
论文题目:Knowledge Graphs Meet Multi-Modal Learning: A Comprehensive Survey
论文链接:http://arxiv.org/abs/2402.05391
项目地址:https://github.com/zjukg/KG-MM-Survey
备注:54 pages, 617 citations, 11 Tables, 13 Figures
机构:浙江大学,东南大学,牛津大学,爱丁堡大学,曼彻斯特大学,普渡大学引言
在该综述中,作者重点分析了近三年(2020-2023)超过300篇文章,聚焦于两个主要方向:一是知识图谱驱动的多模态学习(KG4MM),探讨知识图谱如何支持多模态任务;二是多模态知识图谱(MM4KG),研究如何将知识图谱扩展到多模态知识图谱领域。作者从定义KGs和MMKGs的基本概念入手,继而探讨它们的构建和演化,涵盖知识图谱感知的多模态学习任务(如图像分类、视觉问答)及固有的MMKG构建内部任务(如多模态知识图谱补全、实体对齐)。本文还强调了研究重点,提供了任务定义、评估基准,并概述了基本见解。通过讨论当前面临的挑战和评估新兴研究趋势,如大型语言模型和多模态预训练策略的进展,本调研旨在为KG与多模态学习领域的研究人员提供一个全面的参考框架,以及对该领域不断演进的洞察,从而支持未来的工作。

Task

KG驱动的多模态(KG4MM)学习 (KG-driven Multi-modal Learning)
理解与推理任务 (Understanding & Reasoning Tasks)

KG4MMR
视觉问答 (Visual Question Answering)

VQA
视觉问题生成 (Visual Question Generation)
视觉对话 (Visual Dialog)
分类任务 (Classification Tasks)
图像分类 (Image Classification)

IMGC

假新闻检测 (Fake News Detection)
电影类型分类 (Movie Genre Classification)
内容生成任务 (Content Generation Tasks)

图像注释 (Image Captioning)
视觉故事讲述 (Visual Storytelling)
条件文本到图像生成 (Conditional Text-to-Image Generation)
场景图生成 (Scene Graph Generation)
检索任务 (Retrieval Tasks)

跨模态检索 (Cross-Modal Retrieval)
视觉指代表达与定位 (Visual Referring Expressions & Grounding)
知识图谱感知的多模态预训练 (KG-aware Multi-modal Pre-training)
结构知识感知预训练 (Structure Knowledge aware Pre-training)
知识图谱感知预训练 (Knowledge Graph aware Pre-training)
多模态知识图谱(MM4KG) (Multi-modal Knowledge Graphs)

MMKGOnto
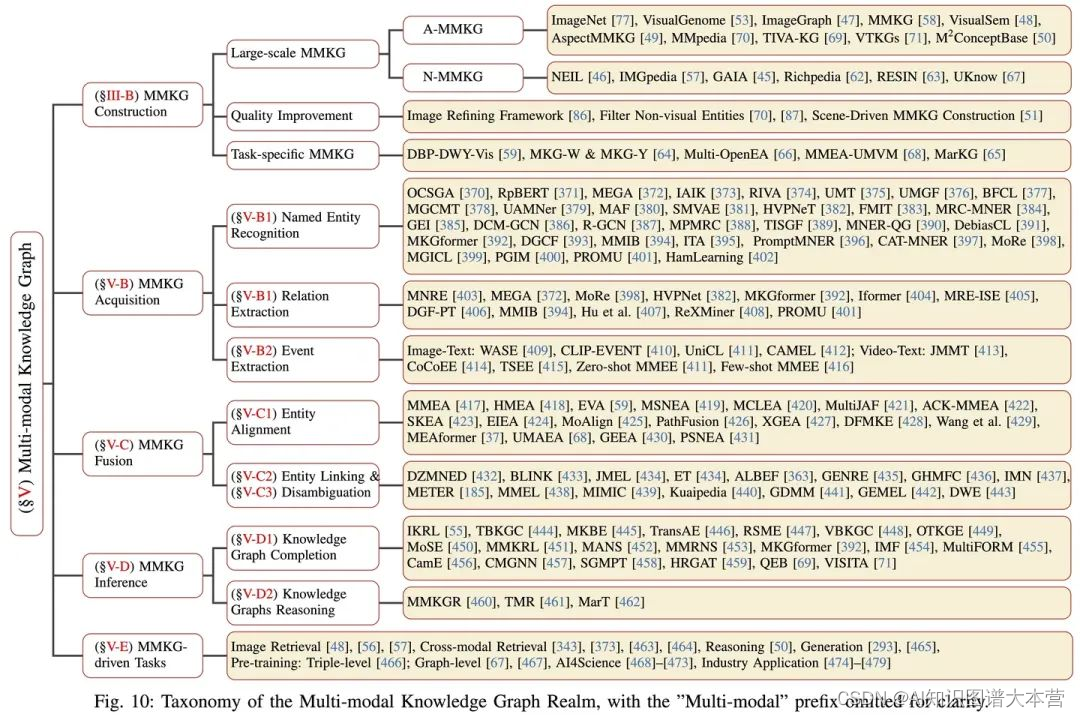
MMKG资源 (MMKG Resources)
公开的MMKGs (Public MMKGs)

