一 Hive的搭建
1.1 准备好文件
1. apache-hive-3.1.2-bin.tar.gz
2.mysql-connector-java-8.0.29.jar
3.上传到linux中
1.2 安装
1.解压
tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /usr/local/soft/
2.重命名
mv apache-hive-3.1.2-bin hive-3.1.2
3.配置环境变量
进入/etc/profile文件下
export HIVE_HOME=/usr/local/soft/hive-3.1.2
export PATH=$PATH:$HIVE_HOME/bin
4.刷新一下
source /etc/profile
5.进入hive-3.1.2/conf目录下
将hive-default.xml.template这个文件复制一份,改名为hive-site.xml
6.修改hive-site.xml相关内容
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://master:3306/hive?useSSL=false&createDatabaseIfNotExist=true&characterEncoding=utf8&useUnicode=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://master:9083</value>
</property>
<property>
<name>hive.server2.enable.doAs</name>
<value>false</value>
</property>
<property>
<name>hive.querylog.location</name>
<value/>
</property>
(同上)
<property>
<name>hive.exec.local.scratchdir</name>
<value/>
</property>
(同上)
<property>
<name>hive.downloaded.resources.dir</name>
<value/>
</property>
</configuration>7.创建log4j.properties配置文件
# 将日志级别改成WARN,避免执行sql出现很多日志
log4j.rootLogger=WARN,CA
log4j.appender.CA=org.apache.log4j.ConsoleAppender
log4j.appender.CA.layout=org.apache.log4j.PatternLayout
log4j.appender.CA.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n%
8.上传mysql驱动到lib目录下
cp /usr/local/soft/jars/mysql-connector-java-8.0.29.jar ./
9.将hadoop的jline-0.9.94.jar的jar替换成hive的版本。
cp ./jline-2.12.jar /usr/local/soft/hadoop-3.1.1/share/hadoop/yarn/lib/
10初始化hive元数据库
schematool -dbType mysql -initSchema
