目录
1:ElasticSearch的是数据聚合
1.1:什么是聚合
在之前都是使用ES的查询,结合各种查询条件来查询出结果集,聚合即使查询的结果接
在学习聚合之前我们先来了解两个名字
1:桶(Buckets):满足于特定条件的结果集,相当于mysql的group by
2:指标(Metrics):对桶内的文档进行统计计算,相当于mysq的max()、min()、avg()函数
2:DSL聚合语句(在kinaba中测试)
2.1:DSL实现桶(Buckets)测试
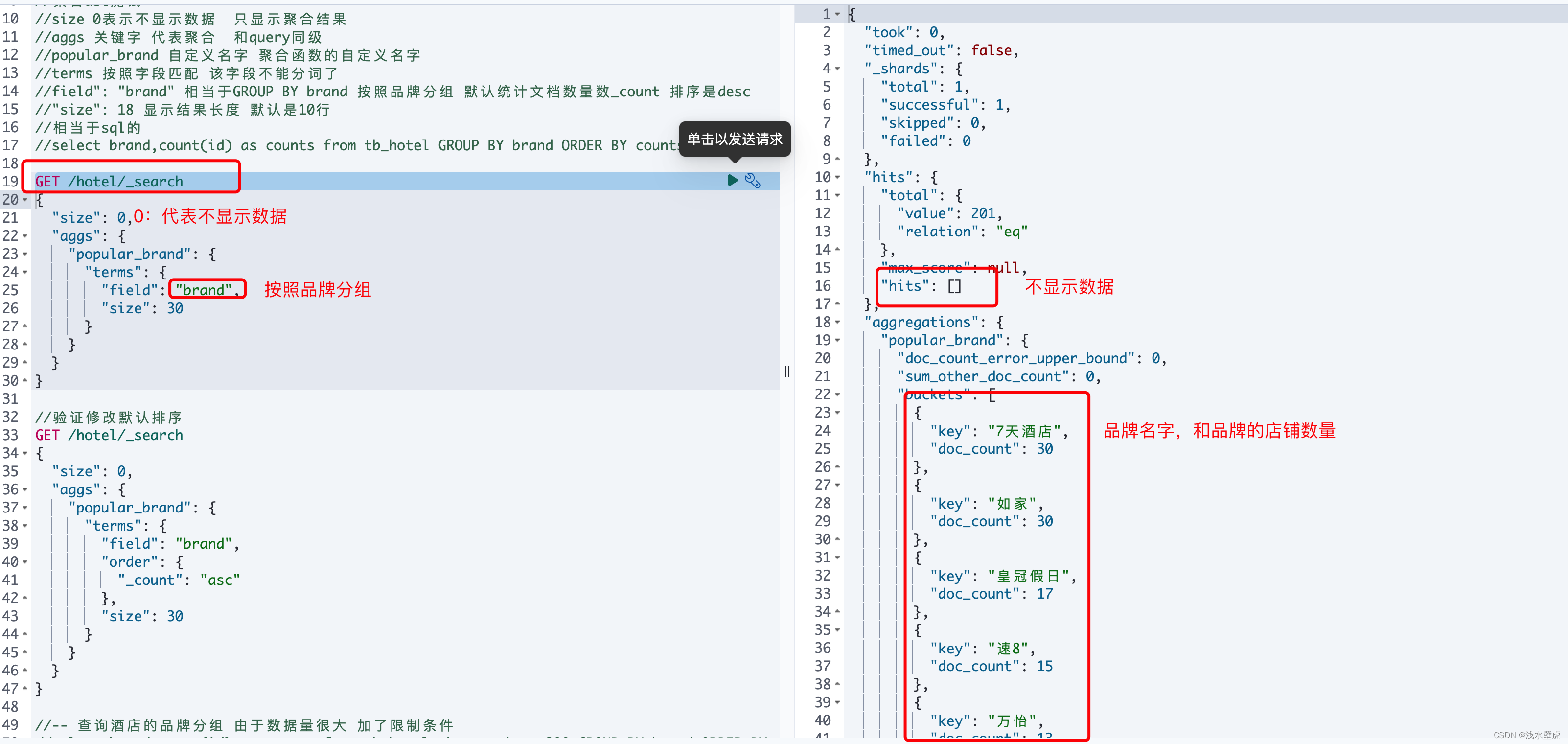
聚合函数DSL测试,桶语句测试,相当于group by
//聚合dsl测试
//size 0表示不显示数据 只显示聚合结果
//aggs 关键字 代表聚合 和query同级
//popular_brand 自定义名字 聚合函数的自定义名字
//terms 按照字段匹配 该字段不能分词了
//field": "brand" 相当于GROUP BY brand 按照品牌分组 默认统计文档数量数_count 排序是desc
//"size": 18 显示结果长度 默认是10行
//相当于sql的
//select brand,count(id) as counts from tb_hotel GROUP BY brand ORDER BY counts desc
GET /hotel/_search
{
"size": 0,
"aggs": {
"popular_brand": {
"terms": {
"field": "brand",
"size": 30
}
}
}
}
//验证修改默认排序
GET /hotel/_search
{
"size": 0,
"aggs": {
"popular_brand": {
"terms": {
"field": "brand",
"order": {
"_count": "asc"
},
"size": 30
}
}
}
}
//-- 查询酒店的品牌分组 由于数据量很大 加了限制条件
//select brand,count(id) as counts from tb_hotel where price<=200 GROUP BY brand ORDER BY counts desc
get /hotel/_search
{
"query":{
"range": {
"price": {
"gte": 0,
"lte": 200
}
}
},
"size": 0,
"aggs": {
"popular_brand": {
"terms": {
"field": "brand",
"order": {
"_count": "asc"
},
"size": 30
}
}
}
}
测试结果显示
2.2:DSL语句实现指标(Metrics)测试
聚合函数DSL测试,指标语句测试,相当于max()、vag()、min()
//嵌套聚合 指标(Metrics) 桶在概念上类似于 SQL 的分组(GROUP BY),而指标则类似于 COUNT() 、 SUM() 、 MAX() 等统计方法。
//测试聚合和指标(对桶内的文档进行统计计算)
//查询品牌的评分最大值、最小值、平均值
//select brand,count(id) as counts,max(score),min(score),avg(score) from tb_hotel GROUP BY brand ORDER BY avg(score) desc
//stats 相当于max(score),min(score),avg(score) 这三个函数
get /hotel/_search
{
"size":0,
"aggs":{
"brand_agg":{
"terms": {
"field": "brand",
"size": 20,
"order": {
"price_agg.avg": "desc"
}
},
"aggs": {
"price_agg": {
"stats": {
"field": "score"
}
}
}
}
}
}测试结果显示

2.3:java代码的桶和指标实现
@Autowired
ElasticsearchClient elasticsearchClient;
