一、摘要
二、地址
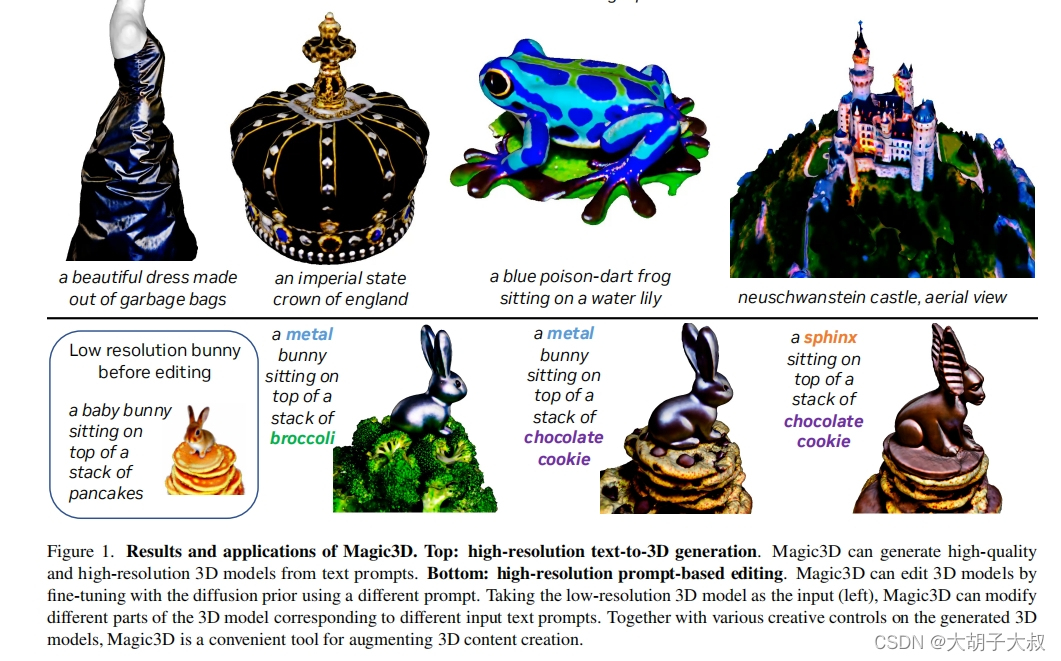
标题:Magic3D: High-Resolution Text-to-3D Content Creation
论文:https://arxiv.org/abs/2211.10440
demo展示(此地址还还可以访问):https://deepimagination.cc/Magic3D/
三、方法
上面简单来说:
第一阶段,利用低分辨率扩散先验并优化神经场表示(颜色、密度和正常场)来获得粗模型。
第二阶段:从粗模型的密度场和颜色场中提取纹理三维网格。然后用高分辨率潜在扩散模型对其进行微调。
经过优化后,模型生成了具有详细纹理的高质量3D网格。以从粗到细的方式从输入文本提示生成高分辨率的3D内容。
四、实现过程
DreamBooth描述了一种方法,通过对一个主题的几张图像微调预先训练的模型,来个性化文本到图像扩散模型。经过微调的模型可以学习将主题绑定到一个唯一的标识符字符串(记为[V]),并在文本提示中包含[V]时生成主题的图像。在文本到3D生成的上下文中,希望生成主题的3D模型。这可以通过首先使用DreamBooth方法微调扩散先验模型来实现,然后使用带有[V]标识符的微调扩散先验作为条件文本提示的一部分,在优化3D模型时提供学习信号。
为了证明DreamBooth在论文框架中的适用性,收集了一只猫的11张图像和一只狗的4张图像。微调eDiff-I和LDM,将文本标识符[V]绑定到给定的主题。然后在文本提示中用[V]对三维模型进行优化。使用批处理大小为1进行所有微调。对于eDiff-I,使用学习率为1 × 10−5的Adam优化器进行1500次迭代;对于LDM,对800次迭代的学习率进行微调,学习率为1 × 10−6。下图显示了个性化文本到3D结果:能够成功地修改3D模型,在给定的输入图像中保留主题。

五、GPU
使用8块A100
coarse stage训练5000 iter,大概训练15分钟;
fine stage训练3000 iter,大概训练25分钟。
六、结论
我们提出了Magic3D,这是一个快速、高质量的文本到3D生成框架。我们以从粗到细的方法从高效的场景模型和高分辨率的扩散先验中获益。特别是,3D网格模型可以很好地与图像分辨率进行缩放,并在不牺牲其速度的情况下享受潜在扩散模型带来的高分辨率监督的好处。从atext提示到准备用于图形引擎的高质量3D网格模型需要40分钟。通过广泛的用户研究和定性比较,我们发现与DreamFusion相比,Magic3D更受评分者的青睐(61.7%),同时速度提高了2倍。最后,我们提出了一套在三维生成中更好地控制样式和内容的工具。我们希望通过Magic3D,我们可以使3D合成民主化,并在3D内容创作中打开每个人的创造力。










