一、概述
// 主要见讲义第1-4页
1.1、应用场景
-
缓冲/消峰:有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
-
**解耦:**允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。【就是可以暂存数据在消息队列中,消费者需要什么数据就取什么,不需要点对点的建立多条生产者-消费者通讯】
-
异步通信:允许用户把一个消息放入队列,但并不立即处理它,然后在需要的时候再去处理它们。
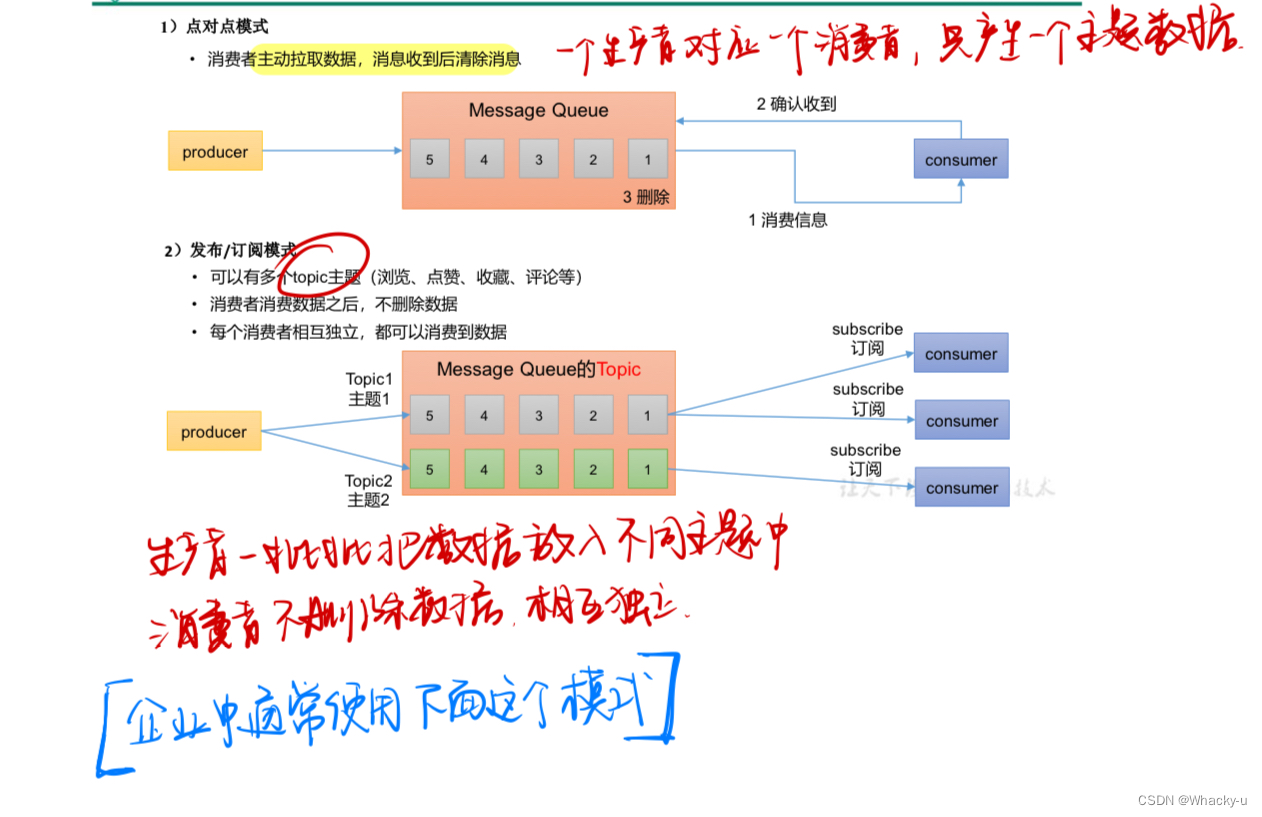
1.2、消息队列的两种模式
1.3、基础架构
- 分区
- 消费者组
- 副本
- 用到zk。也可以不用zk,就是kraft模式
- 生产者和消费者只针对leader操作【leader是主题在存储时候,副本才有的概念】

二、部署和配置
我们此次,在三台机器上都安装了kafka
//主要看讲义的第5-7页
- 先解压tar.gz (tgz后缀) 安装包
- 进入config修改配置文件。主要修改server.properties
- 修改broker.id 每台机器都要不一样!!!!!!注意
- 修改log.dir,默认是inux下的tmp临时路径,会被定期删除,我们更改成自己的路径
- 修改zookeeper.connect,需要用自己的主机地址,默认端口是2181,zookeeper提供客户端访问的端口。我们需要在最后再加上/kafka,因为zookeeper是目录树结构,如果不加这个文件夹,他会把收到的信息打散到zookeeper中
- 分发安装包。修改每台机器中server.properties的broker.id
- 配置环境变量
- source一下环境变量
- 先启动zookeeper,再启动kafka集群

三、Kafka命令行操作
但是上面三个都需要声明连接的kafka broker主机名,和端口号。:
-- bootstrap-server hadoop102:9092
//这里就是举了一个例子,连接的是kafka集群中hadoop102的broker
3.1、topic命令行操作
// 见讲义的第8-9页
3.2、生产者命令行操作
// 见讲义的第9页
3.3、消费者命令行操作
// 见讲义的第10页
四、Kafka生产者
4.1、生产者消息发送流程
// 主要见讲义的第10页
主要涉及到两个线程:main线程和sender线程
下面章节会仔细讲这里涉及到的重点:
- main线程的send(produceRecord)代码的编写
- 和集群建立联系
- 应答acks参数
- 以及重要参数batch.size和linger.ms
- 需要注意的是!!!一个分区创建一个队列!!!
