本来准备空闲之余尝试用RPA软件抓取数据,【AI+RPA系列】1、利用AI+RPA提升工作效率 应用场景 , 最近工作项目有点忙, RPA实操系列可能会晚点了(自己真正实操后再写,copy别人的没啥意思)。这里简单整理下爬取网站或APP的几种常用技术方案。
1. RPA(Robotic Process Automation)
首先,我们来谈谈RPA。它其实就是一种机器人自动化技术,通过模拟人工操作来完成各种任务。想象一下,有一个机器人,可以代替你在网站或APP上点击、填写表单、抓取数据,是不是感觉非常酷炫?使用RPA,你甚至可以不需要编程知识,只要简单地录制你的操作步骤,机器人就能为你自动执行。不过,值得一提的是,RPA相对于其他爬虫方式来说,它的应用场景更多地集中在一些需要与现有系统进行交互的业务流程自动化上。
PRA软件很多,我前面文章有介绍,感兴趣的可以查阅。【AI+RPA系列】2、懒人必备,你的“自动化小助手”,顶级RPA软件盘点! 下面是我用影刀写的一个简单例子部分截图。
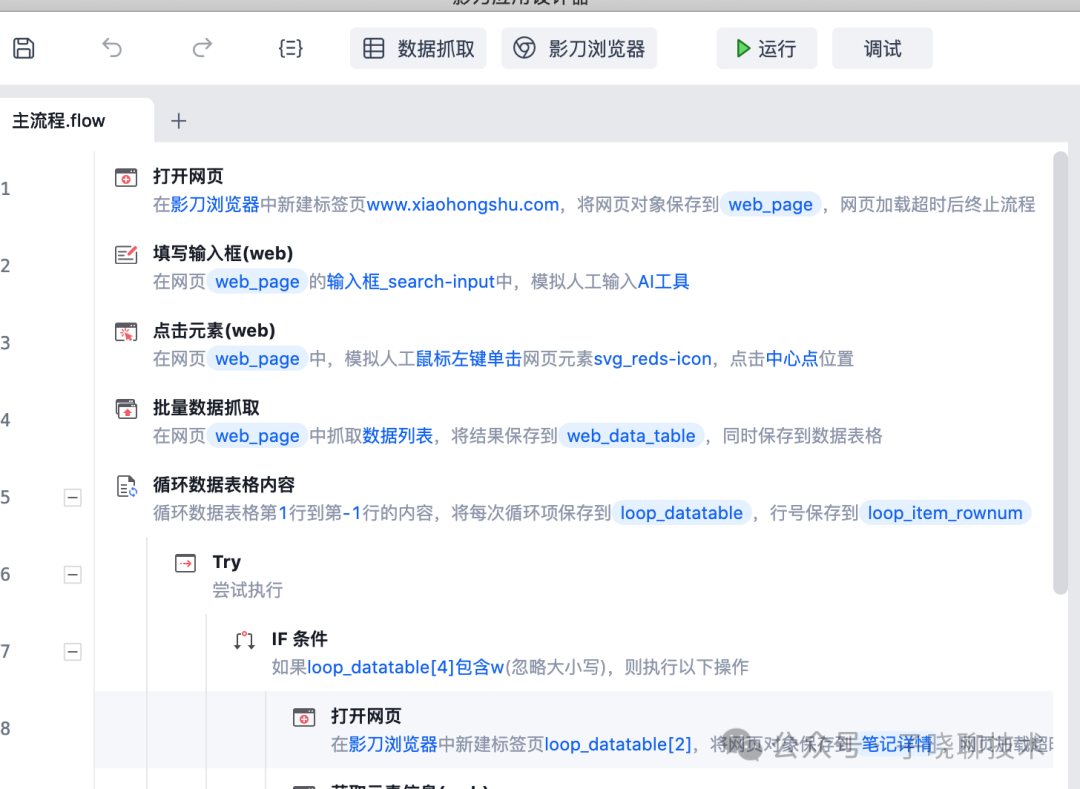
2. 抓包工具
接下来,我们来看看抓包工具。抓包工具主要用来捕获网络数据包,并分析其中的信息。通过这种方式,你可以轻松地获取网站和APP的数据,而且几乎可以捕获到所有的网络请求和响应。常见的抓包工具有Fiddler、Charles、Wireshark等。使用抓包工具,你可以深入了解网络通信的细节,轻松捕获到你想要的数据。下图是我mac的Charles截图界面。
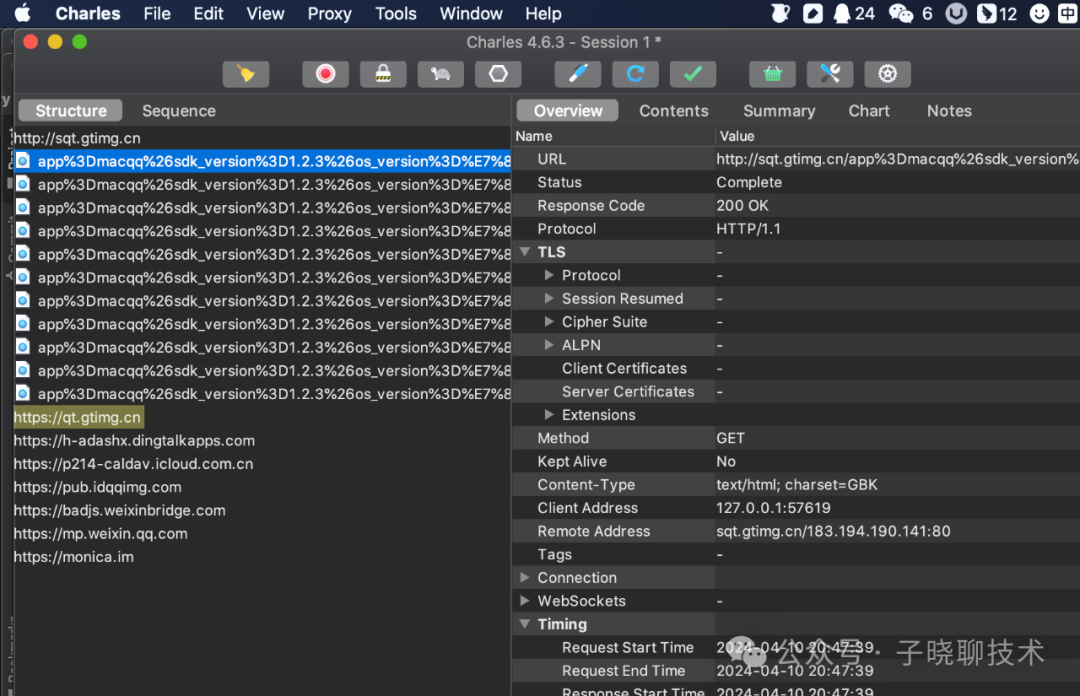
3. Python爬虫
