具体课程请看课程简介_哔哩哔哩_bilibili
概念

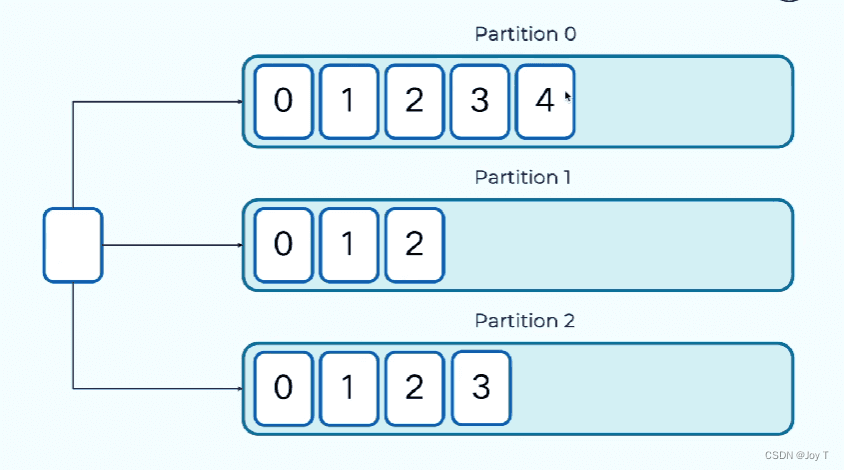
消息Record 以键值对的形式进行存储:

如果key不指定则默认为空#,此时生产者会以轮询的方式把消息写到不同的队列中。

有key的话生产者借助于分区器来分区,key同分区同。

生产者(Producers)
生产者 是向 Kafka 主题发送消息的客户端应用程序或系统。生产者负责创建消息,并将其发布到指定的 Kafka 主题。生产者可以通过指定消息的键(Key)来控制消息被发送到主题的哪个分区。
消费者(Consumers)
消费者 是从 Kafka 主题读取消息的客户端应用程序或系统。消费者可以订阅一个或多个主题,并从中读取消息数据进行处理。Kafka 还支持消费者组的概念,允许多个消费者作为一个组协同处理主题中的消息,实现消息的负载均衡和容错。
Kafka为生产者和消费者之间的消息传递提供服务。生产者和消费者都位于 Kafka 集群的外部,它们通过 Kafka 提供的客户端库与 Kafka 集群进行通信,实现消息的生产和消费。
Kafka 消息通道
消息通道作用:Kafka 集群充当生产者和消费者之间的消息通道,提供了高效、可靠的消息传递机制。Kafka 的设计目标是能够处理高速流动的数据,并支持数据的持久化存储,以便消费者可以根据需要读取数据,即使是在生产者发送消息后的很长一段时间。
- Kafka集群是由多个Broker消息代理组成的Kafka Cluster。
- Broker负责消息的读写请求并将消息写入磁盘中,通常在每个服务器中都启动一个Broker的实例。(这个面试的时候可以说一下啊)
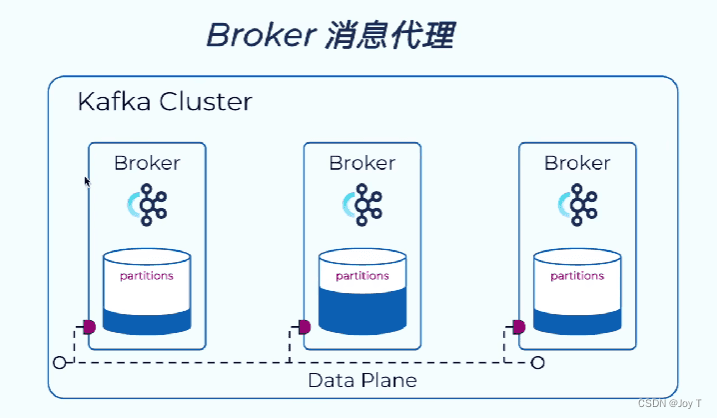
例子:八个Broker服务器,共有八种分区,每个分区都有三个备份。
- 以左上角为例,p1分区是leader,所以p1的所有读写请求和磁盘请求,都是由p1所在的服务器(Broker)处理。
- 对于p0和p2只是follower,所以Broker会找到他们的leader并且处理同步工作。

Kafka消息模型
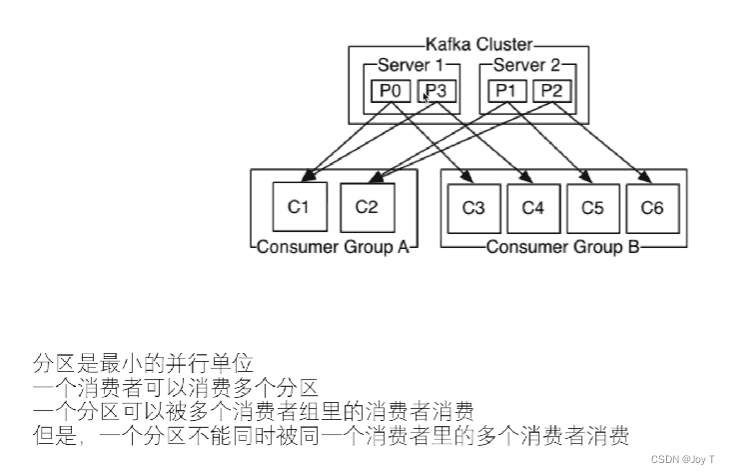
最后一句话少了个“组”。首先记忆消费者和分区是多对多的关系,然后只要多记住一个限制:同一个组的消费者不能同时消费一个分区(出于性能和开销的考虑,会额外引入锁这样的机制)。
发布订阅模式:每一个消息都会被每个消费者所消费。
- 措施:所有Consumer自成一组。