- sender线程中有一个请求队列,每一个请求队列可以缓冲最多5个请求,不需要等前面的得到应答再发第二个请求

(1)异步发送API编写
// 主要看讲义的第12-13页
异步什么含义,可以去看讲义,有手写笔记。其实就是可以不用等上一次写的数据都被kafka从内存,也就是双端队列中拿走,就可以继续写数据到双端队列。
- 导入kafaka依赖
- 编写代码
- 创建kafka生产者的配置对象properties,主要用来存放参数,然后将其放进kafkaproducer对象中
- 给properties添加配置信息,必须配置的是bootstrap-server连接的主机,以及key和value的序列化。因为生产者对象其实就是一堆k-v值
- 调用send方法,发送数据
- 调用send方法,发送数据
- 最后关闭资源
- 直接运行程序即可,如果消费者打开着,就可以看到生产者写进去的数据
(2)带回调函数的异步发送API编写
// 主要看讲义的第13-15页
主要就是数据发送结束后,返回数据的相关信息到控制台
在send 方法中加上一个callback方法,里编写自己想要的内容
// 添加回调
kafkaProducer.send(new ProducerRecord<>("first", "atguigu " + i), new Callback() {
// 该方法在 Producer 收到 ack 时调用,为异步调用
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception == null) {
// 没有异常,输出信息到控制台
System.out.println(" 主题: " + metadata.topic() + "->" + "分区:" + metadata.partition());
} else {
// 出现异常打印
exception.printStackTrace();
}
}
});
(3)同步发送API编写
// 主要看讲义的第15-13页
就是在异步发送的基础上,再调用一下get()方法
kafkaProducer.send(new ProducerRecord<>("first","kafka" + i)).get();
4.2、生产者分区
1、分区策略
有三种分区策略:
- 分别是指明自己将要存放的数据存放到哪个分区。
- 或者没有指明分区的值,但是提供了key。
- 最后一个就是什么也没制定,但是会尽可能都划分到一个区
所以说前两种都需要提供key值,我们4.1节的代码中默认使用的send中ProducerRecord只是提交value值
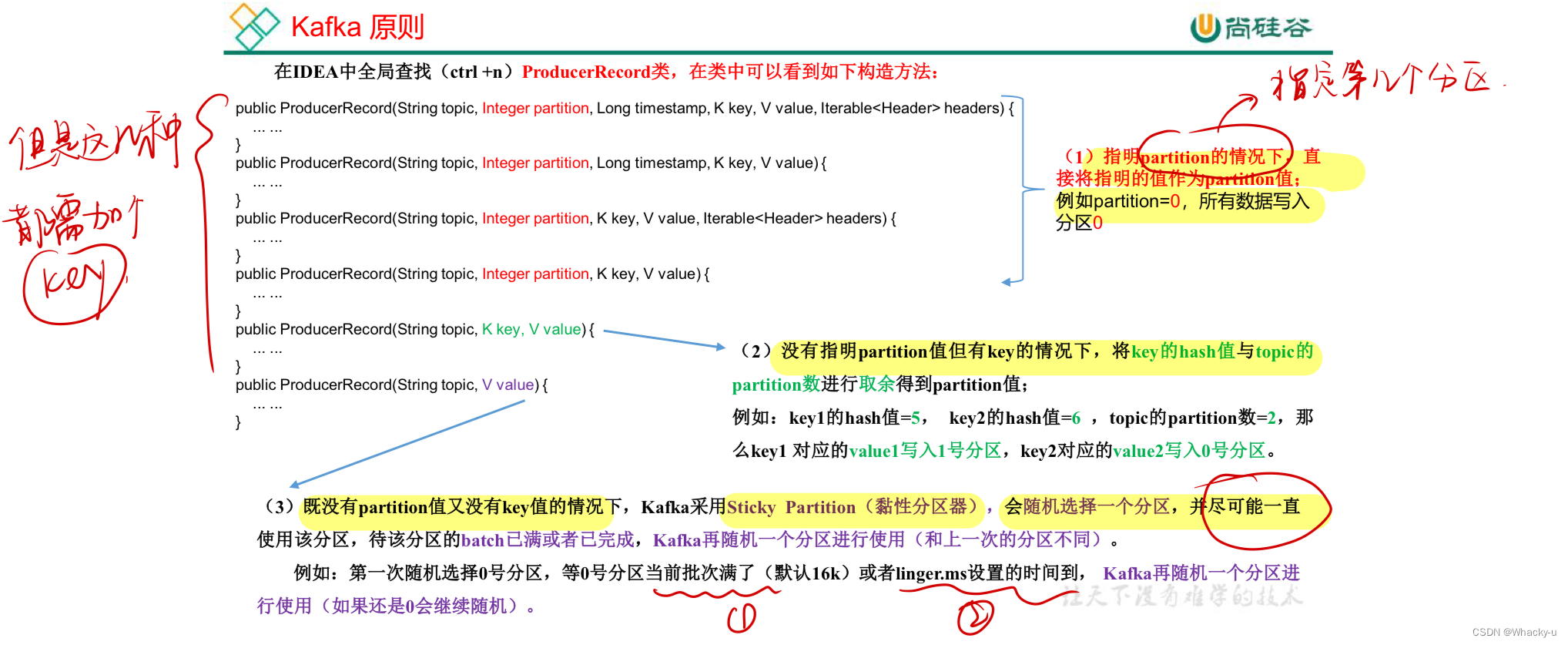
//主要见讲义第18-21页
其实在实际编写代码的时候,就是改send部分,他底层源码会按照上面的三个策略去帮你分配进入哪个分区
2、自定义分区
//主要见讲义第21-23页
代码中实际完成的就是重写partition方法中的几个步骤:
-
获取消息,将参数的value值变成tostring
-
然后根据需求,去分析value,然后返回不同情况返回不同的partition值
-
最后将这个类的全类名,放在生产者的代码中,添加一个参数
// 添加自定义分区器 properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,"com.atguigu.kafka.producer.MyPartitioner");
4.3、生产经验
1、提高吞吐量
//主要见讲义第24-25页
在生产者代码中可以调整参数:
-
批次大小
-
等待时间
-
缓冲区大小
-
压缩
2、数据可靠性
//主要见讲义第25-28页
一共有三个应答等级0,1,-1
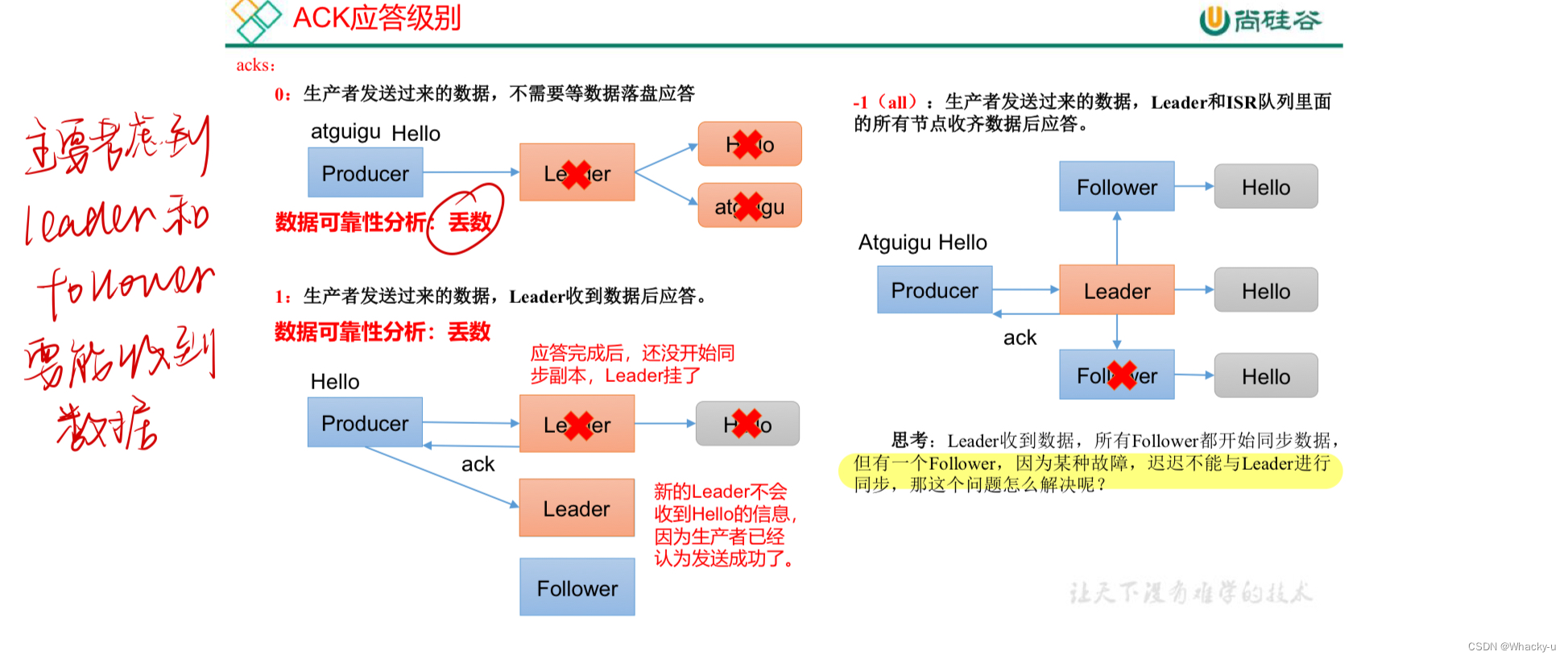
但是各有利弊,其中较为完善的“ -1,也就是all ” 中,还是会有一个问题。
Leader收到数据,所有Follower都开始同步数据, 但有一个Follower,因为某种故障,迟迟不能与Leader进行 同步,那这个问题怎么解决呢?
