Trainable params: 906
Non-trainable params: 0
_________________________________________________________________
多输入,多输出模型
与这个玩具模型不同,大多数深度学习模型看起来不像列表,而更像图形。例如,它们可能具有多个输入或多个输出。正是对于这种类型的模型,功能 API 真正发挥作用。
假设你正在构建一个系统,根据优先级对客户支持票据进行排名并将其路由到适当的部门。你的模型有三个输入:
-
票据的标题(文本输入)
-
票据的文本主体(文本输入)
-
用户添加的任何标签(假定为独热编码的分类输入)
我们可以将文本输入编码为大小为vocabulary_size的一维数组(有关文本编码技术的详细信息,请参阅第十一章)。
您的模型还有两个输出:
-
票证的优先级分数,介于 0 和 1 之间的标量(sigmoid 输出)
-
应处理票证的部门(对部门集合进行 softmax)
您可以使用几行代码使用函数式 API 构建此模型。
列表 7.9 多输入、多输出函数式模型
vocabulary_size = 10000
num_tags = 100
num_departments = 4
title = keras.Input(shape=(vocabulary_size,), name="title") # ❶
text_body = keras.Input(shape=(vocabulary_size,), name="text_body") # ❶
tags = keras.Input(shape=(num_tags,), name="tags") # ❶
features = layers.Concatenate()([title, text_body, tags]) # ❷
features = layers.Dense(64, activation="relu")(features) # ❸
priority = layers.Dense(1, activation="sigmoid", name="priority")(features)# ❹
department = layers.Dense(
num_departments, activation="softmax", name="department")(features) # ❹
model = keras.Model(inputs=[title, text_body, tags], # ❺
outputs=[priority, department]) # ❺
❶ 定义模型输入。
❷ 通过将它们连接起来,将输入特征组合成一个张量 features。
❸ 应用中间层以将输入特征重新组合为更丰富的表示。
❹ 定义模型输出。
❺ 通过指定其输入和输出来创建模型。
函数式 API 是一种简单、类似于乐高的、但非常灵活的方式,用于定义这样的层图。
训练多输入、多输出模型
您可以像训练序贯模型一样训练模型,通过使用输入和输出数据的列表调用fit()。这些数据列表应与传递给Model构造函数的输入顺序相同。
列表 7.10 通过提供输入和目标数组列表来训练模型
import numpy as np
num_samples = 1280
title_data = np.random.randint(0, 2, size=(num_samples, vocabulary_size)) # ❶
text_body_data = np.random.randint(0, 2, size=(num_samples, vocabulary_size)) # ❶
tags_data = np.random.randint(0, 2, size=(num_samples, num_tags)) # ❶
priority_data = np.random.random(size=(num_samples, 1)) # ❷
department_data = np.random.randint(0, 2, size=(num_samples, num_departments))# ❷
model.compile(optimizer="rmsprop",
loss=["mean_squared_error", "categorical_crossentropy"],
metrics=[["mean_absolute_error"], ["accuracy"]])
model.fit([title_data, text_body_data, tags_data],
[priority_data, department_data],
epochs=1)
model.evaluate([title_data, text_body_data, tags_data],
[priority_data, department_data])
priority_preds, department_preds = model.predict(
[title_data, text_body_data, tags_data])
❶ 虚拟输入数据
❷ 虚拟目标数据
如果您不想依赖输入顺序(例如,因为您有许多输入或输出),您还可以利用给Input对象和输出层命名的名称,并通过字典传递数据。
列表 7.11 通过提供输入和目标数组的字典来训练模型
model.compile(optimizer="rmsprop",
loss={"priority": "mean_squared_error", "department":
"categorical_crossentropy"},
metrics={"priority": ["mean_absolute_error"], "department":
["accuracy"]})
model.fit({"title": title_data, "text_body": text_body_data,
"tags": tags_data},
{"priority": priority_data, "department": department_data},
epochs=1)
model.evaluate({"title": title_data, "text_body": text_body_data,
"tags": tags_data},
{"priority": priority_data, "department": department_data})
priority_preds, department_preds = model.predict(
{"title": title_data, "text_body": text_body_data, "tags": tags_data})
函数式 API 的强大之处:访问层连接性
函数式模型是一种显式的图数据结构。这使得可以检查层如何连接并重用先前的图节点(即层输出)作为新模型的一部分。它还很好地适应了大多数研究人员在思考深度神经网络时使用的“心智模型”:层的图。这使得两个重要用例成为可能:模型可视化和特征提取。
让我们可视化我们刚刚定义的模型的连接性(模型的拓扑结构)。您可以使用plot_model()实用程序将函数式模型绘制为图形(参见图 7.2)。
keras.utils.plot_model(model, "ticket_classifier.png")

图 7.2 由plot_model()在我们的票证分类器模型上生成的图
您可以在此图中添加模型中每个层的输入和输出形状,这在调试过程中可能会有所帮助(参见图 7.3)。
keras.utils.plot_model(
model, "ticket_classifier_with_shape_info.png", show_shapes=True)

图 7.3 添加形状信息的模型图
张量形状中的“None”表示批处理大小:此模型允许任意大小的批处理。
访问层连接性还意味着您可以检查和重用图中的单个节点(层调用)。model.layers 模型属性提供组成模型的层列表,对于每个层,您可以查询layer.input 和layer.output。
列表 7.12 检索函数式模型中层的输入或输出
>>> model.layers
[<tensorflow.python.keras.engine.input_layer.InputLayer at 0x7fa963f9d358>,
<tensorflow.python.keras.engine.input_layer.InputLayer at 0x7fa963f9d2e8>,
<tensorflow.python.keras.engine.input_layer.InputLayer at 0x7fa963f9d470>,
<tensorflow.python.keras.layers.merge.Concatenate at 0x7fa963f9d860>,
<tensorflow.python.keras.layers.core.Dense at 0x7fa964074390>,
<tensorflow.python.keras.layers.core.Dense at 0x7fa963f9d898>,
<tensorflow.python.keras.layers.core.Dense at 0x7fa963f95470>]
>>> model.layers[3].input
[<tf.Tensor "title:0" shape=(None, 10000) dtype=float32>,
<tf.Tensor "text_body:0" shape=(None, 10000) dtype=float32>,
<tf.Tensor "tags:0" shape=(None, 100) dtype=float32>]
>>> model.layers[3].output
<tf.Tensor "concatenate/concat:0" shape=(None, 20100) dtype=float32>
这使您能够进行特征提取,创建重用另一个模型中间特征的模型。
假设您想要向先前的模型添加另一个输出—您想要估计给定问题票证解决所需时间,一种难度评级。您可以通过三个类别的分类层来实现这一点:“快速”、“中等”和“困难”。您无需从头开始重新创建和重新训练模型。您可以从先前模型的中间特征开始,因为您可以访问它们,就像这样。
列表 7.13 通过重用中间层输出创建新模型
features = model.layers[4].output # ❶
difficulty = layers.Dense(3, activation="softmax", name="difficulty")(features)
new_model = keras.Model(
inputs=[title, text_body, tags],
outputs=[priority, department, difficulty])
❶ 层[4] 是我们的中间密集层
让我们绘制我们的新模型(参见图 7.4):
keras.utils.plot_model(
new_model, "updated_ticket_classifier.png", show_shapes=True)

图 7.4 我们新模型的绘图
7.2.3 继承 Model 类
你应该了解的最后一个模型构建模式是最高级的一个:Model子类化。你在第三章学习了如何子类化Layer类来创建自定义层。子类化Model与此类似:
-
在
__init__()方法中,定义模型将使用的层。 -
在
call()方法中,定义模型的前向传递,重用先前创建的层。 -
实例化你的子类,并在数据上调用它以创建其权重。
将我们之前的例子重写为一个子类模型
让我们看一个简单的例子:我们将使用Model子类重新实现客户支持票务管理模型。
图 7.14 一个简单的子类模型
class CustomerTicketModel(keras.Model):
def __init__(self, num_departments):
super().__init__() # ❶
self.concat_layer = layers.Concatenate() # ❷
self.mixing_layer = layers.Dense(64, activation="relu") # ❷
self.priority_scorer = layers.Dense(1, activation="sigmoid") # ❷
self.department_classifier = layers.Dense( # ❷
num_departments, activation="softmax")
def call(self, inputs): # ❸
title = inputs["title"]
text_body = inputs["text_body"]
tags = inputs["tags"]
features = self.concat_layer([title, text_body, tags])
features = self.mixing_layer(features)
priority = self.priority_scorer(features)
department = self.department_classifier(features)
return priority, department
❶ 不要忘记调用 super()构造函数!
❷ 在构造函数中定义子层。
❸ 在 call()方法中定义前向传递。
一旦你定义了模型,你可以实例化它。请注意,它只会在第一次在一些数据上调用它时创建它的权重,就像Layer子类一样:
model = CustomerTicketModel(num_departments=4)
priority, department = model(
{"title": title_data, "text_body": text_body_data, "tags": tags_data})
到目前为止,一切看起来与Layer子类化非常相似,这是你在第三章遇到的工作流程。那么,Layer子类和Model子类之间的区别是什么呢?很简单:一个“层”是你用来创建模型的构建块,而一个“模型”是你实际上将要训练、导出用于推断等的顶层对象。简而言之,一个Model有fit()、evaluate()和predict()方法。层没有。除此之外,这两个类几乎是相同的。(另一个区别是你可以保存模型到磁盘上的文件中,我们将在几节中介绍。)
你可以像编译和训练 Sequential 或 Functional 模型一样编译和训练Model子类:
model.compile(optimizer="rmsprop",
loss=["mean_squared_error", "categorical_crossentropy"], # ❶
metrics=[["mean_absolute_error"], ["accuracy"]]) # ❶
model.fit({"title": title_data, # ❷
"text_body": text_body_data, # ❷
"tags": tags_data}, # ❷
[priority_data, department_data], # ❸
epochs=1)
model.evaluate({"title": title_data,
"text_body": text_body_data,
"tags": tags_data},
[priority_data, department_data])
priority_preds, department_preds = model.predict({"title": title_data,
"text_body": text_body_data,
"tags": tags_data})
❶ 作为损失和指标参数传递的结构必须与 call()返回的完全匹配——这里是两个元素的列表。
❷ 输入数据的结构必须与 call()方法所期望的完全匹配——这里是一个具有标题、正文和标签键的字典。
❸ 目标数据的结构必须与 call()方法返回的完全匹配——这里是两个元素的列表。
Model子类化工作流是构建模型的最灵活方式。它使你能够构建无法表示为层的有向无环图的模型——想象一下,一个模型在call()方法中使用层在一个for循环内,甚至递归调用它们。任何事情都是可能的——你有控制权。
警告:子类模型不支持的内容
这种自由是有代价的:对于子类模型,你需要负责更多的模型逻辑,这意味着你的潜在错误面更大。因此,你将需要更多的调试工作。你正在开发一个新的 Python 对象,而不仅仅是将 LEGO 积木拼在一起。
函数式模型和子类模型在本质上也有很大的不同。函数式模型是一个显式的数据结构——层的图,你可以查看、检查和修改。子类模型是一段字节码——一个带有包含原始代码的call()方法的 Python 类。这是子类化工作流程灵活性的源泉——你可以编写任何你喜欢的功能,但它也引入了新的限制。
例如,因为层之间的连接方式隐藏在call()方法的内部,你无法访问该信息。调用summary()不会显示层连接,并且你无法通过plot_model()绘制模型拓扑。同样,如果你有一个子类模型,你无法访问层图的节点进行特征提取,因为根本没有图。一旦模型被实例化,其前向传递就变成了一个完全的黑匣子。
7.2.4 混合和匹配不同的组件
重要的是,选择这些模式之一——Sequential 模型、Functional API 或 Model 子类化——不会将您排除在其他模式之外。Keras API 中的所有模型都可以平滑地相互操作,无论它们是 Sequential 模型、Functional 模型还是从头开始编写的子类化模型。它们都是同一系列工作流的一部分。
例如,您可以在 Functional 模型中使用子类化层或模型。
列表 7.15 创建包含子类化模型的 Functional 模型
class Classifier(keras.Model):
def __init__(self, num_classes=2):
super().__init__()
if num_classes == 2:
num_units = 1
activation = "sigmoid"
else:
num_units = num_classes
activation = "softmax"
self.dense = layers.Dense(num_units, activation=activation)
def call(self, inputs):
return self.dense(inputs)
inputs = keras.Input(shape=(3,))
features = layers.Dense(64, activation="relu")(inputs)
outputs = Classifier(num_classes=10)(features)
model = keras.Model(inputs=inputs, outputs=outputs)
相反地,您可以将 Functional 模型用作子类化层或模型的一部分。
列表 7.16 创建包含 Functional 模型的子类化模型
inputs = keras.Input(shape=(64,))
outputs = layers.Dense(1, activation="sigmoid")(inputs)
binary_classifier = keras.Model(inputs=inputs, outputs=outputs)
class MyModel(keras.Model):
def __init__(self, num_classes=2):
super().__init__()
self.dense = layers.Dense(64, activation="relu")
self.classifier = binary_classifier
def call(self, inputs):
features = self.dense(inputs)
return self.classifier(features)
model = MyModel()
7.2.5 记住:使用合适的工具来完成工作
您已经了解了构建 Keras 模型的工作流程的范围,从最简单的工作流程 Sequential 模型到最先进的工作流程模型子类化。何时应该使用其中一个而不是另一个?每种方法都有其优缺点——选择最适合手头工作的方法。
一般来说,Functional API 为您提供了易用性和灵活性之间的很好的权衡。它还为您提供了直接访问层连接性的功能,这对于模型绘图或特征提取等用例非常强大。如果您可以使用 Functional API——也就是说,如果您的模型可以表示为层的有向无环图——我建议您使用它而不是模型子类化。
今后,本书中的所有示例都将使用 Functional API,仅因为我们将使用的所有模型都可以表示为层的图。但是,我们将经常使用子类化层。一般来说,使用包含子类化层的 Functional 模型既具有高开发灵活性,又保留了 Functional API 的优势。
7.3 使用内置的训练和评估循环
逐步披露复杂性的原则——从非常简单到任意灵活的工作流程的访问,一步一步——也适用于模型训练。Keras 为您提供了不同的训练模型的工作流程。它们可以简单到在数据上调用 fit(),也可以高级到从头开始编写新的训练算法。
您已经熟悉了 compile()、fit()、evaluate()、predict() 的工作流程。作为提醒,请查看以下列表。
列表 7.17 标准工作流程:compile()、fit()、evaluate()、predict()
from tensorflow.keras.datasets import mnist
def get_mnist_model(): # ❶
inputs = keras.Input(shape=(28 * 28,))
features = layers.Dense(512, activation="relu")(inputs)
features = layers.Dropout(0.5)(features)
outputs = layers.Dense(10, activation="softmax")(features)
model = keras.Model(inputs, outputs)
return model
(images, labels), (test_images, test_labels) = mnist.load_data() # ❷
images = images.reshape((60000, 28 * 28)).astype("float32") / 255
test_images = test_images.reshape((10000, 28 * 28)).astype("float32") / 255
train_images, val_images = images[10000:], images[:10000]
train_labels, val_labels = labels[10000:], labels[:10000]
model = get_mnist_model()
model.compile(optimizer="rmsprop", # ❸
loss="sparse_categorical_crossentropy", # ❸
metrics=["accuracy"]) # ❸
model.fit(train_images, train_labels, # ❹
epochs=3, # ❹
validation_data=(val_images, val_labels)) # ❹
test_metrics = model.evaluate(test_images, test_labels) # ❺
predictions = model.predict(test_images) # ❻
❶ 创建一个模型(我们将其分解为一个单独的函数,以便以后重用)。
❷ 加载数据,保留一些用于验证。
❸ 通过指定其优化器、要最小化的损失函数和要监视的指标来编译模型。
❹ 使用 fit() 训练模型,可选择提供验证数据以监视在未见数据上的性能。
❺ 使用 evaluate() 在新数据上计算损失和指标。
❻ 使用 predict() 在新数据上计算分类概率。
有几种方法可以自定义这个简单的工作流程:
-
提供您自己的自定义指标。
-
将 callbacks 传递给
fit()方法以安排在训练过程中的特定时间点执行的操作。
让我们来看看这些。
7.3.1 编写自己的指标
指标对于衡量模型性能至关重要——特别是用于衡量模型在训练数据和测试数据上性能差异的指标。用于分类和回归的常用指标已经是内置的 keras.metrics 模块的一部分,大多数情况下您会使用它们。但是,如果您正在做一些与众不同的事情,您将需要能够编写自己的指标。这很简单!
