一、YOLOV8环境准备
1.1 下载安装最新的YOLOv8代码
仓库地址: https://github.com/ultralytics/ultralytics
1.2 配置环境
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
二、数据准备
2.1 安装labelme标注软件
pip install labelme
2.1.2 打开LabelImg软件
使用Anaconda Prompt启动labeme标注工具

2.2 标注自己的数据

2.3 数据处理
2.3.1 运行下面代码,将json格式标签转为txt格式标签
先创建txt文件夹,整体目录如下

import json
import os
name2id = {
"-":0,
"0":1,
"1":2,
"2":3,
"3":4,
"4":5,
"5":6,
"6":7,
"7":8,
"8":9,
"9":10,
"A":11,
"B":12,
"C":13,
"D":14,
"E":15,
"F":16,
"G":17,
"H":18,
"I":19,
"J":20,
"K":21,
"L":22,
"M":23,
"N":24,
"O":25,
"P":26,
"Q":27,
"R":28,
"S":29,
"T":30,
"U":31,
"V":32,
"W":33,
"X":34,
"Y":35,
"Z":36}
def convert(img_size, box):
dw = 1./(img_size[0])
dh = 1./(img_size[1])
x = (box[0] + box[2])/2.0 - 1
y = (box[1] + box[3])/2.0 - 1
w = box[2] - box[0]
h = box[3] - box[1]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
x = round(x, 3)
w = round(w, 3)
y = round(y, 3)
h = round(h, 3)
return (x,y,w,h)
def decode_json(json_floder_path,json_name):
# 需要手动新建下面目录的文件夹,根据自己实际情况而定
txt_name = 'D:\\data\\slot-number\\wanda\\txt\\' + json_name[0:-5] + '.txt'
txt_file = open(txt_name, 'w')
json_path = os.path.join(json_floder_path, json_name)
data = json.load(open(json_path, 'r', encoding='gb2312'))
img_w = data['imageWidth']
img_h = data['imageHeight']
for i in data['shapes']:
label_name = i['label']
if (i['shape_type'] == 'rectangle'):
x1 = int(i['points'][0][0])
y1 = int(i['points'][0][1])
x2 = int(i['points'][1][0])
y2 = int(i['points'][1][1])
bb = (x1,y1,x2,y2)
bbox = convert((img_w,img_h),bb)
txt_file.write(str(name2id[label_name]) + " " + " ".join([str(a) for a in bbox]) + '\n')
if __name__ == "__main__":
# D:\\data\\slot-number\\wanda\\json存放了labelme标注生成的json文件的文件夹
json_floder_path = 'D:\\data\\slot-number\\wanda\\json'
json_names = os.listdir(json_floder_path)
for json_name in json_names:
decode_json(json_floder_path,json_name)
查看转换后生成的yolo格式的txt标签文件