提出了ISR。基于此:
数据完全可靠条件 = ACK级别设置为-1 + 分区副本大于等于2 + ISR里应答的最小副本数量大于等于2
但是还会有一个数据可能重复的问题。
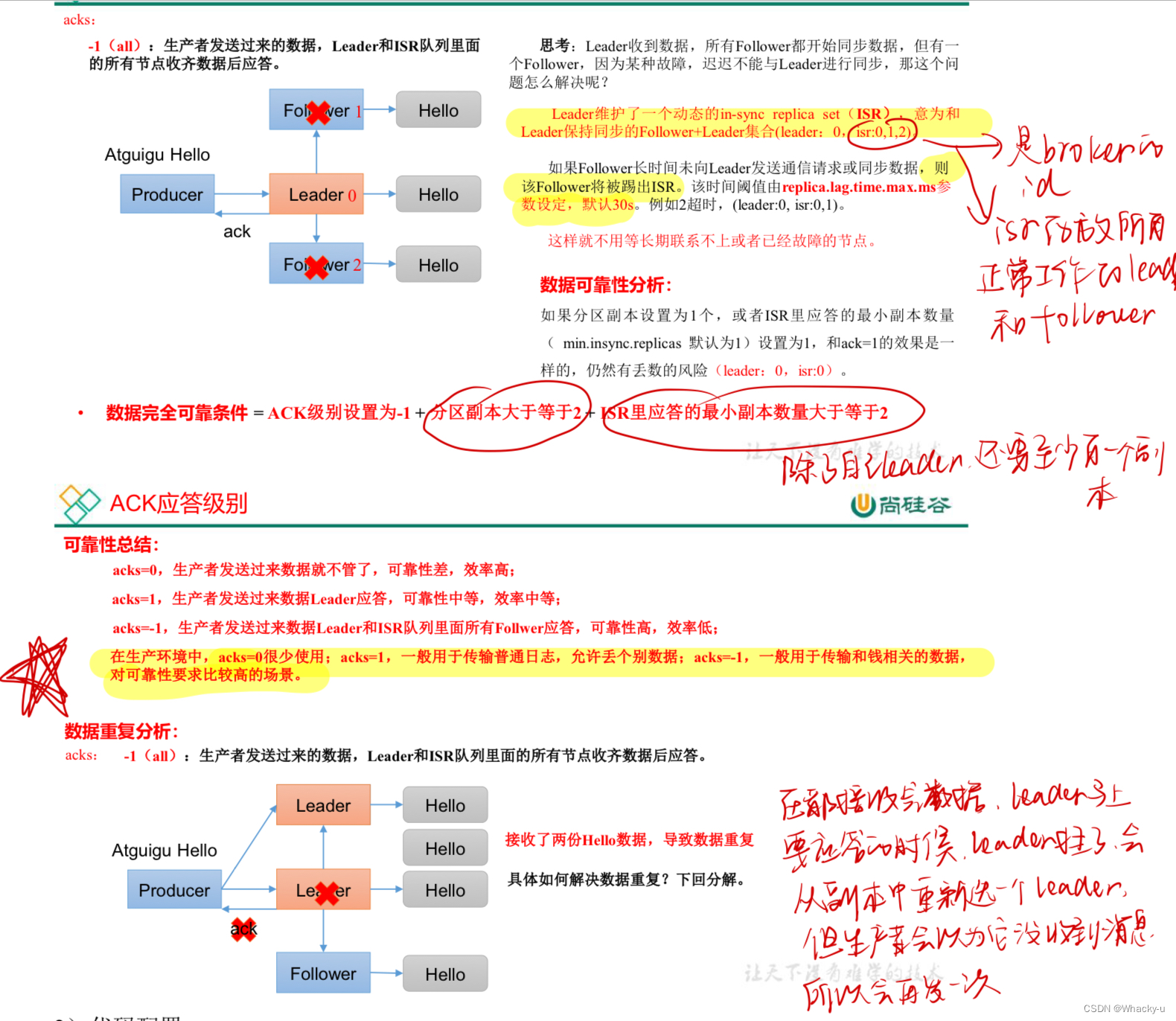
其实默认就是-1的机制,但是我们可以在生产者代码中进行配置
// 设置 acks
properties.put(ProducerConfig.ACKS_CONFIG, "all");
3、数据去重
//主要见讲义第29-31页
这里主要是幂等性和事务
默认幂等性是开的。
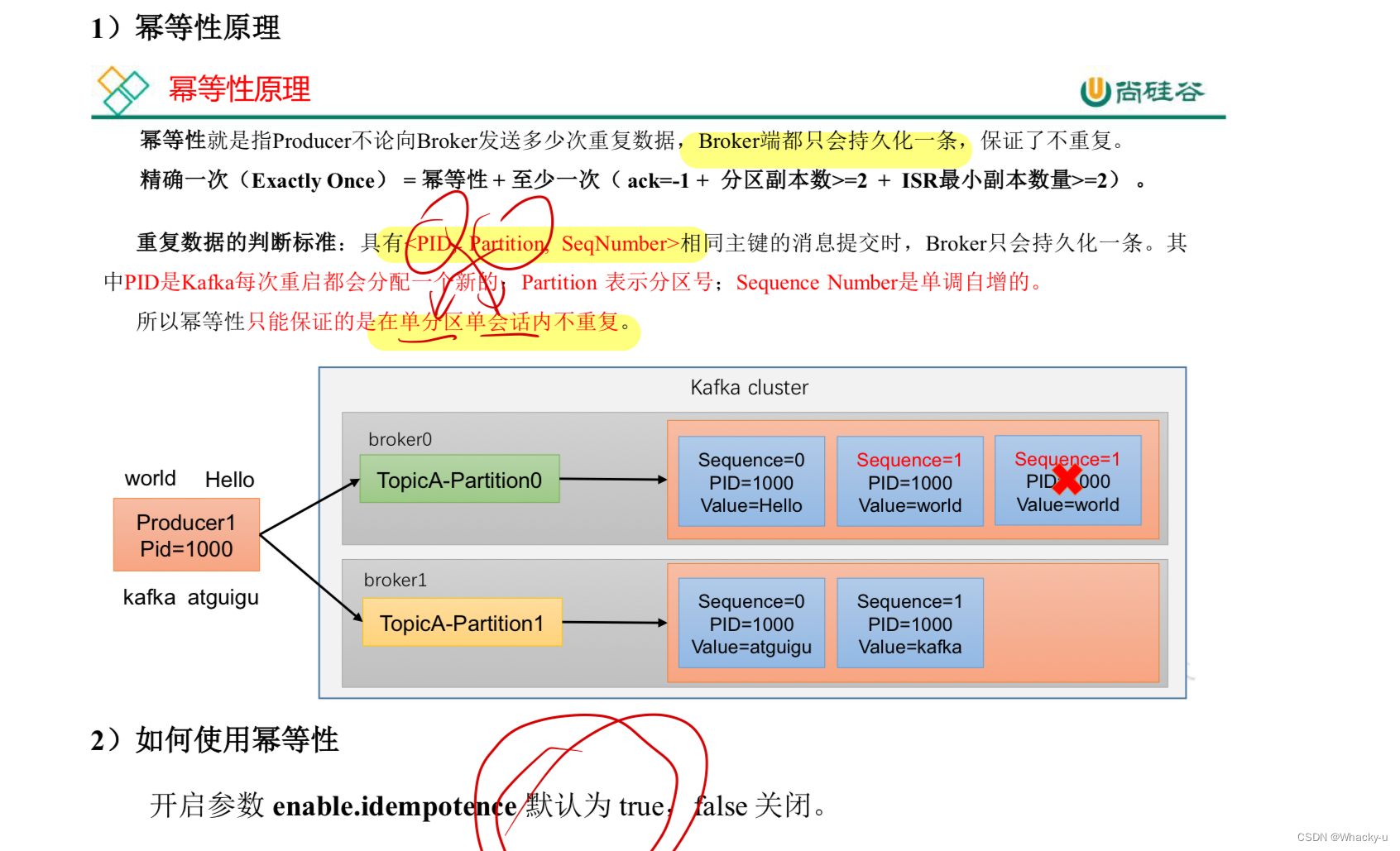
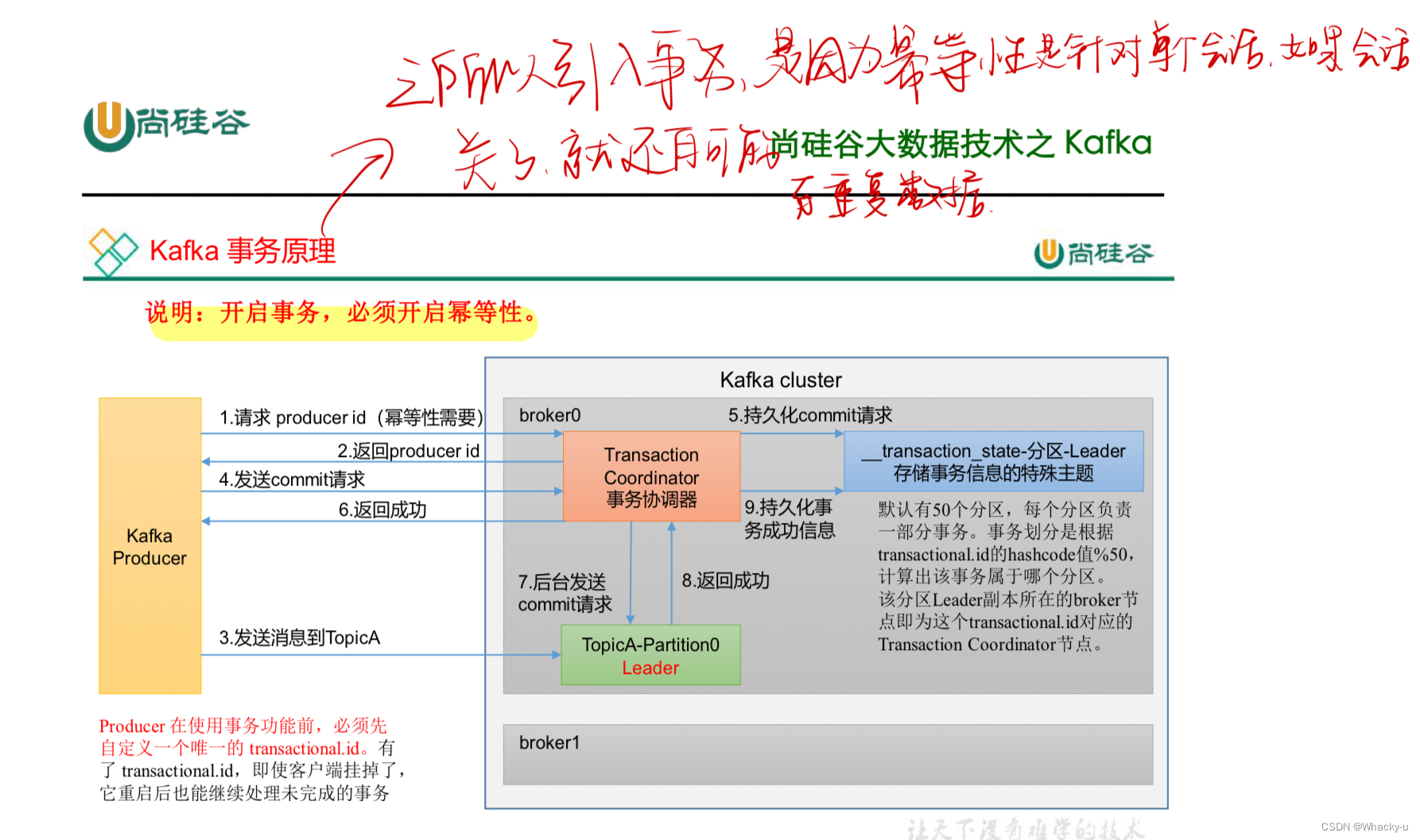
在生产者代码中,实际就是引入关于事务的一个API,在讲义中可以看看
一定要设置一个事务id!!!!要不一样的
这里举一个例子:
// 设置事务 id(必须),事务 id 任意起名
properties.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "transaction_id_0");
// 3. 创建 kafka 生产者对象
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);
// 初始化事务
kafkaProducer.initTransactions();
// 开启事务
kafkaProducer.beginTransaction();
try {
// 4. 调用 send 方法,发送消息
for (int i = 0; i < 5; i++) {
// 发送消息
kafkaProducer.send(new ProducerRecord<>("first", "atguigu " + i));
}
// 提交事务
kafkaProducer.commitTransaction();
} catch (Exception e) {
// 终止事务
kafkaProducer.abortTransaction();
} finally {
// 5. 关闭资源
kafkaProducer.close();
}
}
4、数据有序 & 数据乱序
其中数据乱序是面试重点!!!