Keras 指标是 keras.metrics.Metric 类的子类。像层一样,指标在 TensorFlow 变量中存储内部状态。与层不同,这些变量不会通过反向传播进行更新,因此您必须自己编写状态更新逻辑,这发生在 update_state() 方法中。
例如,这里有一个简单的自定义指标,用于测量均方根误差(RMSE)。
列表 7.18 通过子类化Metric类实现自定义指标
import tensorflow as tf
class RootMeanSquaredError(keras.metrics.Metric): # ❶
def __init__(self, name="rmse", **kwargs): # ❷
super().__init__(name=name, **kwargs) # ❷
self.mse_sum = self.add_weight(name="mse_sum", initializer="zeros")# ❷
self.total_samples = self.add_weight( # ❷
name="total_samples", initializer="zeros", dtype="int32") # ❷
def update_state(self, y_true, y_pred, sample_weight=None): # ❸
y_true = tf.one_hot(y_true, depth=tf.shape(y_pred)[1]) # ❹
mse = tf.reduce_sum(tf.square(y_true - y_pred))
self.mse_sum.assign_add(mse)
num_samples = tf.shape(y_pred)[0]
self.total_samples.assign_add(num_samples)
❶ 子类化 Metric 类。
❷ 在构造函数中定义状态变量。就像对于层一样,你可以访问add_weight()方法。
❸ 在update_state()中实现状态更新逻辑。y_true参数是一个批次的目标(或标签),而y_pred表示模型的相应预测。你可以忽略sample_weight参数——我们这里不会用到它。
❹ 为了匹配我们的 MNIST 模型,我们期望分类预测和整数标签。
你可以使用result()方法返回指标的当前值:
def result(self):
return tf.sqrt(self.mse_sum / tf.cast(self.total_samples, tf.float32))
与此同时,你还需要提供一种方法来重置指标状态,而不必重新实例化它——这使得相同的指标对象可以在训练的不同时期或在训练和评估之间使用。你可以使用reset_state()方法来实现这一点:
def reset_state(self):
self.mse_sum.assign(0.)
self.total_samples.assign(0)
自定义指标可以像内置指标一样使用。让我们试用我们自己的指标:
model = get_mnist_model()
model.compile(optimizer="rmsprop",
loss="sparse_categorical_crossentropy",
metrics=["accuracy", RootMeanSquaredError()])
model.fit(train_images, train_labels,
epochs=3,
validation_data=(val_images, val_labels))
test_metrics = model.evaluate(test_images, test_labels)
现在你可以看到fit()进度条显示你的模型的 RMSE。
7.3.2 使用回调
在大型数据集上进行数十个时期的训练运行,使用model.fit()有点像发射纸飞机:过了初始冲动,你就无法控制它的轨迹或着陆点。如果你想避免不良结果(从而浪费纸飞机),更明智的做法是使用不是纸飞机,而是一架可以感知环境、将数据发送回操作员并根据当前状态自动做出转向决策的无人机。Keras 的回调API 将帮助你将对model.fit()的调用从纸飞机转变为一个智能、自主的无人机,可以自我反省并动手采取行动。
回调是一个对象(实现特定方法的类实例),它在对fit()的模型调用中传递给模型,并在训练过程中的各个时刻被模型调用。它可以访问有关模型状态和性能的所有可用数据,并且可以采取行动:中断训练、保存模型、加载不同的权重集,或者以其他方式改变模型的状态。
以下是一些使用回调的示例:
-
模型检查点——在训练过程中保存模型的当前状态。
-
提前停止——当验证损失不再改善时中断训练(当然,保存在训练过程中获得的最佳模型)。
-
在训练过程中动态调整某些参数的值——比如优化器的学习率。
-
在训练过程中记录训练和验证指标,或者在更新时可视化模型学习到的表示——你熟悉的
fit()进度条实际上就是一个回调!
keras.callbacks模块包括许多内置回调(这不是一个详尽的列表):
keras.callbacks.ModelCheckpoint
keras.callbacks.EarlyStopping
keras.callbacks.LearningRateScheduler
keras.callbacks.ReduceLROnPlateau
keras.callbacks.CSVLogger
让我们回顾其中的两个,以便让你了解如何使用它们:EarlyStopping和ModelCheckpoint。
EarlyStopping 和 ModelCheckpoint 回调
当你训练一个模型时,有很多事情是你无法从一开始就预测的。特别是,你无法知道需要多少个时期才能达到最佳的验证损失。到目前为止,我们的例子采用了训练足够多个时期的策略,以至于你开始过拟合,使用第一次运行来确定适当的训练时期数量,然后最终启动一个新的训练运行,使用这个最佳数量。当然,这种方法是浪费的。更好的处理方式是在测量到验证损失不再改善时停止训练。这可以通过EarlyStopping回调来实现。
EarlyStopping回调会在监控的目标指标停止改进一定数量的时期后中断训练。例如,此回调允许您在开始过拟合时立即中断训练,从而避免不得不为更少的时期重新训练模型。此回调通常与ModelCheckpoint结合使用,后者允许您在训练过程中持续保存模型(可选地,仅保存迄今为止的当前最佳模型:在时期结束时表现最佳的模型版本)。
列表 7.19 在fit()方法中使用callbacks参数
callbacks_list = [ # ❶
keras.callbacks.EarlyStopping( # ❷
monitor="val_accuracy", # ❸
patience=2, # ❹
),
keras.callbacks.ModelCheckpoint( # ❺
filepath="checkpoint_path.keras", # ❻
monitor="val_loss", # ❼
save_best_only=True, # ❼
)
]
model = get_mnist_model()
model.compile(optimizer="rmsprop",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"]) # ❽
model.fit(train_images, train_labels, # ❾
epochs=10, # ❾
callbacks=callbacks_list, # ❾
validation_data=(val_images, val_labels)) # ❾
❶ 回调通过fit()方法中的 callbacks 参数传递给模型,该参数接受一个回调函数列表。您可以传递任意数量的回调函数。
❷ 当改进停止时中断训练
❸ 监控模型的验证准确率
❹ 当准确率连续两个时期没有改善时中断训练
❺ 在每个时期结束后保存当前权重
❻ 目标模型文件的路径
❼ 这两个参数意味着除非 val_loss 有所改善,否则您不会覆盖模型文件,这样可以保留训练过程中看到的最佳模型。
❽ 您正在监视准确率,因此它应该是模型指标的一部分。
❾ 请注意,由于回调将监视验证损失和验证准确率,您需要将 validation_data 传递给 fit()调用。
请注意,您也可以在训练后手动保存模型——只需调用model.save('my_checkpoint_path')。要重新加载保存的模型,只需使用
model = keras.models.load_model("checkpoint_path.keras")
7.3.3 编写自己的回调函数
如果您需要在训练过程中执行特定操作,而内置回调函数没有涵盖,您可以编写自己的回调函数。通过继承keras.callbacks.Callback类来实现回调函数。然后,您可以实现以下任意数量的透明命名方法,这些方法在训练过程中的各个时刻调用:
on_epoch_begin(epoch, logs) # ❶
on_epoch_end(epoch, logs) # ❷
on_batch_begin(batch, logs) # ❸
on_batch_end(batch, logs) # ❹
on_train_begin(logs) # ❺
on_train_end(logs) # ❻
❶ 在每个时期开始时调用
❷ 在每个时期结束时调用
❸ 在处理每个批次之前调用
❹ 在处理每个批次后立即调用
❺ 在训练开始时调用
❻ 在训练结束时调用
这些方法都带有一个logs参数,其中包含有关先前批次、时期或训练运行的信息——训练和验证指标等。on_epoch_*和on_batch_*方法还将时期或批次索引作为它们的第一个参数(一个整数)。
这里有一个简单的示例,它保存了训练过程中每个批次的损失值列表,并在每个时期结束时保存了这些值的图表。
列表 7.20 通过继承Callback类创建自定义回调
from matplotlib import pyplot as plt
class LossHistory(keras.callbacks.Callback):
def on_train_begin(self, logs):
self.per_batch_losses = []
def on_batch_end(self, batch, logs):
self.per_batch_losses.append(logs.get("loss"))
def on_epoch_end(self, epoch, logs):
plt.clf()
plt.plot(range(len(self.per_batch_losses)), self.per_batch_losses,
label="Training loss for each batch")
plt.xlabel(f"Batch (epoch {epoch})")
plt.ylabel("Loss")
plt.legend()
plt.savefig(f"plot_at_epoch_{epoch}")
self.per_batch_losses = []
让我们试驾一下:
model = get_mnist_model()
model.compile(optimizer="rmsprop",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
model.fit(train_images, train_labels,
epochs=10,
callbacks=[LossHistory()],
validation_data=(val_images, val_labels))
我们得到的图表看起来像图 7.5。
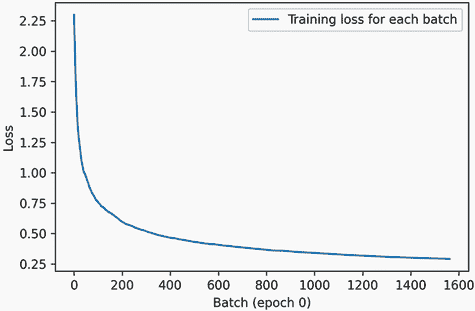
图 7.5 我们自定义历史绘图回调的输出
7.3.4 使用 TensorBoard 进行监控和可视化
要进行良好的研究或开发良好的模型,您需要在实验过程中获得关于模型内部情况的丰富、频繁的反馈。这就是进行实验的目的:获取有关模型表现的信息——尽可能多的信息。取得进展是一个迭代过程,一个循环——您从一个想法开始,并将其表达为一个实验,试图验证或否定您的想法。您运行此实验并处理它生成的信息。这激发了您的下一个想法。您能够运行此循环的迭代次数越多,您的想法就会变得越精细、更强大。Keras 帮助您在最短的时间内从想法到实验,快速的 GPU 可以帮助您尽快从实验到结果。但是处理实验结果呢?这就是 TensorBoard 的作用(见图 7.6)。

图 7.6 进展的循环
TensorBoard(www.tensorflow.org/tensorboard)是一个基于浏览器的应用程序,您可以在本地运行。这是在训练过程中监视模型内部所有活动的最佳方式。使用 TensorBoard,您可以
-
在训练过程中可视化监控指标
-
可视化您的模型架构
-
可视化激活和梯度的直方图
-
在 3D 中探索嵌入
如果您监控的信息不仅仅是模型的最终损失,您可以更清晰地了解模型的作用和不作用,并且可以更快地取得进展。
使用 TensorBoard 与 Keras 模型和fit()方法的最简单方法是使用keras.callbacks.TensorBoard回调。
在最简单的情况下,只需指定回调写入日志的位置,然后就可以开始了:
model = get_mnist_model()
model.compile(optimizer="rmsprop",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
tensorboard = keras.callbacks.TensorBoard(
log_dir="/full_path_to_your_log_dir",
)
model.fit(train_images, train_labels,
epochs=10,
validation_data=(val_images, val_labels),
callbacks=[tensorboard])
一旦模型开始运行,它将在目标位置写入日志。如果您在本地计算机上运行 Python 脚本,则可以使用以下命令启动本地 TensorBoard 服务器(请注意,如果您通过pip安装了 TensorFlow,则tensorboard可执行文件应该已经可用;如果没有,则可以通过pip install tensorboard手动安装 TensorBoard):
tensorboard --logdir /full_path_to_your_log_dir