//查询酒店的品牌分组
//select brand,count(id) as counts from tb_hotel GROUP BY brand ORDER BY counts desc
@Test
void GROUP_BY_brand() throws IOException {
SearchRequest.Builder builder = new SearchRequest.Builder();
builder.index("hotel");
builder.size(0);//查询数据的条数 0代表不查询
builder.aggregations("popular_brand",agg->agg.terms(t->t
.field("brand")
.size(30)//查询分组的数据条数
));
SearchRequest searchRequest = builder.build();
SearchResponse<Void> search = elasticsearchClient.search(searchRequest, Void.class);
System.out.println(search);
//解析数据
Aggregate aggregate = search.aggregations().get("popular_brand");
StringTermsAggregate o = (StringTermsAggregate) aggregate._get();
Buckets<StringTermsBucket> buckets = o.buckets();
List<StringTermsBucket> array = buckets.array();
for (StringTermsBucket stringTermsBucket : array) {
System.out.println("结果集"+stringTermsBucket.key()._toJsonString()+":"+stringTermsBucket.docCount());
}
}
//查询全部数据 默认分页 查询10条数据
//查询酒店的品牌、城市、星级分组
//select brand,count(id) as counts from tb_hotel GROUP BY brand ORDER BY counts desc
//select city,count(id) as counts from tb_hotel GROUP BY city ORDER BY counts desc
//select starName,count(id) as counts from tb_hotel GROUP BY starName ORDER BY counts desc
@Test
void GROUP_BY_brand_city_startName() throws IOException {
SearchRequest.Builder builder = new SearchRequest.Builder();
builder.index("hotel");
//1:判断city是否为空
//构建BoolQuery
BoolQuery.Builder boolQuery = QueryBuilders.bool();
Query filter_city = MatchQuery.of(o -> o.field("city").query("上海"))._toQuery();
boolQuery.filter(filter_city);
BoolQuery build = boolQuery.build();
builder.query(b->b.bool(build));
builder.size(0);//查询数据的条数 0代表不查询
builder.aggregations("popular_brand",agg->agg.terms(t->t
.field("brand")
.size(30)//查询分组的数据条数 品牌分组
));
builder.aggregations("popular_city",agg->agg.terms(t->t
.field("city")
.size(30)//查询分组的数据条数 城市分组