MMKG
MMKG构建方法 (MMKG Construction Methods)
MMKG获取 (MMKG Acquisition)

多模态命名实体识别 (Multi-modal Named Entity Recognition)

多模态关系抽取 (Multi-modal Relation Extraction)

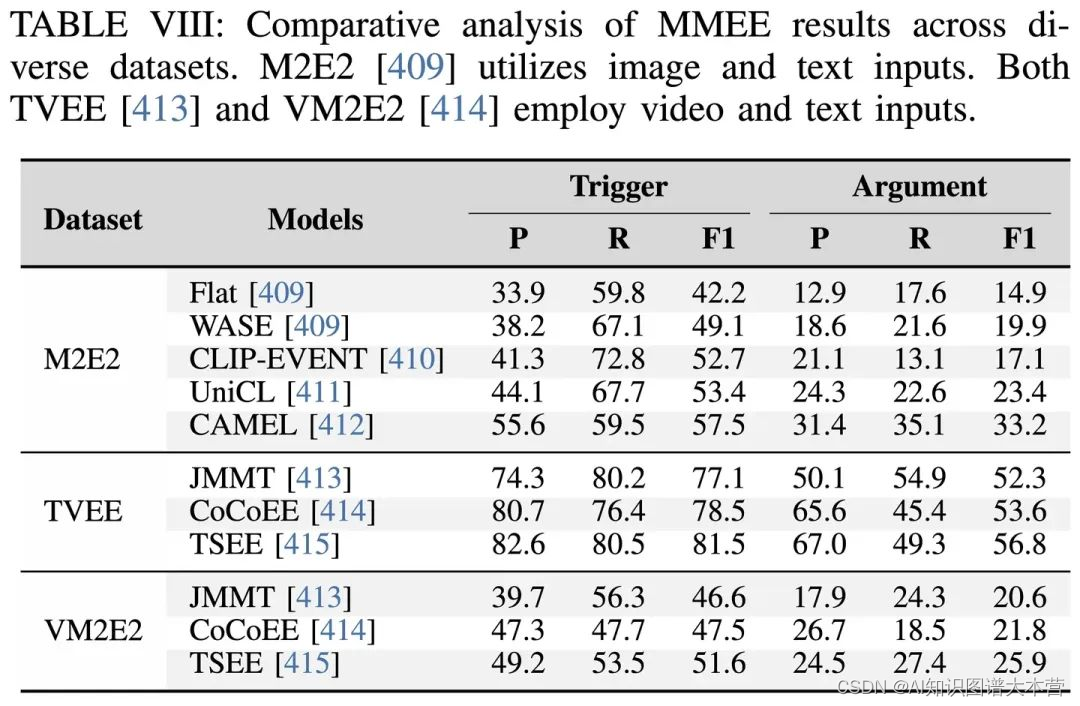
多模态事件抽取 (Multi-modal Event Extraction)
MMKG融合 (MMKG Fusion)
多模态实体对齐 (Multi-modal Entity Alignment)

多模态实体链接与消歧 (Multi-modal Entity Linking & Disambiguation)

MMKG推理 (MMKG Inference)
多模态知识图谱补全 (Multi-modal Knowledge Graph Completion)

多模态知识图谱推理 (Multi-modal Knowledge Graphs Reasoning)
MMKG驱动的任务 (MMKG-driven Tasks)

