Word2Vec模型介绍
1. 背景介绍
自然语言处理和词嵌入的重要性
自然语言处理(NLP)一直是人工智能领域中最具挑战性的问题之一。它旨在使计算机能够理解和解释人类语言,从而完成如文本翻译、情感分析和语音识别等任务。在这个过程中,词嵌入(word embedding)扮演了关键角色。词嵌入是将词语转化为计算机可以理解的数值形式的技术,即将词语映射到高维空间中的向量。
在Word2Vec之前,传统的词表示方法,如one-hot编码,虽然简单但有一个显著的缺点:它们无法有效地表达不同词之间的语义关系。例如,"国王"和"王后"这两个词在语义上明显相关,但在one-hot编码中它们看起来毫无关联。为了解决这个问题,需要一种能够捕捉这种语义关系的表示方法。
Word2Vec的出现和发展概述
Word2Vec的提出,标志着词嵌入技术的一次重大进步。Word2Vec是一种高效的词嵌入模型,由Google的研究团队于2013年开发。它使用一种称为神经网络的机器学习方法,通过学习大量文本数据,生成能够表达词语间丰富语义关系的词向量。
Word2Vec的核心优势在于它能够捕捉到词语之间的细微关系。例如,在Word2Vec模型中,可以通过计算向量之间的距离来估计词语之间的相似度。这不仅能帮助理解语言的复杂性,还可以应用于各种NLP任务,如机器翻译和搜索引擎优化。
自其推出以来,Word2Vec一直是自然语言处理研究和应用的热点。尽管后来出现了更先进的模型,如GloVe和BERT,Word2Vec仍然是了解词嵌入基础的重要起点。其简洁高效的特点使得它在许多情况下仍是首选的词嵌入工具。
总的来说,Word2Vec不仅在技术层面上为自然语言处理领域带来了创新,而且还为后续的研究和开发奠定了基础。接下来,我们将深入探讨Word2Vec的工作原理,以及它是如何改变NLP领域的。
2. Word2Vec基础
Word2Vec模型的核心是通过学习文本数据来生成词向量,这些向量能够在多维空间中表征词语的语义。Word2Vec主要有两种架构:连续词袋模型(CBOW)和跳跃模型(Skip-gram)。
CBOW(连续词袋模型)
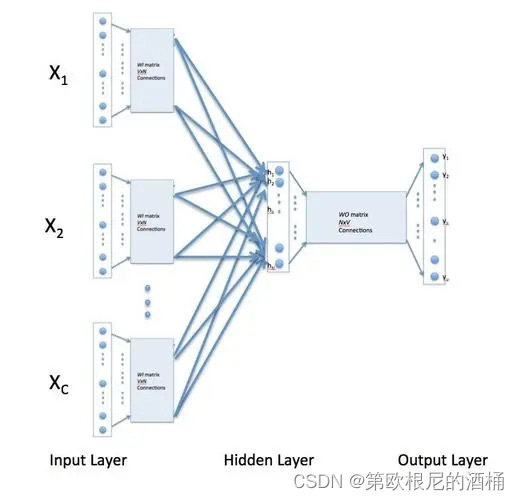
CBOW模型的目标是预测目标词基于其上下文。具体来说,模型试图根据上下文中的词来预测中间的目标词。这个过程可以用以下数学公式表示:
P ( w ∣ c o n t e x t ) = exp ( v w T v c o n t e x t ) ∑ w ′ ∈ V exp ( v w ′ T v c o n t e x t ) P(w|context) = \frac{\exp({v_w}^T v_{context})}{\sum_{w' \in V} \exp({v_{w'}}^T v_{context})} P(w∣context)=∑w′∈Vexp(vw′Tvcontext)exp(vwTvcontext)
在这个公式中, v w v_w vw是目标词w的词向量, v c o n t e x t v_{context} vcontext是上下文词向量的平均值,V是词汇表。公式计算了在给定上下文的情况下,生成特定目标词的概率。
Skip-gram(跳跃模型)
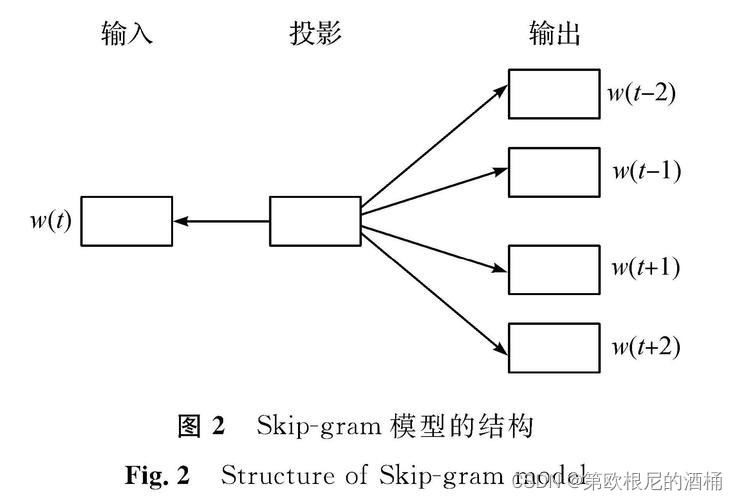
与CBOW模型相反,Skip-gram模型的目标是使用目标词来预测其上下文。这意味着给定一个目标词,模型尝试预测它周围的上下文词。Skip-gram模型的基本公式为:
P ( c o n t e x t ∣ w ) = exp ( v c o n t e x t T v w ) ∑ w ′ ∈ V exp ( v w ′ T v w ) P(context|w) = \frac{\exp({v_{context}}^T v_w)}{\sum_{w' \in V} \exp({v_{w'}}^T v_w)} P(context∣w)=∑w′∈Vexp(vw′Tvw)exp(vcontextTvw)
