文章目录
1. 前言
GPT-1 到 GPT-3 的论文请参考:
《详解GPT-1到GPT-3的论文亮点以及实验结论》
GPT-4 论文原文《GPT-4 Technical Report》 GPT-4 这篇论文直接以“技术报告”为标题,虽然来自 OpenAI,但是后续并未 “Open”,原文提到:
文章没有涉及 GPT-4 模型的技术细节,主要重点是 GPT-4 的能力、限制和安全特性。
2. 总述
GPT-4,大型多模态模型,具备处理图像和文本输入并生成文本输出的能力。
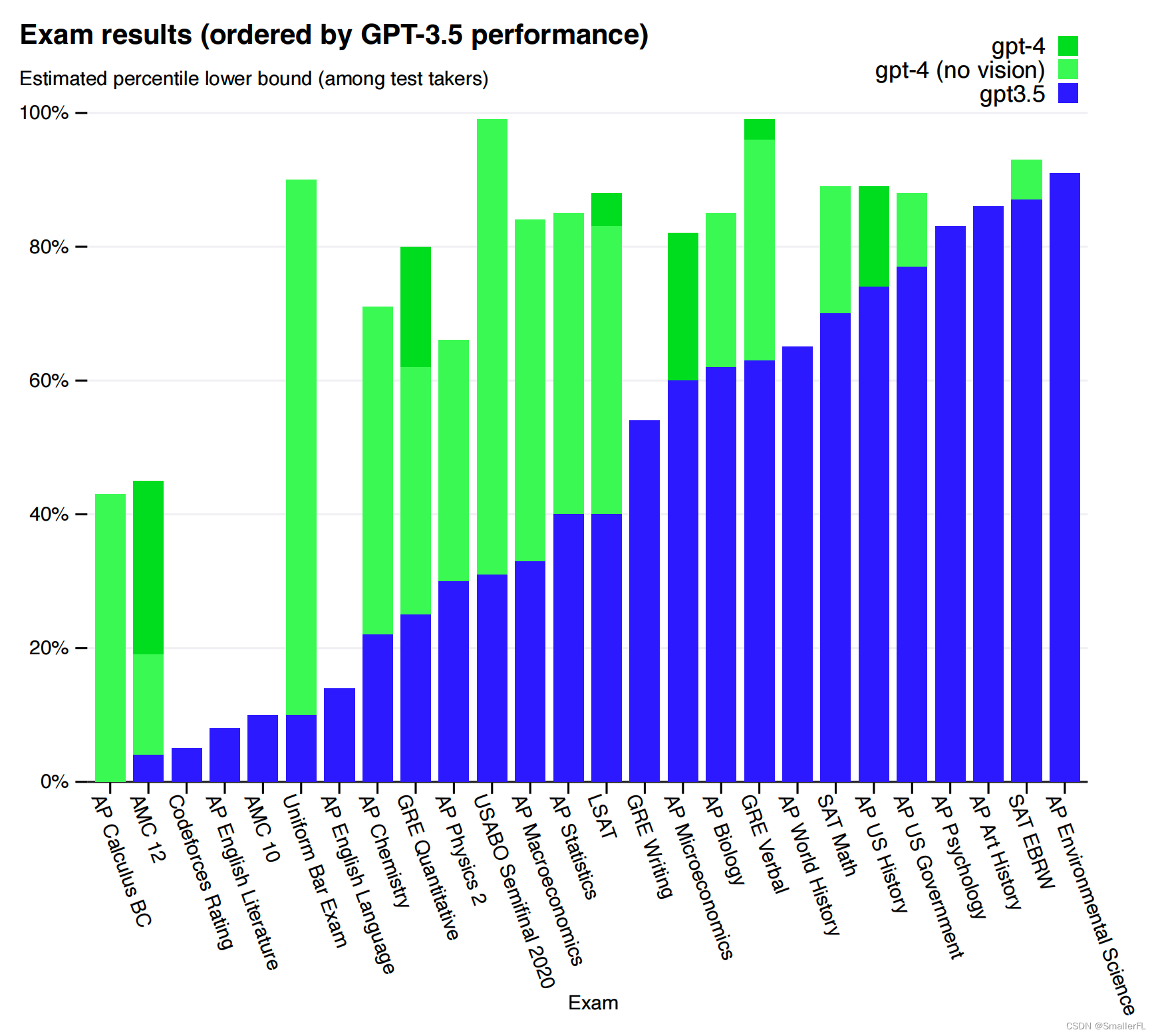
研究人员将 GPT-4 应用于为人类设计的各种考试中进行评估,结果显示 GPT-4 表现出色,通常超过绝大多数人类测试者的得分。例如,在一项模拟的律师资格考试中,GPT-4 的成绩处于顶级10%的水平,而相比之下,之前的 GPT-3.5 则处于底部10%。