));
builder.aggregations("popular_starName",agg->agg.terms(t->t
.field("starName")
.size(30)//查询分组的数据条数 星级分组
));
SearchRequest searchRequest = builder.build();
SearchResponse<Void> search = elasticsearchClient.search(searchRequest, Void.class);
System.out.println(search);
//解析品牌 三个方法一样 可以抽理出来
Aggregate aggregate = search.aggregations().get("popular_brand");
StringTermsAggregate o = (StringTermsAggregate) aggregate._get();
Buckets<StringTermsBucket> buckets = o.buckets();
List<StringTermsBucket> array = buckets.array();
for (StringTermsBucket stringTermsBucket : array) {
System.out.println("brand结果集("+stringTermsBucket.key()._toJsonString()+":"+stringTermsBucket.docCount());
}
System.out.println("=======分割线======");
//解析城市 三个方法一样 可以抽理出来
Aggregate city = search.aggregations().get("popular_city");
StringTermsAggregate o1 = (StringTermsAggregate) city._get();
Buckets<StringTermsBucket> buckets1 = o1.buckets();
List<StringTermsBucket> array1 = buckets1.array();
for (StringTermsBucket stringTermsBucket : array1) {
System.out.println("city结果集("+stringTermsBucket.key()._toJsonString()+":"+stringTermsBucket.docCount());
}
System.out.println("=======分割线======");
//解析星级 三个方法一样 可以抽理出来
Aggregate starName = search.aggregations().get("popular_starName");
StringTermsAggregate o2 = (StringTermsAggregate) starName._get();
Buckets<StringTermsBucket> buckets2 = o2.buckets();
List<StringTermsBucket> array2 = buckets2.array();
for (StringTermsBucket stringTermsBucket : array2) {
System.out.println("starName结果集("+stringTermsBucket.key()._toJsonString()+":"+stringTermsBucket.docCount());
}
}
3:拼音分词器自动补全
我们在使用电视的时候,搜用电影,往往只需要输入电影名称的简写首字母,就能自动补全匹配的电影,或者在百度搜索的时候,输入关键字,自动联想出来内容,这就搜索引擎的自动补全功能
3.1:拼音分词器安装
拼音分词器地址
GitHub - infinilabs/analysis-pinyin: 🛵 This Pinyin Analysis plugin is used to do conversion between Chinese characters and Pinyin.
