文章目录
- 1、KNN算法简介
- 2、KNN算法实现
- 3、使用scikit-learn库生成数据集
- 4、使用scikit-learn库对鸢尾花数据集进行分类
- 5、什么是超参数
- 6、特征归一化
- 7、KNN实现回归任务
- 8、根据Boston数据集建立回归模型
1、KNN算法简介
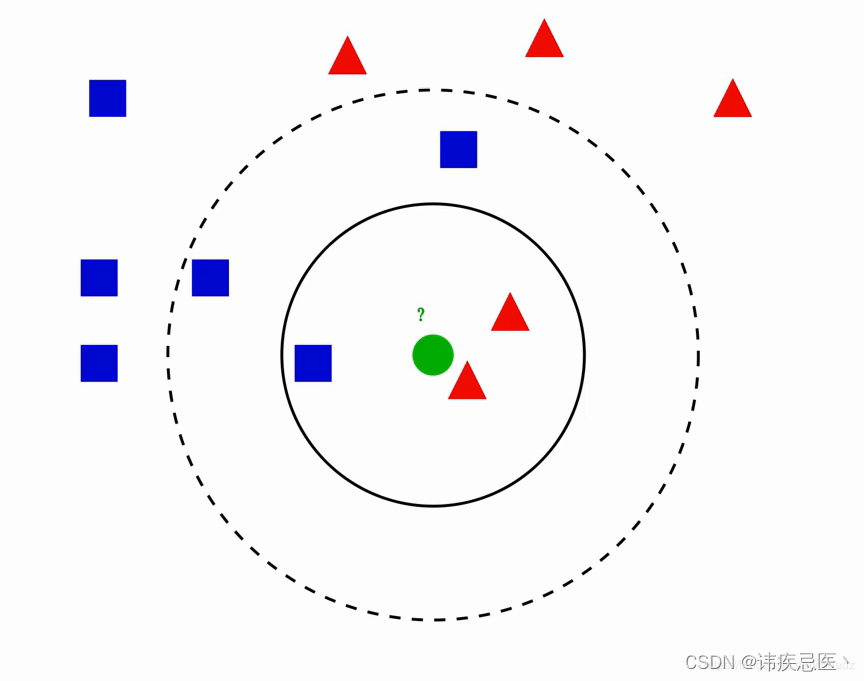
图中绿色圆归为哪一类?
1、如果k=3,绿色圆归为红色三角形
2、如果k=5,绿色圆归为蓝色正方形
参考文章
knn算法实现原理:为判断未知样本数据的类别,以所有已知样本数据作为参照物,计算未知样本数据与所有已知样本数据的距离,从中选取k个与已知样本距离最近的k个已知样本数据,根据少数服从多数投票法则,将未知样本与K个最邻近样本中所属类别占比较多的归为一类。(我们还可以给邻近样本加权,距离越近的权重越大,越远越小)
2、KNN算法实现
实现KNN算法简单实例
# KNN算法实现
import numpy as np
import matplotlib.pyplot as plt
# 样本数据
data_X = [
[1.3,6],
[3.5,5],
[4.2,2],
[5,3.3],
[2,9],
[5,7.5],
[7.2,4],
[8.1,8],
[9,2.5],
]
# 样本标记数组
data_y = [0,0,0,0,1,1,1,1,1]
# 将数组转换成np数组
X_train = np.array(data_X)
y_train = np.array(data_y)
# 散点图绘制
# 取等于0的行中的第0列数据X_train[y_train==0,0]
plt.scatter(X_train[y_train==0,0],X_train[y_train==0,1],color='red',marker='x')
# 取等于1的行中的第1列数据X_train[y_train==1,0]
plt.scatter(X_train[y_train==1,0],X_train[y_train==1,1],color='black',marker='o')
plt.show()
data_new = np.array([4,5])
plt.scatter(X_train[y_train==0,0],X_train[y_train==0,1],color='red',marker='x')
plt.scatter(X_train[y_train==1,0],X_train[y_train==1,1],color='black',marker='o')
plt.scatter(data_new[0],data_new[1],color='blue',marker='s')
plt.show()
Numpy使用
# 样本数据-新样本数据 的平方,然后开平,存储距离值到distances中
distances = [np.sqrt(np.sum((data-data_new)**2)) for data in X_train]
# 按照距离进行排序,返回原数组中索引 升序
sort_index = np.argsort(distances)
# 随机选一个k值
k = 5
# 距离最近的5个点进行投票表决
first_k = [y_train[i] for i in sort_index[:k]]
# 使用计数库统计
from collections import Counter
# 取出结果为类别0
predict_y = Counter(first_k).most_common(1)[0][0]
predict_y
2.1、调用scikit-learn库中KNN算法
安装:pip install scikit-learn

# 使用scikit-learn中的KNN算法
from sklearn.neighbors import KNeighborsClassifier
# 初始化设置k大小
knn_classifier = KNeighborsClassifier(n_neighbors=5)
# 喂入数据集,以及数据类型
knn_classifier.fit(X_train,y_train)
# 放入新样本数据进行预测,需要先转换成二维数组
knn_classifier.predict(data_new.reshape(1,-1))
3、使用scikit-learn库生成数据集
生成的数据,画出的散点图
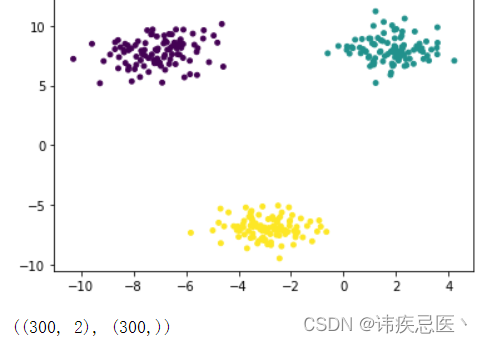
# 数据集生产
import numpy as np
from matplotlib import pyplot as plt
from sklearn.datasets import make_blobs
x,y = make_blobs(
n_samples=300, # 样本总数
n_features=2, # 生产二维数据
centers=3, # 种类数据
cluster_std=1, # 类内的标注差
center_box=(-10,10), # 取值范围
