
WIOU损失函数替换

👀🎉📜系列文章目录
【yolov5-v6.0详细解读】
【目标检测—IOU计算详细解读(IoU、GIoU、DIoU、CIoU、EIOU、Focal-EIOU、SIOU、WIOU)】
【YOLOv5改进系列(1)】高效涨点----使用EIoU、Alpha-IoU、SIoU、Focal-EIOU替换CIou
🚀🚀🚀前言
在上一篇文章使用了EIoU、Alpha-IoU、SIoU、Focal-EIOU替换yolov5中默认的CIou损失,发现Focal-EIOU对于钢轨表面缺陷识别的提升效果最好,将map@0.5提升到了81.1%,这节使用Wise-IoU的三个版本(分别是v1、v2、v3)去替换CIOU损失,来观察不同类别的map@0.5变化。其中使用Wise-IoU v1方法将钢轨表面缺陷数据集的map@50从77.9%提升到了86.3%,将近提升了10个百分点。
一、1️⃣ Wise-IoU解读—基于动态非单调聚焦机制的边界框损失
1.1 🎓 介绍
🚀目标检测作为计算机视觉的核心问题,其检测性能依赖于损失函数的设计。边界框损失函数作为目标检测损失函数的重要组成部分,其良好的定义将为目标检测模型带来显著的性能提升。近年来的研究大多假设训练数据中的示例有较高的质量,致力于强化边界框损失的拟合能力。但我们注意到目标检测训练集中含有低质量示例,如果一味地强化边界框对低质量示例的回归,显然会危害模型检测性能的提升。Focal-EIoU v1 被提出以解决这个问题,但由于其聚焦机制是静态的,并未充分挖掘非单调聚焦机制的潜能。
⭐️基于这个观点,我们提出了动态非单调的聚焦机制,设计了 Wise-IoU (WIoU)。动态非单调聚焦机制使用“离群度”替代 IoU 对锚框进行质量评估,并提供了明智的梯度增益分配策略。该策略在降低高质量锚框的竞争力的同时,也减小了低质量示例产生的有害梯度。这使得 WIoU 可以聚焦于普通质量的锚框,并提高检测器的整体性能。将WIoU应用于最先进的单级检测器 YOLOv7 时,在 MS-COCO 数据集上的 AP-75 从 53.03% 提升到 54.50%
目前的Wise-IoU一共有三个版本分别是v1、v2、v3=
1.2 ✨WIOU解决的问题
🔥在数据标准的过程中,存在一下物体标准的不够正确,会有一些目标物体标注的质量很差,如下:

一个性能良好的模型在为低质量示例生成高质量锚框时会产生较大的
L
I
o
U
\mathcal{L}_{I o U}
LIoU(iou损失)。如果单调 FM 为这些锚框分配较大的梯度增益,则模型的学习将受到损害。
在性能提升上,数据集的标注质量越差 (当然差到一定程度就不叫数据集了),WIoU 相对其它边界框损失的表现越好。
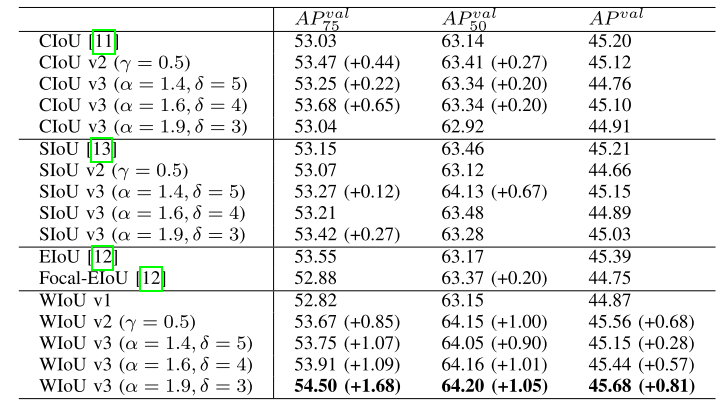
1.3 ⭐️论文实验结果
☀️CIoU、SIoU 的 v2 使用和 WIoU v2 一致的单调聚焦机制,v3 使用和 WIoU v3 一致的动态非单调聚焦机制,详见论文的消融实验,在计算速度上,WIoU 所增加的计算成本主要在于聚焦系数的计算、IoU 损失的均值统计。在实验条件相同时,WIoU 因为没有对纵横比进行计算反而有更快的速度,WIoU 的计算耗时为 CIoU 的 87.2%。
对比CIOU和SIOU等方法,WIOU的AP50要优于之前的边界框损失。
1.4 🎯论文方法
🚀该本文所涉及的聚焦机制有以下几种:
- 静态:当边界框的 IoU 为某一指定值时有最高的梯度增益,如 Focal EIoU v1
- 动态:享有最高梯度增益的边界框的条件处于动态变化中,如 WIoU v3
- 单调:梯度增益随损失值的增加而单调增加,如 Focal loss
- 非单调:梯度增益随损失值的增加呈非单调变化
WIoU v1 构造了基于注意力的边界框损失,WIoU v2 和 v3 则是在此基础上通过构造梯度增益 (聚焦系数) 的计算方法来附加聚焦机制。
1.4.1☀️Wise-IoU v1
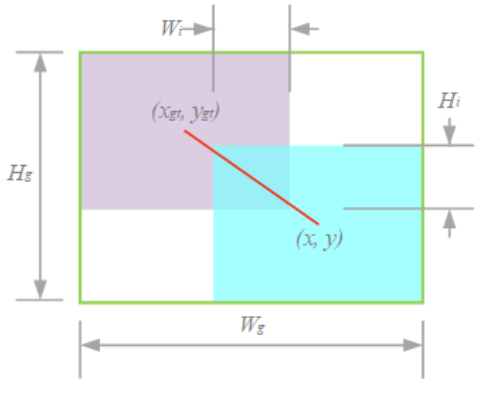
由于训练数据不可避免地包含低质量示例,距离和长宽比等几何因素会加剧对低质量示例的惩罚,从而降低模型的泛化性能。一个好的损失函数应该在锚框与目标框重合良好时削弱几何因素的惩罚,并且较少的训练干预将使模型获得更好的泛化能力。基于此,我们构建距离注意力,并获得具有两层注意力机制的WIoU v1:
