爬虫-1
爬虫学习第一天
1、什么是爬虫
通俗来讲,假如你需要互联网上的信息,如商品价格,图片视频资源等,但你又不想或者不能自己一个一个自己去打开网页收集,这时候你便写了一个程序,让程序按照你指定好的规则去互联网上收集信息,这便是爬虫,我们熟知的百度,谷歌等搜索引擎背后其实也是一个巨大的爬虫。
2、爬虫的工作原理
爬虫的基本工作流程通常包括以下几个步骤:
- 发起请求:爬虫首先向目标网站发送HTTP请求,请求特定的网页内容1。
- 获取响应:服务器处理这些请求后,会返回相应的网页内容,爬虫接收这些内容1。
- 解析内容:爬虫对获取的网页内容进行解析,提取有用信息。这通常涉及到HTML、CSS和JavaScript的解析。
- 提取数据:解析后的内容中,爬虫会根据预设的规则提取所需的数据,如文本、图片、链接等。
- 存储数据:提取的数据会被存储到数据库或文件中,以便后续的分析和使用。
- 发现新链接:在解析内容的过程中,爬虫会发现新的链接地址,这些链接将被加入到待爬取的队列中,循环执行上述步骤。
3、爬虫核心
-
**爬取网页:**爬取整个页面,包含了网页中所有的内容
-
**解析数据:**将网页中你得到的数据,进行解析,获取需要的数据
-
**存储数据:**将解析后的数据保存到数据库、文件系统或其他存储介质中,以便后续的访问和使用。
-
**分析数据:**对存储的数据进行统计、挖掘和分析,提取有价值的信息或洞察,为决策提供支持。
-
**可视化数据:**将分析结果通过图表、图形等形式直观展现出来,帮助用户更好地理解和利用数据。
4、爬虫的合法性
5、爬虫框架
随着爬虫技术的发展,出现了一些成熟的爬虫框架,如Scrapy。这些框架提供了一套完整的解决方案,包括请求管理、数据解析、数据存储等,使得开发者能够更专注于爬虫逻辑的实现。
6、爬虫的挑战
爬虫在实际应用中可能会遇到一些挑战,如网站的反爬策略、动态加载的内容、登录认证等。这些挑战需要爬虫开发者具备一定的技术能力,包括但不限于JavaScript逆向、模拟登录、使用代理IP等。
7、难点
- 爬虫和反爬虫之间的博弈
- 爬虫会加大系统负载!并发(每秒访问的人数100)爬虫1000
- 什么是反爬虫
- 阻止非正常用户来访问我的系统
- 登录站点=》输入验证码(图片,手机)
- 刷新太快
8、反爬手段
8.1、Robots协议
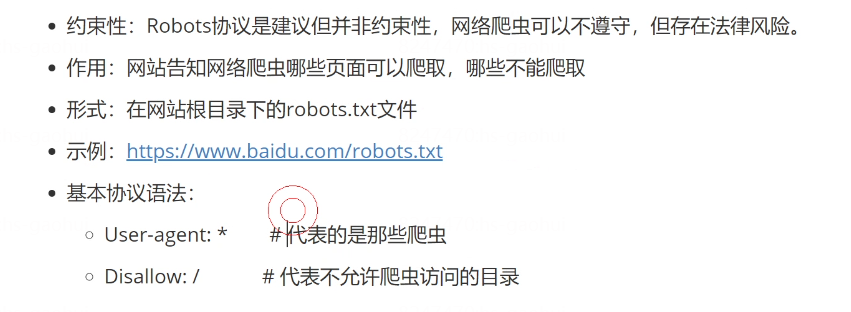
8.2、检查 User-Agent

8.3、ip限制

8.4、SESSION访问限制

8.5、验证码

8.6、数据动态加载

8.7、数据加密-使用加密算法

9、用python学习爬虫,需要用到 request模块
Requests is an HTTP library, written in Python, for human beings.