random_state=233, # 随机数种子
return_centers=False, # 类别中心坐标反回值
)
# c指定每个点颜色,s指定点大小
plt.scatter(x[:,0],x[:,1],c=y,s=15)
plt.show()
x.shape,y.shape
3.1、自定义函数划分数据集
# 数据集划分
np.random.seed(233)
# 随机生成数组排列下标
shuffle = np.random.permutation(len(x))
train_size = 0.7
train_index = shuffle[:int(len(x)*train_size)]
test_index = shuffle[int(len(x)*train_size):]
train_index.shape,test_index.shape
# 通过下标数组到数据集中取出数据
x_train = x[train_index]
y_train = y[train_index]
x_test = x[test_index]
y_test = y[test_index]
# 训练数据集
plt.scatter(x_train[:,0],x_train[:,1],c=y_train,s=15)
plt.show()
# 测试数据集
plt.scatter(x_test[:,0],x_test[:,1],c=y_test,s=15)
plt.show()
3.2、使用scikit-learn库划分数据集
# sklearn划分数据集
from sklearn.model_selection import train_test_split
# 保证3个样本数保持原来分布,添加参数stratify=y
x_train,x_test,y_train,y_test = train_test_split(x,y,train_size=0.7,random_state=233,stratify=y)
from collections import Counter
Counter(y_test)
4、使用scikit-learn库对鸢尾花数据集进行分类
# 使用鸢尾花数据集
import numpy as np
from sklearn import datasets
# 加载数据集
iris = datasets.load_iris()
# 获取样本数组,样本类型数组
X = iris.data
y = iris.target
# 拆分数据集
# 不能直接拆分因为现在的y已经是排序好的,需要先乱序数组
# shuffle_index = np.random.permutation(len(X))
# train_ratio = 0.8
# train_size = int(len(y)*train_ratio)
# train_index = shuffle_index[:train_size]
# test_index = shuffle_index[train_size:]
# X_train = X[train_index]
# Y_train = y[train_index]
# X_test = X[test_index]
# Y_test = y[test_index]
from sklearn.model_selection import train_test_split
# 保证3个样本数保持原来分布,添加参数stratify=y
x_train,x_test,y_train,y_test = train_test_split(X,y,train_size=0.8,random_state=666)
# 预测
from sklearn.neighbors import KNeighborsClassifier
# 初始化设置k大小
knn_classifier = KNeighborsClassifier(n_neighbors=5
)
# 喂入数据集,以及数据类型
knn_classifier.fit(x_train,y_train)
# 如果关心预测结果可以跳过下面所有score返回得分
knn_classifier.score(x_test,y_test)
y_predict = knn_classifier.predict(x_test)
# 评价预测结果 将y_predict和真是的predict进行比较就可以了
accuracy = np.sum(y_predict == y_test)/len(y_test)
# accuracy
# sklearn中计算准确度的方法
from sklearn.metrics import accuracy_score
accuracy_score(y_test,y_predict)
5、什么是超参数
KNN算法中超参数表示什么,表示K的最近邻居有几个,是分类表决还是加权表决。
5.1、实现寻找超参数
# 超参数
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
import numpy as np