1.3启动
1.3.1xhsell交互页面启动
1.先启动hadoop集群
2.后台启动元数据服务
nohup hive --service metastore &
3.输入hive命令即可进入xhsell交互界面
1.3.2JDBC启动
1.先将hadoop/etc/hadoop/core-site.xml文件追加两条数据
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
2.如果还有问题 关闭安全模式
3.将master中的hive复制一份给node1
4.在master中启动Hadoop集群,跟nohup hive --service metastore &
5.再启动 nohup hiveserver2 &
6.再在node1中启动 beeline -u jdbc:hive2://master:10000 -n root
1.3.3 命令行启动
1. hive -e "hive的命令"
例如 hive -e "show database;"
2. hive -f 文件名 (文件里面是hive的命令)
二 Hive的介绍
2.1hive的介绍
1.Hive本质是将SQL转换为MapReduce的任务进行运算,底层由HDFS来提供数据存储,说白了hive可以理解为一个将SQL转换为MapReduce的任务的工具,甚至更近一步说hive就是一个MapReduce客户端。
2.2 什么是hive
1、hive是数据仓库建模的工具之一。
2、可以向hive传入一条交互式的sql,在海量数据中查询分析得到结果的平台。
2.3 hive的优点
1、操作接口采用类sql语法,提供快速开发的能力(简单、容易上手)
2、避免了去写MapReduce,减少开发人员的学习成本
3、Hive的延迟性比较高,因此Hive常用于数据分析,适用于对实时性要求不高的场合
4、Hive 优势在于处理大数据,对于处理小数据没有优势,因为 Hive 的执行延迟比较高。(不断地开关JVM虚拟机)
5、Hive 支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
6、集群可自由扩展并且具有良好的容错性,节点出现问题SQL仍可以完成执行
7、如果直接使用hadoop的话,人员学习成本太高,项目要求周期太短,MapReduce实现复杂查询逻辑开发难度太大。如果使用hive的话,可以操作接口采用类SQL语法,提高开发能力,免去了写MapReduce,减少开发人员学习成本,功能扩展很方便(比如:开窗函数)。
2.4缺点
1、Hive的HQL表达能力有限
(1)迭代式算法无法表达 (反复调用,mr之间独立,只有一个map一个reduce,反复开关)
(2)数据挖掘方面不擅长
2、Hive 的效率比较低
(1)Hive 自动生成的 MapReduce 作业,通常情况下不够智能化
(2)Hive 调优比较困难,粒度较粗 (hql根据模板转成mapreduce,不能像自己编写mapreduce一样精细,无法控制在map处理数据还是在reduce处理数据)
2.5 hive的特点
1、可扩展性
Hive可以自由的扩展集群的规模,一般情况下不需要重启服务
2、延申性
Hive支持自定义函数,用户可以根据自己的需求来实现自己的函数
3、容错
即使节点出现错误,SQL仍然可以完成执行
2.6 hive于MySQL的区别
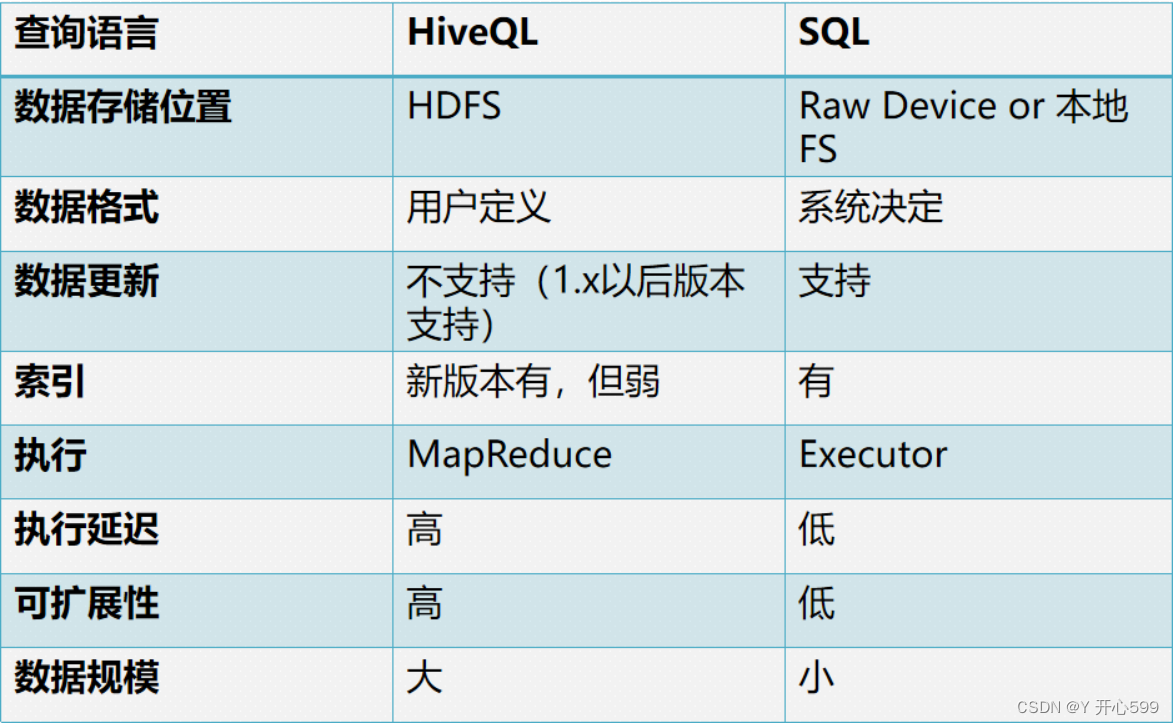
2.7 hive的应用场景