- R W IoU ∈ [ 1 , e ) \mathcal{R}_{W \text { IoU }} \in[1, e) RW IoU ∈[1,e) :显著放大普通质量锚框的 L I o U \mathcal{L}_{I o U} LIoU。
- L I o U ∈ [ 0 , 1 ] \mathcal{L}_{I o U} \in[0,1] LIoU∈[0,1]:显着降低高质量anchor box的RWIoU,并且当anchor box与目标框重合良好时,它更注重中心点之间的距离。
L W I o U v 1 = R W I o U L I o U R W I o U = exp ( ( x − x g t ) 2 + ( y − y g t ) 2 ( W g 2 + H g 2 ) ∗ ) \begin{aligned}&\mathcal{L}_{WIoUv1}=\mathcal{R}_{WIoU}\mathcal{L}_{IoU}\\&\mathcal{R}_{WIoU}=\exp(\frac{(x-x_{gt})^2+(y-y_{gt})^2}{(W_g^2+H_g^2)^*})\end{aligned} LWIoUv1=RWIoULIoURWIoU=exp((Wg2+Hg2)∗(x−xgt)2+(y−ygt)2)
其中,Wg,Hg是最小的封闭框的大小。为了防止RWIoU产生阻碍收敛的梯度,Wg,Hg从计算图中分离出来(上标∗表示此操作)。因为它有效地消除了阻碍收敛的因素,所以没有引入新的度量,比如宽高比。
1.4.2☀️Wise-IoU v2
🚀Focal Loss 设计了一种针对交叉熵的单调聚焦机制,有效降低了简单示例对损失值的贡献。这使得模型能够聚焦于困难示例,获得分类性能的提升。该论文类似地构造了单调聚焦系数
L
I
o
U
γ
∗
\mathcal{L}_{IoU}^{\gamma*}
LIoUγ∗和
L
W
I
o
U
v
1
\mathcal{L}_{WIoUv1}
LWIoUv1。
L
W
I
o
U
v
2
=
L
I
o
U
γ
∗
L
W
I
o
U
v
1
,
γ
>
0
\mathcal{L}_{WIoUv2}=\mathcal{L}_{IoU}^{\gamma*}\mathcal{L}_{WIoUv1},\gamma>0
LWIoUv2=LIoUγ∗LWIoUv1,γ>0
由于增加了聚焦系数,WIoU v2反向传播的梯度也发生了变化:
∂
L
W
I
o
U
v
2
∂
L
I
o
U
=
L
I
o
U
γ
∗
∂
L
W
I
o
U
v
1
∂
L
I
o
U
,
γ
>
0
\frac{\partial\mathcal{L}_{WIoUv2}}{\partial\mathcal{L}_{IoU}}=\mathcal{L}_{IoU}^{\gamma*}\frac{\partial\mathcal{L}_{WIoUv1}}{\partial\mathcal{L}_{IoU}},\gamma>0
∂LIoU∂LWIoUv2=LIoUγ∗∂LIoU∂LWIoUv1,γ>0
❗️注意,梯度增益为
r
=
L
I
o
U
γ
∗
∈
[
0
,
1
]
r=\mathcal{L}_{IoU}^{\gamma*}\in[0,1]
r=LIoUγ∗∈[0,1]。在模型训练过程中,梯度增益随着
L
I
o
U
\mathcal{L}_{I o U}
LIoU的减小而减小,导致训练后期收敛速度较慢。因此,引入
L
I
o
U
\mathcal{L}_{I o U}
LIoU均值作为归一化因子:
L
W
I
o
U
v
2
=
(
L
I
o
U
∗
L
I
o
U
‾
)
γ
L
W
I
o
U
v
1
\mathcal{L}_{WIoUv2}=(\frac{\mathcal{L}_{IoU}^*}{\overline{\mathcal{L}_{IoU}}})^\gamma\mathcal{L}_{WIoUv1}
LWIoUv2=(LIoULIoU∗)γLWIoUv1