data = load_iris()
X = data.data
y = data.target
X.shape,y.shape
X_train,X_test,y_train,y_test = train_test_split(X,y,train_size=0.7,random_state=233,stratify=y)
X_train.shape,X_test.shape,y_train.shape,y_test.shape
# 遍历所有超参数,选取准确率
# uniform权重一直,越近权重越高distance
# p等于1折线曼哈顿距离计算方式,p=2欧式距离
best_score = -1
best_n = -1
best_p = -1
best_weight = ''
for i in range(1,20):
for weight in ['uniform','distance']:
for p in range(1,7):
neigh = KNeighborsClassifier(
n_neighbors=i,
weights=weight,
p = p
)
neigh.fit(X_train,y_train)
score = neigh.score(X_test,y_test)
if score>best_score:
best_score = score
best_n = i
best_p = p
best_weight = weight
print(best_n,best_p,best_weight,best_score)
5.2、使用scikit-learn库实现
# 使用skleran超参数搜索
from sklearn.model_selection import GridSearchCV
params = {
'n_neighbors':[n for n in range(1,20)],
'weights':['uniform','distance'],
'p':[p for p in range(1,7)]
}
grid = GridSearchCV(
estimator=KNeighborsClassifier(),# 分类模型器
param_grid=params,# 参数
n_jobs=-1 # 自动设置并行任务数量
)
# 传入数据集
grid.fit(X_train,y_train)
# 得到超参数和得分
grid.best_params_
print(grid.best_score_)
# knn对象对测试数据集进行预测
y_predict = grid.best_estimator_.predict(X_test)
# sklearn中计算准确度的方法
from sklearn.metrics import accuracy_score
accuracy_score(y_test,y_predict)
6、特征归一化
6.1、实现最大最小值归一化
对上面数据做最大最小归一化操作
# 对数据做归一化
X[:5]
X[:,0] = (X[:,0] - np.min(X[:,0]))/(np.max(X[:,0])-np.min(X[:,0]))
X[:,1] = (X[:,1] - np.min(X[:,1]))/(np.max(X[:,1])-np.min(X[:,1]))
X[:,2] = (X[:,2] - np.min(X[:,2]))/(np.max(X[:,2])-np.min(X[:,2]))
X[:,3] = (X[:,3] - np.min(X[:,3]))/(np.max(X[:,3])-np.min(X[:,3]))
X[:5]
6.2、实现零均值归一化
假设有一组数据集:[3, 6, 9, 12, 15]
计算平均值:
平均值 = (3 + 6 + 9 + 12 + 15) / 5 = 9
计算方差:
方差 = ((3-9)^2 + (6-9)^2 + (9-9)^2 + (12-9)^2 + (15-9)^2) / 5 = 18
计算标准差:
标准差 = √方差 = √18 ≈ 4.24
# 零均值归一化
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
import numpy as np
data = load_iris()
X = data.data
y = data.target
X[:5]
# 求均值
np.mean(X[:,0])
# 标准差
np.std(X[:,0])
X[:,0] = (X[:,0]- np.mean(X[:,0]))/(np.std(X[:,0]))
X[:,1] = (X[:,1]- np.mean(X[:,1]))/(np.std(X[:,1]))
X[:,2] = (X[:,2]- np.mean(X[:,2]))/(np.std(X[:,2]))
X[:,3] = (X[:,3]- np.mean(X[:,3]))/(np.std(X[:,3]))
X[:5]
6.3、scikit-learn归一化使用