//主要见讲义第32页
分为单分区有序和多分区有序。但是多分区有序这个需要等所有分区数据都到齐才能重新排序,因为分区间是无序的
而单分区有序是有条件的,没有开启幂等性的时候,那就是一个请求处理完才会来一个请求,这样的话两个请求之间的顺序不会乱,因为如果第一个请求没有完成我们不管的话,直接开始接受第二个请求去传数据,那第一个请求的数据会在之后发送,那么就会造成这个分区的数据混乱无序掉
但是开了幂等性后就没事了,比如第三个请求挂掉,但是他会记录顺序,之后先接受第四个和后面的请求,之后接受了第三个请求后,在broker中重新排序

五、Kafka Broker
5.1、Zookeeper存储Kafka信息
这块查看zookeeper中节点存储的信息,可以用一个app,叫prettyZoo,可以看到内部信息
主要明白zookeeper中存储的kafka信息都有什么,和什么含义
// 主要见讲义的第33页
这里重点理解一下controller
因为下面broker的工作流程也是很多用到这个东西
要明白最后kafka集群,也就是broker集群中只会有一个节点上的controller模块会被选中当作整个集群的controller
其中,每个节点都有一个controller模块,注意是模块,他是实际可以决定哪个副本是leader的
但是由于每一个节点都有这么一个模块
所以就会抢着注册controller,谁抢到谁就说的算
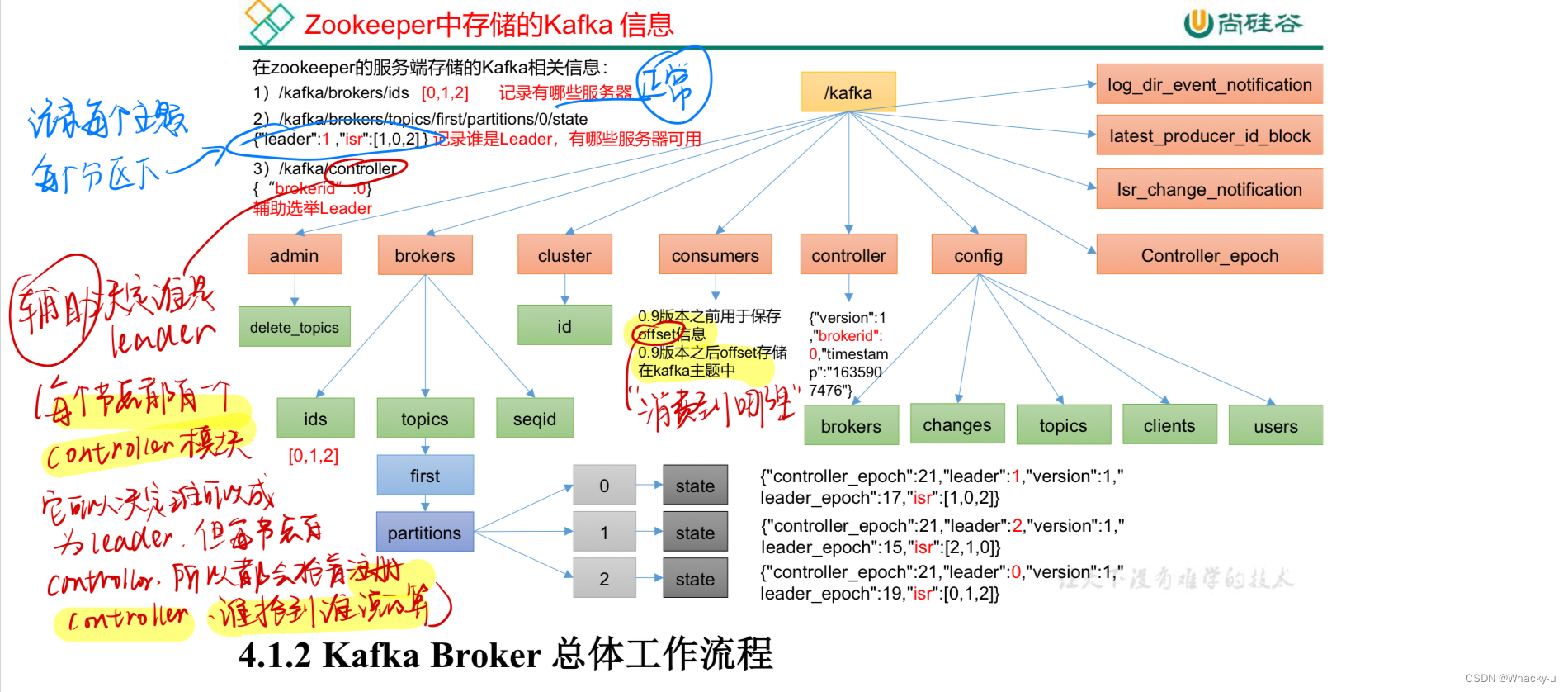
5.2、broker工作流程
// 主要见讲义第33-35页
- broker启动 后在zk中注册
- zookeeper中的 ids 会记录正常的服务器
- 每台broker抢着注册controller,controller谁先注册,谁说了算,假如broker0抢到了【每一台broker都有一个controller】
- 那broker0上的controller模块监听brokers节点变化【监听各个节点的状态,从zoo中ids可以监听到】
- Controller决定Leader选举,决定出来副本中谁是leader,这里说的副本是每一个主题每一个分区都会有几个副本,这几个副本中就有一个leader,剩下的就是follower
- Controller将节点信息上传到ZK
- 其他contorller从zk同 步相关信息【第5和6其实就是一个同步信息的过程,防止之后有节点挂点,信息不全】
- 假如broker1这个leader挂了,controller监听到后
- 从zookeeper中获取ISR,和AR
- 选举新的Leader(在 isr中存活为前提,按照 AR中排在前面的优先)
- 更新Leader及ISR

5.3、节点服役和退役
这个其实主要就是生产环境中,可能有时候突然需要新增加broker节点,或者退役节点
这就需要操作一下
// 主要看讲义的第35-38页
1、服役
- 准备一个新的服务器,下载好jdk,kafka等环境。【实际生产中确实需要一个干净的服务器,但是平常学习直接克隆】
- 打开hadoop105这个克隆好的,修改静态IP,主机名【之前主机映射文件也改好了hadoop105和ip的了】
- 重新启动
- 重点修改克隆后机器上的配置文件,和其余文件
- 修改 haodoop105 中 kafka 的 broker.id 为 3。
- 删除 hadoop105 中 kafka 下的 datas 和 logs。
- 最后单独启动hadoop105的kafka就相当于这个节点上线了
-
创建一个要均衡的主题:一个json文件
{ "topics": [ {"topic": "first"} //可以有多个主题 ], "version": 1 } -
命令行用上面的json文件生成一个负载均衡的计划。
bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --topics-to-move-json-file topics-to-move.json --broker-list "0,1,2,3" --generate -
执行上面生成的计划
-
先复制上面生成的计划到一个新的json文件
-
然后执行命令行命令,执行计划
bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --reassignment-json-file increase-replication-factor.json --execute
-
2、退役
退役其实也是需要重新用到上面的负载均衡计划
把要退役节点数据均衡走
然后再退出节点的kafka服务即可
5.4、副本
// 主要看讲义的第38-44页
1、首先明确副本是针对谁的:
每一个主题的每一个分区会有几个副本,不同副本存放在不同的broker中。所以分区可以有很多个,但是副本个数最好不要超过broker个数。并且从这几个副本里面选举一个leader
2、Kafka分区中的所有副本统称AR
AR = ISR + OSR
ISR,表示和 Leader 保持同步的 Follower 集合。
// 如果 Follower 长时间未向 Leader 发送通信请求或同步数据,则该 Follower 将被踢出 ISR。该时间阈值由 replica.lag.time.max.ms参数设定,默认 30s。Leader 发生故障之后,就会从 ISR 中选举新的 Leader。
OSR,表示 Follower 与 Leader 副本同步时,延迟过多的副本
1)leader选举流程
//其实在broker中的工作流程中有讲到,不过讲义的第39-40举了一个例子,可以看看详细过程
2)Leader和Follower故障处理细节
//看讲义的第39-40页
这里面有两个标记值,LEO和HW
follower故障后再恢复的时候:是Follower会读取本地磁盘记录的 上次的HW,并将log文件高于HW的部分截取掉,从HW开始 向Leader进行同步。等该Follower的LEO大于等于该Partition的HW,即 Follower追上Leader之后,就可以重新加入ISR了。
leader故障后:其余的Follower会先 将各自的log文件高于HW的部分截掉,然后从新的Leader同步数据。【追求的数据一致性,不能保证数据不会丢失或者重复】
3)分区副本分配
//讲义的第41-42页
假如有四个broker,分区数大于服务器台数的时候。就会出现每一个broker出现多个分区
那这种情况如何分配副本呢?是有一定规律的
但是也可以手动调整分区副本,因为有的时候新服役的机器性能比较好
可以多分配一些
这个其实和节点服役退役是一样的流程,去创建计划然后执行计划
//讲义的第43页
4)Leader partition负载均衡
//讲义的第44页
如果某些broker宕机,会导致Leader Partition过于集中在其他少部分几台broker上,
正常来说,一般AR的顺序,也就是里面副本存放的broker主机id是不会更换顺序的
所以AR中的第一个id,比如1,就是该分区对应副本中,leader的那个副本所在的broker节点id,,但是如果实际的leader不是在这个上面,比如是0,这个不是1,那就是1发生过宕机,所以1的不平衡数加一

5.5、文件存储
//讲义的第45-46页
5.6、文件清理策略
//讲义的第47-48页
Kafka 中默认的日志保存时间为 7 天
删除日志,包括基于时间和基于大小两种
日志压缩,这个压缩和平常说到的压缩不一样!!!!!!!只留下最新的,类似是覆盖
5.7、高效读写数据【面试重点】
//讲义的第48-49页
- Kafka 本身是分布式集群,可以采用分区技术,并行度高
- 读数据采用稀疏索引,可以快速定位要消费的数据
- 顺序写磁盘【顺序比随机写快很多】
- 页缓存 + 零拷贝技术
六、Kafka消费者
1、消费方式
拉pull 和 推push两种模式
主要由消费者决定自己的需求,因为broker没法决定每个消费者不同的速度需求,所以采取拉取数据的方式
但是也有不足之处,就是如果broker中没有数据,消费者会陷入循环中,一直返回空数据
2、消费者工作流程
- 消费者组初始化,主要涉及每个消费者消费哪个分区的分配,还有一些参数的配置
- 详细消费流程
// 主要见讲义的第50-52页
这里有两个重点!!!!!!!!!!