Requests是一个HTTP库,用Python编写,供人类使用。
这段文本是Python中`requests`库的一个函数文档字符串,描述了`get`函数的用途和参数。`requests`是一个非常流行的HTTP库,用于发送HTTP请求并处理返回的响应。下面是对这段文档的详细解释:
### 函数名称
`get` - 这是`requests`库中的一个函数,用于发送HTTP GET请求。
### 参数
- `url`: 这是必须提供的参数,表示要发送GET请求的目标URL。这个URL可以是完整的,也可以是相对路径,如果是相对路径,它会基于当前的URL上下文进行解析。
- `params`: 这是一个可选参数,用于传递查询字符串。它可以是一个字典、列表或元组,也可以是字节串。这个参数中的数据会被添加到URL的查询字符串中。例如,当你想要传递查询参数如`page=1`和`limit=10`时,你可以这样做:`params={'page': 1, 'limit': 10}`。
- `**kwargs`: 这是Python中的参数字典,它允许你传递任意数量的其他参数给函数。在`get`函数中,这可以用来传递`requests`库中`Request`对象支持的其他参数,比如`headers`、`cookies`、`auth`等。
### 返回值
- `Response`对象 - 当GET请求发送并接收到服务器响应后,`get`函数会返回一个`Response`对象。这个对象包含了服务器返回的所有信息,包括状态码、响应头、以及响应体(通常是HTML、JSON或其他格式的数据)。
### 示例代码
```python
import requests
# 发送GET请求
response = requests.get('https://api.example.com/data', params={'page': 1, 'limit': 10})
# 打印响应状态码
print(response.status_code)
# 打印响应内容
print(response.text)
```