# scikit-learn中归一化
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
import numpy as np
data = load_iris()
X = data.data
y = data.target
X[:5]
from sklearn.preprocessing import StandardScaler
standard_scaler = StandardScaler()
standard_scaler.fit(X)
# 输出4列特征的均值
standard_scaler.mean_
# 输出标4列特标准差
standard_scaler.scale_
# X本身没有改变,我们需要将结果重新赋值给X
X = standard_scaler.transform(X)
X[:5]
7、KNN实现回归任务
7.1、实现KNN回归代码
# KNN 实现回归任务
# KNN算法实现
import numpy as np
import matplotlib.pyplot as plt
# 样本数据
data_X = [
[1.3,6],
[3.5,5],
[4.2,2],
[5,3.3],
[2,9],
[5,7.5],
[7.2,4],
[8.1,8],
[9,2.5],
]
# 样本标记数组
data_y = [0.1,0.3,0.5,0.7,0.9,1.1,1.3,1.5,1.7]
X_train = np.array(data_X)
y_train = np.array(data_y)
data_new = np.array([4,5])
plt.scatter(X_train[:,0],X_train[:,1],color='black')
plt.scatter(data_new[0],data_new[1],color='b',marker='s')
for i in range(len(y_train)):
plt.annotate(y_train[i],xy=X_train[i],xytext=(-15,-15),textcoords='offset points')
plt.show()
distance = [np.sqrt(np.sum((i-data_new)**2)) for i in X_train]
sort_index = np.argsort(distance)
k = 5
first_k = [y_train[i] for i in sort_index[:k]]
np.mean(first_k)
7.2、使用scikit-learn库实现
# 使用scikit-learn实现
from sklearn.neighbors import KNeighborsRegressor
knn_reg = KNeighborsRegressor(n_neighbors=5)
knn_reg.fit(X_train,y_train)
predict_y = knn_reg.predict(data_new.reshape(1,-1))
predict_y
8、根据Boston数据集建立回归模型
import numpy as np
import matplotlib.pyplot as plt
import sklearn
from sklearn.model_selection import train_test_split
import pandas as pd
# 加载波士顿房屋数据集
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]
# 数据准备
X = data
y = target
X.shape,y.shape
# 数据集划分
X_train,X_test,y_train,y_test = train_test_split(X,y,train_size=0.7,random_state=233)
# 建立回归模型
from sklearn.neighbors import KNeighborsRegressor
knn_reg = KNeighborsRegressor(n_neighbors=5,weights='distance',p=2)
knn_reg.fit(X_train,y_train)
# 计算得分,发现得分很低,原因是因为没有做归一化处理导致
knn_reg.score(X_test,y_test)
做归一化处理之后输出得分
# 归一化操作
from sklearn.preprocessing import StandardScaler
standard_scaler = StandardScaler()
standard_scaler.fit(X_train)
# 对x train进行归一化操作
x_train = standard_scaler.transform(X_train)
x_test = standard_scaler.transform(X_test)
knn_reg.fit(x_train,y_train)
knn_reg.score(x_test,y_test)