然后,您可以转到命令返回的 URL 以访问 TensorBoard 界面。
如果您在 Colab 笔记本中运行脚本,则可以作为笔记本的一部分运行嵌入式 TensorBoard 实例,使用以下命令:
%load_ext tensorboard
%tensorboard --logdir /full_path_to_your_log_dir
在 TensorBoard 界面中,您将能够监视训练和评估指标的实时图表(参见图 7.7)。

图 7.7 TensorBoard 可用于轻松监控训练和评估指标。
7.4 编写自己的训练和评估循环
fit()工作流在易用性和灵活性之间取得了很好的平衡。这是您大部分时间将使用的方法。但是,即使使用自定义指标、自定义损失和自定义回调,它也不意味着支持深度学习研究人员可能想要做的一切。
毕竟,内置的fit()工作流仅专注于监督学习:一种已知目标(也称为标签或注释)与输入数据相关联的设置,您根据这些目标和模型预测的函数计算损失。然而,并非所有形式的机器学习都属于这一类别。还有其他设置,其中没有明确的目标,例如生成学习(我们将在第十二章中讨论)、自监督学习(目标来自输入)和强化学习(学习受偶尔“奖励”驱动,类似训练狗)。即使您正在进行常规监督学习,作为研究人员,您可能希望添加一些需要低级灵活性的新颖功能。
每当您发现内置的fit()不够用时,您将需要编写自己的自定义训练逻辑。您已经在第二章和第三章看到了低级训练循环的简单示例。作为提醒,典型训练循环的内容如下:
-
运行前向传播(计算模型的输出)在梯度磁带内以获得当前数据批次的损失值。
-
检索损失相对于模型权重的梯度。
-
更新模型的权重以降低当前数据批次上的损失值。
这些步骤将根据需要重复多个批次。这基本上是fit()在幕后执行的操作。在本节中,您将学习如何从头开始重新实现fit(),这将为您提供编写任何可能想出的训练算法所需的所有知识。
让我们详细了解一下。
7.4.1 训练与推断
在你迄今为止看到的低级训练循环示例中,第 1 步(前向传播)通过predictions = model(inputs)完成,第 2 步(检索梯度)通过gradients = tape.gradient(loss, model.weights)完成。在一般情况下,实际上有两个你需要考虑的细微之处。
一些 Keras 层,比如Dropout层,在训练和推理(当你用它们生成预测时)时有不同的行为。这些层在它们的call()方法中暴露了一个training布尔参数。调用dropout(inputs, training=True)会丢弃一些激活条目,而调用dropout(inputs, training=False)则不会做任何操作。扩展到 Functional 和 Sequential 模型,它们的call()方法中也暴露了这个training参数。记得在前向传播时传递training=True给 Keras 模型!因此我们的前向传播变成了predictions = model(inputs, training=True)。
另外,请注意,当你检索模型权重的梯度时,不应该使用tape.gradients(loss, model.weights),而应该使用tape .gradients(loss, model.trainable_weights)。实际上,层和模型拥有两种权重:
-
可训练权重—这些权重通过反向传播来更新,以最小化模型的损失,比如
Dense层的核和偏置。 -
不可训练权重—这些权重在前向传播过程中由拥有它们的层更新。例如,如果你想让一个自定义层记录到目前为止处理了多少批次,那么这些信息将存储在不可训练权重中,每个批次,你的层会将计数器加一。
在 Keras 内置层中,唯一具有不可训练权重的层是BatchNormalization层,我们将在第九章讨论。BatchNormalization层需要不可训练权重来跟踪通过它的数据的均值和标准差的信息,以便执行特征归一化的在线近似(这是你在第六章学到的概念)。
考虑到这两个细节,监督学习训练步骤最终看起来像这样:
def train_step(inputs, targets):
with tf.GradientTape() as tape:
predictions = model(inputs, training=True)
loss = loss_fn(targets, predictions)
gradients = tape.gradients(loss, model.trainable_weights)
optimizer.apply_gradients(zip(model.trainable_weights, gradients))
7.4.2 指标的低级使用
在低级训练循环中,你可能想要利用 Keras 指标(无论是自定义的还是内置的)。你已经了解了指标 API:只需为每个目标和预测批次调用update_state(y_true, y_pred),然后使用result()来查询当前指标值:
metric = keras.metrics.SparseCategoricalAccuracy()
targets = [0, 1, 2]
predictions = [[1, 0, 0], [0, 1, 0], [0, 0, 1]]
metric.update_state(targets, predictions)
current_result = metric.result()
print(f"result: {current_result:.2f}")
你可能还需要跟踪标量值的平均值,比如模型的损失。你可以通过keras.metrics.Mean指标来实现这一点:
values = [0, 1, 2, 3, 4]
mean_tracker = keras.metrics.Mean()
for value in values:
mean_tracker.update_state(value)
print(f"Mean of values: {mean_tracker.result():.2f}")
当你想要重置当前结果(在训练周期的开始或评估的开始)时,请记得使用metric.reset_state()。
7.4.3 完整的训练和评估循环
让我们将前向传播、反向传播和指标跟踪结合到一个类似于fit()的训练步骤函数中,该函数接受一批数据和目标,并返回fit()进度条显示的日志。
列表 7.21 编写逐步训练循环:训练步骤函数
model = get_mnist_model()
loss_fn = keras.losses.SparseCategoricalCrossentropy() # ❶
optimizer = keras.optimizers.RMSprop() # ❷
metrics = [keras.metrics.SparseCategoricalAccuracy()] # ❸
loss_tracking_metric = keras.metrics.Mean() # ❹
def train_step(inputs, targets):
with tf.GradientTape() as tape: # ❺
predictions = model(inputs, training=True) # ❺
loss = loss_fn(targets, predictions) # ❺
gradients = tape.gradient(loss, model.trainable_weights) # ❻
optimizer.apply_gradients(zip(gradients, model.trainable_weights)) # ❻
logs = {} # ❼
for metric in metrics: # ❼
metric.update_state(targets, predictions) # ❼
logs[metric.name] = metric.result() # ❼
loss_tracking_metric.update_state(loss) # ❽
logs["loss"] = loss_tracking_metric.result() # ❽
return logs # ❾
❶ 准备损失函数。
❷ 准备优化器。
❸ 准备要监视的指标列表。
❹ 准备一个 Mean 指标追踪器来跟踪损失的平均值。
❺ 进行前向传播。注意我们传递了training=True。
❻ 进行反向传播。注意我们使用了model.trainable_weights。
❼ 跟踪指标。
❽ 跟踪损失平均值。
❾ 返回当前的指标值和损失。
我们需要在每个周期开始和运行评估之前重置指标的状态。这里有一个实用函数来做到这一点。
列表 7.22 编写逐步训练循环:重置指标
def reset_metrics():
for metric in metrics:
metric.reset_state()
loss_tracking_metric.reset_state()
现在我们可以布置完整的训练循环。请注意,我们使用tf.data.Dataset对象将我们的 NumPy 数据转换为一个迭代器,该迭代器按大小为 32 的批次迭代数据。
列表 7.23 编写逐步训练循环:循环本身
training_dataset = tf.data.Dataset.from_tensor_slices(
(train_images, train_labels))
training_dataset = training_dataset.batch(32)
epochs = 3
for epoch in range(epochs):
reset_metrics()
for inputs_batch, targets_batch in training_dataset:
logs = train_step(inputs_batch, targets_batch)
print(f"Results at the end of epoch {epoch}")
for key, value in logs.items():
print(f"...{key}: {value:.4f}")
这就是评估循环:一个简单的for循环,反复调用test_step()函数,该函数处理一个数据批次。test_step()函数只是train_step()逻辑的一个子集。它省略了处理更新模型权重的代码——也就是说,所有涉及GradientTape和优化器的内容。
列表 7.24 编写逐步评估循环
def test_step(inputs, targets):
predictions = model(inputs, training=False) # ❶
loss = loss_fn(targets, predictions)
logs = {}
for metric in metrics:
metric.update_state(targets, predictions)
logs["val_" + metric.name] = metric.result()
loss_tracking_metric.update_state(loss)
logs["val_loss"] = loss_tracking_metric.result()
return logs
val_dataset = tf.data.Dataset.from_tensor_slices((val_images, val_labels))
val_dataset = val_dataset.batch(32)
reset_metrics()
for inputs_batch, targets_batch in val_dataset:
logs = test_step(inputs_batch, targets_batch)
print("Evaluation results:")
for key, value in logs.items():
print(f"...{key}: {value:.4f}")
❶ 注意我们传递了 training=False。
恭喜你——你刚刚重新实现了fit()和evaluate()!或几乎:fit()和evaluate()支持许多更多功能,包括大规模分布式计算,这需要更多的工作。它还包括几个关键的性能优化。
让我们来看看其中一个优化:TensorFlow 函数编译。
7.4.4 使用 tf.function 使其更快
你可能已经注意到,尽管实现了基本相同的逻辑,但自定义循环的运行速度明显比内置的fit()和evaluate()慢。这是因为,默认情况下,TensorFlow 代码是逐行执行的,急切执行,类似于 NumPy 代码或常规 Python 代码。急切执行使得调试代码更容易,但从性能的角度来看远非最佳选择。
将你的 TensorFlow 代码编译成一个可以全局优化的计算图更有效。要做到这一点的语法非常简单:只需在要执行之前的任何函数中添加@tf.function,如下面的示例所示。
列表 7.25 为我们的评估步骤函数添加@tf.function装饰器
@tf.function # ❶
def test_step(inputs, targets):
predictions = model(inputs, training=False)
loss = loss_fn(targets, predictions)
logs = {}
for metric in metrics:
metric.update_state(targets, predictions)
logs["val_" + metric.name] = metric.result()
loss_tracking_metric.update_state(loss)
logs["val_loss"] = loss_tracking_metric.result()
return logs
val_dataset = tf.data.Dataset.from_tensor_slices((val_images, val_labels))
val_dataset = val_dataset.batch(32)
reset_metrics()
for inputs_batch, targets_batch in val_dataset:
logs = test_step(inputs_batch, targets_batch)
print("Evaluation results:")
for key, value in logs.items():
print(f"...{key}: {value:.4f}")
❶ 这是唯一改变的一行。
在 Colab CPU 上,我们从运行评估循环需要 1.80 秒,降低到只需要 0.8 秒。速度更快!