日志分析:大部分互联网公司使用hive进行日志分析,如百度、淘宝等。
统计一个网站一个时间段内的pv,uv,SKU,SPU,SKC
多维度数据分析(数据仓库)
海量结构化数据离线分析
构建数据仓库
2.8 hive的架构
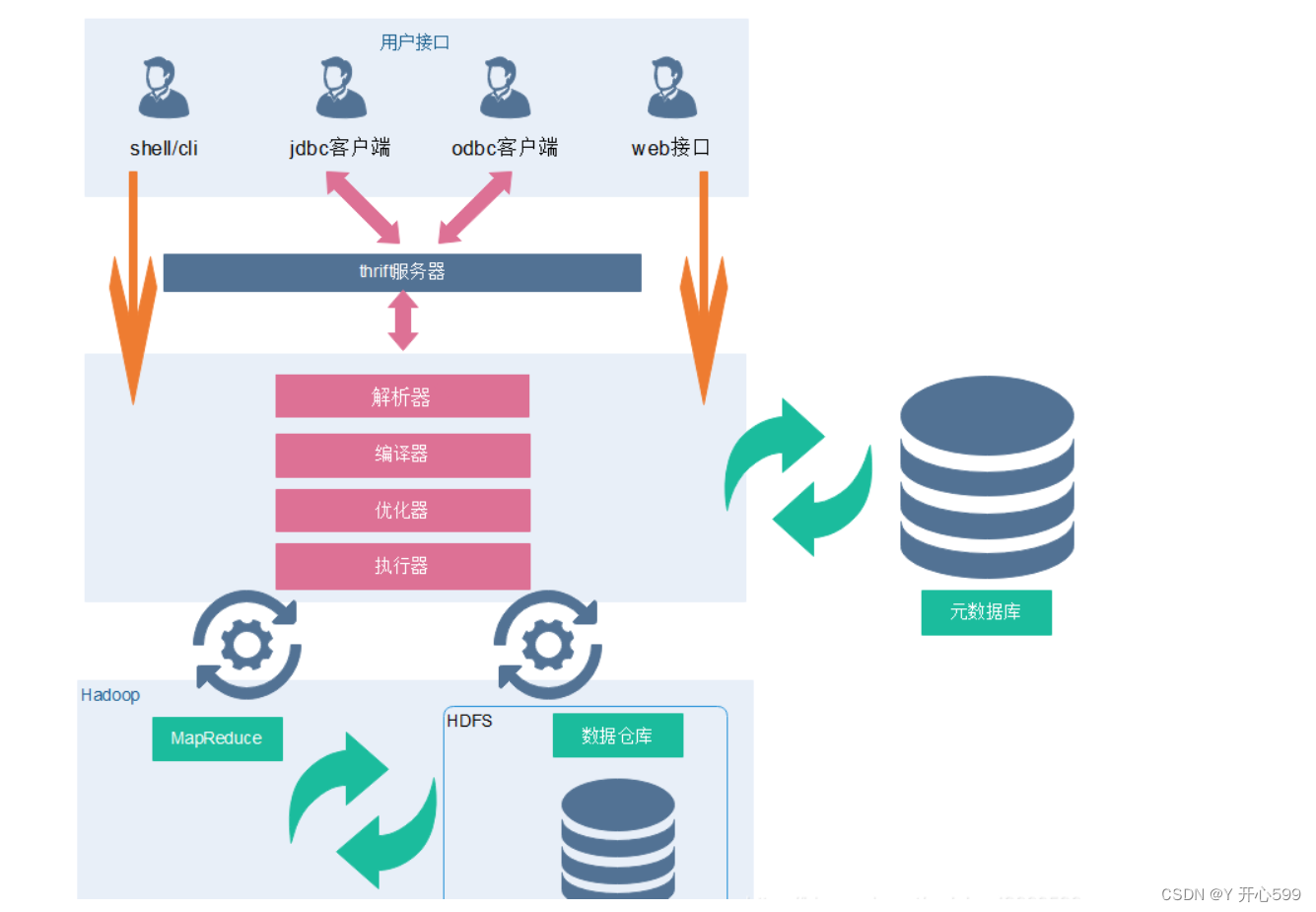
2.元数据
元数据包括表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是 外部表)、表的数据所在目录等。
一般需要借助于其他的数据载体(数据库)
主要用于存放数据库的建表语句等信息
推荐使用Mysql数据库存放数据
3.Driver(sql怎么转化为MR任务的)
元数据存储在数据库中,默认存在自带的derby数据库(单用户局限性)中,推荐使用Mysql进行存储。
1) 解析器(SQL Parser):将SQL字符串转换成抽象语法树AST(从3.x版本之后,转换成一些的stage),这一步一般都用第三方工具库完 成,比如ANTLR;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
2) 编译器(Physical Plan):将AST编译(从3.x版本之后,转换成一些的stage)生成逻辑执行计划。
3) 优化器(Query Optimizer):对逻辑执行计划进行优化。
4) 执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是 MR/Spark/flink。
三 Hive元数据
3.1相关表
Hive元数据库中一些重要的表结构及用途,方便Impala、SparkSQL、Hive等组件访问元数据库的理解。
1、存储Hive版本的元数据表(VERSION),该表比较简单,但很重要,如果这个表出现问题,根本进不来Hive-Cli。比如该表不存在,当启动Hive-Cli的时候,就会报错“Table 'hive.version' doesn't exist”
2、Hive数据库相关的元数据表(DBS、DATABASE_PARAMS)
DBS:该表存储Hive中所有数据库的基本信息。
DATABASE_PARAMS:该表存储数据库的相关参数。
3、Hive表和视图相关的元数据表
主要有TBLS、TABLE_PARAMS、TBL_PRIVS,这三张表通过TBL_ID关联。 TBLS:该表中存储Hive表,视图,索引表的基本信息。 TABLE_PARAMS:该表存储表/视图的属性信息。 TBL_PRIVS:该表存储表/视图的授权信息。 4、Hive文件存储信息相关的元数据表
主要涉及SDS、SD_PARAMS、SERDES、SERDE_PARAMS,由于HDFS支持的文件格式很多,而建Hive表时候也可以指定各种文件格式,Hive在将HQL解析成MapReduce时候,需要知道去哪里,使用哪种格式去读写HDFS文件,而这些信息就保存在这几张表中。 SDS:该表保存文件存储的基本信息,如INPUT_FORMAT、OUTPUT_FORMAT、是否压缩等。TBLS表中的SD_ID与该表关联,可以获取Hive表的存储信息。 SD_PARAMS: 该表存储Hive存储的属性信息。 SERDES:该表存储序列化使用的类信息。 SERDE_PARAMS:该表存储序列化的一些属性、格式信息,比如:行、列分隔符。 5、Hive表字段相关的元数据表
主要涉及COLUMNS_V2:该表存储表对应的字段信息。