🔥其中 L I o U ‾ \overline{{\mathcal{L}_{IoU}}} LIoU是具有动量m的指数移动平均值。动态更新归一化因子使梯度增益 r = ( L I o U ∗ L I o U ‾ ) γ r=(\frac{\mathcal{L}_{IoU}^{*}}{\overline{\mathcal{L}_{IoU}}})^{\gamma} r=(LIoULIoU∗)γ总体保持在高水平,这解决了训练后期收敛缓慢的问题。
1.4.3☀️Wise-IoU v3
动态非单调FM:锚框的离群度用
L
I
o
U
\mathcal{L}_{I o U}
LIoU与
L
I
o
U
‾
\overline{{\mathcal{L}_{IoU}}}
LIoU的比值表示:
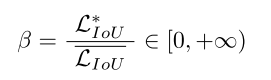
🚀离群值小意味着锚框是高质量的。我们为其分配一个小的梯度增益,以便将== BBR (边界框回归)==集中在普通质量的锚框上。此外,为异常值较大的锚框分配较小的梯度增益将有效防止低质量示例产生较大的有害梯度。我们使用 β 构造一个非单调聚焦系数并将其应用于 WIoU v1:
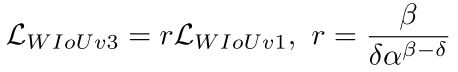
离群度β和梯度增益r的映射,由超参数α、δ控制。不同的超参数可能适用于不同的模型和数据集,需要自行调整 _scaled_loss 的缺省值以找到最优解。
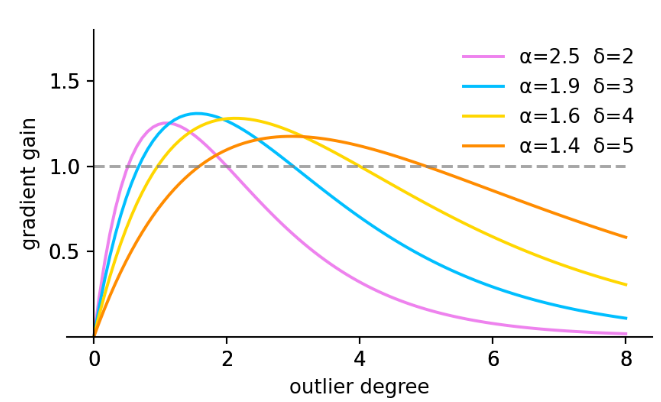
其中,当 β = δ 时,δ 使得 r = 1。如图所示,当锚框的离群度满足β=C(C为常数值)时,锚框将享有最高的梯度增益。由于
L
I
o
U
\mathcal{L}_{I o U}
LIoU是动态的,因此锚框的质量划分标准也是动态的,这使得 WIoU v3 能够在每一个时刻做出最符合当前情况的梯度增益分配策略。
二、2️⃣如何添加WIOU损失函数
2.1 🎓 修改bbox_iou函数
📌首先找到utils文件夹下的metrics.py文件,然后找到该python文件下的bbox_iou函数
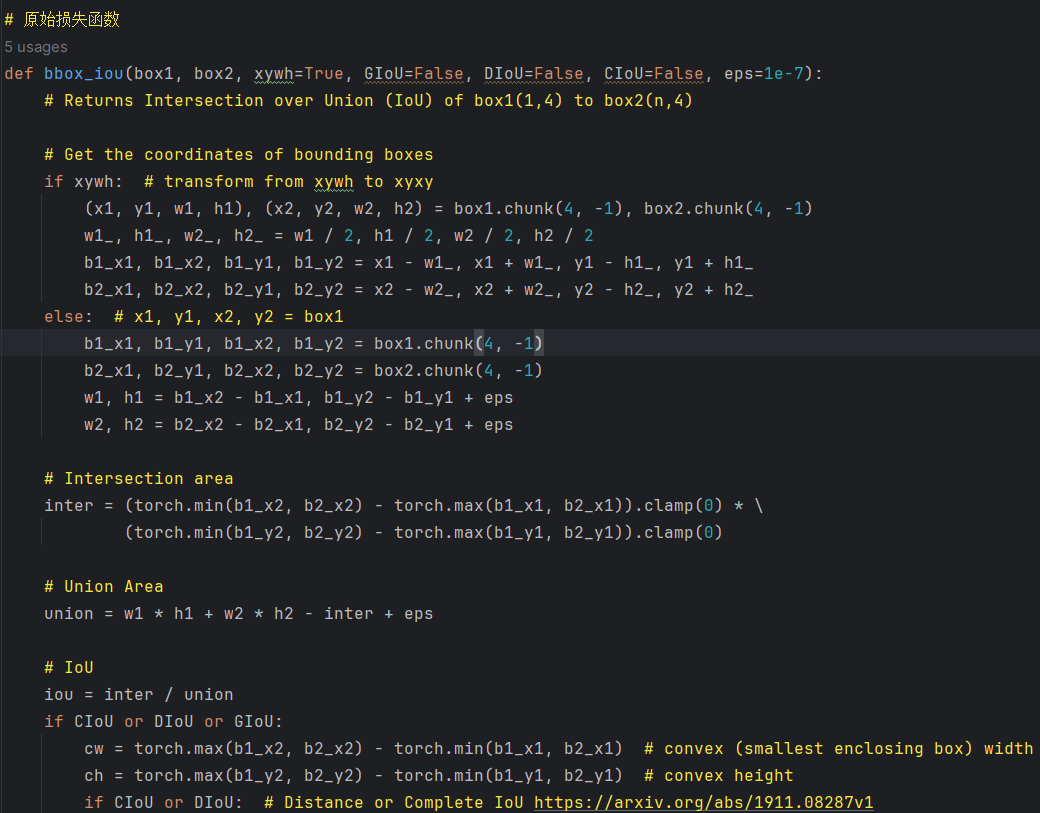
📌然后将原始的bbox_iou函数代码注释掉,替换成如下代码,分别是WIoU_Scale类和bbox_iou函数,其中WIoU_Scale类是相关配置参数,需要注意monotonous这个参数,当其设置不同参数所表示的WIoU的不同版本。
- monotonous =None:表示Wise-IoU v1
- monotonous =True:表示Wise-IoU v2
- monotonous =False:表示Wise-IoU v3
class WIoU_Scale:
''' monotonous: {
None: origin v1
True: monotonic FM v2
False: non-monotonic FM v3
}
momentum: The momentum of running mean'''
iou_mean = 1.
monotonous = False
_momentum = 1 - 0.5 ** (1 / 7000)
_is_train = True
def __init__(self, iou):
self.iou = iou
self._update(self)
@classmethod
def _update(cls, self):
if cls._is_train: cls.iou_mean = (1 - cls._momentum) * cls.iou_mean + \
cls._momentum * self.iou.detach().mean().item()
@classmethod
def _scaled_loss(cls, self, gamma=1.9, delta=3):
if isinstance(self.monotonous, bool):
if self.monotonous:
return (self.iou.detach() / self.iou_mean).sqrt()
else:
beta = self.iou.detach() / self.iou_mean