记住,在调试代码时,最好急切地运行它,不要添加任何@tf.function装饰器。这样更容易跟踪错误。一旦你的代码运行正常并且想要加快速度,就在你的训练步骤和评估步骤或任何其他性能关键函数中添加@tf.function装饰器。
7.4.5 利用 fit() 与自定义训练循环
在之前的章节中,我们完全从头开始编写自己的训练循环。这样做为你提供了最大的灵活性,但同时你会写很多代码,同时错过了fit()的许多便利功能,比如回调或内置的分布式训练支持。
如果你需要一个自定义训练算法,但仍想利用内置 Keras 训练逻辑的强大功能,那么实际上在fit()和从头编写的训练循环之间有一个中间地带:你可以提供一个自定义训练步骤函数,让框架来处理其余部分。
你可以通过重写Model类的train_step()方法来实现这一点。这个函数是fit()为每个数据批次调用的函数。然后你可以像往常一样调用fit(),它将在幕后运行你自己的学习算法。
这里有一个简单的例子:
-
我们创建一个继承
keras.Model的新类。 -
我们重写了方法
train_step(self,data)。它的内容几乎与我们在上一节中使用的内容相同。它返回一个将度量名称(包括损失)映射到它们当前值的字典。 -
我们实现了一个
metrics属性,用于跟踪模型的Metric实例。这使得模型能够在每个时期开始和在调用evaluate()开始时自动调用reset_state()模型的度量,因此你不必手动执行。
列表 7.26 实现一个自定义训练步骤以与fit()一起使用
loss_fn = keras.losses.SparseCategoricalCrossentropy()
loss_tracker = keras.metrics.Mean(name="loss") # ❶
class CustomModel(keras.Model):
def train_step(self, data): # ❷
inputs, targets = data
with tf.GradientTape() as tape:
predictions = self(inputs, training=True) # ❸
loss = loss_fn(targets, predictions)
gradients = tape.gradient(loss, model.trainable_weights)
optimizer.apply_gradients(zip(gradients, model.trainable_weights))
loss_tracker.update_state(loss) # ❹
return {"loss": loss_tracker.result()} # ❺
@property
def metrics(self): # ❻
return [loss_tracker] # ❻
❶ 这个度量对象将用于跟踪训练和评估过程中每个批次损失的平均值。
❷ 我们重写了 train_step 方法。
❸ 我们使用self(inputs, training=True)而不是model(inputs, training=True),因为我们的模型就是类本身。
❹ 我们更新跟踪平均损失的损失跟踪器指标。
❺ 通过查询损失跟踪器指标返回到目前为止的平均损失。
❻ 任何你想要在不同 epoch 之间重置的指标都应该在这里列出。
现在,我们可以实例化我们的自定义模型,编译它(我们只传递了优化器,因为损失已经在模型外部定义),并像往常一样使用fit()进行训练:
inputs = keras.Input(shape=(28 * 28,))
features = layers.Dense(512, activation="relu")(inputs)
features = layers.Dropout(0.5)(features)
outputs = layers.Dense(10, activation="softmax")(features)
model = CustomModel(inputs, outputs)
model.compile(optimizer=keras.optimizers.RMSprop())
model.fit(train_images, train_labels, epochs=3)
有几点需要注意:
-
这种模式不会阻止你使用 Functional API 构建模型。无论你是构建 Sequential 模型、Functional API 模型还是子类化模型,都可以做到这一点。
-
当你重写
train_step时,不需要使用@tf.function装饰器—框架会为你做这件事。
现在,关于指标,以及如何通过compile()配置损失呢?在调用compile()之后,你可以访问以下内容:
-
self.compiled_loss—你传递给compile()的损失函数。 -
self.compiled_metrics—对你传递的指标列表的包装器,允许你调用self.compiled_metrics.update_state()一次性更新所有指标。 -
self.metrics—你传递给compile()的实际指标列表。请注意,它还包括一个跟踪损失的指标,类似于我们之前手动使用loss_tracking_metric所做的。
因此,我们可以写下
class CustomModel(keras.Model):
def train_step(self, data):
inputs, targets = data
with tf.GradientTape() as tape:
predictions = self(inputs, training=True)
loss = self.compiled_loss(targets, predictions) # ❶
gradients = tape.gradient(loss, model.trainable_weights)
optimizer.apply_gradients(zip(gradients, model.trainable_weights))
self.compiled_metrics.update_state(targets, predictions) # ❷
return {m.name: m.result() for m in self.metrics} # ❸
❶ 通过self.compiled_loss计算损失。
❷ 通过self.compiled_metrics更新模型的指标。
❸ 返回一个将指标名称映射到它们当前值的字典。
让我们试试:
inputs = keras.Input(shape=(28 * 28,))
features = layers.Dense(512, activation="relu")(inputs)
features = layers.Dropout(0.5)(features)
outputs = layers.Dense(10, activation="softmax")(features)
model = CustomModel(inputs, outputs)
model.compile(optimizer=keras.optimizers.RMSprop(),
loss=keras.losses.SparseCategoricalCrossentropy(),
metrics=[keras.metrics.SparseCategoricalAccuracy()])
model.fit(train_images, train_labels, epochs=3)
这是很多信息,但现在你已经了解足够多的内容来使用 Keras 做几乎任何事情了。
摘要
-
Keras 提供了一系列不同的工作流程,基于逐步透露复杂性的原则。它们之间可以平滑地互操作。
-
你可以通过
Sequential类、Functional API 或通过子类化Model类来构建模型。大多数情况下,你会使用 Functional API。 -
训练和评估模型的最简单方法是通过默认的
fit()和evaluate()方法。 -
Keras 回调提供了一种简单的方法,在调用
fit()期间监视模型,并根据模型的状态自动采取行动。 -
你也可以通过重写
train_step()方法完全控制fit()的行为。 -
除了
fit(),你还可以完全从头开始编写自己的训练循环。这对于实现全新训练算法的研究人员非常有用。
八、计算机视觉深度学习简介
本章涵盖
-
理解卷积神经网络(卷积网络)
-
使用数据增强来减轻过拟合
-
使用预训练的卷积网络进行特征提取
-
对预训练的卷积网络进行微调
计算机视觉是深度学习最早也是最大的成功故事。每天,你都在与深度视觉模型互动——通过 Google 照片、Google 图像搜索、YouTube、相机应用中的视频滤镜、OCR 软件等等。这些模型也是自动驾驶、机器人、AI 辅助医学诊断、自动零售结账系统甚至自动农业等尖端研究的核心。
计算机视觉是在 2011 年至 2015 年间导致深度学习初次崛起的问题领域。一种称为卷积神经网络的深度学习模型开始在那个时候在图像分类竞赛中取得非常好的结果,首先是 Dan Ciresan 在两个小众竞赛中获胜(2011 年 ICDAR 汉字识别竞赛和 2011 年 IJCNN 德国交通标志识别竞赛),然后更引人注目的是 2012 年秋季 Hinton 的团队赢得了备受关注的 ImageNet 大规模视觉识别挑战赛。在其他计算机视觉任务中,很快也涌现出更多有希望的结果。
有趣的是,这些早期的成功并不足以使深度学习在当时成为主流——这花了几年的时间。计算机视觉研究社区花了很多年投资于除神经网络之外的方法,他们并不准备放弃这些方法,只因为有了一个新的玩家。在 2013 年和 2014 年,深度学习仍然面临着许多资深计算机视觉研究人员的强烈怀疑。直到 2016 年,它才最终占据主导地位。我记得在 2014 年 2 月,我曾劝告我的一位前教授转向深度学习。“这是下一个大事!”我会说。“嗯,也许只是一时的热潮,”他回答。到了 2016 年,他的整个实验室都在做深度学习。一个时机已经成熟的想法是无法阻挡的。
本章介绍了卷积神经网络,也被称为卷积网络,这种深度学习模型现在几乎在计算机视觉应用中被普遍使用。你将学会将卷积网络应用于图像分类问题,特别是涉及小训练数据集的问题,如果你不是一个大型科技公司,这是最常见的用例。
8.1 卷积网络简介
我们将要深入探讨卷积网络是什么以及为什么它们在计算机视觉任务中取得如此成功的理论。但首先,让我们从一个简单的卷积网络示例开始,该示例对 MNIST 数字进行分类,这是我们在第二章中使用全连接网络执行的任务(当时我们的测试准确率为 97.8%)。即使卷积网络很基础,它的准确率也会远远超过我们在第二章中使用的全连接模型。
以下列表显示了基本卷积网络的外观。它是一堆Conv2D和MaxPooling2D层。你马上就会看到它们的作用。我们将使用我们在上一章中介绍的函数式 API 构建模型。
列表 8.1 实例化一个小型卷积网络
from tensorflow import keras
from tensorflow.keras import layers
inputs = keras.Input(shape=(28, 28, 1))
x = layers.Conv2D(filters=32, kernel_size=3, activation="relu")(inputs)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=64, kernel_size=3, activation="relu")(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=128, kernel_size=3, activation="relu")(x)
x = layers.Flatten()(x)
outputs = layers.Dense(10, activation="softmax")(x)
model = keras.Model(inputs=inputs, outputs=outputs)
重要的是,卷积神经网络以形状为(image_height, image_width, image_channels)的张量作为输入,不包括批处理维度。在这种情况下,我们将配置卷积网络以处理大小为(28, 28, 1)的输入,这是 MNIST 图像的格式。
让我们展示一下我们卷积网络的架构。
列表 8.2 显示模型的摘要
>>> model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 28, 28, 1)] 0
_________________________________________________________________
conv2d (Conv2D) (None, 26, 26, 32) 320
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 13, 13, 32) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 11, 11, 64) 18496
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 5, 5, 64) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 3, 3, 128) 73856
_________________________________________________________________
flatten (Flatten) (None, 1152) 0
_________________________________________________________________
dense (Dense) (None, 10) 11530
=================================================================
Total params: 104,202
Trainable params: 104,202
Non-trainable params: 0
_________________________________________________________________
你可以看到每个Conv2D和MaxPooling2D层的输出是形状为(height, width, channels)的三维张量。随着模型深入,宽度和高度维度会逐渐缩小。通道的数量由传递给Conv2D层的第一个参数控制(32、64 或 128)。
在最后一个Conv2D层之后,我们得到了一个形状为(3, 3, 128)的输出——一个 3×3 的 128 通道特征图。下一步是将这个输出馈送到一个类似你已经熟悉的密集连接分类器的地方:一堆Dense层。这些分类器处理向量,这些向量是 1D 的,而当前的输出是一个秩为 3 的张量。为了弥合这个差距,我们使用Flatten层将 3D 输出展平为 1D,然后再添加Dense层。
最后,我们进行 10 路分类,所以我们的最后一层有 10 个输出和 softmax 激活。
现在,让我们在 MNIST 数字上训练卷积神经网络。我们将重用第二章 MNIST 示例中的许多代码。因为我们要进行 10 路分类,并且输出是 softmax,所以我们将使用分类交叉熵损失,因为我们的标签是整数,所以我们将使用稀疏版本,sparse_categorical_crossentropy。
列表 8.3 在 MNIST 图像上训练卷积神经网络
from tensorflow.keras.datasets import mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = train_images.reshape((60000, 28, 28, 1))
train_images = train_images.astype("float32") / 255
test_images = test_images.reshape((10000, 28, 28, 1))
test_images = test_images.astype("float32") / 255
model.compile(optimizer="rmsprop",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
model.fit(train_images, train_labels, epochs=5, batch_size=64)
让我们在测试数据上评估模型。
列表 8.4 评估卷积神经网络
>>> test_loss, test_acc = model.evaluate(test_images, test_labels)
>>> print(f"Test accuracy: {test_acc:.3f}")
Test accuracy: 0.991
相比之前第二章的密集连接模型的测试准确率为 97.8%,基本卷积神经网络的测试准确率为 99.1%:我们将错误率降低了约 60%(相对)。不错!