// 在初始化过程中,需要知道coordinator节点如何进行选择的
// 还有触发再平衡的两个条件,就是两个时间参数,一个3s,一个45s,一个5min
1)消费者组初始化【面试重点】
每一个broker节点都有一个coordinator,这个可以辅助消费者组选择出来怎么消费
然后类似事务中有一个特殊的主题,默认50个分区,然后每一个消费者组有一个独立的id。由id的hash值去%50
得到的值就是选中负责的coordinator,然后coordinator会随机选择消费者组中的一个消费者是leader,然后把这个leader指定的方案,发送给消费者组中的所有消费者。也会接受提交的offset
具体流程如下图:

2)消费流程
- 发送拉取数据请求
- 回调信息,将数据写入一个消息队列
- 然后对队列中的数据反序列化,经过拦截器处理数据
- 消费者组拉取数据
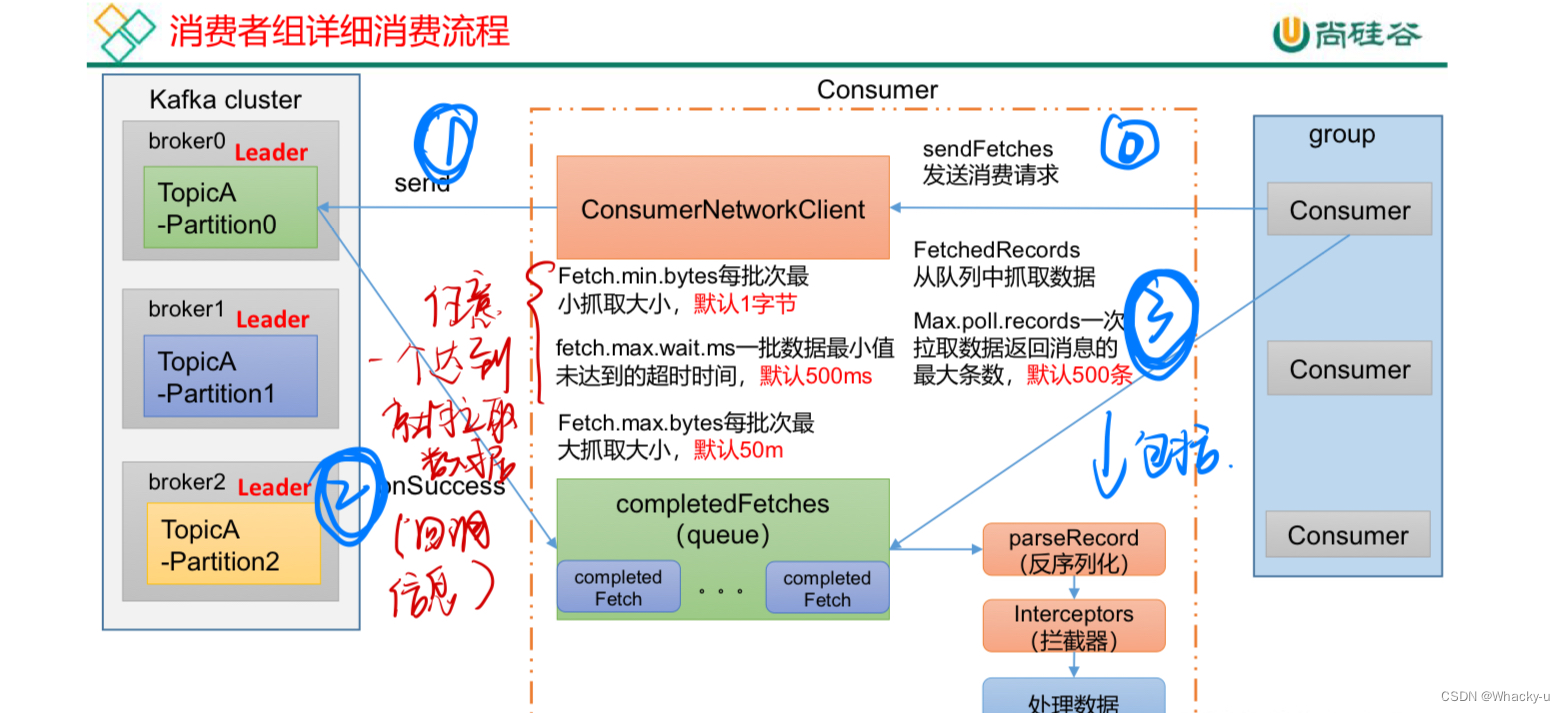
3、消费者API【代码实现】
//主要见讲义第53-59页
如果只是订阅主题,就是找到想要消费的主题,把主题中来的数据都消费【获取】,那在注册要消费主题时候用subscribe()
如果是订阅分区,就是消费主题中具体的分区,用assign()
1、独立消费者案例【订阅主题】
-
创建消费者配置对象properties
-
给消费者配置对象添加参数
-
连接参数
-
配置反序列化
-
一定不要忘了!!!配置消费者组id
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"test");
-
-
创建消费者对象
//1 创建一个消费者 KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties); -
注册要消费的主题,就是subscribe
//2 订阅主题 ArrayList<String> topics = new ArrayList<>(); topics.add("first"); kafkaConsumer.subscribe(topics); -
拉取数据,消费数据,就是poll
//3 消费数据 while(true){ // 设置 1s 中消费一批数据 ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1)); // 打印消费到的数据 for (ConsumerRecord<String, String> consumerRecord : consumerRecords) { System.out.println(consumerRecord); } }
2、独立消费者案例【订阅分区】
就是在订阅部分是不一样的
不是subscribe,而是assign
// 消费某个主题的某个分区数据
ArrayList<TopicPartition> topicPartitions = new ArrayList<>();
topicPartitions.add(new TopicPartition("first", 0)); //说明要订阅的主题,和其中的分区
kafkaConsumer.assign(topicPartitions);
//对比一下单纯的订阅主题
ArrayList<String> topics = new ArrayList<>();
topics.add("first");
kafkaConsumer.subscribe(topics);
3、消费者组案例
其实就是定义很多个消费者代码
主要他们的group的id一样就行
他们就会被分配到同一个消费者组
4、分区的分配以及再平衡
//主要见讲义第59-65页
Kafka有四种主流的分区分配策略: Range、RoundRobin、Sticky、CooperativeSticky。
这里提到的再平衡就是,按照45s这个标准判断这个broker是否退出,如果超过45s这个消费者还是没有进行拉取数据进行消费
那么,这个消费者本应该消费的数据,就会被重新分配到其他机器上,这些数据分配到其他机器上的方案,和整体的方案是一致的
上面那种情况是针对45s之前还是存活工作的,如果被检查到上次就已经退出不工作了,那么这个broker就不会被分配数据,就相当于集群中没有这个机器,不会出现上面那段描述的情况
//这个再分配,在下面的集中分配策略中,讲义和自己的手写笔记也有详细描写,可以好好看看
分区方案是怎么发送的呢?