alpha = delta * torch.pow(gamma, beta - delta)
return beta / alpha
return 1
def bbox_iou(box1, box2, xywh=True, GIoU=False, DIoU=False, CIoU=False, SIoU=False, EIoU=False, WIoU=False, Focal=False, alpha=1, gamma=0.5, scale=False, eps=1e-7):
# Returns Intersection over Union (IoU) of box1(1,4) to box2(n,4)
# Get the coordinates of bounding boxes
if xywh: # transform from xywh to xyxy
(x1, y1, w1, h1), (x2, y2, w2, h2) = box1.chunk(4, -1), box2.chunk(4, -1)
w1_, h1_, w2_, h2_ = w1 / 2, h1 / 2, w2 / 2, h2 / 2
b1_x1, b1_x2, b1_y1, b1_y2 = x1 - w1_, x1 + w1_, y1 - h1_, y1 + h1_
b2_x1, b2_x2, b2_y1, b2_y2 = x2 - w2_, x2 + w2_, y2 - h2_, y2 + h2_
else: # x1, y1, x2, y2 = box1
b1_x1, b1_y1, b1_x2, b1_y2 = box1.chunk(4, -1)
b2_x1, b2_y1, b2_x2, b2_y2 = box2.chunk(4, -1)
w1, h1 = b1_x2 - b1_x1, (b1_y2 - b1_y1).clamp(eps)
w2, h2 = b2_x2 - b2_x1, (b2_y2 - b2_y1).clamp(eps)
# Intersection area
inter = (b1_x2.minimum(b2_x2) - b1_x1.maximum(b2_x1)).clamp(0) * \
(b1_y2.minimum(b2_y2) - b1_y1.maximum(b2_y1)).clamp(0)
# Union Area
union = w1 * h1 + w2 * h2 - inter + eps
if scale:
self = WIoU_Scale(1 - (inter / union))
# IoU
# iou = inter / union # ori iou
iou = torch.pow(inter/(union + eps), alpha) # alpha iou
if CIoU or DIoU or GIoU or EIoU or SIoU or WIoU:
cw = b1_x2.maximum(b2_x2) - b1_x1.minimum(b2_x1) # convex (smallest enclosing box) width
ch = b1_y2.maximum(b2_y2) - b1_y1.minimum(b2_y1) # convex height
if CIoU or DIoU or EIoU or SIoU or WIoU: # Distance or Complete IoU https://arxiv.org/abs/1911.08287v1
c2 = (cw ** 2 + ch ** 2) ** alpha + eps # convex diagonal squared
rho2 = (((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2 + (b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4) ** alpha # center dist ** 2
if CIoU: # https://github.com/Zzh-tju/DIoU-SSD-pytorch/blob/master/utils/box/box_utils.py#L47