但是,为什么这个简单的卷积神经网络效果如此出色,相比之下要好于密集连接模型?为了回答这个问题,让我们深入了解Conv2D和MaxPooling2D层的作用。
8.1.1 卷积操作
密集连接层和卷积层之间的根本区别在于:Dense层在其输入特征空间中学习全局模式(例如,对于 MNIST 数字,涉及所有像素的模式),而卷积层学习局部模式——在图像的情况下,是在输入的小 2D 窗口中找到的模式(见图 8.1)。在前面的例子中,这些窗口都是 3×3 的。
图 8.1 图像可以被分解为局部模式,如边缘、纹理等。
这个关键特征赋予了卷积神经网络两个有趣的特性:
-
它们学习的模式是平移不变的。在学习了图片右下角的某个模式后,卷积神经网络可以在任何地方识别它:例如,在左上角。密集连接模型如果出现在新位置,就必须重新学习这个模式。这使得卷积神经网络在处理图像时具有数据效率(因为视觉世界在根本上是平移不变的):它们需要更少的训练样本来学习具有泛化能力的表示。
-
它们可以学习空间模式的层次结构。第一个卷积层将学习小的局部模式,如边缘,第二个卷积层将学习由第一层特征组成的更大模式,依此类推(见图 8.2)。这使得卷积神经网络能够高效地学习越来越复杂和抽象的视觉概念,因为视觉世界在根本上是空间层次结构的。

图 8.2 视觉世界形成了视觉模块的空间层次结构:基本线条或纹理组合成简单的对象,如眼睛或耳朵,这些对象组合成高级概念,如“猫”。
卷积在称为特征图的秩为 3 的张量上运行,具有两个空间轴(高度和宽度)以及一个深度轴(也称为通道轴)。对于 RGB 图像,深度轴的维度为 3,因为图像具有三个颜色通道:红色、绿色和蓝色。对于像 MNIST 数字这样的黑白图片,深度为 1(灰度级)。卷积操作从其输入特征图中提取补丁,并对所有这些补丁应用相同的变换,生成一个输出特征图。这个输出特征图仍然是一个秩为 3 的张量:它有一个宽度和一个高度。它的深度可以是任意的,因为输出深度是层的一个参数,而该深度轴中的不同通道不再代表 RGB 输入中的特定颜色;相反,它们代表滤波器。滤波器编码输入数据的特定方面:在高层次上,单个滤波器可以编码“输入中存在面孔”的概念,例如。
在 MNIST 示例中,第一个卷积层接收大小为(28, 28, 1)的特征图,并输出大小为(26, 26, 32)的特征图:它在输入上计算 32 个滤波器。这 32 个输出通道中的每一个包含一个 26×26 的值网格,这是滤波器在输入上的响应图,指示了该滤波器模式在输入的不同位置的响应(见图 8.3)。

图 8.3 响应图的概念:在输入的不同位置显示模式存在的 2D 地图
这就是术语特征图的含义:深度轴中的每个维度都是一个特征(或滤波器),而张量output[:, :, n]是该滤波器在输入上的 2D 空间响应图。
卷积由两个关键参数定义:
-
从输入中提取的补丁的大小—通常为 3×3 或 5×5。在示例中,它们是 3×3,这是一个常见选择。
-
输出特征图的深度—这是卷积计算的滤波器数量。示例从深度为 32 开始,最终深度为 64。
在 Keras 的Conv2D层中,这些参数是传递给层的第一个参数:Conv2D(output_depth, (window_height, window_width))。
卷积通过在 3D 输入特征图上滑动大小为 3×3 或 5×5 的窗口,在每个可能的位置停止,并提取周围特征的 3D 补丁(形状为(window_height, window_width, input_depth))。然后,每个这样的 3D 补丁通过与一个学习的权重矩阵进行张量积转换为形状为(output_depth,)的 1D 向量,称为卷积核—相同的核在每个补丁上重复使用。所有这些向量(每个补丁一个)然后在空间上重新组装成形状为(height, width, output_ depth)的 3D 输出图。输出特征图中的每个空间位置对应于输入特征图中的相同位置(例如,输出的右下角包含有关输入右下角的信息)。例如,对于 3×3 窗口,向量output[i, j, :]来自 3D 补丁input[i-1:i+1, j-1:j+1, :]。整个过程在图 8.4 中有详细说明。

图 8.4 卷积的工作原理
请注意,输出宽度和高度可能与输入宽度和高度不同,原因有两个:
-
边界效应,可以通过填充输入特征图来抵消
-
步幅的使用,我将在下一节中定义
让我们更深入地了解这些概念。
理解边界效应和填充
考虑一个 5×5 的特征图(总共 25 个瓦片)。只有 9 个瓦片周围可以放置一个 3×3 窗口的中心,形成一个 3×3 的网格(见图 8.5)。因此,输出特征图将是 3×3。它会略微缩小:在每个维度上正好减少两个瓦片,本例中是这样。您可以在之前的示例中看到这种边界效应:您从 28×28 的输入开始,经过第一层卷积后变为 26×26。

图 8.5 5×5 输入特征图中 3×3 补丁的有效位置
如果您想获得与输入相同空间维度的输出特征图,可以使用填充。填充包括在输入特征图的每一侧添加适当数量的行和列,以便使每个输入瓦片周围都能放置中心卷积窗口。对于 3×3 窗口,您在右侧添加一列,在左侧添加一列,在顶部添加一行,在底部添加一行。对于 5×5 窗口,您添加两行(见图 8.6)。

图 8.6 对 5×5 输入进行填充以便提取 25 个 3×3 补丁
在Conv2D层中,填充可以通过padding参数进行配置,该参数接受两个值:"valid"表示无填充(只使用有效的窗口位置),“same"表示“填充以使输出具有与输入相同的宽度和高度”。padding参数默认为"valid”。
理解卷积步幅
影响输出大小的另一个因素是步幅的概念。到目前为止,我们对卷积的描述假定卷积窗口的中心瓦片都是连续的。但是两个连续窗口之间的距离是卷积的一个参数,称为步幅,默认为 1。可以进行步幅卷积:步幅大于 1 的卷积。在图 8.7 中,您可以看到在 5×5 输入(无填充)上使用步幅 2 进行 3×3 卷积提取的补丁。
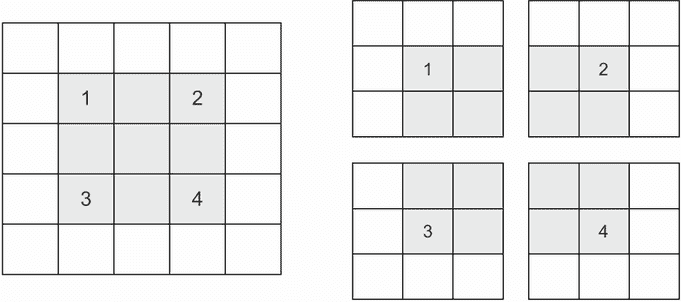
图 8.7 2×2 步幅下的 3×3 卷积补丁
使用步幅 2 意味着特征图的宽度和高度会被下采样 2 倍(除了边界效应引起的任何变化)。步幅卷积在分类模型中很少使用,但对于某些类型的模型非常有用,您将在下一章中看到。
在分类模型中,我们倾向于使用最大池化操作来对特征图进行下采样,您在我们的第一个卷积神经网络示例中看到了它的作用。让我们更深入地看一下。
8.1.2 最大池化操作
在卷积神经网络示例中,您可能已经注意到在每个MaxPooling2D层之后特征图的大小减半。例如,在第一个MaxPooling2D层之前,特征图为 26×26,但最大池化操作将其减半为 13×13。这就是最大池化的作用:大幅度地对特征图进行下采样,类似于步幅卷积。
最大池化包括从输入特征图中提取窗口并输出每个通道的最大值。它在概念上类似于卷积,不同之处在于,最大池化不是通过学习的线性变换(卷积核)来转换局部补丁,而是通过硬编码的max张量操作来转换。与卷积的一个重要区别是,最大池化通常使用 2×2 窗口和步幅 2 进行,以便将特征图下采样 2 倍。另一方面,卷积通常使用 3×3 窗口和无步幅(步幅 1)。
为什么要以这种方式对特征图进行下采样?为什么不删除最大池化层,一直保持相当大的特征图?让我们看看这个选项。我们的模型将如下所示。
列表 8.5 一个结构不正确的卷积神经网络,缺少最大池化层
inputs = keras.Input(shape=(28, 28, 1))
x = layers.Conv2D(filters=32, kernel_size=3, activation="relu")(inputs)
x = layers.Conv2D(filters=64, kernel_size=3, activation="relu")(x)
x = layers.Conv2D(filters=128, kernel_size=3, activation="relu")(x)
x = layers.Flatten()(x)
outputs = layers.Dense(10, activation="softmax")(x)
model_no_max_pool = keras.Model(inputs=inputs, outputs=outputs)
这里是模型的摘要:
>>> model_no_max_pool.summary()
Model: "model_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 28, 28, 1)] 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 26, 26, 32) 320
_________________________________________________________________
conv2d_4 (Conv2D) (None, 24, 24, 64) 18496
_________________________________________________________________
conv2d_5 (Conv2D) (None, 22, 22, 128) 73856
_________________________________________________________________
flatten_1 (Flatten) (None, 61952) 0
_________________________________________________________________
dense_1 (Dense) (None, 10) 619530
=================================================================
Total params: 712,202
Trainable params: 712,202
Non-trainable params: 0
_________________________________________________________________
这种设置有什么问题?有两个问题:
-
这不利于学习特征的空间层次结构。第三层中的 3×3 窗口只包含来自初始输入的 7×7 窗口的信息。卷积网络学到的高级模式仍然相对于初始输入非常小,这可能不足以学会分类数字(尝试仅通过查看 7×7 像素窗口来识别数字!)。我们需要最后一个卷积层的特征包含关于整个输入的信息。
-
最终的特征图每个样本有 22×22×128 = 61,952 个总系数。这是巨大的。当你将其展平以在顶部放置一个
Dense层大小为 10 时,该层将有超过一百万个参数。对于这样一个小模型来说,这太大了,会导致严重的过拟合。
简而言之,使用降采样的原因是减少要处理的特征图系数的数量,并通过使连续的卷积层查看越来越大的窗口(就覆盖原始输入的部分而言)来引入空间滤波器层次结构。
注意,最大池化并不是唯一实现这种降采样的方法。正如你已经知道的,你也可以在先前的卷积层中使用步幅。你也可以使用平均池化代替最大池化,其中每个局部输入块通过取该块上每个通道的平均值来进行转换,而不是最大值。但是最大池化往往比这些替代方案效果更好。原因在于特征往往编码了特定模式或概念在特征图的不同块上的空间存在(因此术语特征图),查看不同特征的最大存在比查看它们的平均存在更具信息量。最合理的子采样策略是首先通过非步幅卷积生成密集特征图,然后查看特征在小块上的最大激活,而不是查看输入的稀疏窗口(通过步幅卷积)或平均输入块,这可能导致您错过或稀释特征存在信息。
此时,你应该了解卷积网络的基础知识——特征图、卷积和最大池化,并且应该知道如何构建一个小型卷积网络来解决诸如 MNIST 数字分类之类的玩具问题。现在让我们转向更有用、实际的应用。
8.2 在小数据集上从头开始训练卷积网络
不得不使用非常少的数据训练图像分类模型是一种常见情况,在实践中,如果你在专业环境中进行计算机视觉,你可能会遇到这种情况。少量样本可以是从几百到几万张图像。作为一个实际例子,我们将专注于在一个包含 5,000 张猫和狗图片的数据集中对图像进行分类(2,500 只猫,2,500 只狗)。我们将使用 2,000 张图片进行训练,1,000 张用于验证,2,000 张用于测试。
在本节中,我们将回顾一种基本策略来解决这个问题:使用你拥有的少量数据从头开始训练一个新模型。我们将从头开始训练一个小型卷积网络,使用 2,000 个训练样本,没有任何正则化,来建立一个可以实现的基准。这将使我们达到约 70%的分类准确率。在那时,主要问题将是过拟合。然后我们将介绍数据增强,这是一种在计算机视觉中减轻过拟合的强大技术。通过使用数据增强,我们将改进模型,使准确率达到 80-85%。
在下一节中,我们将回顾将深度学习应用于小数据集的另外两种基本技术:使用预训练模型进行特征提取(这将使我们达到 97.5% 的准确率)和微调预训练模型(这将使我们达到最终准确率 98.5%)。这三种策略——从头开始训练一个小模型、使用预训练模型进行特征提取以及微调预训练模型——将构成您未来解决使用小数据集进行图像分类问题的工具箱。
8.2.1 深度学习在小数据问题上的相关性
什么样的“足够样本”可以用来训练模型是相对的——相对于您尝试训练的模型的大小和深度。仅凭几十个样本无法训练卷积网络解决复杂问题,但如果模型小且经过良好的正则化,任务简单,那么几百个样本可能就足够了。因为卷积网络学习局部、平移不变的特征,它们在感知问题上具有高效的数据利用率。在非常小的图像数据集上从头开始训练卷积网络将产生合理的结果,尽管数据相对较少,无需进行任何自定义特征工程。您将在本节中看到这一点。
此外,深度学习模型天生具有高度的可重用性:您可以拿一个在大规模数据集上训练的图像分类或语音转文本模型,仅进行轻微更改就可以在完全不同的问题上重用它。具体来说,在计算机视觉领域,现在有许多预训练模型(通常在 ImageNet 数据集上训练)可以公开下载,并且可以用来从很少的数据中启动强大的视觉模型。这是深度学习的最大优势之一:特征重用。您将在下一节中探索这一点。
让我们开始获取数据。
8.2.2 下载数据
我们将使用的 Dogs vs. Cats 数据集不随 Keras 打包。它是由 Kaggle 在 2013 年底作为计算机视觉竞赛的一部分提供的,当时卷积网络还不是主流。您可以从 www.kaggle.com/c/dogs-vs-cats/data 下载原始数据集(如果您还没有 Kaggle 帐户,需要创建一个—不用担心,这个过程很简单)。您将可以使用 Kaggle API 在 Colab 中下载数据集(请参阅“在 Google Colaboratory 中下载 Kaggle 数据集”侧边栏)。
在 Google Colaboratory 中下载 Kaggle 数据集
Kaggle 提供了一个易于使用的 API,用于以编程方式下载托管在 Kaggle 上的数据集。例如,您可以使用它将 Dogs vs. Cats 数据集下载到 Colab 笔记本中。这个 API 可以作为 kaggle 包使用,在 Colab 上预先安装。在 Colab 单元格中运行以下命令就可以轻松下载这个数据集:
!kaggle competitions download -c dogs-vs-cats
然而,API 的访问权限仅限于 Kaggle 用户,因此为了运行上述命令,您首先需要进行身份验证。kaggle 包将在位于 ~/.kaggle/kaggle.json 的 JSON 文件中查找您的登录凭据。让我们创建这个文件。
首先,您需要创建一个 Kaggle API 密钥并将其下载到本地计算机。只需在 Web 浏览器中导航到 Kaggle 网站,登录,然后转到“我的帐户”页面。在您的帐户设置中,您会找到一个 API 部分。点击“创建新的 API 令牌”按钮将生成一个 kaggle.json 密钥文件,并将其下载到您的计算机。
其次,转到您的 Colab 笔记本,并通过在笔记本单元格中运行以下代码将 API 密钥 JSON 文件上传到您的 Colab 会话:
from google.colab import files
files.upload()
当您运行此单元格时,您将看到一个“选择文件”按钮出现。点击它并选择您刚下载的 kaggle.json 文件。这将上传文件到本地的 Colab 运行时。
最后,创建一个 ~/.kaggle 文件夹(mkdir ~/.kaggle),并将密钥文件复制到其中(cp kaggle.json ~/.kaggle/)。作为安全最佳实践,您还应确保该文件仅可由当前用户,即您自己(chmod 600)读取:
!mkdir ~/.kaggle
!cp kaggle.json ~/.kaggle/
!chmod 600 ~/.kaggle/kaggle.json
您现在可以下载我们即将使用的数据:
!kaggle competitions download -c dogs-vs-cats
第一次尝试下载数据时,您可能会收到“403 Forbidden”错误。这是因为您需要在下载数据之前接受与数据集相关的条款 - 您需要转到 www.kaggle.com/c/dogs-vs-cats/rules(登录到您的 Kaggle 帐户)并点击“我理解并接受”按钮。您只需要执行一次此操作。
最后,训练数据是一个名为 train.zip 的压缩文件。确保您安静地解压缩它(unzip -qq):
!unzip -qq train.zip
我们数据集中的图片是中等分辨率的彩色 JPEG 图片。图 8.8 展示了一些示例。

图 8.8 显示了来自狗与猫数据集的样本。大小没有被修改:样本具有不同的大小、颜色、背景等。
毫不奇怪,最早的狗与猫 Kaggle 竞赛,即 2013 年,是由使用卷积网络的参赛者赢得的。最好的参赛作品达到了高达 95% 的准确率。在这个示例中,我们将接近这个准确率(在下一节中),即使我们将在可用于参赛者的数据的不到 10% 上训练我们的模型。
该数据集包含 25,000 张狗和猫的图片(每类 12,500 张)并且大小为 543 MB(压缩)。在下载和解压缩数据后,我们将创建一个新数据集,其中包含三个子集:一个包含每个类别 1,000 个样本的训练集,一个包含每个类别 500 个样本的验证集,以及一个包含每个类别 1,000 个样本的测试集。为什么这样做?因为您在职业生涯中遇到的许多图像数据集只包含几千个样本,而不是数万个。有更多的数据可用会使问题变得更容易,因此最好的做法是使用一个小数据集进行学习。
我们将使用的子采样数据集将具有以下目录结构:
cats_vs_dogs_small/
...train/
......cat/ # ❶
......dog/ # ❷
...validation/
......cat/ # ❸
......dog/ # ❹
...test/
......cat/ # ❺
