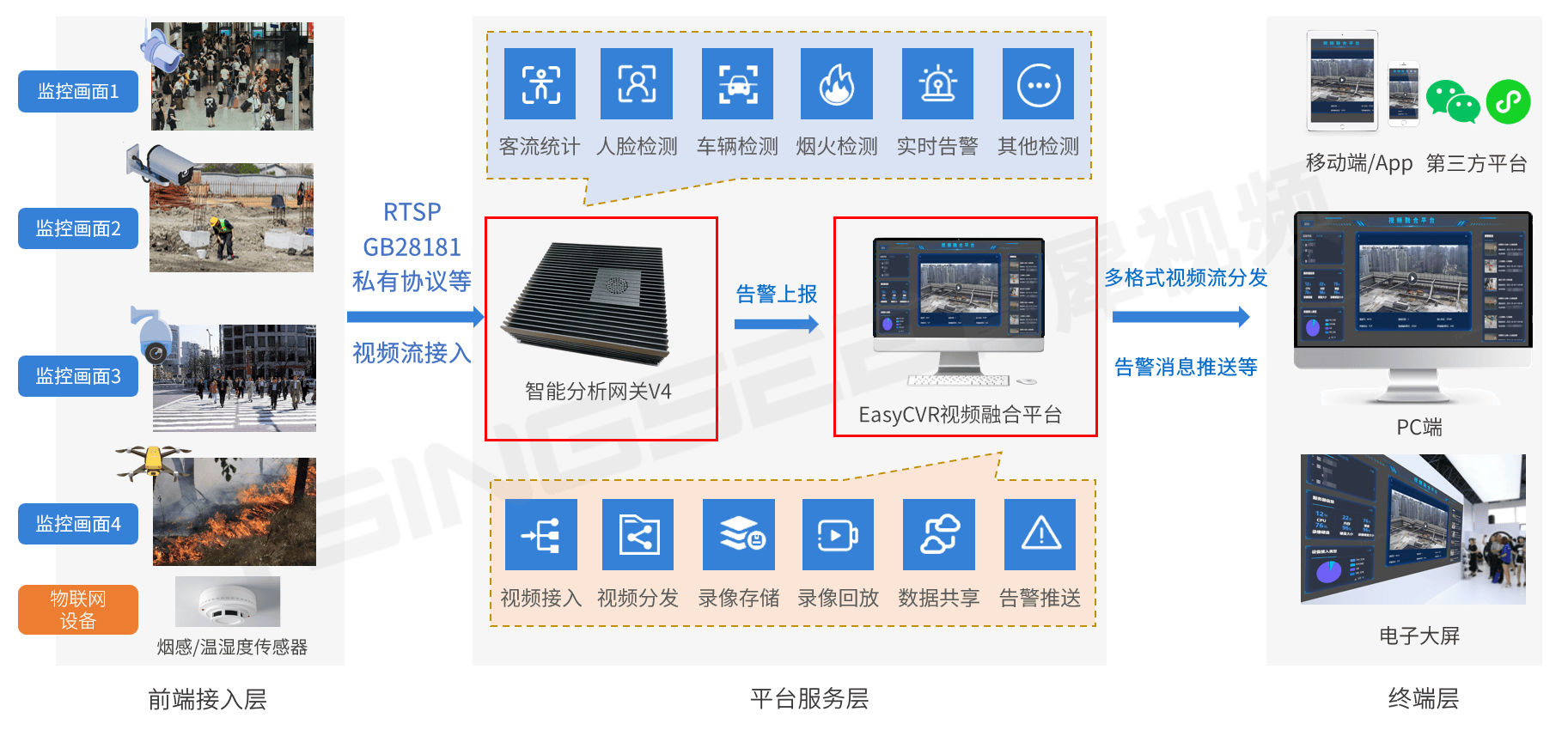
视频汇聚/安防视频监控云平台EasyCVR支持多协议接入、可分发多格式的视频流,平台支持高清视频的接入、管理、共享,支持7*24小时不间断监控。视频监控管理平台EasyCVR可提供实时远程视频监控、录像、回放与存储、告警、语音对讲、云台控制、平台级联、磁盘阵列存储、视频集中存储、云存储等丰富的视频能力,并具备权限管理、设备管理、鉴权管理、流媒体接入与转发、系统运维等管理能力。
今天我们来介绍下安防监控/视频汇聚EasyCVR平台云端录像播放及下载的接口调用方法。
视频监控/智能分析/视频分析EasyCVR平台不仅支持本地自定义录像计划,也支持提供云端录像播放及下载接口,接口文档如下:


1)云端录像播放接口:
http://ip:端口/api/v1/record/recordvideo/play/mp4/7/20240410102038/