下载完对应的版本之后解压,放到es的插件目录下边![]()
3.2:拼音分词器验证效果
//测试分词器 使用ik分词器 按照名次划分 如家、酒店、很不错
POST /_analyze
{
"text":"如家酒店很不错",
"analyzer":"ik_max_word"
}
//使用拼音分词器 每一个字都会分词 不是理想效果 应该按照关键字匹配
//ru jia jiu dian hen bu cuo rjjdhbc
POST /_analyze
{
"text":"如家酒店很不错",
"analyzer":"pinyin" //使用拼音分词器
}
//使用拼音分词器 liu de hua ldh
POST /_analyze
{
"text":"刘德华",
"analyzer":"pinyin"
}效果截图:

3.2: 创建索引设置拼音分词器、并且验证测试
//创建一个索引库 设置分词器
PUT /test
{
"settings" : {
"analysis" : {
"analyzer" : { //自定义分词器
"my_analyzer" : { //分词器名称自定义名字
"tokenizer" : "ik_max_word",//先把字符串ik分词
"filter":"py" //然后只用拼音分词器分词
}
},
"filter": { //自定filter 然后再把分词好的名次 按照拼音分词
"py" : { //对应前边的名字
"type" : "pinyin",
"keep_full_pinyin" : false,
"keep_joined_full_pinyin" : true,
"keep_original" : true,
"limit_first_letter_length" : 16,
"lowercase" : true,
"remove_duplicated_term" : true
}
}
}
},
"mappings": {
"properties": {
"name":{ //只有一个字段
"type": "text", //字段类型是text
"analyzer": "my_analyzer",//分词使用my_analyzer
"search_analyzer": "ik_smart" //查询不分词
}
}
}
}
//插入数据
//索引库添加数据
PUT /test/_doc/1
{
"id":1,
"name":"狮子"
}
PUT /test/_doc/2
{
"id":2,
"name":"虱子"
}
PUT /test/_doc/3
{
"id":3,
"name":"小米手机充电器"
}
测试1:DSL语句、然后我们来验证自己创建索引设置的拼音分词器
//使用my_analyzer 分词器 小米、手机、充电器、xiaomi、xm、shouji、sj、chongdianqi、cdq
POST /test/_analyze
{
"text":"小米手机充电器",
"analyzer":"my_analyzer"
}
//使用my_analyzer 分词器 虱子、shizi、sz
POST /test/_analyze
{
"text":"虱子",
"analyzer":"my_analyzer"
}测试1结果如下:自定义的pinyin分词器,先对text适应ik分词器分词、然后使用拼音分词器进行了拼音分词

测试2:DLS语句,用拼音简写、全拼、汉字来搜索测试
//查询全部数据
get /test/_search
{
"query":{
"match_all": {}
}
}
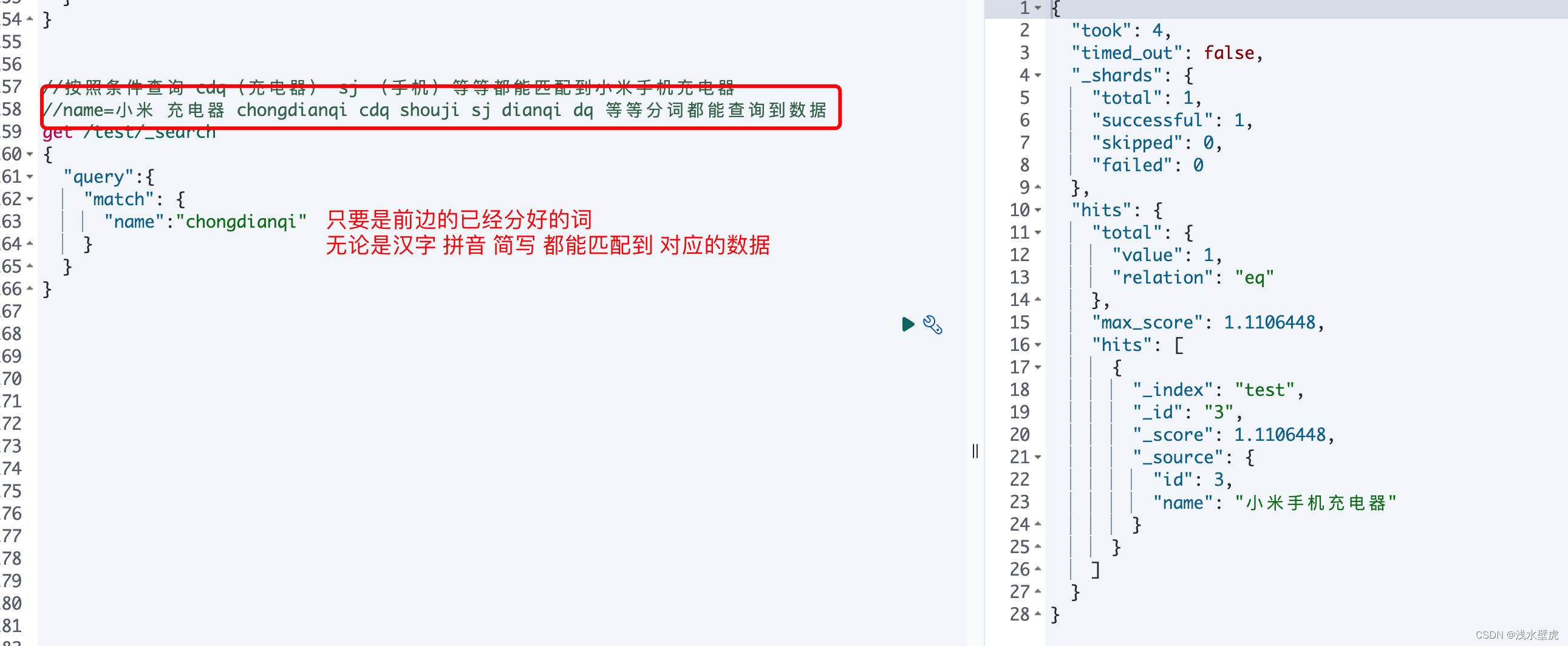
//按照条件查询 cdq(充电器) sj (手机)等等都能匹配到小米手机充电器
get /test/_search
{
"query":{
"match": {
"name":"cdq"
}
}
}
//填写 shizi sz 虱子 都能查到数据 但是只填写s查不到数据
get /test/_search
{
"query":{
"match": {
"name":"shizi"
}
}
}
get /test/_search
{
"query":{
"match": {
"name":"虱子"
}
}
}
get /test/_search
{
"query":{
"match": {
"name":"掉进狮子笼了怎么办"
}
}
}
测试2:测试结果如下
3.3:拼音分词器的自定补全