......dog/ # ❻
❶ 包含 1,000 张猫的图片
❷ 包含 1,000 张狗的图片
❸ 包含 500 张猫的图片
❹ 包含 500 张狗的图片
❺ 包含 1,000 张猫的图片
❻ 包含 1,000 张狗的图片
让我们通过几次调用 shutil 来实现。
列表 8.6 将图片复制到训练、验证和测试目录
import os, shutil, pathlib
original_dir = pathlib.Path("train") # ❶
new_base_dir = pathlib.Path("cats_vs_dogs_small") # ❷
def make_subset(subset_name, start_index, end_index): # ❸
for category in ("cat", "dog"):
dir = new_base_dir / subset_name / category
os.makedirs(dir)
fnames = [f"{category}.{i}.jpg"
for i in range(start_index, end_index)]
for fname in fnames:
shutil.copyfile(src=original_dir / fname,
dst=dir / fname)
make_subset("train", start_index=0, end_index=1000) # ❹
make_subset("validation", start_index=1000, end_index=1500) # ❺
make_subset("test", start_index=1500, end_index=2500) # ❻
❶ 包含原始数据集解压缩后的目录路径
❷ 我们将存储我们较小数据集的目录
❸ 复制猫(和狗)图片的实用函数,从索引 start_index 到索引 end_index 复制到子目录 new_base_dir/{subset_name}/cat(和/dog)。“subset_name” 将是 “train”、“validation” 或 “test” 中的一个。
❹ 创建训练子集,包括每个类别的前 1,000 张图片。
❺ 创建验证子集,包括每个类别的接下来的 500 张图片。
❻ 创建测试子集,包括每个类别的接下来的 1,000 张图片。
现在我们有 2,000 张训练图片,1,000 张验证图片和 2,000 张测试图片。每个拆分包含每个类别相同数量的样本:这是一个平衡的二元分类问题,这意味着分类准确率将是一个适当的成功衡量标准。
8.2.3 构建模型
我们将重用你在第一个示例中看到的相同的通用模型结构:卷积网络将是交替的 Conv2D(带有 relu 激活)和 MaxPooling2D 层的堆叠。
但由于我们处理的是更大的图片和更复杂的问题,我们将相应地使我们的模型更大:它将有两个额外的 Conv2D 和 MaxPooling2D 阶段。这既增加了模型的容量,也进一步减小了特征图的大小,以便在达到 Flatten 层时它们不会过大。在这里,因为我们从大小为 180 像素 × 180 像素的输入开始(这是一个有点随意的选择),我们最终得到了在 Flatten 层之前大小为 7 × 7 的特征图。
注意:特征图的深度在模型中逐渐增加(从 32 增加到 256),而特征图的大小在减小(从 180 × 180 减小到 7 × 7)。这是您几乎在所有卷积网络中看到的模式。
因为我们正在处理一个二分类问题,所以我们将模型以一个单元(大小为 1 的 Dense 层)和一个 sigmoid 激活结束。这个单元将编码模型正在查看的是一个类还是另一个类的概率。
最后一个小差异:我们将使用一个 Rescaling 层开始模型,它将重新缩放图像输入(其值最初在 [0, 255] 范围内)到 [0, 1] 范围内。
列表 8.7 实例化一个用于狗与猫分类的小型卷积网络
from tensorflow import keras
from tensorflow.keras import layers
inputs = keras.Input(shape=(180, 180, 3)) # ❶
x = layers.Rescaling(1./255)(inputs) # ❷
x = layers.Conv2D(filters=32, kernel_size=3, activation="relu")(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=64, kernel_size=3, activation="relu")(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=128, kernel_size=3, activation="relu")(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=256, kernel_size=3, activation="relu")(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=256, kernel_size=3, activation="relu")(x)
x = layers.Flatten()(x)
outputs = layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs=inputs, outputs=outputs)
❶ 模型期望尺寸为 180 × 180 的 RGB 图像。
❷ 将输入重新缩放到 [0, 1] 范围,通过将它们除以 255。
让我们看看随着每一层的连续变化,特征图的维度如何改变:
>>> model.summary()
Model: "model_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_3 (InputLayer) [(None, 180, 180, 3)] 0
_________________________________________________________________
rescaling (Rescaling) (None, 180, 180, 3) 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 178, 178, 32) 896
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 89, 89, 32) 0
_________________________________________________________________
conv2d_7 (Conv2D) (None, 87, 87, 64) 18496
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 43, 43, 64) 0
_________________________________________________________________
conv2d_8 (Conv2D) (None, 41, 41, 128) 73856
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 20, 20, 128) 0
_________________________________________________________________
conv2d_9 (Conv2D) (None, 18, 18, 256) 295168
_________________________________________________________________
max_pooling2d_5 (MaxPooling2 (None, 9, 9, 256) 0
_________________________________________________________________
conv2d_10 (Conv2D) (None, 7, 7, 256) 590080
_________________________________________________________________
flatten_2 (Flatten) (None, 12544) 0
_________________________________________________________________
dense_2 (Dense) (None, 1) 12545
=================================================================
Total params: 991,041
Trainable params: 991,041
Non-trainable params: 0
_________________________________________________________________
对于编译步骤,我们将继续使用 RMSprop 优化器。因为我们最后一层是一个单一的 sigmoid 单元,所以我们将使用二元交叉熵作为损失函数(作为提醒,请查看第六章中表 6.1,了解在各种情况下使用哪种损失函数的速查表)。
列表 8.8 配置用于训练的模型
model.compile(loss="binary_crossentropy",
optimizer="rmsprop",
metrics=["accuracy"])
8.2.4 数据预处理
正如你现在所知,数据在被馈送到模型之前应该被格式化为适当预处理的浮点张量。目前,数据以 JPEG 文件的形式存储在驱动器上,因此将其传递到模型的步骤大致如下:
-
读取图片文件。
-
将 JPEG 内容解码为 RGB 像素网格。
-
将它们转换为浮点张量。
-
调整它们到共享大小(我们将使用 180 × 180)。
-
将它们打包成批次(我们将使用 32 张图像的批次)。
这可能看起来有点令人生畏,但幸运的是,Keras 有工具可以自动处理这些步骤。特别是,Keras 提供了实用函数 image_dataset_from_directory(),它可以让您快速设置一个数据管道,可以自动将磁盘上的图像文件转换为预处理张量的批次。这就是我们将在这里使用的方法。
调用 image_dataset_from_directory(directory) 首先会列出 directory 的子目录,并假定每个子目录包含一个类别的图像。然后,它将索引每个子目录中的图像文件。最后,它将创建并返回一个配置为读取这些文件、对其进行洗牌、解码为张量、调整大小为共享大小并打包成批次的 tf.data.Dataset 对象。
列表 8.9 使用 image_dataset_from_directory 读取图像
from tensorflow.keras.utils import image_dataset_from_directory
train_dataset = image_dataset_from_directory(
new_base_dir / "train",
image_size=(180, 180),
batch_size=32)
validation_dataset = image_dataset_from_directory(
new_base_dir / "validation",
image_size=(180, 180),
batch_size=32)
test_dataset = image_dataset_from_directory(
new_base_dir / "test",
image_size=(180, 180),
batch_size=32)
理解 TensorFlow Dataset 对象
TensorFlow 提供了 tf.data API 来为机器学习模型创建高效的输入管道。其核心类是 tf.data.Dataset。
Dataset 对象是一个迭代器:你可以在 for 循环中使用它。它通常会返回输入数据和标签的批次。你可以直接将 Dataset 对象传递给 Keras 模型的 fit() 方法。
Dataset 类处理许多关键功能,否则实现起来会很麻烦,特别是异步数据预取(在模型处理上一个批次数据的同时预处理下一个批次数据,从而保持执行流畅而没有中断)。
Dataset 类还提供了一个用于修改数据集的函数式 API。这里有一个快速示例:让我们从一个大小为 16 的随机数 NumPy 数组创建一个 Dataset 实例。我们将考虑 1,000 个样本,每个样本是一个大小为 16 的向量:
import numpy as np
import tensorflow as tf
random_numbers = np.random.normal(size=(1000, 16))
dataset = tf.data.Dataset.from_tensor_slices(random_numbers) # ❶
❶ 使用 from_tensor_slices() 类方法可以从 NumPy 数组、元组或字典中创建一个 Dataset。
起初,我们的数据集只产生单个样本:
>>> for i, element in enumerate(dataset):
>>> print(element.shape)
>>> if i >= 2:
>>> break
(16,)
(16,)
(16,)
我们可以使用 .batch() 方法对数据进行分批处理:
>>> batched_dataset = dataset.batch(32)
>>> for i, element in enumerate(batched_dataset):
>>> print(element.shape)
>>> if i >= 2:
>>> break
(32, 16)
(32, 16)
(32, 16)
更广泛地说,我们可以访问一系列有用的数据集方法,例如
-
.shuffle(buffer_size)—在缓冲区内对元素进行洗牌 -
.prefetch(buffer_size)—预取 GPU 内存中的一组元素,以实现更好的设备利用率。 -
.map(callable)—对数据集的每个元素应用任意转换(函数callable,期望接受数据集产生的单个元素作为输入)。
.map()方法特别常用。这里有一个例子。我们将用它将我们的玩具数据集中的元素从形状(16,)改变为形状(4, 4):
>>> reshaped_dataset = dataset.map(lambda x: tf.reshape(x, (4, 4)))
>>> for i, element in enumerate(reshaped_dataset):
>>> print(element.shape)
>>> if i >= 2:
>>> break
(4, 4)
(4, 4)
(4, 4)
在本章中,你将看到更多map()的应用。
让我们看看其中一个Dataset对象的输出:它产生大小为(32, 180, 180, 3)的 RGB 图像批次和整数标签(形状为(32,))。每个批次中有 32 个样本(批次大小)。
列表 8.10 显示Dataset产生的数据和标签的形状
>>> for data_batch, labels_batch in train_dataset:
>>> print("data batch shape:", data_batch.shape)
>>> print("labels batch shape:", labels_batch.shape)
>>> break
data batch shape: (32, 180, 180, 3)
labels batch shape: (32,)
让我们在我们的数据集上拟合模型。我们将使用fit()中的validation_data参数来监视单独的Dataset对象上的验证指标。
请注意,我们还将使用ModelCheckpoint回调来在每个周期后保存模型。我们将配置它的路径,指定保存文件的位置,以及参数save_best_only=True和monitor="val_loss":它们告诉回调只在当前val_loss指标的值低于训练过程中任何先前时间的值时保存新文件(覆盖任何先前的文件)。这确保了你保存的文件始终包含模型对验证数据表现最佳的训练周期状态。因此,如果开始过拟合,我们不必重新训练一个更少周期的模型:我们只需重新加载保存的文件。
列表 8.11 使用Dataset拟合模型
callbacks = [
keras.callbacks.ModelCheckpoint(
filepath="convnet_from_scratch.keras",
save_best_only=True,
monitor="val_loss")
]
history = model.fit(
train_dataset,
epochs=30,
validation_data=validation_dataset,
callbacks=callbacks)
让我们绘制模型在训练和验证数据上的损失和准确率随训练过程的变化(见图 8.9)。
列表 8.12 显示训练过程中损失和准确率的曲线
import matplotlib.pyplot as plt
accuracy = history.history["accuracy"]
val_accuracy = history.history["val_accuracy"]
loss = history.history["loss"]
val_loss = history.history["val_loss"]
epochs = range(1, len(accuracy) + 1)
plt.plot(epochs, accuracy, "bo", label="Training accuracy")
plt.plot(epochs, val_accuracy, "b", label="Validation accuracy")
plt.title("Training and validation accuracy")
plt.legend()
plt.figure()
plt.plot(epochs, loss, "bo", label="Training loss")
plt.plot(epochs, val_loss, "b", label="Validation loss")
plt.title("Training and validation loss")
plt.legend()
plt.show()

图 8.9 简单卷积网络的训练和验证指标