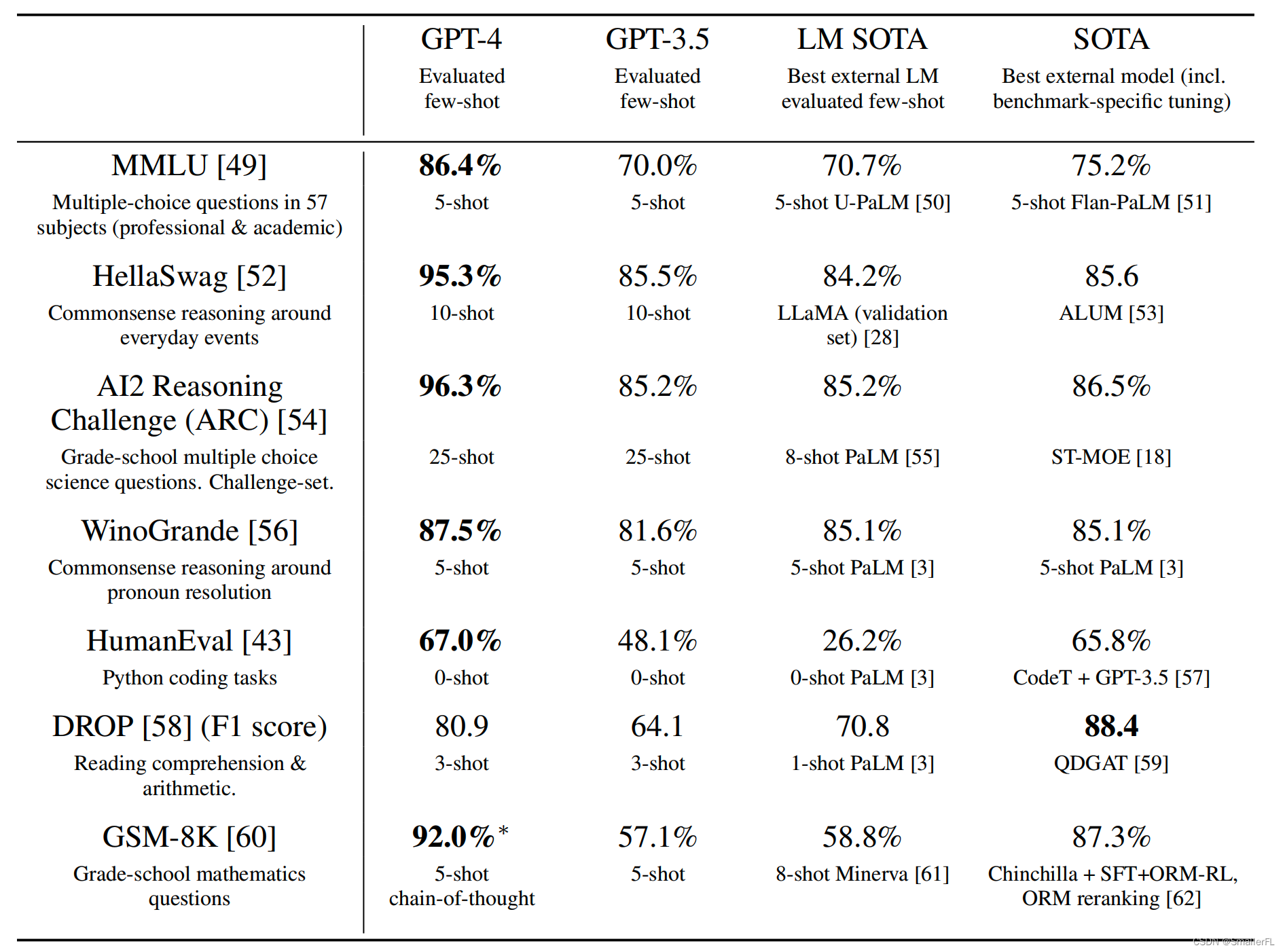
此外,GPT-4 在传统的自然语言处理(NLP)基准测试上也超越了之前的大规模语言模型和其他多数模型。
OpenAI 在准备 GPT-4 部署时采用了全面的安全流程,包括从模型级别的改变、产品和系统层面的干预措施(比如监控和政策制定),到与外部专家的合作。
3. 可预测缩放(Predictable Scaling)
Predictable Scaling 指的是构建一个能够在多个尺度上表现稳定、可预测的深度学习堆栈。对于像 GPT-4 这样的大规模训练运行,进行细致的模型特定调优并不现实,因为资源消耗巨大且难以实施。
为解决这个问题,团队专门开发了一套基础设施和优化方法,这些方法在不同的计算规模上都能展现出非常稳定的性能。这意味着即使在远小于 GPT-4 所需计算量(1,000至10,000倍)的小型模型进行训练,也能可靠地预测出 GPT-4 在某些方面的性能表现。