在这个示例中,我们使用`requests.get`函数向`https://api.example.com/data`发送了一个GET请求,并且传递了查询参数`page=1`和`limit=10`。然后,我们打印出响应的状态码和响应的内容。
总的来说,`requests.get`函数是一个非常方便的工具,用于发送HTTP GET请求并处理响应。通过这个函数,你可以轻松地与Web服务进行交互,获取或提交数据。
10、函数
get(url,params=None,**kwargs)
括号中的变量叫函数的参数
-
url=>位置参数(有顺序,按位置依次给数据)
-
params=None =>默认参数(如果你没有传递会给一个默认值)
-
*args => 可变长位置参数
-
**kwargs => 可变长关键字参数

位置参数的使用:
# 定义一个函数,实现摄氏度转华氏度
# 32°F + 摄氏度 × 1.8
def Celsius_To_Fahrenheit(a):
b=(a*1.8)+32
print(f"{a}°C 转换成 华氏度 为:{b:.2f}°F")
Celsius_To_Fahrenheit(44.5)
更好的写法:

# get(url, params=None, **kwargs)
# 括号中的变量叫函数的参数
# url => 必选位置参数(有顺序,按位置依次给数据)
# => 注意按顺序传递参数
# params=None => 默认参数(如果你没有传递会给一个默认值)
# *args => 可变长位置参数
# **kwargs => 可变长关键字参数
# 调用:requests.get("test", "http://www.baidu.com") X 位置参数调用
# requests.get(params="test", url="http://www.baidu.com") J 关键字参数调用
# def 函数名(参数列表<0-n>):
# 函数体
# return value =>返回值
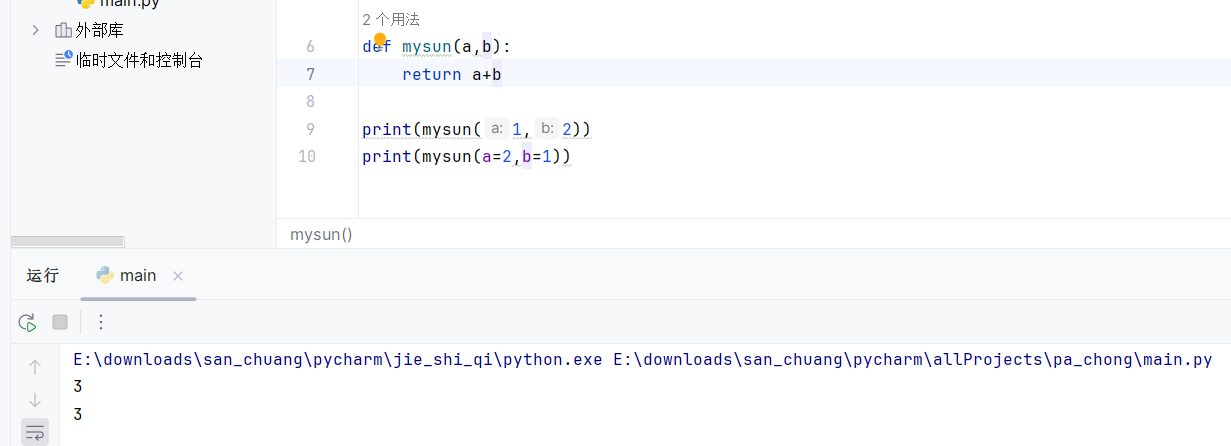
def mysum(a, b):
return a+b
# a = 1
# b = 2
# 位置参数的调用
print(mysum(1,2))