这些图表是过拟合的特征。训练准确率随时间线性增加,直到接近 100%,而验证准确率在 75%时达到峰值。验证损失在仅十个周期后达到最小值,然后停滞,而训练损失随着训练的进行线性减少。
让我们检查测试准确率。我们将从保存的文件重新加载模型以评估它在过拟合之前的状态。
列表 8.13 在测试集上评估模型
test_model = keras.models.load_model("convnet_from_scratch.keras")
test_loss, test_acc = test_model.evaluate(test_dataset)
print(f"Test accuracy: {test_acc:.3f}")
我们得到了 69.5% 的测试准确率。(由于神经网络初始化的随机性,你可能得到与此相差不到一个百分点的数字。)
因为我们有相对较少的训练样本(2,000),过拟合将是我们关注的首要问题。你已经了解到一些可以帮助减轻过拟合的技术,如 dropout 和权重衰减(L2 正则化)。现在我们将使用一个新的技术,特定于计算机视觉,并在使用深度学习模型处理图像时几乎普遍使用:数据增强。
8.2.5 使用数据增强
过拟合是由于样本量太少,导致无法训练出能够泛化到新数据的模型。如果有无限的数据,你的模型将暴露于手头数据分布的每一个可能方面:你永远不会过拟合。数据增强采取生成更多训练数据的方法,通过一些随机转换增强样本,生成看起来可信的图像。目标是,在训练时,你的模型永远不会看到完全相同的图片。这有助于让模型接触数据的更多方面,从而更好地泛化。
在 Keras 中,可以通过在模型开头添加一些数据增强层来实现。让我们通过一个示例开始:下面的 Sequential 模型链接了几个随机图像转换。在我们的模型中,我们会在Rescaling层之前包含它。
列表 8.14 定义要添加到图像模型中的数据增强阶段
data_augmentation = keras.Sequential(
[
layers.RandomFlip("horizontal"),
layers.RandomRotation(0.1),
layers.RandomZoom(0.2),
]
)
这些只是一些可用的层(更多内容,请参阅 Keras 文档)。让我们快速浏览一下这段代码:
-
RandomFlip("horizontal")—对通过它的随机 50%图像应用水平翻转 -
RandomRotation(0.1)—将输入图像旋转一个在范围[–10%,+10%]内的随机值(这些是完整圆的分数—以度为单位,范围将是[–36 度,+36 度]) -
RandomZoom(0.2)—通过在范围[-20%,+20%]内的随机因子放大或缩小图像
让我们看一下增强后的图像(参见图 8.10)。
列表 8.15 显示一些随机增强的训练图像
plt.figure(figsize=(10, 10))
for images, _ in train_dataset.take(1): # ❶
for i in range(9):
augmented_images = data_augmentation(images) # ❷
ax = plt.subplot(3, 3, i + 1)
plt.imshow(augmented_images[0].numpy().astype("uint8")) # ❸
plt.axis("off")
❶ 我们可以使用 take(N)仅从数据集中取样 N 批次。这相当于在第 N 批次后的循环中插入一个中断。
❷ 将增强阶段应用于图像批次。
❸ 显示输出批次中的第一张图像。对于九次迭代中的每一次,这是同一图像的不同增强。

图 8.10 通过随机数据增强生成一个非常好的男孩的变化
如果我们使用这个数据增强配置训练一个新模型,那么模型将永远不会看到相同的输入两次。但是它看到的输入仍然高度相关,因为它们来自少量原始图像—我们无法产生新信息;我们只能重新混合现有信息。因此,这可能不足以完全消除过拟合。为了进一步对抗过拟合,我们还将在密集连接分类器之前向我们的模型添加一个Dropout层。
关于随机图像增强层,还有一件事你应该知道:就像Dropout一样,在推断时(当我们调用predict()或evaluate()时),它们是不活动的。在评估期间,我们的模型的行为将与不包括数据增强和 dropout 时完全相同。
列表 8.16 定义一个包含图像增强和 dropout 的新卷积神经网络
inputs = keras.Input(shape=(180, 180, 3))
x = data_augmentation(inputs)
x = layers.Rescaling(1./255)(x)
x = layers.Conv2D(filters=32, kernel_size=3, activation="relu")(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=64, kernel_size=3, activation="relu")(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=128, kernel_size=3, activation="relu")(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=256, kernel_size=3, activation="relu")(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=256, kernel_size=3, activation="relu")(x)
x = layers.Flatten()(x)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs=inputs, outputs=outputs)
model.compile(loss="binary_crossentropy",
optimizer="rmsprop",
metrics=["accuracy"])
让我们使用数据增强和 dropout 来训练模型。因为我们预计过拟合会在训练期间发生得更晚,所以我们将训练三倍的时期—一百个时期。
列表 8.17 训练正则化的卷积神经网络
callbacks = [
keras.callbacks.ModelCheckpoint(
filepath="convnet_from_scratch_with_augmentation.keras",
save_best_only=True,
monitor="val_loss")
]
history = model.fit(
train_dataset,
epochs=100,
validation_data=validation_dataset,
callbacks=callbacks)
让我们再次绘制结果:参见图 8.11。由于数据增强和 dropout,我们开始过拟合的时间要晚得多,大约在 60-70 个时期(与原始模型的 10 个时期相比)。验证准确性最终稳定在 80-85%的范围内—相比我们的第一次尝试,这是一个很大的改进。
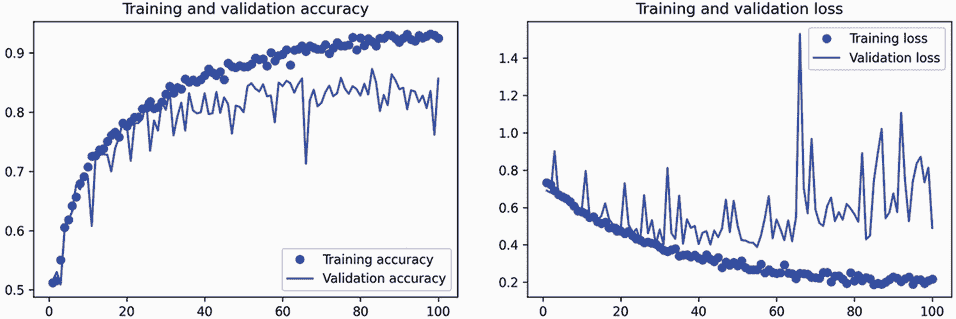
图 8.11 使用数据增强的训练和验证指标
让我们检查测试准确性。
列表 8.18 在测试集上评估模型
test_model = keras.models.load_model(
"convnet_from_scratch_with_augmentation.keras")
test_loss, test_acc = test_model.evaluate(test_dataset)
print(f"Test accuracy: {test_acc:.3f}")
我们获得了 83.5%的测试准确性。看起来不错!如果你在使用 Colab,请确保下载保存的文件(convnet_from_scratch_with_augmentation.keras),因为我们将在下一章中用它进行一些实验。
通过进一步调整模型的配置(例如每个卷积层的滤波器数量,或模型中的层数),我们可能能够获得更高的准确性,可能高达 90%。但是,仅通过从头开始训练我们自己的卷积神经网络,要想获得更高的准确性将会变得困难,因为我们的数据量太少。为了提高这个问题上的准确性,我们将不得不使用一个预训练模型,这是接下来两节的重点。
8.3 利用预训练模型
一种常见且高效的小图像数据集深度学习方法是使用预训练模型。预训练模型是先前在大型数据集上训练过的模型,通常是在大规模图像分类任务上。如果原始数据集足够大且足够通用,那么预训练模型学习到的空间特征层次结构可以有效地充当视觉世界的通用模型,因此,其特征对许多不同的计算机视觉问题都可能有用,即使这些新问题可能涉及与原始任务完全不同的类别。例如,您可以在 ImageNet 上训练一个模型(其中类别主要是动物和日常物品),然后将这个训练好的模型重新用于识别图像中的家具物品等远程任务。与许多较旧的、浅层学习方法相比,学习到的特征在不同问题之间的可移植性是深度学习的一个关键优势,这使得深度学习在小数据问题上非常有效。
在这种情况下,让我们考虑一个在 ImageNet 数据集上训练的大型卷积网络(140 万标记图像和 1000 个不同类别)。ImageNet 包含许多动物类别,包括不同品种的猫和狗,因此您可以期望它在狗与猫的分类问题上表现良好。
我们将使用 VGG16 架构,这是由 Karen Simonyan 和 Andrew Zisserman 于 2014 年开发的。虽然这是一个较老的模型,远非当前技术水平,并且比许多其他最新模型要重,但我选择它是因为其架构类似于您已经熟悉的内容,并且没有引入任何新概念。这可能是您第一次遇到这些可爱的模型名称之一——VGG、ResNet、Inception、Xception 等;如果您继续进行计算机视觉的深度学习,您将经常遇到它们。
使用预训练模型有两种方法:特征提取和微调。我们将涵盖这两种方法。让我们从特征提取开始。
8.3.1 使用预训练模型进行特征提取
特征提取包括使用先前训练模型学习到的表示来从新样本中提取有趣的特征。然后,这些特征通过一个新的分类器,该分类器是从头开始训练的。
正如您之前看到的,用于图像分类的卷积网络由两部分组成:它们从一系列池化和卷积层开始,然后以一个密集连接的分类器结束。第一部分被称为模型的卷积基础。在卷积网络的情况下,特征提取包括获取先前训练网络的卷积基础,将新数据通过它运行,并在输出之上训练一个新的分类器(参见图 8.12)。
图 8.12 在保持相同卷积基础的情况下交换分类器
为什么只重用卷积基?我们能否也重用密集连接的分类器?一般来说,应该避免这样做。原因是卷积基学习到的表示可能更通用,因此更具重用性:卷积网络的特征图是图片上通用概念的存在图,这些概念可能无论面临什么计算机视觉问题都有用。但分类器学习到的表示必然是特定于模型训练的类集合的——它们只包含关于整个图片中这个或那个类别存在概率的信息。此外,密集连接层中的表示不再包含有关对象在输入图像中位置的信息;这些层摆脱了空间的概念,而对象位置仍然由卷积特征图描述。对于需要考虑对象位置的问题,密集连接特征基本上是无用的。
请注意,特定卷积层提取的表示的泛化程度(因此可重用性)取决于模型中该层的深度。模型中较早的层提取局部、高度通用的特征图(如视觉边缘、颜色和纹理),而较高层提取更抽象的概念(如“猫耳”或“狗眼”)。因此,如果您的新数据集与原始模型训练的数据集差异很大,您可能最好只使用模型的前几层进行特征提取,而不是使用整个卷积基。
在这种情况下,因为 ImageNet 类别集包含多个狗和猫类别,重用原始模型的密集连接层中包含的信息可能是有益的。但我们选择不这样做,以涵盖新问题的类别集与原始模型的类别集不重叠的更一般情况。让我们通过使用在 ImageNet 上训练的 VGG16 网络的卷积基从猫和狗图片中提取有趣的特征,然后在这些特征之上训练一个狗与猫的分类器来实践这一点。
VGG16 模型,以及其他模型,已经预先打包在 Keras 中。您可以从 keras.applications 模块导入它。许多其他图像分类模型(都在 ImageNet 数据集上预训练)都作为 keras.applications 的一部分可用:
-
Xception
-
ResNet
-
MobileNet
-
EfficientNet
-
DenseNet
-
等等。
让我们实例化 VGG16 模型。
列表 8.19 实例化 VGG16 卷积基
conv_base = keras.applications.vgg16.VGG16(
weights="imagenet",
include_top=False,
input_shape=(180, 180, 3))
我们向构造函数传递三个参数:
-
weights指定了初始化模型的权重检查点。 -
include_top指的是是否包括(或不包括)网络顶部的密集连接分类器。默认情况下,这个密集连接分类器对应于 ImageNet 的 1,000 个类。因为我们打算使用我们自己的密集连接分类器(只有两个类:cat和dog),所以我们不需要包含它。 -
input_shape是我们将馈送到网络的图像张量的形状。这个参数是完全可选的:如果我们不传递它,网络将能够处理任何大小的输入。在这里,我们传递它,以便我们可以可视化(在下面的摘要中)随着每个新的卷积和池化层特征图的大小如何缩小。
这是 VGG16 卷积基架构的详细信息。它类似于您已经熟悉的简单卷积网络:
>>> conv_base.summary()
Model: "vgg16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_19 (InputLayer) [(None, 180, 180, 3)] 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 180, 180, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 180, 180, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 90, 90, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 90, 90, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 90, 90, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 45, 45, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 45, 45, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 45, 45, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 45, 45, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 22, 22, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 22, 22, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 22, 22, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 22, 22, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 11, 11, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 11, 11, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 11, 11, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 11, 11, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 5, 5, 512) 0
=================================================================
Total params: 14,714,688
Trainable params: 14,714,688
Non-trainable params: 0
_________________________________________________________________
最终的特征图形状为(5, 5, 512)。这是我们将在其上放置一个密集连接分类器的特征图。
在这一点上,我们可以有两种方式继续:
-
运行卷积基在我们的数据集上,将其输出记录到磁盘上的 NumPy 数组中,然后使用这些数据作为输入到一个独立的、与本书第四章中看到的类似的密集连接分类器。这种解决方案运行快速且成本低,因为它只需要为每个输入图像运行一次卷积基,而卷积基是整个流程中最昂贵的部分。但出于同样的原因,这种技术不允许我们使用数据增强。
-
通过在
conv_base顶部添加Dense层来扩展我们的模型,并在输入数据上端对端地运行整个模型。这将允许我们使用数据增强,因为每个输入图像在模型看到时都会经过卷积基。但出于同样的原因,这种技术比第一种要昂贵得多。
我们将涵盖这两种技术。让我们逐步了解设置第一种技术所需的代码:记录conv_base在我们的数据上的输出,并使用这些输出作为新模型的输入。
无数据增强的快速特征提取
我们将通过在训练、验证和测试数据集上调用conv_base模型的predict()方法来提取特征作为 NumPy 数组。
让我们迭代我们的数据集以提取 VGG16 特征。
列表 8.20 提取 VGG16 特征和相应标签
import numpy as np
def get_features_and_labels(dataset):
all_features = []
all_labels = []
for images, labels in dataset:
preprocessed_images = keras.applications.vgg16.preprocess_input(images)
features = conv_base.predict(preprocessed_images)
all_features.append(features)
all_labels.append(labels)
return np.concatenate(all_features), np.concatenate(all_labels)