在具体实践中,团队通过应用如下技术手段实现了可预测缩放:
(1)损失预测:基于大量研究表明,经过适当训练的大规模语言模型的最终损失与其训练所用计算量之间存在幂律关系。因此,研究者利用较小规模模型训练获得的数据拟合了一个损失项的缩放定律,从而在 GPT-4 训练开始不久后,未使用任何中间结果的情况下,就能高精度预测出 GPT-4 的最终损失。
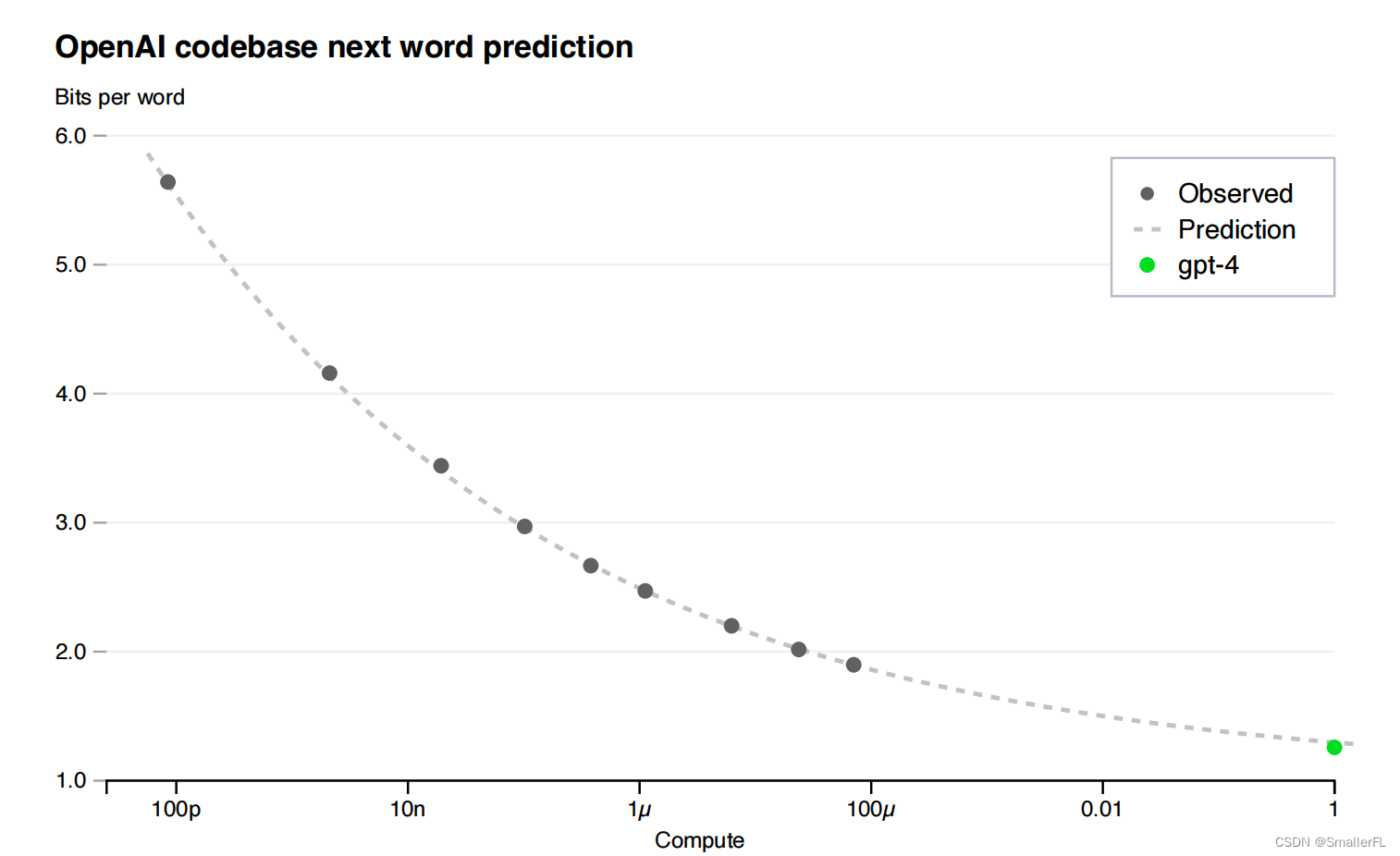
(2)HumanEval 上的能力扩展预测:除了预测最终损失,研究者还发展了预测模型能力的可解释性指标的方法。其中一个指标是 HumanEval 数据集的通过率。团队成功从原先1/1000的计算量训练的模型出发,通过外推法预测了 GPT-4 在 HumanEval 子集上的通过率。
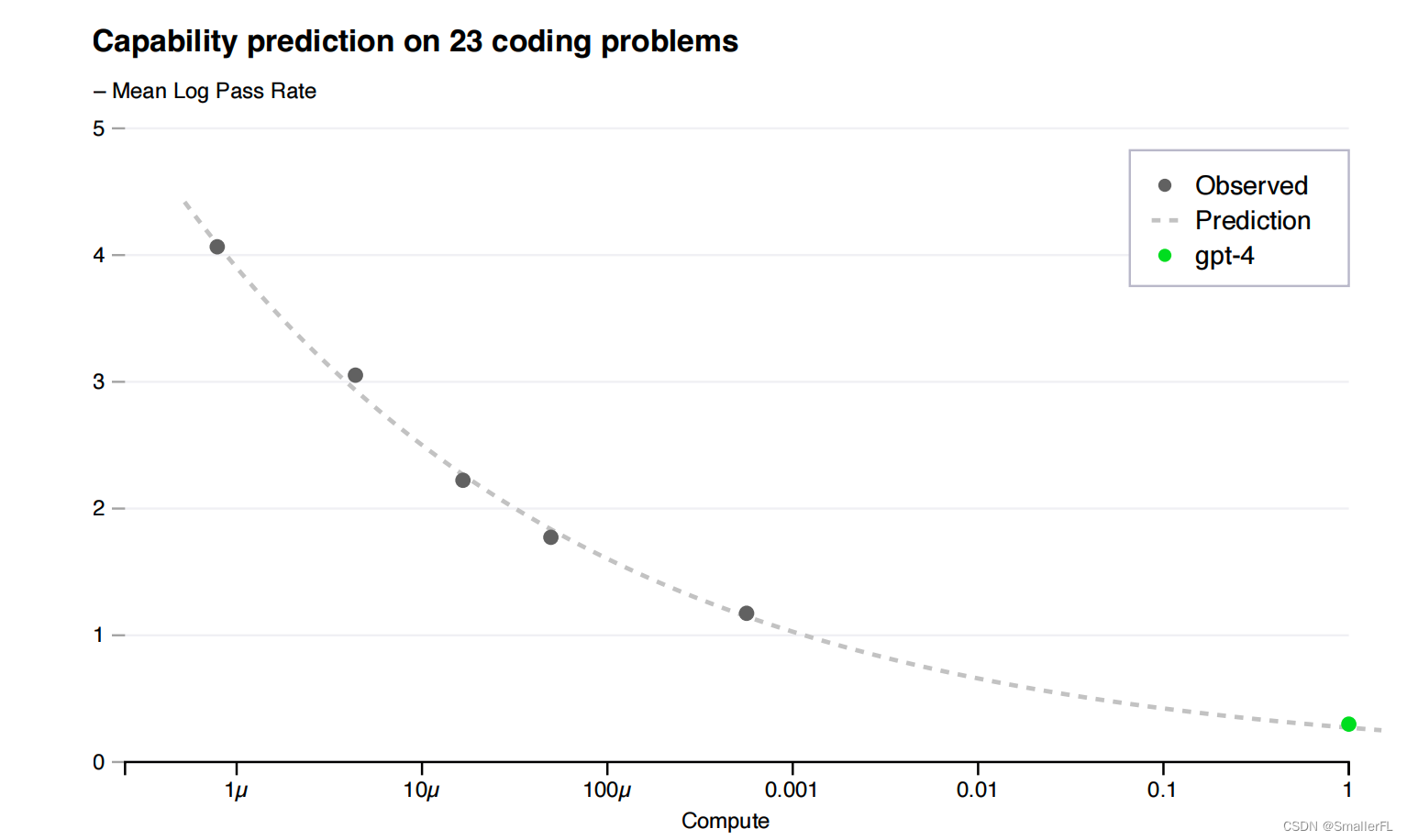
结论:这种可预测缩放方法使得研究者能提前了解模型的潜在性能。
4. 模型能力