回忆一下消费者的工作流程,每一台broker都有一个coordinator,根据消费者组的id,去选出来是哪个broker的coordinator用来做决定。coordinator会随机选择一个消费者,让其当作leader,之后这个leader的消费者,就负责制定消费方案,将方案发给coordinator,coordinator会把方案发给消费者组中的每一个消费者
那么这里面的leader在指定消费方案的时候,是怎么指定分区的
1、Range
//见讲义的第60-62页
- 先对同一个topic里的分区进行排序,消费者按字母也进行排序
- 通过 partitions数/consumer数 来决定每个消费者应该 消费几个分区。如果除不尽,那么前面几个消费者将会多 消费 1 个分区。【这里说的多消费一个分区,是在最开始多消费,比如就是第一个消费者消费0,1,2;之后第二个消费者消费3,4】
这样的分区策略如果topic越多,那么多消费的那个消费者就会明显多消费。
容易造成数据倾斜
这种策略是并不需要指定的,默认就是。只要生产者对每个分区都发过一些数据,就可以检验到
2、RoundRobin
//见讲义的第62-63页
-
这个是针对集群中所有的topic而言
【!!!注意!!!这里是针对所有topic中的partition一起排序了!!!】
-
把所有的 partition 和所有的 consumer 都列出来,然后按照 hashcode 进行排序,最后 通过轮询算法来分配 partition 给到各个消费者
【这里说的轮询,就是从上到下一个个把partition分配给消费者,可以具体看讲义中的图】
这个就需要更改一下分配策略了。就是在代码中更改就好。最好多看看官网,因为每个版本的kafka参数可能不太一样
// 修改分区分配策略
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,"org.apache.kafka.clients.consumer.RoundRobinAssignor");
3、 Sticky 以及再平衡
//见讲义的第64-65页
- 也是针对集群中所有的topic而言
- 首先会尽量均衡的放置分区 到消费者上面,在出现同一消费者组内消费者出现问题的时候,会尽量保持原有分配的分区不变化。
【这一部分看讲义手写笔记吧。类似range,但是不是有序的,不过之后的版本好像是有规律分布】
5、offset位移
5.1、查看消费offset
// 在讲义的第66页
默认是不能查看消费系统主题数据的,需要改成false: config/consumer.properties 中添加配置 exclude.internal.topics=false,
如果是命令行启动消费者,最好手动加上group id,要不系统自动给你加一个,你不知道加的是啥样的id
5.2、自动提交offset
//讲义的第67-68页
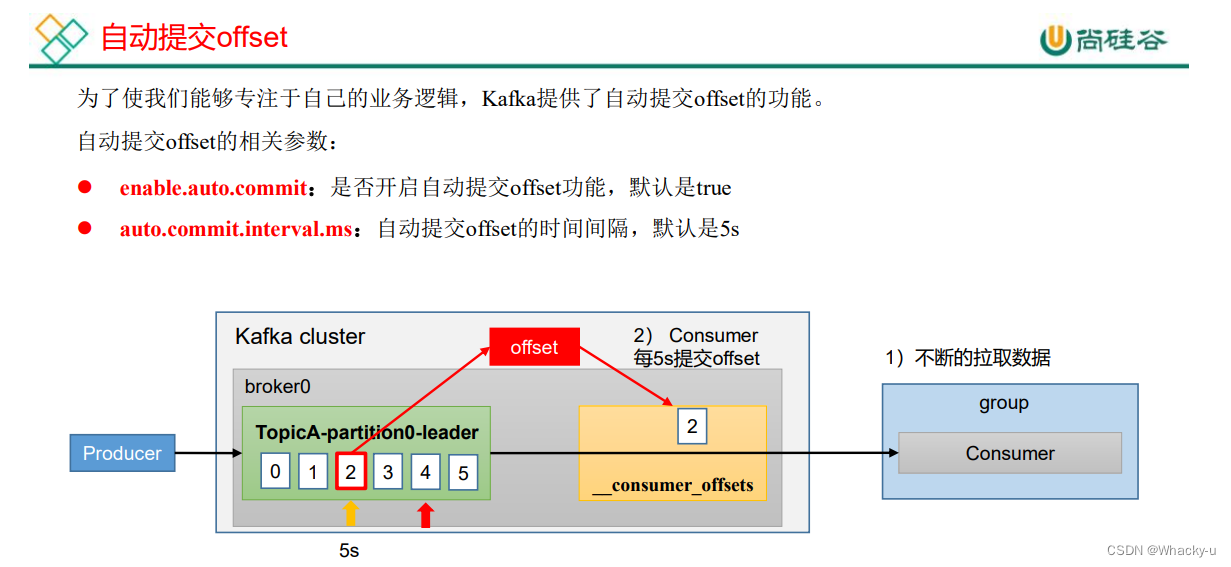
也就是默认打开这个自动提交offset,每隔5秒提交一次
默认是打开的,我们之后写手动提交的时候可以关闭,也可以自己设置自动提交的间隔时间。这个都是在消费者代码中写的
但是需要注意的是,不同版本的参数可能不一样,要多看官网
// 是否自动提交 offset
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
// 提交 offset 的时间周期 1000ms,默认 5s
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 1000); //1000的单位是ms
5.3、手动提交offset
//讲义的第71-73页
之所以提到手动提交offset这个东西,是因为自动提交是基于时间的,我们很难把握offset提交的时机
所以还是有API可以让我们去手动提交的
比如我们可以设置,消费一条数据就提交一次offset,避免了自动提交中可能的提前消费,有时候处理时间过程,但是它已经提交了offset,但是实际它并没有消费到这个提交的offset
// 手动提交offset的方法有两种:分别是commitSync(同步提交)和commitAsync(异步提交)。
• commitSync(同步提交):必须等待offset提交完毕,再去消费下一批数据。
• commitAsync(异步提交) :发送完提交offset请求后,就开始消费下一批数据了【可能offset没提交成功,但也开始消费下一批数据】
其实实现的流程十分简单
- 先是将自动提交offset关闭
- 然后在消费数据的代码部分设置同步提交或者异步提交的代码
// 是否自动提交 offset
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
// 同步提交 offset
consumer.commitSync();
// 异步提交 offset
consumer.commitAsync();
5.4、指定offset消费
//讲义的第73-75页
这一部分主要是指定一开始从哪里开始消费,就是针对消费者怎么利用offset