train_features, train_labels = get_features_and_labels(train_dataset)
val_features, val_labels = get_features_and_labels(validation_dataset)
test_features, test_labels = get_features_and_labels(test_dataset)
重要的是,predict()只期望图像,而不是标签,但我们当前的数据集产生的批次包含图像和它们的标签。此外,VGG16模型期望使用keras.applications.vgg16.preprocess_input函数预处理输入,该函数将像素值缩放到适当的范围。
提取的特征目前的形状为(samples, 5, 5, 512):
>>> train_features.shape
(2000, 5, 5, 512)
在这一点上,我们可以定义我们的密集连接分类器(注意使用了 dropout 进行正则化),并在我们刚刚记录的数据和标签上对其进行训练。
列表 8.21 定义和训练密集连接分类器
inputs = keras.Input(shape=(5, 5, 512))
x = layers.Flatten()(inputs) # ❶
x = layers.Dense(256)(x)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs, outputs)
model.compile(loss="binary_crossentropy",
optimizer="rmsprop",
metrics=["accuracy"])
callbacks = [
keras.callbacks.ModelCheckpoint(
filepath="feature_extraction.keras",
save_best_only=True,
monitor="val_loss")
]
history = model.fit(
train_features, train_labels,
epochs=20,
validation_data=(val_features, val_labels),
callbacks=callbacks)
❶ 注意在将特征传递给密集层之前使用了 Flatten 层。
训练非常快,因为我们只需要处理两个Dense层——即使在 CPU 上,一个时代也不到一秒。
让我们在训练过程中查看损失和准确率曲线(见图 8.13)。
图 8.13 普通特征提取的训练和验证指标
列表 8.22 绘制结果
import matplotlib.pyplot as plt
acc = history.history["accuracy"]
val_acc = history.history["val_accuracy"]
loss = history.history["loss"]
val_loss = history.history["val_loss"]
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, "bo", label="Training accuracy")
plt.plot(epochs, val_acc, "b", label="Validation accuracy")
plt.title("Training and validation accuracy")
plt.legend()
plt.figure()
plt.plot(epochs, loss, "bo", label="Training loss")
plt.plot(epochs, val_loss, "b", label="Validation loss")
plt.title("Training and validation loss")
plt.legend()
plt.show()
我们达到了约 97%的验证准确率——比我们在前一节使用从头开始训练的小模型取得的结果要好得多。然而,这有点不公平的比较,因为 ImageNet 包含许多狗和猫实例,这意味着我们预训练的模型已经具有了完成任务所需的确切知识。当您使用预训练特征时,情况并不总是如此。
然而,图表也表明我们几乎从一开始就过拟合了——尽管使用了相当大的 dropout 率。这是因为这种技术没有使用数据增强,而数据增强对于防止小图像数据集过拟合是至关重要的。
结合数据增强的特征提取
现在让我们回顾一下我提到的第二种特征提取技术,这种技术速度较慢,成本较高,但允许我们在训练过程中使用数据增强:创建一个将conv_base与新的密集分类器连接起来的模型,并在输入上端对端地进行训练。
为了做到这一点,我们首先要冻结卷积基。冻结一层或一组层意味着在训练过程中阻止它们的权重被更新。如果我们不这样做,卷积基先前学到的表示将在训练过程中被修改。因为顶部的Dense层是随机初始化的,非常大的权重更新会通过网络传播,有效地破坏先前学到的表示。
在 Keras 中,通过将其trainable属性设置为False来冻结一个层或模型。
列表 8.23 实例化和冻结 VGG16 卷积基
conv_base = keras.applications.vgg16.VGG16(
weights="imagenet",
include_top=False)
conv_base.trainable = False
将trainable设置为False会清空层或模型的可训练权重列表。
列表 8.24 在冻结前后打印可训练权重列表
>>> conv_base.trainable = True
>>> print("This is the number of trainable weights "
"before freezing the conv base:", len(conv_base.trainable_weights))
This is the number of trainable weights before freezing the conv base: 26
>>> conv_base.trainable = False
>>> print("This is the number of trainable weights "
"after freezing the conv base:", len(conv_base.trainable_weights))
This is the number of trainable weights after freezing the conv base: 0
现在我们可以创建一个新模型,将
-
一个数据增强阶段
-
我们冻结的卷积基础
-
一个密集分类器
列表 8.25 向卷积基添加数据增强阶段和分类器
data_augmentation = keras.Sequential(
[
layers.RandomFlip("horizontal"),
layers.RandomRotation(0.1),
layers.RandomZoom(0.2),
]
)
inputs = keras.Input(shape=(180, 180, 3))
x = data_augmentation(inputs) # ❶
x = keras.applications.vgg16.preprocess_input(x) # ❷
x = conv_base(x)
x = layers.Flatten()(x)
x = layers.Dense(256)(x)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs, outputs)
model.compile(loss="binary_crossentropy",
optimizer="rmsprop",
metrics=["accuracy"])
❶ 应用数据增强。
❷ 应用输入值缩放。
使用这种设置,只有我们添加的两个Dense层的权重将被训练。总共有四个权重张量:每层两个(主要权重矩阵和偏置向量)。请注意,为了使这些更改生效,您必须首先编译模型。如果在编译后修改权重的可训练性,那么您应该重新编译模型,否则这些更改将被忽略。
让我们训练我们的模型。由于数据增强,模型开始过拟合的时间会更长,所以我们可以训练更多的 epochs——让我们做 50 个。
注意 这种技术足够昂贵,只有在您可以访问 GPU(例如 Colab 中提供的免费 GPU)时才应尝试——在 CPU 上无法实现。如果无法在 GPU 上运行代码,则应采用前一种技术。
callbacks = [
keras.callbacks.ModelCheckpoint(
filepath="feature_extraction_with_data_augmentation.keras",
save_best_only=True,
monitor="val_loss")
]
history = model.fit(
train_dataset,
epochs=50,
validation_data=validation_dataset,
callbacks=callbacks)
让我们再次绘制结果(参见图 8.14)。正如您所看到的,我们达到了超过 98%的验证准确率。这是对先前模型的一个强大改进。
图 8.14 使用数据增强进行特征提取的训练和验证指标
让我们检查测试准确率。
列表 8.26 在测试集上评估模型
test_model = keras.models.load_model(
"feature_extraction_with_data_augmentation.keras")
test_loss, test_acc = test_model.evaluate(test_dataset)
print(f"Test accuracy: {test_acc:.3f}")
我们得到了 97.5%的测试准确率。与先前的测试准确率相比,这只是一个适度的改进,考虑到验证数据的强大结果,有点令人失望。模型的准确性始终取决于您评估的样本集!某些样本集可能比其他样本集更难,对一个样本集的强大结果不一定会完全转化为所有其他样本集。
8.3.2 微调预训练模型
用于模型重用的另一种广泛使用的技术,与特征提取相辅相成,即微调(参见图 8.15)。微调包括解冻用于特征提取的冻结模型基础的顶部几层,并同时训练模型的这部分新添加部分(在本例中是全连接分类器)和这些顶部层。这被称为微调,因为它略微调整了被重用模型的更抽象的表示,以使它们对手头的问题更相关。

图 8.15 微调 VGG16 网络的最后一个卷积块
我之前说过,为了能够在顶部训练一个随机初始化的分类器,需要冻结 VGG16 的卷积基。出于同样的原因,只有在顶部的分类器已经训练好后,才能微调卷积基的顶层。如果分类器尚未训练好,那么在训练过程中通过网络传播的误差信号将会太大,并且之前由微调层学到的表示将被破坏。因此,微调网络的步骤如下:
-
在已经训练好的基础网络上添加我们的自定义网络。
-
冻结基础网络。
-
训练我们添加的部分。
-
解冻基础网络中的一些层。(请注意,不应解冻“批量归一化”层,在这里不相关,因为 VGG16 中没有这样的层。有关批量归一化及其对微调的影响,将在下一章中解释。)
-
同时训练这两个层和我们添加的部分。
在进行特征提取时,您已经完成了前三个步骤。让我们继续进行第四步:我们将解冻我们的conv_base,然后冻结其中的各个层。
作为提醒,这是我们的卷积基的样子:
>>> conv_base.summary()
Model: "vgg16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_19 (InputLayer) [(None, 180, 180, 3)] 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 180, 180, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 180, 180, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 90, 90, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 90, 90, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 90, 90, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 45, 45, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 45, 45, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 45, 45, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 45, 45, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 22, 22, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 22, 22, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 22, 22, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 22, 22, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 11, 11, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 11, 11, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 11, 11, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 11, 11, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 5, 5, 512) 0
=================================================================
Total params: 14,714,688
Trainable params: 14,714,688
Non-trainable params: 0
_________________________________________________________________
我们将微调最后三个卷积层,这意味着所有层直到block4_pool应该被冻结,而层block5_conv1、block5_conv2和block5_conv3应该是可训练的。
为什么不微调更多层?为什么不微调整个卷积基?你可以。但你需要考虑以下几点:
-
较早的卷积基层编码更通用、可重复使用的特征,而较高层编码更专业化的特征。对更专业化的特征进行微调更有用,因为这些特征需要在新问题上重新利用。微调较低层会有快速减少的回报。
-
您训练的参数越多,过拟合的风险就越大。卷积基有 1500 万个参数,因此在您的小数据集上尝试训练它是有风险的。
因此,在这种情况下,只微调卷积基的前两三层是一个好策略。让我们从前一个示例中结束的地方开始设置这个。
列表 8.27 冻结直到倒数第四层的所有层
conv_base.trainable = True
for layer in conv_base.layers[:-4]:
layer.trainable = False
现在我们可以开始微调模型了。我们将使用 RMSprop 优化器,使用非常低的学习率。使用低学习率的原因是我们希望限制对我们正在微调的三层表示所做修改的幅度。更新过大可能会损害这些表示。
列表 8.28 微调模型
model.compile(loss="binary_crossentropy",
optimizer=keras.optimizers.RMSprop(learning_rate=1e-5),
metrics=["accuracy"])
callbacks = [
keras.callbacks.ModelCheckpoint(
filepath="fine_tuning.keras",
save_best_only=True,
monitor="val_loss")
]
history = model.fit(
train_dataset,
epochs=30,
validation_data=validation_dataset,
callbacks=callbacks)
最终我们可以在测试数据上评估这个模型:
model = keras.models.load_model("fine_tuning.keras")
test_loss, test_acc = model.evaluate(test_dataset)
print(f"Test accuracy: {test_acc:.3f}")
在这里,我们获得了 98.5% 的测试准确率(再次强调,您自己的结果可能在一个百分点内)。在围绕这个数据集的原始 Kaggle 竞赛中,这将是顶尖结果之一。然而,这并不是一个公平的比较,因为我们使用了预训练特征,这些特征已经包含了关于猫和狗的先前知识,而竞争对手当时无法使用。
积极的一面是,通过利用现代深度学习技术,我们成功地仅使用了比比赛可用的训练数据的一小部分(约 10%)就达到了这个结果。在能够训练 20,000 个样本和 2,000 个样本之间存在巨大差异!
现在您已经掌握了一套处理图像分类问题的工具,特别是处理小数据集。
总结
-
卷积神经网络是计算机视觉任务中最好的机器学习模型类型。即使在一个非常小的数据集上,也可以从头开始训练一个,并取得不错的结果。
-
卷积神经网络通过学习一系列模块化的模式和概念来表示视觉世界。
-
在一个小数据集上,过拟合将是主要问题。数据增强是处理图像数据时对抗过拟合的强大方式。
-
通过特征提取,可以很容易地在新数据集上重用现有的卷积神经网络。这是处理小图像数据集的有价值的技术。
-
作为特征提取的补充,您可以使用微调,这会使现有模型先前学习的一些表示适应新问题。这会稍微提高性能。
¹ Karen Simonyan 和 Andrew Zisserman,“Very Deep Convolutional Networks for Large-Scale Image Recognition”,arXiv(2014),arxiv.org/abs/1409.1556。