v = (4 / math.pi ** 2) * (torch.atan(w2 / h2) - torch.atan(w1 / h1)).pow(2)
with torch.no_grad():
alpha_ciou = v / (v - iou + (1 + eps))
if Focal:
return iou - (rho2 / c2 + torch.pow(v * alpha_ciou + eps, alpha)), torch.pow(inter/(union + eps), gamma) # Focal_CIoU
else:
return iou - (rho2 / c2 + torch.pow(v * alpha_ciou + eps, alpha)) # CIoU
elif EIoU:
rho_w2 = ((b2_x2 - b2_x1) - (b1_x2 - b1_x1)) ** 2
rho_h2 = ((b2_y2 - b2_y1) - (b1_y2 - b1_y1)) ** 2
cw2 = torch.pow(cw ** 2 + eps, alpha)
ch2 = torch.pow(ch ** 2 + eps, alpha)
if Focal:
return iou - (rho2 / c2 + rho_w2 / cw2 + rho_h2 / ch2), torch.pow(inter/(union + eps), gamma) # Focal_EIou
else:
return iou - (rho2 / c2 + rho_w2 / cw2 + rho_h2 / ch2) # EIou
elif SIoU:
# SIoU Loss https://arxiv.org/pdf/2205.12740.pdf
s_cw = (b2_x1 + b2_x2 - b1_x1 - b1_x2) * 0.5 + eps
s_ch = (b2_y1 + b2_y2 - b1_y1 - b1_y2) * 0.5 + eps
sigma = torch.pow(s_cw ** 2 + s_ch ** 2, 0.5)
sin_alpha_1 = torch.abs(s_cw) / sigma
sin_alpha_2 = torch.abs(s_ch) / sigma
threshold = pow(2, 0.5) / 2
sin_alpha = torch.where(sin_alpha_1 > threshold, sin_alpha_2, sin_alpha_1)
angle_cost = torch.cos(torch.arcsin(sin_alpha) * 2 - math.pi / 2)
rho_x = (s_cw / cw) ** 2
rho_y = (s_ch / ch) ** 2
gamma = angle_cost - 2
distance_cost = 2 - torch.exp(gamma * rho_x) - torch.exp(gamma * rho_y)
omiga_w = torch.abs(w1 - w2) / torch.max(w1, w2)
omiga_h = torch.abs(h1 - h2) / torch.max(h1, h2)
shape_cost = torch.pow(1 - torch.exp(-1 * omiga_w), 4) + torch.pow(1 - torch.exp(-1 * omiga_h), 4)
if Focal:
return iou - torch.pow(0.5 * (distance_cost + shape_cost) + eps, alpha), torch.pow(inter/(union + eps), gamma) # Focal_SIou
else:
return iou - torch.pow(0.5 * (distance_cost + shape_cost) + eps, alpha) # SIou
elif WIoU:
if Focal:
raise RuntimeError("WIoU do not support Focal.")