在这个公式中,我们仍然使用 v w v_w vw表示目标词的词向量,而 v c o n t e x t v_{context} vcontext表示某个上下文词的向量。与CBOW不同的是,Skip-gram模型在计算概率时关注的是给定目标词预测上下文词的可能性。
词向量的意义和应用
Word2Vec模型的关键在于其生成的词向量。这些向量不仅仅是数字的集合,它们在多维空间中具有特定的方向和大小,能够反映词语之间的关系。例如,相似的词会在向量空间中彼此靠近,而不同的词则相距较远。
这种词向量的表征使得Word2Vec能够在多种NLP任务中发挥重要作用。比如,在语义相似度计算中,可以通过比较词向量之间的距离来判断词语的相似性。此外,词向量还可以用于更复杂的任务,如词类比问题(例如:“国王”之于“男人”就像“王后”之于“女人”)。
3. Word2Vec的技术细节
Word2Vec模型的高效性和准确性得益于其独特的技术细节。这些技术包括特殊的词向量表示方法、训练过程的优化技巧等。
词向量的表示方法
Word2Vec模型中,每个词都被转换为一个稠密的向量。这些向量通常被初始化为随机值,然后通过训练过程进行调整。向量中的每个元素都是通过模型学习得到的,代表了词在特定维度上的属性。例如,向量可以捕捉语义上的相似性,如“国王”和“王后”的向量在某些维度上可能非常接近。
训练过程:上下文和目标词
Word2Vec模型的训练涉及调整词向量以更好地反映词之间的关系。这是通过最小化以下损失函数来实现的:
L = − ∑ w ∈ C ∑ w ′ ∈ c o n t e x t ( w ) log P ( w ′ ∣ w ) L = -\sum_{w \in C} \sum_{w' \in context(w)} \log P(w'|w) L=−w∈C∑w′∈context(w)∑logP(w′∣w)
其中,C是训练集中的所有词, c o n t e x t ( w ) context(w) context(w)是词w的上下文词集, P ( w ′ ∣ w ) P(w'|w) P(w′∣w)是给定词w时词w’出现的概率。这个公式的目的是最大化上下文词的出现概率,使模型能够更准确地预测上下文。
优化技巧:负采样和层序softmax
Word2Vec模型的另一个关键特点是其优化技巧,如负采样和层序softmax。这些技巧旨在提高训练效率。
-
负采样:这是一种简化的训练方法,只更新一部分权重,而不是模型中的所有权重。这通过随机选择“负样本”(即不在上下文中的词)来实现。
-
层序softmax:这是一种优化概率计算的方法。与传统的softmax不同,层序softmax通过构建一棵二叉树来减少计算复杂度,每个叶子节点代表词汇表中的一个词。
Word2Vec训练流程图
graph LR
A[初始化词向量] --> B[遍历训练数据]
B --> C[选择目标词和上下文词]
C --> D[应用模型:CBOW或Skip-gram]
D --> E[计算损失函数]
E --> F[优化词向量]
F --> G[应用负采样或层序softmax]
G --> H[更新模型参数]
H --> I[重复直到收敛]
4. Word2Vec的应用
Word2Vec模型不仅在理论上具有重要意义,也在实际应用中展示了巨大的潜力。下面我们将探索一些典型的应用场景。
语义相似度和词类比
Word2Vec模型的一个主要应用是在计算词之间的语义相似度。通过比较词向量之间的距离,我们可以量化词语之间的相似性。此外,Word2Vec还可以用于解决词类比问题,例如,找出与“国王 - 男人 + 女人”最相似的词,通常会得到“王后”。
在自然语言处理中的应用实例