# 关键字参数的调用
print(mysum(a=1, b=2))
print(mysum(b=2, a=1))
# TypeError: mysum() missing 1 required positional argument: 'b'
# mysum(1)
# 定义一个函数,实现摄氏度转华氏度
# 32°F+ 摄氏度 × 1.8
# 传递一个摄氏温度 -> 返回一个华氏度温度
# 参数名:数据类型 => 告诉调用者,该函数需要是什么类型的!
# =>类型声明是可写可不写的
# -> 数据类型 => 函数的返回值
# return 接返回值 => 函数如果没有return语句,表示返回None
# 文档注释(document string)和类型注解(type hint)都是可选的
def ctof(celsius:int) -> float:
""" document string 文档注释 => 直接用作帮助文档
:param celsius: 传递一个int类型的摄氏温度
:return: 返回一个float类型的华氏度温度
"""
result = 32+celsius*1.8
return result
# pass => 占位符 => 什么也不做 => 保持语法完整
print(ctof(10))
# 定义一个函数,实现摄氏度转华氏度
# 如果没有传温度过来,当作计算 0摄氏度对应的华氏度
# 默认参数
def ctof(celsius:int=0) -> float:
""" document string 文档注释 => 直接用作帮助文档
:param celsius: 传递一个int类型的摄氏温度
:return: 返回一个float类型的华氏度温度
"""
result = 32+celsius*1.8
return result
print(ctof())
# 默认参数的推荐写法:先给它一个默认值为None,在函数体中处理默认
def ctof(celsius=None) -> float:
""" document string 文档注释 => 直接用作帮助文档
