【C++】狗屁不通文章生成器2.0
1 前言
继上次【C++】狗屁不通文章生成器之后,很久不想看一眼这个代码,因为当时写这个代码深受中文字符的处理烦恼。而且现在回看,程序的模块化、可读性使我大受震惊,是在想不到当时的我为什么要这样做。于是昨天无心工作,想到了把这堆乐色改进一下,至少做到能看的水平。遂记之。
2 改进
2.1 字词的前后关系
为了表示字词的前后关系,即将句子划分为前缀词+后缀词的关系,依然需要定义一个class wordpair,这里去除一些数据上的冗余,强化了类的封闭性。
class wordpair
{
private:
string preword; // 前缀
map<string, int> sufwords; // 后缀,次数
int count; // 总次数
public:
wordpair(string pre);
wordpair(string pre, string suf);
wordpair(string pre, map<string, int> suf);
~wordpair();
string getPreword() const;
map<string, int> getSufwords() const;
void setPreword(string pre);
void setSufwords(map<string, int> suf);
string toJson() const;
void addSufword(string suf);
string chooseSufword() const;
};
采用map记录后缀的出现次数,数据的结构性更强,也易于查找。记录所有后缀出现的总次数是为了在生成文章时选择后缀提供方便(具体作用看3.1.3)
2.2 文章生成系统
将太多的操作塞进main()函数的做法不够美观,且容易忘记各个部分的功能。于是这里将文章生成的功能抽象出来,作为一个类。主要的工作是记录所有的字词对、记录生成的、文件流操作、文章生成等逻辑。
class createArticle
{
private:
vector<wordpair> wordpairlist;
string article;
public:
createArticle();
~createArticle();
void importWords(string filename, int len_pre = 1, int len_suf = 1);
void exportWords(string filename);
void addWordPair(string pre, string suf);
void generateArticle(string startword, int lenout = 10000);
void printArticle(string filename);
};
3 实现(部分)
由于大多函数都很简单,这里只贴出部分比较重要的函数。
3.1 class wordpair
除去构造函数、类成员输出输入等函数,我们直接进入主题。
3.1.1 转化为 json
这个函数主要是为了输出格式化的词对,而文本文件中json格式的结构性且简单。
ps: 其实这个函数不太重要,主要目的是检查。不过也可以为直接读词对做准备(虽然这里没有从文件导入词对的功能)
string wordpair::toJson() const
{
string str = "\"";
str += this->preword + "\" : {";
for (auto &it : this->sufwords)
{
str += "\"" + it.first + "\"" + ":" + to_string(it.second) + ",";
}
str += "}";
return str;
}
效果演示:
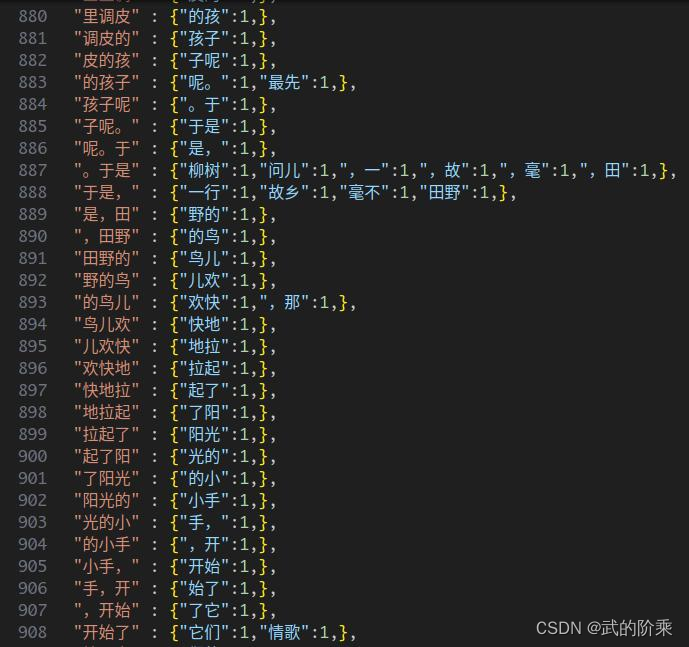
3.1.2 添加后缀词
添加后缀的函数,逻辑是:
- if 这个后缀已经有记录 then
count++; - else 添加新的后缀到
map中
void wordpair::addSufword(string suf)
{
for (auto &it : this->sufwords)
{
if (it.first == suf)
{
it.second++;
return;
}
}
this->sufwords[suf] = 1; // if the word is not in the map, add it with a count of 1
}
3.1.3 选择后缀词
这个函数的主要功能是从众多后缀词中选取一个(语料库大的话就会多啦),选择的策略是随机数的方案,类似于转盘抽奖。实现方法如下:
string wordpair::chooseSufword() const
{
if (this->sufwords.size() == 1)//如果只有一个后缀词就直接输出,减少算力负担
{
return this->sufwords.begin()->first;
}
else
{
// 随机选择一个后缀词