检索 (Retrieval)
预训练 (Pre-training)
科学交叉领域的AI应用(AI for Science)
行业应用 (Industry Application)
挑战与机遇 (Challenges and Opportunities)
MMKG构建与获取 (MMKG Construction & Acquisition)
MMKG和KG的目标是缓解各种任务中长尾知识的稀缺性,反映了现实世界中频繁共现和人类经验的模式。当前的研究基于一个乐观的假设,即一个无限扩展的MMKG可以包含几乎完整的相关世界知识谱系,提供解决所有多模态挑战所需的必要信息。然而关键问题始终存在:我们如何获得理想的多模态知识?理想的MMKG应具备哪些特征,它是否能准确反映人类大脑对世界知识的高级理解?此外,与LLM的知识能力相比,MMKG是否提供了独一无二、不可替代的好处?探索这些问题对于继续探索这一领域至关重要
(1) MMKG构建目前主要涉及两种范式:用KG符号注释图像或将KG符号固定到图像上。将从多个图像中局部提取的三元组与大规模KG对齐可以看作是上述二者的混合。这种混合方法的优势是双重的:它扩大了图像数量的覆盖范围(第一种范式),还融入了第二种范式特有的广泛知识规模,这可以促进大规模、三元组级别的多模态信息生成,为未来在多模态实体对齐和MMKG驱动的应用(如MLLM预训练和VQA)提供新的机遇。
(2) 在MMKG中特征精细化和对细粒度知识齐至关重要。理想的MMKG应该是层次化的,这样的结构允许自动分解大规模跨模态数据成为MMKG,使单个图像能够对齐多个概念。此外,语义分割代表了更高级的要求。随着像Segment Anything 这样的技术成熟,类似方法可以显著减少视觉模态中背景噪声的影响。因此,向视觉特征语义分割、层次化和多粒度MMKG演进是一个重要的未来方向。
(3) 在视觉模态中,我们认为抽象概念应对应于抽象的视觉表示,而具体概念应与特定视觉对齐。例如,像猫和狗这样的一般概念在大脑中表现为通用的、平均的视觉动物图像,而特定的限定词,如“阿拉斯加雪橇犬”,提供了清晰度,类似于MMKG中的基于路径的图像检索。此外,我们还认为每个概念,无论是否可视化,都可以与某些模态表示相关联。例如,抽象概念“心智”可能会唤起“大脑”或“人类思考”的图像,这显示出MMKG中表示不可视化概念的能力。有趣的是,在人类认知中,像“独角兽”这样的罕见概念往往被描绘得更加清晰。如果我们只知道独角兽是有角的马,这个特定的图像在脑海中就是我们记住的那样,而不是有角的海豹或狮子。这反映了MMKG数据结构:图像较少的视觉概念被更加鲜明地表示,而图像较多的概念倾向于被概括且更模糊,除非给定限定。
(4) MMKG存储和利用的效率仍然是一个关注点。尽管传统的KG比较轻量并且以最小的参数存储大量知识,MMKG却需要更多空间,这对高效数据存储和跨任务应用提出挑战。
(5) MMKG中的质量控制具有独特的挑战,如多模态(如视觉)内容中的错误、缺失或过时图像。现有MMKG中图像和文本之间有限的细粒度对齐和自动MMKG构建方法的噪声,需要开发基于模态信息质量打分的质量控制技术。鉴于世界知识的动态性,定期更新MMKG至关重要。
KG4MM任务 (KG4MM Tasks)
多模态内容生成 (Multi-modal Content Generation)
多模态任务集成 (Multi-modal Task Integration)
扩展MMKG以适应多模态任务的挑战 (Challenges in Scaling MMKG for Multi-modal Tasks)
释放大规模MMKG在多模态任务中的潜力 (Unlocking the Potential of Large-Scale MMKGs for Multi-Modal Tasks.)
MM4KG任务 (MM4KG Tasks)
MMKG融合 (MMKG Fusion)
MMKG推理 (MMKG Inference)
将多模态任务转化为MMKG范式 (Transfer Multi-modal Task into MMKG Paradigm)
应用多模态任务进行MMKG内任务增强 (Apply Multi-modal Task for In-MMKG Task Augmentation)
大型语言模型 (Large Language Models)
大模型微调 (Fine-Tuning)
大模型幻觉 (Hallucination)
大模型智能体(Agent)
大模型检索增强生成(Retrieval Augmented Generation (RAG))
大模型编辑 (Editing)
大模型偏好对齐 (Alignment)
MMKG精炼 (MMKG Refinement)
MMKG MoE
参考文献:
[1] Knowledge Graphs Meet Multi-Modal Learning: A Comprehensive Survey. (http://arxiv.org/abs/2402.05391) [2] https://github.com/zjukg/KG-MM-Survey