Word2Vec模型广泛应用于多种自然语言处理任务,如文本分类、情感分析和机器翻译。例如,在情感分析中,Word2Vec可以帮助模型理解不同词语表达的情感,并据此分类文本的情感倾向。
代码演示:使用公开数据集
让我们通过一个简单的代码示例来展示Word2Vec的使用。在这个例子中,我们将使用Gensim库和一个公开的数据集进行词向量的训练。
import gensim
from gensim.models import Word2Vec
import nltk
nltk.download('punkt')
from nltk.tokenize import word_tokenize
# 加载数据集(以Gutenberg数据集为例)
from nltk.corpus import gutenberg
nltk.download('gutenberg')
sentences = list(gutenberg.sents())
# 数据预处理(简单的词条化)
processed_sentences = [word_tokenize(sentence.lower()) for sentence in sentences]
# 训练Word2Vec模型
model = Word2Vec(processed_sentences, vector_size=100, window=5, min_count=1, workers=4)
# 找出与'king'最相似的词
similar_words = model.wv.most_similar('king')
print(similar_words)
在这个例子中,我们使用了Gutenberg数据集,这是一个包含多种文学作品的公开文本库。首先,我们对文本进行了简单的预处理,然后使用Gensim库训练了Word2Vec模型,并展示了如何找出与特定词(如“king”)最相似的其他词。
与其他词嵌入技术的比较
Word2Vec虽然在许多方面表现出色,但在某些情况下,其他词嵌入技术(如GloVe或BERT)可能更为合适。例如,GloVe在捕捉全局统计信息方面优于Word2Vec,而BERT等基于Transformer的模型在理解语境上更为强大。
总结来说,Word2Vec通过其独特的方式提供了理解和处理自然语言的强大工具。它在多种任务中都显示出了极高的价值,同时也为后续更先进的模型奠定了基础。
5. Word2Vec的局限性和挑战
虽然Word2Vec在自然语言处理中取得了显著的成功,但它并非没有局限性。本节将探讨这些局限性及其应对策略。
模型局限性分析
-
上下文的静态表示:Word2Vec生成的词向量是静态的,这意味着一个词在所有上下文中都有相同的表示。这与实际语言使用中词语的多义性和上下文相关性不符。例如,"bank"这个词在不同的句子中可能表示不同的概念(如金融机构或河岸)。
-
缺乏语法和语序信息:Word2Vec关注的是词与词之间的关系,而不是词在句子中的顺序,因此它不能捕捉到语法结构上的细微差异。
-
大规模语料库的需求:为了训练准确的模型,Word2Vec需要大量的训练数据。对于资源较少的语言或专业领域,这可能是一个限制。
应对策略和未来发展方向
为了克服这些局限性,研究者们已经开发了一系列新的技术和模型。例如,BERT和ELMo等基于上下文的模型通过考虑词在具体句子中的使用,提供了动态词表示。
此外,新的研究方向也在探索如何在资源有限的情况下有效训练模型。例如,迁移学习和多语言模型展示了在数据有限的情况下提高模型性能的可能性。
参考文献
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- ELMo: Deep contextualized word representations
总的来说,尽管Word2Vec有其局限性,但它在自然语言处理领域的贡献是不可否认的。同时,这些局限性也促使研究者们持续推动自然语言处理技术的发展和创新。