在3.2中详细的测试的拼音分词器,但是呢?这里有个问题,比如搜索的时候,只填写了一个汉字的首字母,就查询不到数据了,进行了分词
比如只填写首字母

所以呢?创建自动补全,字段的属性必须是必须是completion,并且是数组
//自动补全测试 创建索引test2 字段属性必须是completion 并且是多词条的数组
PUT /test2
{
"mappings": {
"properties": {
"title":{
"type": "completion"
}
}
}
}
//索引库添加数据
POST /test2/_doc
{
"title":["SONY","WH-1000XM3"]
}
POST /test2/_doc
{
"title":["SKII","PITERA"]
}
POST /test2/_doc
{
"title":["Nintendo","switch"]
}
//查询全部
get /test2/_search
{
"query":{
"match_all": {
}
}
}
//自定补全查询
get /test2/_search
{
"suggest":{
"title_suggest":{
"text":"sw",
"completion":{
"field":"title",
"skip_duplicates": true, // 跳过重复的
"size": 10 // 获取前10条结果
}
}
}
}
自定补全测试结果

4:酒店信息自动补全
4.1:创建酒店的是索引库、分词器的DSL
//酒店数据自动补全
get /hotel/_mapping
DELETE /hotel
put /hotel
{
"settings" : {
"analysis" : {
"analyzer" : {
"text_analyzer" : { //自定义分词器 分词器text_analyzer
"tokenizer" : "ik_max_word",//分词
"filter":"py"
},
"completion_analyzer" : { //自定义分词器 分词器completion_analyzer
"tokenizer" : "keyword",//keyword不分词 ik_max_word分词
"filter":"py"
}
},
"filter": { //自定filter
"py" : { //对应前边的名字
"type" : "pinyin",
"keep_full_pinyin" : false,
"keep_joined_full_pinyin" : true,
"keep_original" : true,
"limit_first_letter_length" : 16,
"remove_duplicated_term" : true,
"none_chinese_pinyin_tokenize":false
}
}
}
},
"mappings":{
"properties":{
"id":{
"type": "keyword"
},
"name":{
"type": "text",
"analyzer":"text_analyzer",//创建索引 使用text_analyzer
"search_analyzer": "ik_smart",//搜索使用ik——分词器
"copy_to":"all"
},
"address":{
"type": "keyword",
"index": false
},
"price":{
"type": "integer"
},
"score":{
"type": "integer"
},
"brand":{
"type": "keyword",
"copy_to":"all"
},
"city":{
"type": "keyword"
},
"starName":{
"type": "keyword"
},
"business":{
"type": "keyword",
"copy_to":"all"
},
"location":{
"type": "geo_point"
},
"pic":{
"type": "keyword",
"index": false
},
"all":{
"type": "text",
"analyzer":"text_analyzer",//创建索引 使用text_analyzer
"search_analyzer": "ik_smart"//搜索使用ik——分词器
},