2.3.2 运行下面代码,划分数据集
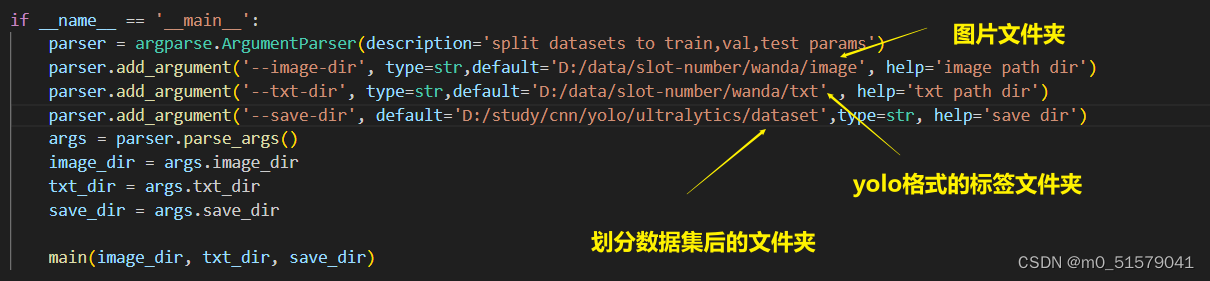
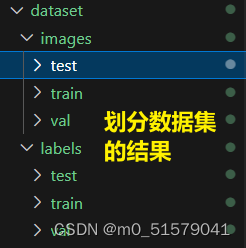
# 将图片和标注数据按比例切分为 训练集和测试集
import shutil
import random
import os
import argparse
# 检查文件夹是否存在
def mkdir(path):
if not os.path.exists(path):
os.makedirs(path)
def main(image_dir, txt_dir, save_dir):
# 创建文件夹
mkdir(save_dir)
images_dir = os.path.join(save_dir, 'images')
labels_dir = os.path.join(save_dir, 'labels')
img_train_path = os.path.join(images_dir, 'train')
img_test_path = os.path.join(images_dir, 'test')
img_val_path = os.path.join(images_dir, 'val')
label_train_path = os.path.join(labels_dir, 'train')
label_test_path = os.path.join(labels_dir, 'test')
label_val_path = os.path.join(labels_dir, 'val')
mkdir(images_dir);
mkdir(labels_dir);
mkdir(img_train_path);
mkdir(img_test_path);
mkdir(img_val_path);
mkdir(label_train_path);
mkdir(label_test_path);
mkdir(label_val_path);
# 数据集划分比例,训练集75%,验证集15%,测试集15%,按需修改
train_percent = 0.8
val_percent = 0.1
test_percent = 0.1
total_txt = os.listdir(txt_dir)
num_txt = len(total_txt)
list_all_txt = range(num_txt) # 范围 range(0, num)
num_train = int(num_txt * train_percent)
num_val = int(num_txt * val_percent)
num_test = num_txt - num_train - num_val
train = random.sample(list_all_txt, num_train)
# 在全部数据集中取出train
val_test = [i for i in list_all_txt if not i in train]
# 再从val_test取出num_val个元素,val_test剩下的元素就是test
val = random.sample(val_test, num_val)
print("训练集数目:{}, 验证集数目:{},测试集数目:{}".format(len(train), len(val), len(val_test) - len(val)))
for i in list_all_txt:
name = total_txt[i][:-4]
srcImage = os.path.join(image_dir, name + '.png')
srcLabel = os.path.join(txt_dir, name + '.txt')
if i in train:
dst_train_Image = os.path.join(img_train_path, name + '.png')
dst_train_Label = os.path.join(label_train_path, name + '.txt')
shutil.copyfile(srcImage, dst_train_Image)
shutil.copyfile(srcLabel, dst_train_Label)
elif i in val:
dst_val_Image = os.path.join(img_val_path, name + '.png')
dst_val_Label = os.path.join(label_val_path, name + '.txt')
shutil.copyfile(srcImage, dst_val_Image)
shutil.copyfile(srcLabel, dst_val_Label)
else:
dst_test_Image = os.path.join(img_test_path, name + '.png')
dst_test_Label = os.path.join(label_test_path, name + '.txt')
shutil.copyfile(srcImage, dst_test_Image)