P2P:每个消息只用被消费一次即可。
- 措施:所有Consumer放在一个组,就不可能存在同一个组内的消费者多次消费某一个消息。
- 同时P2P利于负载均衡:便于动态扩展组的大小,扩展完后可以方便地均衡消费组内部的消费;或者减弱某消费者突然宕机产生的问题。
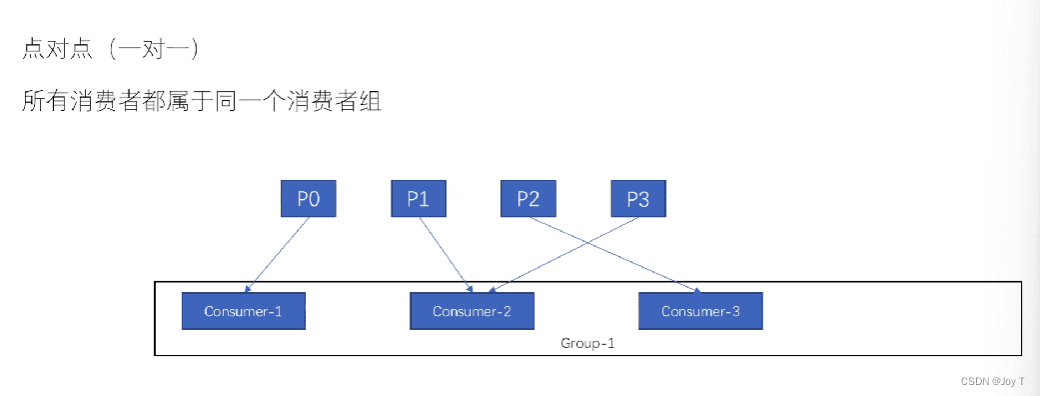

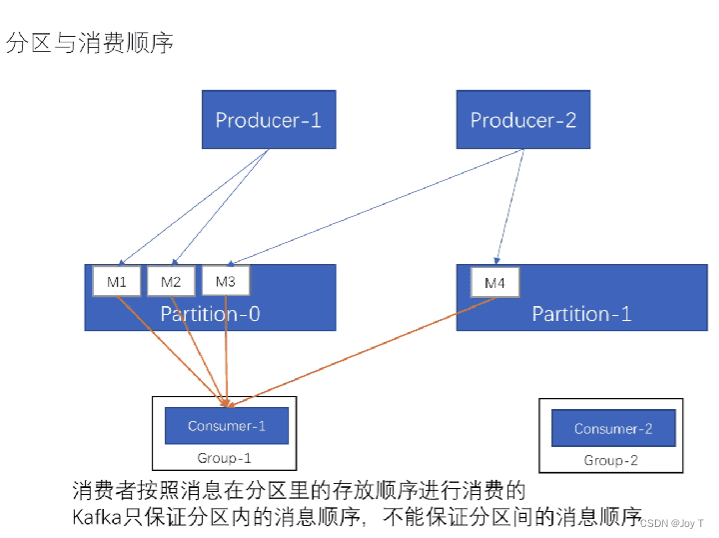
总而言之,无论是生产得到的offset消息顺序还是消费顺序,分区内部的消息是按顺序的,分区之间不存在任何的顺序相关性。
如果要保证消息的顺序应该怎么办?

消息传递语义(和Flink一样)