"suggest":{
//添加一个suggest 字段用来自动补全 属性必须是completion
//该字段是品牌 商圈组成的数组
"type":"completion",
"analyzer":"completion_analyzer"//创建索引 使用text_analyzer
}
}
}
}
#获取索引数据
get /hotel
#删除索引
delete /hotel
get /hotel/_mapping
GET /hotel/_search
{
"query":{
"match_all": {}
},
"size": 100
}
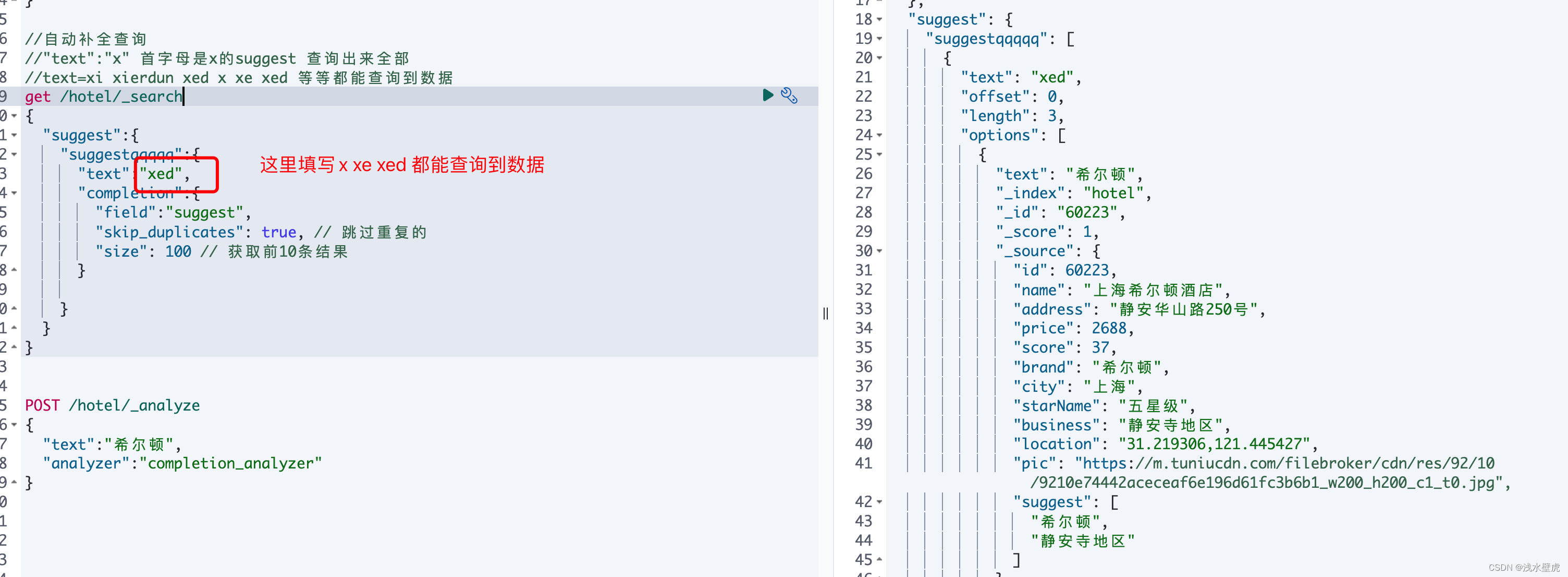
//自动补全查询
get /hotel/_search
{
"suggest":{
"suggestqqqqq":{
"text":"x",
"completion":{
"field":"suggest",
"skip_duplicates": true, // 跳过重复的
"size": 100 // 获取前10条结果
}
}
}
}
POST /hotel/_analyze
{
"text":"希尔顿",
"analyzer":"completion_analyzer"
}
4.2: mysql的数据插入ES
@Data
@NoArgsConstructor
public class TbHotelDoc implements Serializable {
/**
* 酒店id
*/
private Long id;
/**
* 酒店名称
*/
private String name;
/**
* 酒店地址
*/
private String address;
/**
* 酒店价格
*/
private Integer price;
/**
* 酒店评分
*/
private Integer score;
/**
* 酒店品牌
*/
private String brand;
/**
* 所在城市
*/
private String city;
/**
* 酒店星级,1星到5星,1钻到5钻
*/
private String starName;
/**
* 商圈
*/
private String business;
/**
* 纬度,经度 但是es中是
* "location": {
* "type": "geo_point"
* },
*/
private String location;
/**
* 酒店图片
*/
private String pic;
/**
* 距离字段
*/
private Double juli;
/**
* 是否有广告
*/
private Boolean isAD;
/**
* 分词词条
*/
private List<String> suggest;
public TbHotelDoc(TbHotel hotel) {
this.id = hotel.getId();
this.name = hotel.getName();
this.address = hotel.getAddress();
this.price = hotel.getPrice();
this.score = hotel.getScore();
this.brand = hotel.getBrand();
this.city = hotel.getCity();
this.starName = hotel.getStarName();
this.business = hotel.getBusiness();
this.location = hotel.getLatitude()+","+hotel.getLongitude();
this.pic = hotel.getPic();
//将品牌 商圈 放入索引库的suggest 在ES中suggest是个数组
if (this.business.contains("/")){
String[] split = this.business.split("/");
this.suggest=new ArrayList<>();
this.suggest.add(this.brand);
Collections.addAll(this.suggest,split);
}else if (this.business.contains("、")){
String[] split = this.business.split("、");