shutil.copyfile(srcLabel, dst_test_Label)
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='split datasets to train,val,test params')
parser.add_argument('--image-dir', type=str,default='D:/data/slot-number/wanda/image', help='image path dir')
parser.add_argument('--txt-dir', type=str,default='D:/data/slot-number/wanda/txt' , help='txt path dir')
parser.add_argument('--save-dir', default='D:/study/cnn/yolo/ultralytics/dataset',type=str, help='save dir')
args = parser.parse_args()
image_dir = args.image_dir
txt_dir = args.txt_dir
save_dir = args.save_dir
main(image_dir, txt_dir, save_dir)
2.3.3 使用脚本,获取训练集,验证集的txt标签的路径
三、配置文件设置
3.1 修改coco8.yaml
修改ultralytics\ultralytics\cfg\datasets\coco8.yaml配置文件内容:(建议使用绝对路径)
path: D:/data/slot-number/
train: images/train
val: images/val
test:
names:
0: sign -
1: nubmer 0
2: nubmer 1
3: nubmer 2
4: nubmer 3
5: nubmer 4
6: nubmer 5
7: nubmer 6
8: nubmer 7
9: nubmer 8
10: nubmer 9
11: A
12: B
13: C
14: D
15: E
16: F
17: G
18: H
19: I
20: J
21: K
22: L
23: M
24: NN
25: O
26: P
27: Q
28: R
29: S
30: T
31: U
32: V
33: W
34: X
35: YY
36: Z
四、训练
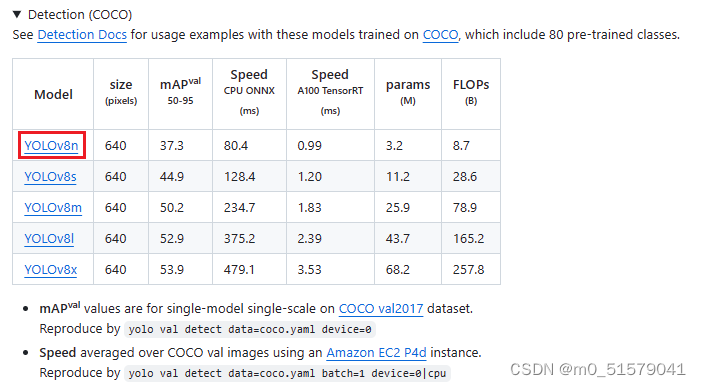
4.1 下载预训练权重
在YOLOv8 github上下载预训练权重:yolov8n.pt,ultralytics\ultralytics\路径下,新建weights文件夹,预训练权重放入其中。
4.2 训练
步骤一:修改ultralytics\ultralytics\cfg\default.yaml文件中的训练参数(根据自己的实际情况决定)
步骤二:执行下面代码:(建议使用绝对路径)
# 训练目标检测代码
from ultralytics import YOLO
# Load a model
model = YOLO('D:/study/cnn/yolo/ultralytics/weights/yolov8n.pt')
# Train the model
results = model.train(data='D:/study/cnn/yolo/ultralytics/ultralytics/cfg/datasets/coco8.yaml', epochs=700, imgsz=640)
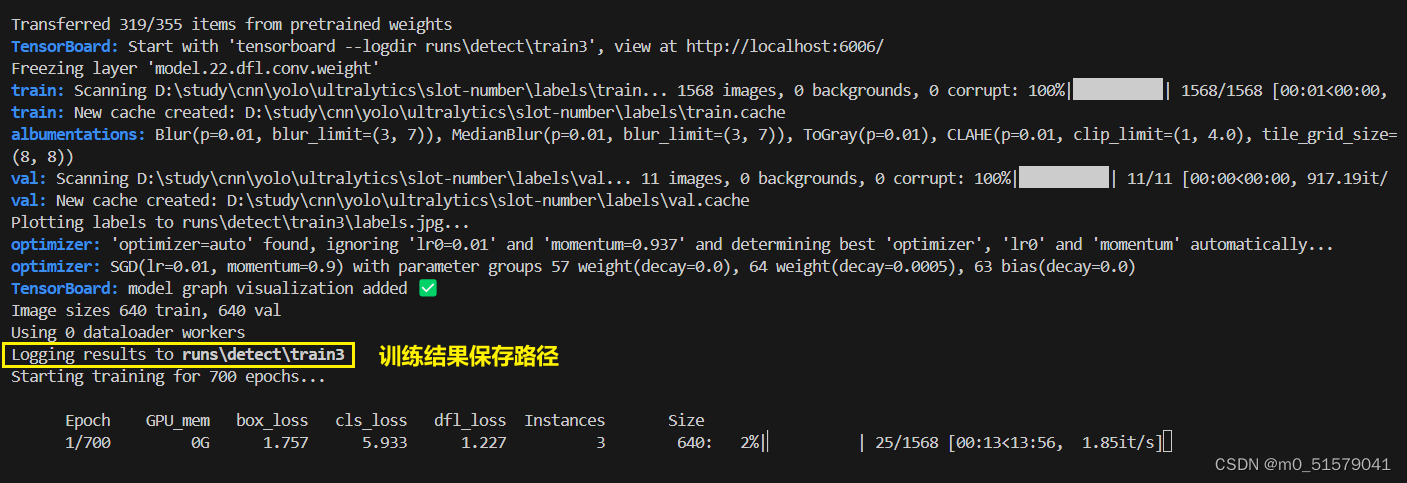
五、验证
# 验证目标检测代码
from ultralytics import YOLO
# Load a model
model = YOLO('D:/study/cnn/yolo/ultralytics/runs/detect/train3/weights/best.pt')
# Train the model
results = model.val(data='D:/study/cnn/yolo/ultralytics/ultralytics/cfg/datasets/coco8.yaml', epochs=700, imgsz=640)
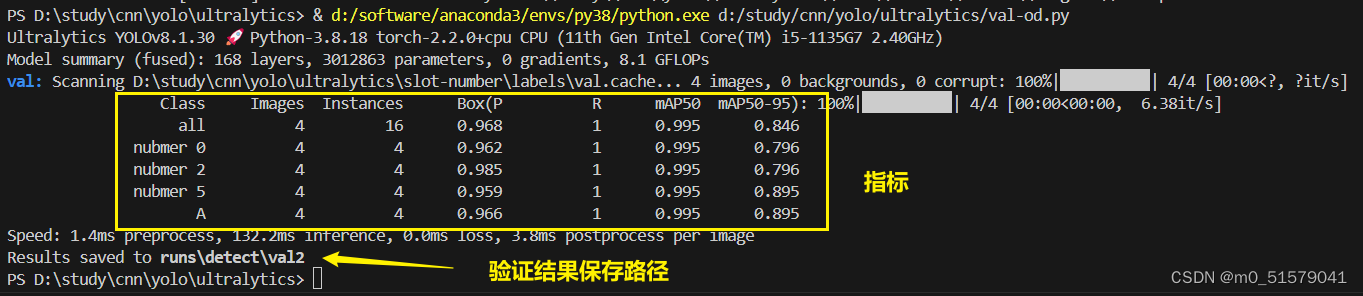
查看模型验证的其中一张图片结果

六、推理
根据自己实际的情况,修改路径(建议使用绝对路径)
# YOLOv8目标检测推理代码
from ultralytics import YOLO
# Load a model
model = YOLO('D:/study/cnn/yolo/ultralytics/runs/detect/train3/weights/best.pt')
# Predict with the model
results = model('D:/study/cnn/yolo/ultralytics/slot-number/images/train/1.png',save=True) # predict on an image