elif scale:
return getattr(WIoU_Scale, '_scaled_loss')(self), (1 - iou) * torch.exp((rho2 / c2)), iou # WIoU https://arxiv.org/abs/2301.10051
else:
return iou, torch.exp((rho2 / c2)) # WIoU v1
if Focal:
return iou - rho2 / c2, torch.pow(inter/(union + eps), gamma) # Focal_DIoU
else:
return iou - rho2 / c2 # DIoU
c_area = cw * ch + eps # convex area
if Focal:
return iou - torch.pow((c_area - union) / c_area + eps, alpha), torch.pow(inter/(union + eps), gamma) # Focal_GIoU https://arxiv.org/pdf/1902.09630.pdf
else:
return iou - torch.pow((c_area - union) / c_area + eps, alpha) # GIoU https://arxiv.org/pdf/1902.09630.pdf
if Focal:
return iou, torch.pow(inter/(union + eps), gamma) # Focal_IoU
else:
return iou # IoU
🔥温馨提示WIOU和Focal不能同时使用,两者是互斥的,所以不能使用Focal项,在代码中也体现出来。
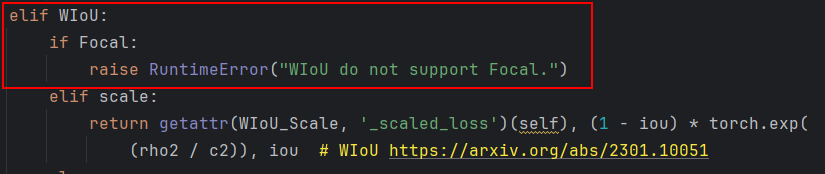
2.2 ✨修改__call__中iou函数
📌找到utils文件夹下面的loss.py损失函数计算文件,在该文件中找到ComputeLoss类下面的__call__函数,在__call__()函数里面找到红框部分的代码。
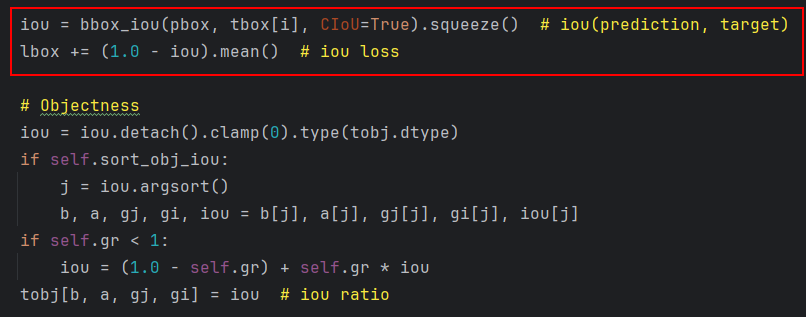
📌将红框内容替换成如下代码:
# ============替换WIoU之后的代码====================
iou = bbox_iou(pbox, tbox[i], WIoU=True, scale=True)
if type(iou) is tuple:
if len(iou) == 2:
lbox += (iou[1].detach().squeeze() * (1 - iou[0].squeeze())).mean()
iou = iou[0].squeeze()
else:
lbox += (iou[0] * iou[1]).mean()
iou = iou[2].squeeze()
else:
lbox += (1.0 - iou.squeeze()).mean() # iou loss