random_device rd;
ranlux48 engine(rd());
uniform_int_distribution<> dist(0, this->count);//在类中定义了count,这里就省掉了遍历
int random_number = dist(engine);//产生一个随机数
std::string result;
for (auto &it : this->sufwords)//抽奖
{
if (random_number < it.second)
{
result = it.first;
}
else
random_number -= it.second;
}
return result;
}
}
3.2 class createArticle
3.2.1文本分割
vector<string> charlist = splitchar(filestr);//先将从文件读到的字符串分割
string preword = "", sufword = "";
for (int i = 0; i < charlist.size() - len_suf - len_pre; i++)//每次向后移动一个字符,进行切割
{
preword = "", sufword = "";
for (int j = i; j < i + len_pre + len_suf; j++)
{
if (j - i < len_pre)
{
preword += charlist[j];//从第i个字符开始,到第i+len_pre个字符连接起来作为前缀
}
else
{
sufword += charlist[j];//从第i+len_pre个到字符开始,到第i+len_pre+len_suf个字符连接作后缀
}
}
this->addWordPair(preword, sufword);//添加进wordpairlist
}
3.2.2生成文章
/*
startword——启动词
lenout——长度限制(避免无限循环)
*/
void createArticle::generateArticle(string startword, int lenout)
{
this->article += startword;
bool stop; // 加一个停止标志,当无法匹配到前缀时停止
int prewordlen = this->wordpairlist.front().getPreword().length();
int sufwordlen = this->wordpairlist.front().getSufwords().begin()->first.length();
string lastword;
for (int i = 0; i < lenout; ++i)
{
stop = true;
if (this->article.length() >= prewordlen) // 如果文章长度大于词对中前缀词的长度,则直接拼接
{
lastword = this->article.substr(this->article.length() - prewordlen, prewordlen);//article最后的len_pre个字符,作为前缀
for (auto &it : this->wordpairlist)
{
if (it.getPreword() == lastword)//通过lastword匹配词对
{
this->article += it.chooseSufword();
stop = false;
break;
}
}
if (stop)//遍历了一边词对的list没有匹配的词对时,退出循环
break;
}
else//启动词长度小于词对前缀的情况,例如词对分割为3+2时,启动词长度为2,小于前缀长度3,无法正常拼接,于是走此处
{
lastword = this->article;
for (auto &it : this->wordpairlist)//同上遍历
{
int position = it.getPreword().find(lastword);
if (position != string::npos)
{
this->article += (it.getPreword() + it.chooseSufword()).substr(position+lastword.length(), sufwordlen);//先将前后缀连接,再从匹配到的位置开始截取
stop = false;
break;
}
}
if (stop)
break;
}
}
}
4演示
4.1 wordpair(3x2), 启动词(春天)

4.2 wordpair(2x1),启动词(春天)

4.3 wordpair(2x2),启动词(春天)
 可见,加了长度限制的重要性。
可见,加了长度限制的重要性。
5总结
目前,这个版本的处理方法不会出现中文乱码,即使是中英文混合字符串也能正确读取和分割。而且拼接时采用的随机数策略,在语料库足够大的情况下可以有较好的灵活性。但是任然无法产出具备可读性的文章。