最后,我们当然不能忘记Python爬虫。Python爬虫是一种非常强大的爬虫方式,它能够灵活地处理各种网页和APP的数据。有了Python爬虫,你可以轻松地获取网站上的信息,抓取APP中的数据,甚至进行数据分析和可视化。而且,Python爬虫的学习门槛相对较低,只要掌握了基本的编程知识,就可以开始使用了。当然,这也意味着它的应用场景非常广泛,无论是爬取网站、APP,还是进行数据分析,Python爬虫都能轻松胜任。
具体采用哪项具体技术,看网页的具体场景。比如一般静态网页基本 requests模块、BeautifulSoup模块就能搞定,也可以选择封装的crawler封框架(https://github.com/shuizhubocai/crawler)。 如果涉及到动态网页,一般采用selenium(不建议用这个,浏览器驱动版本坑比较多,比如google chrome版本升级啥的,驱动要跟着升级),playwright,drissionpage(国产之光,官方地址https://drissionpage.cn/)。
之前也小打小闹写过几篇python爬虫相关的文章
[python爬虫]怎么用 python爬取网页
[python爬虫]谷歌浏览器驱动安装及selenium的安装与使用selenium爬取简单的淘宝商品页
【python爬虫】python爬取豆瓣top250电影
【python爬虫】图形验证码识别的几种技术实现方案
【rpa机器人】python编写rpa机器人编码技术储备
总的来说,无论是使用RPA、抓包工具还是Python爬虫,它们都是非常强大的爬虫方式,能够帮助我们轻松获取网站和APP的数据。不过,在使用这些技术的时候,我们也需要注意一些法律和道德问题,避免侵犯他人的权益。希望通过今天的分享,能够给大家带来一些启发,让我们一起探索爬虫技术的奥秘!
原文链接:【技术揭秘】爬取网站或APP应用的几种常用方案:RPA、抓包工具、Python爬虫,你了解多少?