iou = iou.squeeze()
# ==============================================
❗️注意:scale需要设置为True,它是wiou中的一个缩放参数
三、3️⃣实验测试结果
🚀 这里一共做了三次实验,分别是Wise-IoU v1、Wise-IoU v2、Wise-IoU v3三个不同版本方法训练钢轨表面疵点的结果。
➤原始CIOU实验结果:
F1置信度分数为0.71、map@0.5=0.779
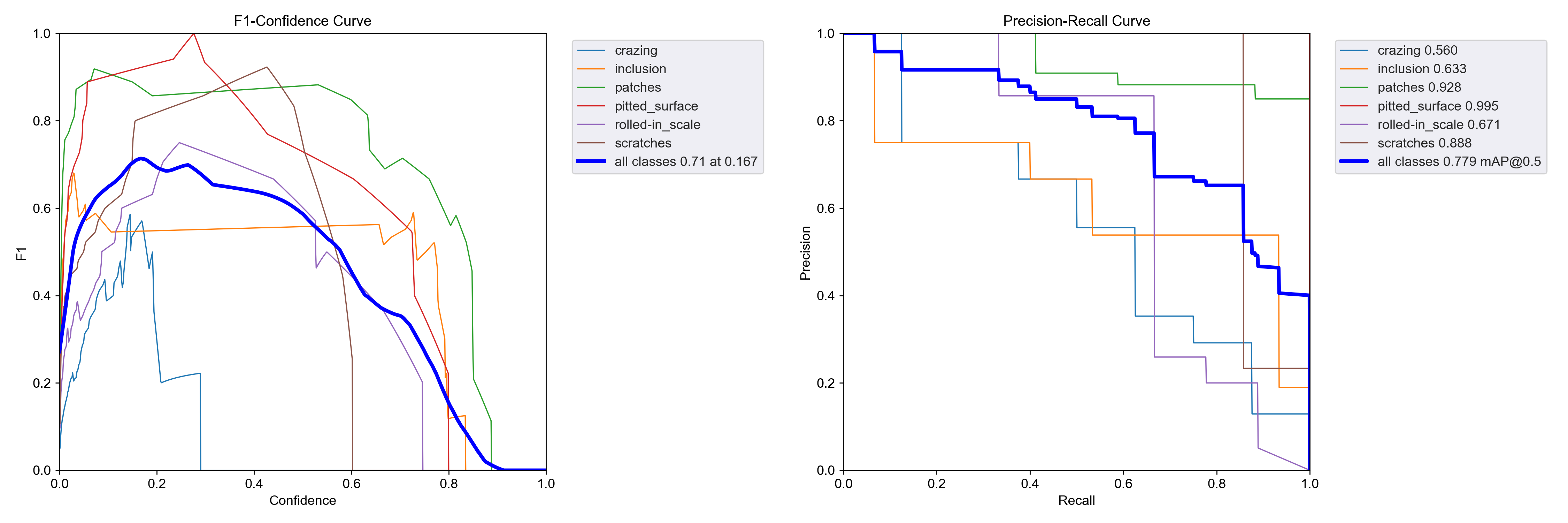
➤Wise-IoU v1实验结果:
F1置信度分数为0.72、map@0.5=0.863,F1置信度分数变化不大,但是map值增加最多。
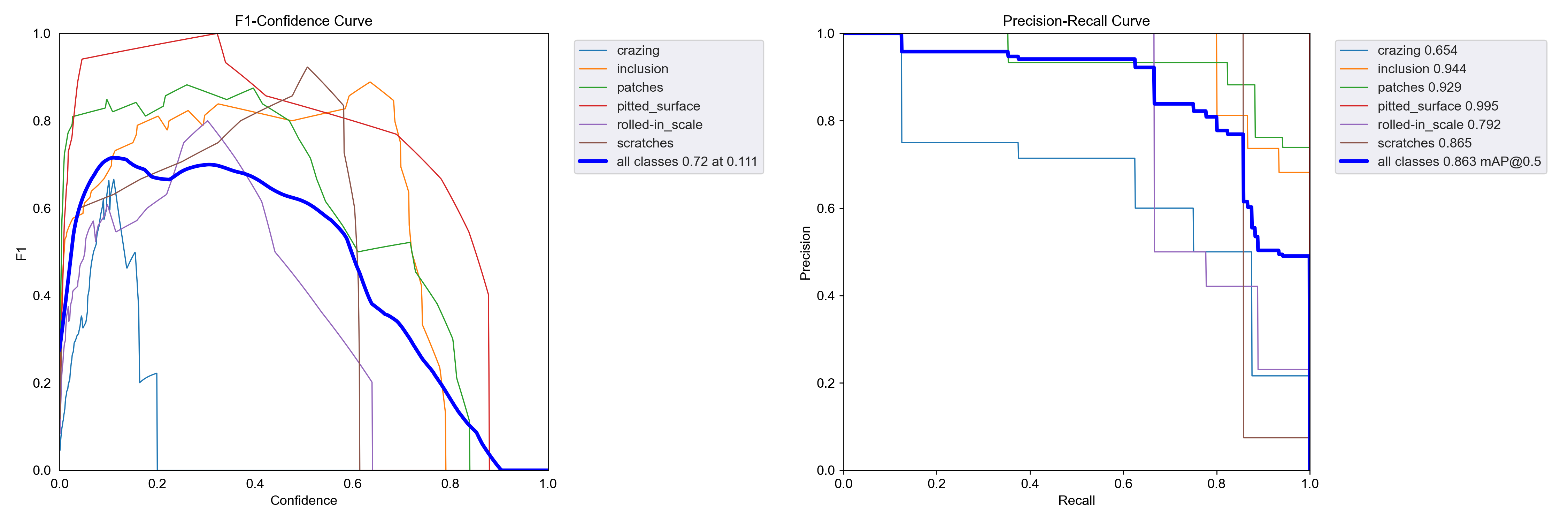
➤Wise-IoU v2实验结果:
F1置信度分数为0.76、map@0.5=0.841,虽然map值没有 v1提升的那么大,但是F1置信度分数增长最多。
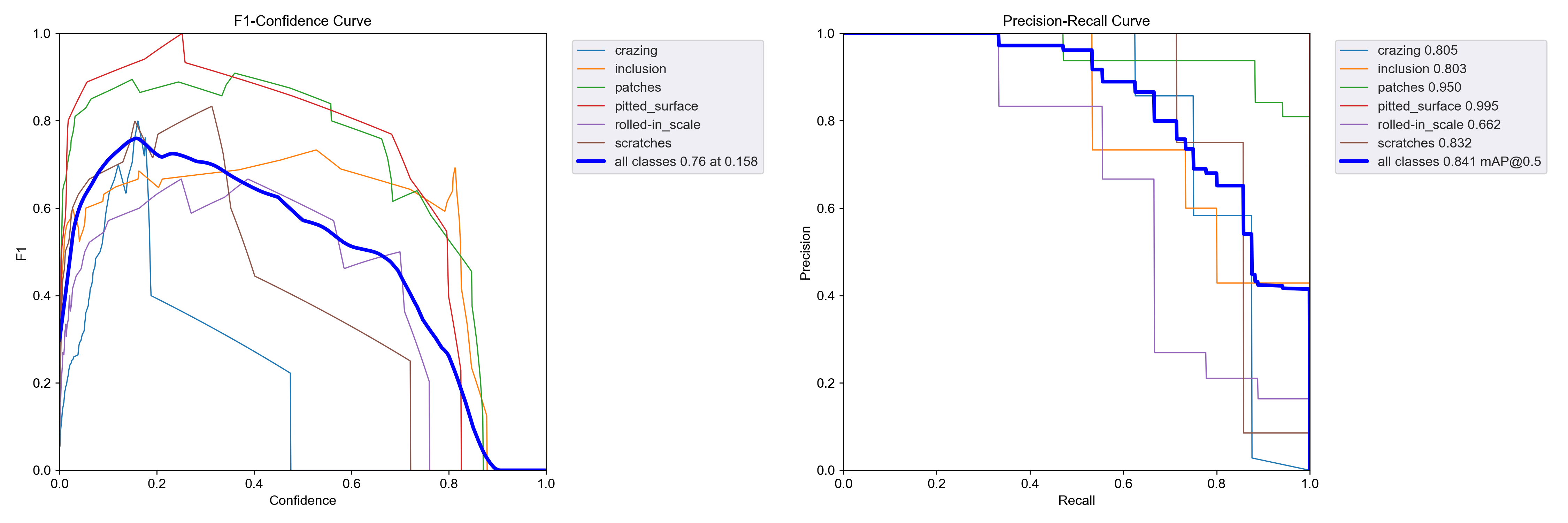
➤Wise-IoU v3实验结果:
F1置信度分数为0.74、map@0.5=0.844。
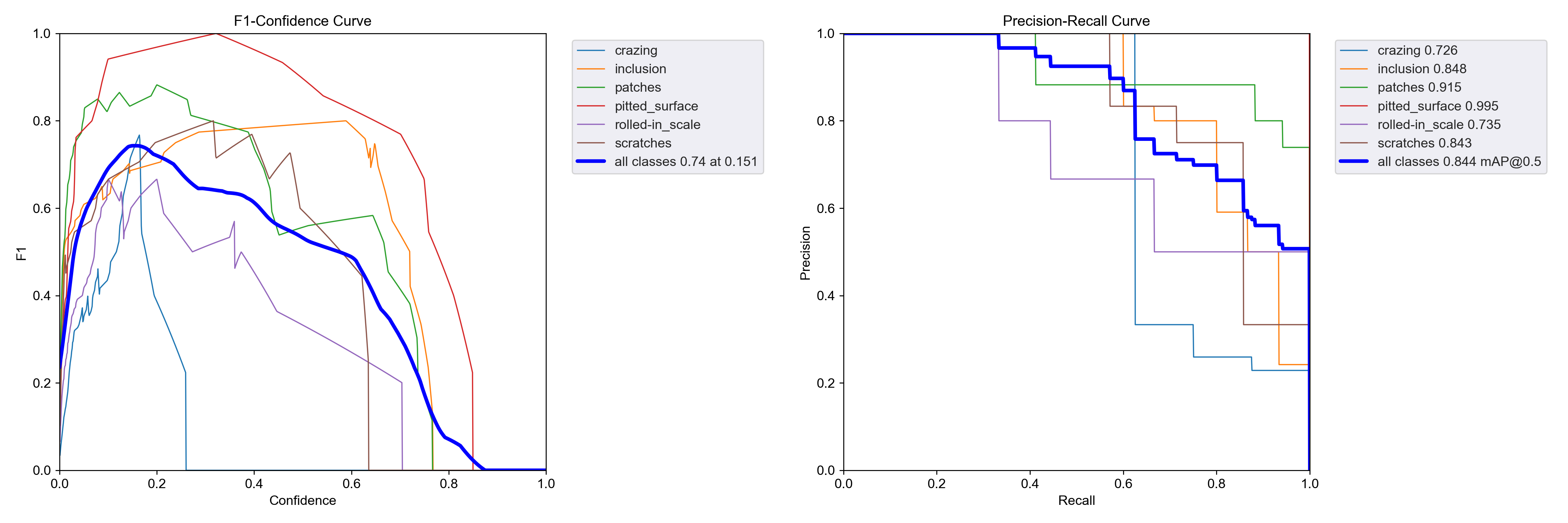
➤总结:
🚀 不管是Wise-IoU 哪一个版本,对于数据集的精确度、召回率、map值等指标都有所提升。