this.suggest=new ArrayList<>();
this.suggest.add(this.brand);
Collections.addAll(this.suggest,split);
}
else {
this.suggest= Arrays.asList(this.brand,this.business);
}
}
}mysql数据代码插入ES:
//mysql批量添加数据到ES BulkRequest
@Test
void addAllDocument() throws IOException {
//查询所有数据
List<TbHotel> list = tbHotelService.list();
System.out.println("list:"+list.size());
//将数据添加到ES中
BulkRequest.Builder builder = new BulkRequest.Builder();
for (TbHotel hotel : list) {
TbHotelDoc hotelDoc=new TbHotelDoc(hotel);
builder.operations(op->op.index(
idx->idx.index("hotel")
.id(hotelDoc.getId().toString())
.document(hotelDoc)
));
}
elasticsearchClient.bulk(builder.refresh(Refresh.WaitFor).build());
}
4.3:查询数据

4.5:Java 查询验证代码
@Autowired
ElasticsearchClient elasticsearchClient;
//查询酒店的品牌分组
//select brand,count(id) as counts from tb_hotel GROUP BY brand ORDER BY counts desc
@Test
void 自动补全() throws IOException {
SearchRequest.Builder builder = new SearchRequest.Builder();
builder.index("hotel");
builder.size(0);//查询数据的条数 0代表不查询
builder.suggest(suggest -> suggest.suggesters("suggests",
b -> b.prefix("x") //前置字段 用来搜索
.completion(c -> c
.field("suggest")//表中的字段
.skipDuplicates(true)
.size(100)
)
));
SearchRequest searchRequest = builder.build();
SearchResponse<TbHotelDoc> search = elasticsearchClient.search(searchRequest,TbHotelDoc.class);
System.out.println(search);
//获取suggest 是一个map
Map<String, List<Suggestion<TbHotelDoc>>> suggest = search.suggest();
//获取自定义的表字段 对应上边的表字段suggest
List<Suggestion<TbHotelDoc>> suggests = suggest.get("suggests");
Suggestion<TbHotelDoc> tbHotelDocSuggestion = suggests.get(0);
//获取options
List<CompletionSuggestOption<TbHotelDoc>> options = tbHotelDocSuggestion.completion().options();
//解析获取匹配的text
for (CompletionSuggestOption<TbHotelDoc> option : options) {
String text = option.text();
System.out.println("提示的词条====:"+text);
// System.out.println(option);
}
}
4.6:自定补全原理

那么查询的时候按照分词规范,支持自动补全