(1)earliest:自动将偏移量重置为最早的信息位置,–from-beginning。
(2)latest(默认值):自动将偏移量重置为最新发送来的信息位置【偏移量】
其实上面说的这个就是,分区中的数据位置,一个是从最头的位置开始,另外一个是当前时刻,注意是时间的当前时间下,生产者可能又发送新数据来,那我们就送这里还是进行往后消费,这里就是此次消费者组offset的起点
代码实现就是seek,然后获取分区分配信息,用seek去从分区中我们指定的offset中开始消费
// 这里还是看讲义的第73页代码吧
5.5、指定时间消费
//看讲义的第74页代码和手写笔记
其实就是想办法找到时间和offset的联系,想要通过时间获取到offset
这一部分比较晦涩,好好看看代码吧
6、漏消费和重复消费
重复消费:已经消费了数据,但是 offset 没提交。
漏消费:先提交 offset 后消费,有可能会造成数据的漏消费。
7、消费者事务
//讲义的第76页
那么需要Kafka消费端将消费过程和提交offset
过程做原子绑定。此时我们需要将Kafka的offset保存到支持事务的自定义介质
比如(MySQL)
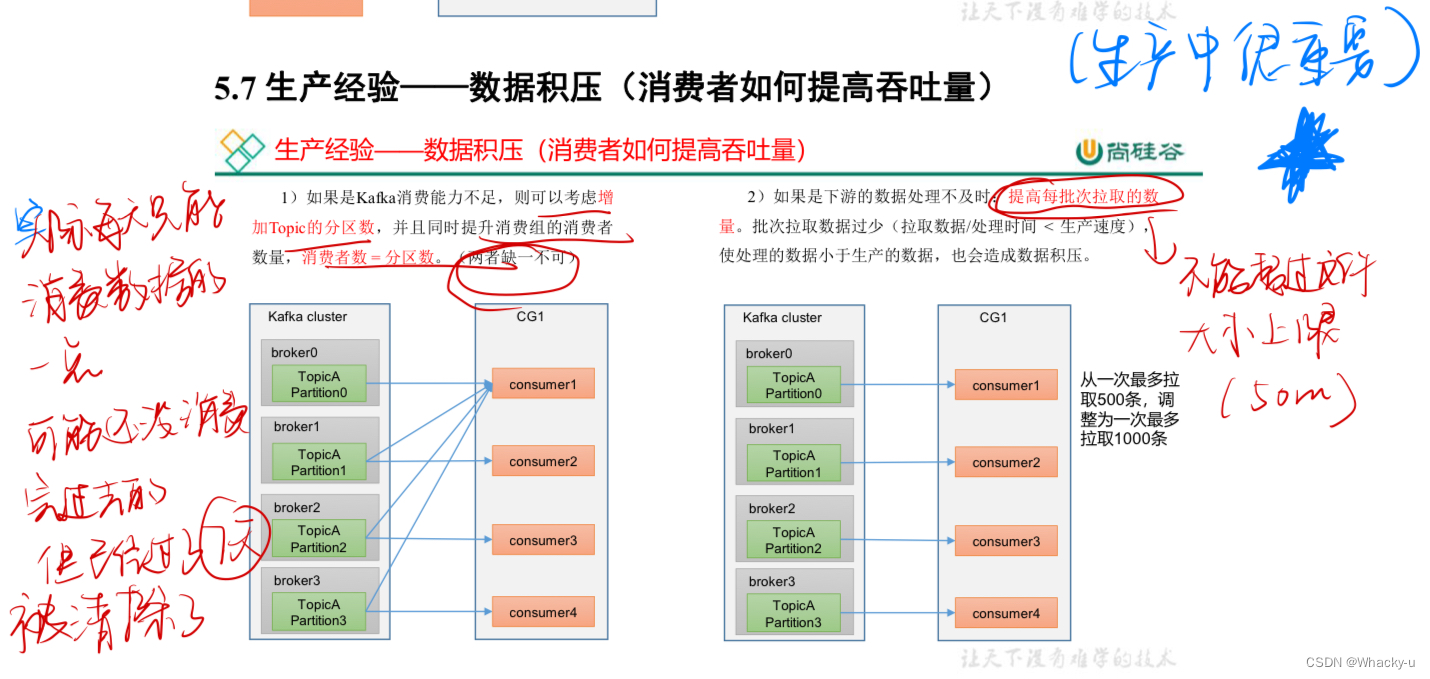
8、数据积压【生产中很重要!!!】
//讲义的第76页
可能两点造成:
1、kafka集群性能所限
2、拉取数据不及时,拉的数据一次较少或者时间间隔过长。也可以这么说,就是消费的及时,但是后续发给消费者目的地的效率不高,目的地
七、Kafka-Eagle监控【efak】
// 见讲义第77-81页
Kafka-Eagle 框架可以监控 Kafka 集群的整体运行情况
Kafka-Eagle 的安装依赖于 MySQL,MySQL 主要用来存储可视化展示的数据。
- 安装mysql
- kafka内存从1G调整到2G,并且暴露一个用来监控kafka的端口号,9999
- 安装kafka-Eagle
- 修改其中配置文件件/opt/module/efak/conf/system-config.properties
- 更改监控集群的信息
- 更改保留kafka的offset的选线,删掉zk
- 配置mysql的连接参数
- 添加环境变量
- 启动bin/ke.sh start【但是需要先开启zookeeper和Kafka】
- 命令生成后,会提供一个网址,和账号密码。进去后可以看到各种详细信息、可视化界面,也可以直接在界面中多主题进行创建等操作
八、Kafka-kraft模式
//见讲义第82-84页
看怎么安装部署的
九、调优【涉及到调优讲义】
主要涉及四部分:
- 硬件配置怎么配,需要什么样的参数,给什么样的硬件条件
- 生产者,消费者,broker服务端。这三部分的调优和生产经验,在前面文档都讲过了,都在api部分后面那些就是
- 总体调优部分,其中数据精确一次这个内容可以好好看一下,容易面试问!!还有合理分配分区数的计算公式,单条日志大小
- 压测,kafka提供了命令行脚本,可以进行压测
//主要看第一、三、四,这三个部分
十、源码【涉及到源码讲义】
另外看源码讲义
其中生产者和消费者,是用java写的,broker,是在源码中的core文件中,用scala语言写的
5.png" alt=“image-20240101155217055” style=“zoom:50%;” />
七、Kafka-Eagle监控【efak】
// 见讲义第77-81页
Kafka-Eagle 框架可以监控 Kafka 集群的整体运行情况
Kafka-Eagle 的安装依赖于 MySQL,MySQL 主要用来存储可视化展示的数据。
- 安装mysql
- kafka内存从1G调整到2G,并且暴露一个用来监控kafka的端口号,9999
- 安装kafka-Eagle
- 修改其中配置文件件/opt/module/efak/conf/system-config.properties
- 更改监控集群的信息
- 更改保留kafka的offset的选线,删掉zk
- 配置mysql的连接参数
- 添加环境变量
- 启动bin/ke.sh start【但是需要先开启zookeeper和Kafka】
- 命令生成后,会提供一个网址,和账号密码。进去后可以看到各种详细信息、可视化界面,也可以直接在界面中多主题进行创建等操作
八、Kafka-kraft模式
//见讲义第82-84页
看怎么安装部署的
九、调优【涉及到调优讲义】
主要涉及四部分:
- 硬件配置怎么配,需要什么样的参数,给什么样的硬件条件
- 生产者,消费者,broker服务端。这三部分的调优和生产经验,在前面文档都讲过了,都在api部分后面那些就是
- 总体调优部分,其中数据精确一次这个内容可以好好看一下,容易面试问!!还有合理分配分区数的计算公式,单条日志大小
- 压测,kafka提供了命令行脚本,可以进行压测
//主要看第一、三、四,这三个部分
十、源码【涉及到源码讲义】
另外看源码讲义
其中生产者和消费者,是用java写的,broker,是在源码中的core文件中,用scala语言写的