20240410102150?token=

2)云端录像下载接口:
http://ip:端口/api/v1/record/recordvideo/download/mp4/7/
20240410102038/20240410102150?token=
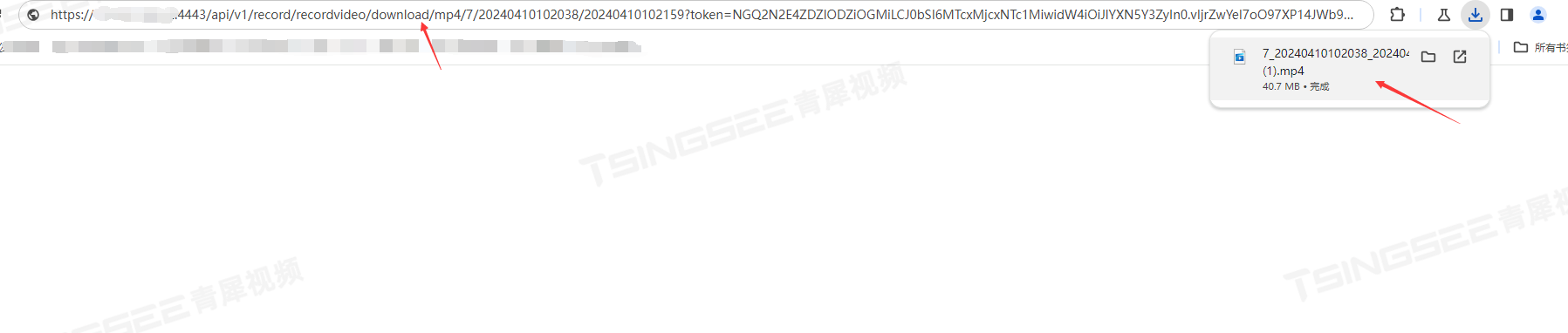
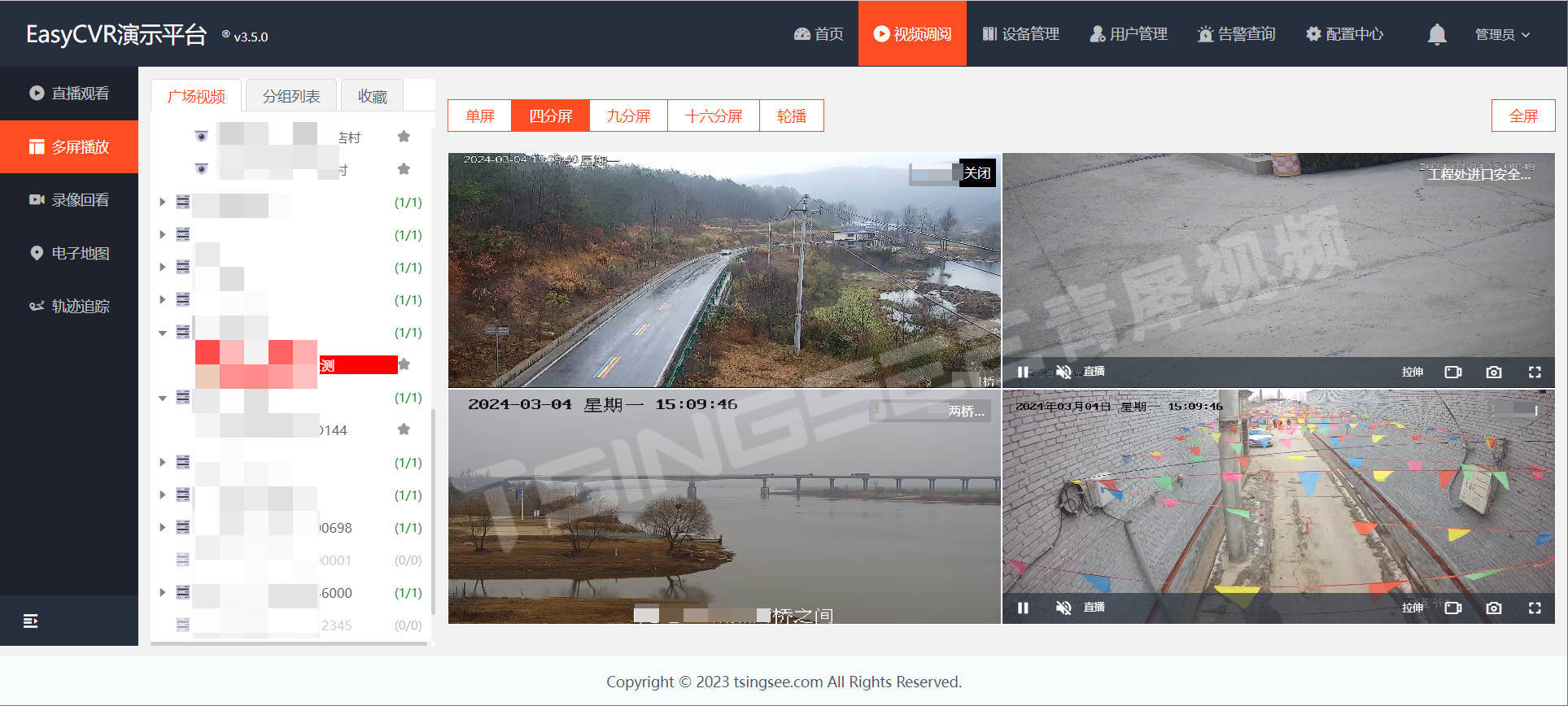
通过以上接口可以调用云端录像进行播放和下载。视频监控汇聚平台EasyCVR平台可拓展性强、视频能力灵活,具备传统安防视频监控的能力,也具备接入AI智能分析的能力,包括对人、车、物、行为等事件的智能追踪与识别分析、抓拍、比对、告警上报、语音提醒等。感兴趣的用户可以前往演示平台进行体验或部署测试。