生产者将消息发送给Broker之后,Broker会发送ACK。在 Kafka 中,确保消息传递语义(至少一次、至多一次、正好一次)主要是通过消费者如何提交偏移量以及生产者如何发送消息(包括消息的确认机制)来实现的。
- 如果消费者在处理消息之前就提交偏移量至_consumer_offsets(一种特殊的Topic,存放每个Consumer的消费位置),然后消费消息,则属于最多一次(自动提交【下文会讲】可能会导致这种情况)。如果在处理消息之后发生故障,那些消息可能不会被重新消费。
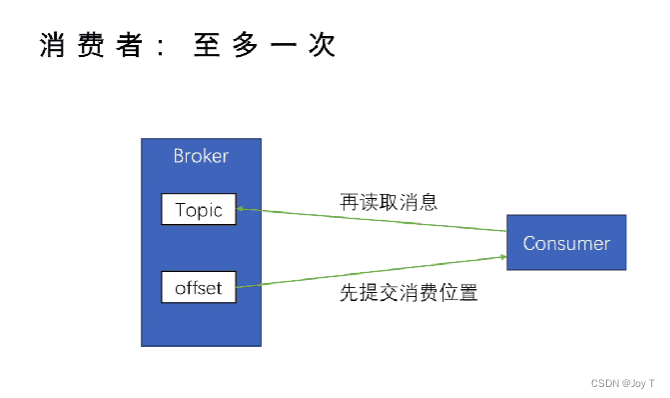
- 消费者在处理消息之后提交偏移量(通过手动提交实现)。这样,即使发生故障,消费者也可以从最后一个已知的提交偏移量重新开始,确保所有消息至少被处理一次。
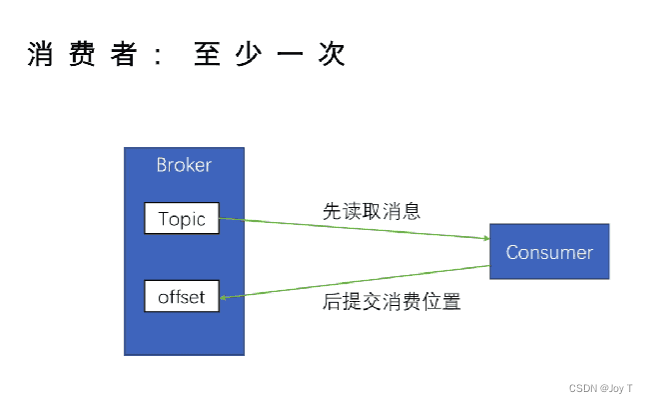
- 至多一次和至少一次的实现并不是通过“生产者确定提交偏移量位置”来实现的,而是依赖于消费者如何管理自己的偏移量提交策略。
精确一次:需要更复杂的机制,比如 Kafka 的事务(Transactions)支持,确保生产和消费过程中的消息不会丢失也不会被重复处理。
生产者API
生产者通过send发送消息:

生产者(客户端程序或系统)创建缓冲区,缓冲区会为每个分区创建一个缓冲以存放消息,大小为batch.size。生产者首先将消息放入对应分区的缓冲中,不管消息是否会成功发送到服务端Broker,转头继续消息的处理。(但是会随着acks的1/-1设置而异步接收ACK) 消息发送给Broker由后台IO线程负责。这样的异步模型有利于提高生产效率(可以类比于等待收货人签字和直接放入菜鸟驿站)。

在生产者和服务端通信之前会有一段connection建立联系的过程,生产者会同时不断地将消息放入到生产者的缓冲区中。等到connection建立完成,才由后台IO线程处理缓冲消息放在Broker中。
同步发送
- send方法会返回一段Future类型的结果,进一步通过它的get()方法对消息进行阻塞,等这一条消息发送之后才会进行下一条消息的发送。
批量发送
在请求非常频繁或者数据量非常大的情况下,可以通过设置linger.ms(延迟时间,单位ms。每几ms就发送一批消息。)和Batch.size(每一批消息的最大大小,只要数据量一到达这个大小,就会自动打包成批发送,忽略linger.ms的设置,及其霸道)这两个参数进行批量发送。
- 当消息设置了任何一个以上的两个参数,就会进行批量发送。可以理解为这两个参数的设置就是Kafka生产者批量发送的大门,开一个就ok。
生产者配置说明
- acks:Broker消息向生产者确认的ACK。(acks并不是配置ACK消息,而是配置ACK这个消息响应的机制)
- 0:生产者不会等待服务器端的任何请求,一旦消息进入缓冲,我们就认为它发送成功了,有可能会导致数据的丢失。这种模式的延迟最低,但数据丢失的风险也最高。
- 1:服务器端的leader已经将消息存储在本地,但是不管配套的follower是否同步完成,立马通知生产者消息发送成功。
- 默认值
- 这提供了一个中等级别的数据可靠性,可能会产生数据丢失:leader虽然收到了,但是还没来得及同步到follower就宕机了。
- -1/all:follower已经将leader存储的消息同步到磁盘中了,再发送成功ACK,这保证了消息数据不会丢失。
- 通常设置为all而不是默认值1
- 这提供了最高级别的数据可靠性保证,但相对来说,延迟也最高,因为它需要等待所有参与复制的副本都确认消息。
- retries:重试的次数,常见于消息发送失败后的重试。
- 默认0次
- 和acks配合使用就可以形成不同的消息传递语义:
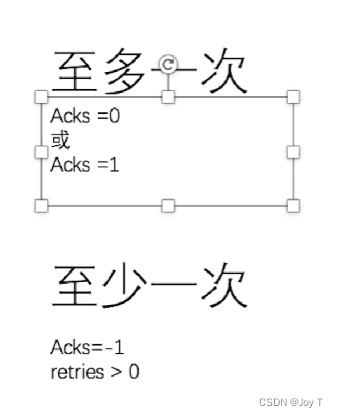
- 至多一次:Acks=0/1,不能保证消息的存在,可能会丢失数据,同时易知此时retries=0默认值。即使数据传输失败(没到缓冲或者leader没来的及存储到本地)也不会进行额外重复的发送。
- 至少一次:Acks=-1保证了消息一定不会丢失。同时retires>0,当消息发送失败了我们会对消息进行重复的发送。