GPT-4 的技术报告详述了模型在多样化的基准测试中所展现的能力。GPT-4 不仅能够处理纯文本输入,还能结合图像信息进行输入输出,这一特点使它在处理复杂的跨模态任务上具有强大的潜力。
(1)GPT 系列在专业考试上的评测对比
(2)GPT 系列在学术通用基准的得分对比
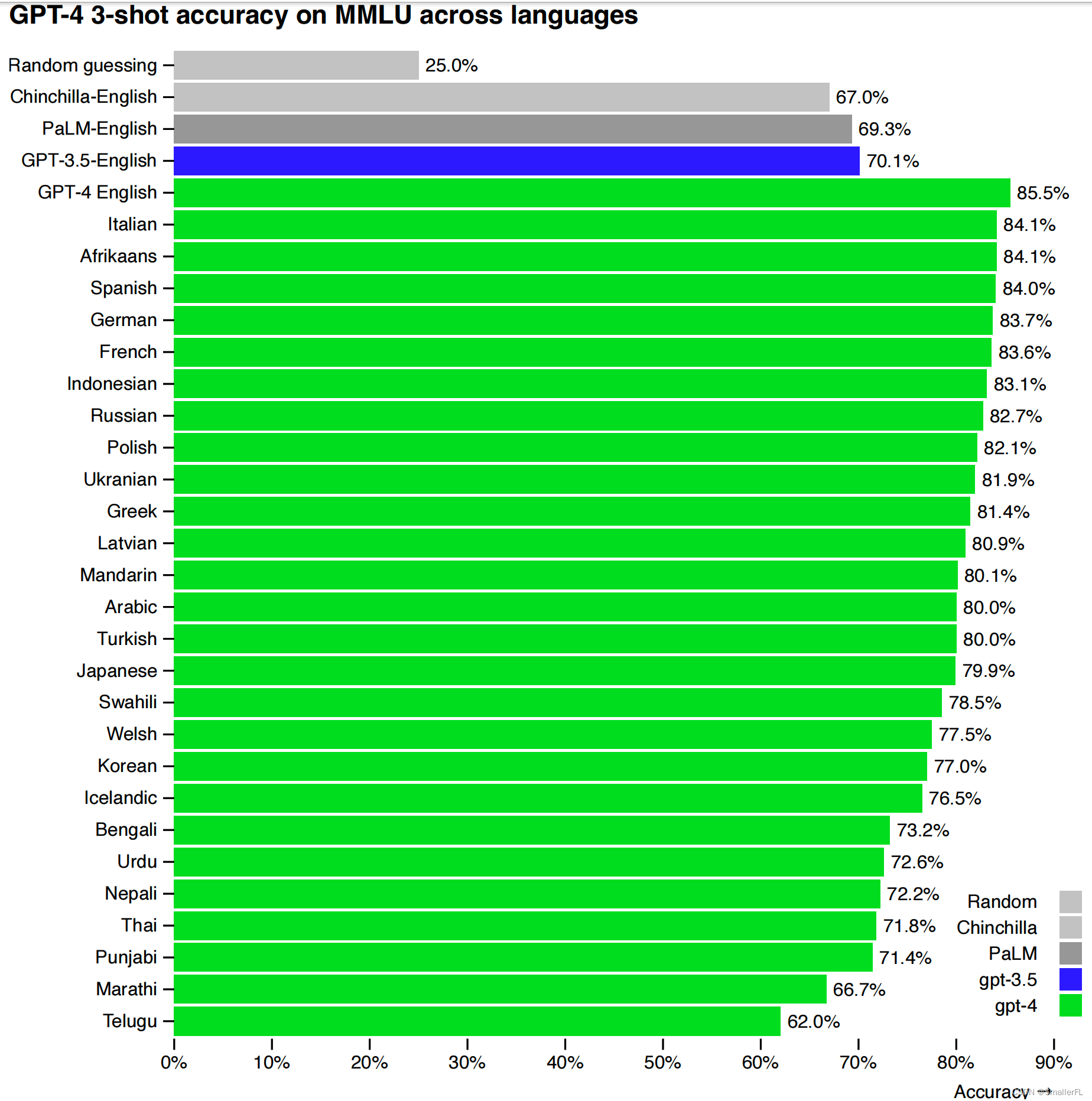
(3)GPT-4 3-shot 在 MMLU 多语言数据集的评测结果
(4)多模态之视觉识别

GPT-4:
...
这幅图中的幽默来自于把一个巨大的,过时的VGA接口连接到一个小巧的现代智能手机充电接口。
5. 风险和应对
大模型可能生成有害内容,如犯罪策划建议、仇恨言论等,这些都是早期版本模型在未施加足够安全控制时存在的典型风险。模型还会反映出社会中存在的偏见和世界观,这些内容可能偏离用户意图或普遍认可的价值观。此外,还能生成可能存在漏洞或易受攻击的代码。
如何应对:
(1)领域专家进行对抗性测试。OpenAI 聘请了超过50位来自不同专业领域的专家,包括长期人工智能对齐风险、网络安全、生物风险、国际安全等方面的专家,对 GPT-4 进行了对抗性测试。例如:

(2)模型辅助的流水线。在这种安全流程中,主要包含两大部分:
-
附加的安全相关 RLHF(强化学习) 训练提示:为了进一步优化 GPT-4 的行为准则,OpenAI 设计了一组额外的安全相关的训练提示,这些提示在 RLHF 精调过程中被用于指导模型,确保模型在遇到潜在风险或边缘情况时能做出更为审慎和恰当的反应。
-
基于规则的奖励模型:OpenAI 引入了基于规则的奖励模型(Rule-Based Reward Models, RBRMs),这些模型是一系列零样本的 GPT-4 分类器。在 RLHF 微调期间,这些分类器提供了额外的奖励信号给 GPT-4 策略模型,目标是针对模型在生成回应时的合规性和安全性进行强化。
例如:

(3)安全指标的改进。根据报告数据,在 RealToxicityPrompts 数据集上,GPT-4 仅在 0.73%的情况下生成有毒内容,而 GPT-3.5 的这一比例为 6.48%,表明毒性内容生成的频率大幅降低。
6. 结论
(1)GPT-4 是一个大型多模式模型。在某些困难的专业和学术基准上具有人类水平的性能。GPT-4 在 NLP任务集合上优于现有的大型语言模型,并且超过了绝大多数报道的最先进的系统(通常包括特定于任务的微调)
(2)多语言验证。在多种不同语言上, GPT-4 都具备高水平的能力
(3)可预测的缩放。验证了能在小模型下预测大模型的损失和能力
(4)风险和应对。GPT-4 带来了新的风险,讨论了一些应对方法,以了解和提高其安全性和一致性。
7. 参考
《GPT-4 Technical Report》
《详解GPT-1到GPT-3的论文亮点以及实验结论》
欢迎关注本人,我是喜欢搞事的程序猿; 一起进步,一起学习;
欢迎关注知乎:SmallerFL;