:param celsius: 传递一个int类型的摄氏温度
:return: 返回一个float类型的华氏度温度
"""
if celsius is None:
celsius = 0
result = 32+celsius*1.8
return result
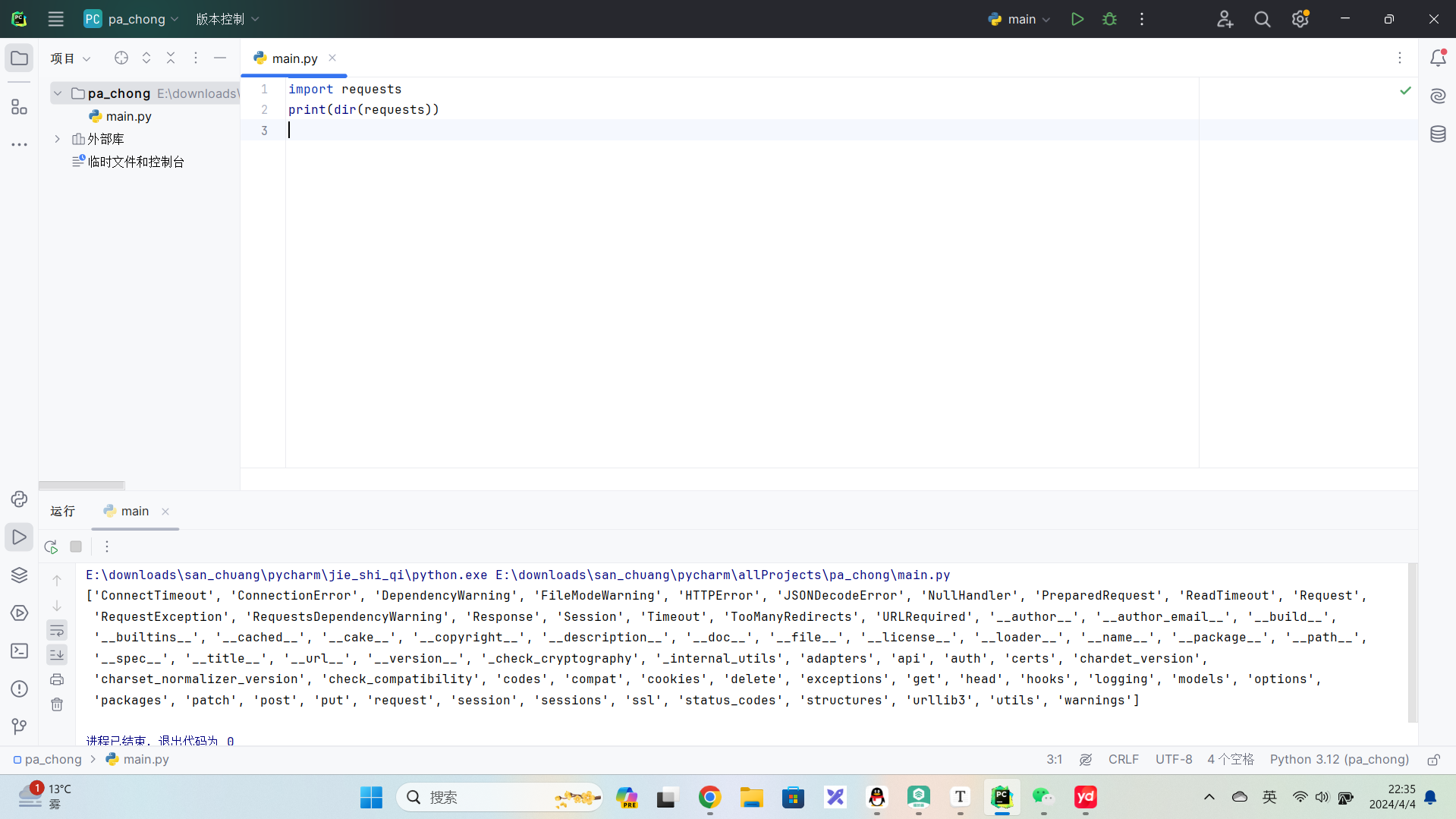
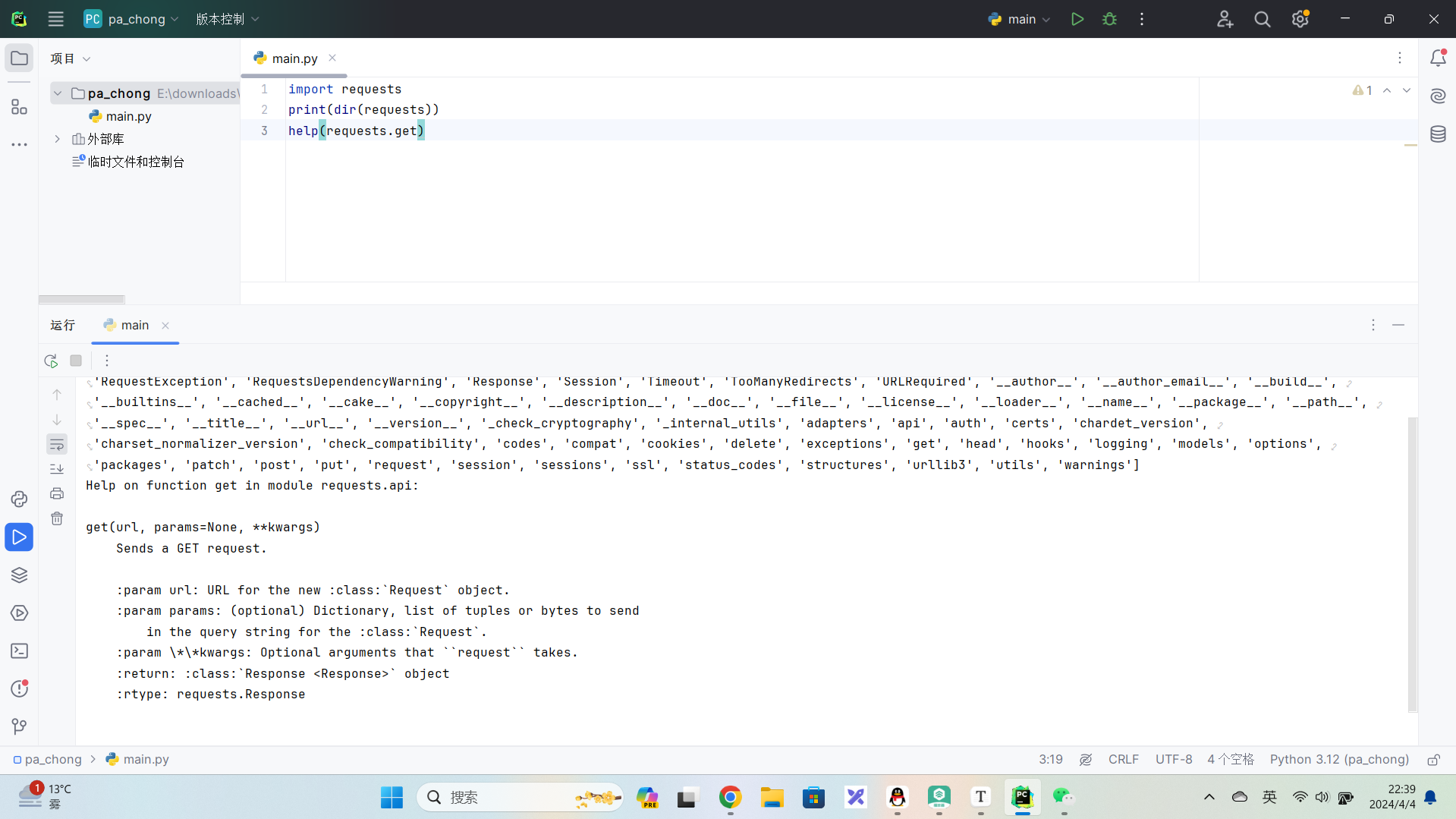
import requests
# print(dir(requests))
help(requests.get)
# get(url, params=None, **kwargs)
# 括号中的变量叫函数的参数
# url => 必选位置参数(有顺序,按位置依次给数据)
# => 注意按顺序传递参数
# params=None => 默认参数(如果你没有传递会给一个默认值)
# *args => 可变长位置参数
# **kwargs => 可变长关键字参数
# 调用:requests.get("test", "http://www.baidu.com") X 位置参数调用
# requests.get(params="test", url="http://www.baidu.com") J 关键字参数调用
# def 函数名(参数列表<0-n>):
# 函数体
# return value =>返回值
def mysum(a, b):
return a+b
# a = 1
# b = 2
# 位置参数的调用
print(mysum(1,2))
# 关键字参数的调用
print(mysum(a=1, b=2))
print(mysum(b=2, a=1))
# TypeError: mysum() missing 1 required positional argument: 'b'
# mysum(1)
# 定义一个函数,实现摄氏度转华氏度
# 32°F+ 摄氏度 × 1.8
# 传递一个摄氏温度 -> 返回一个华氏度温度
# 参数名:数据类型 => 告诉调用者,该函数需要是什么类型的!
# =>类型声明是可写可不写的
# -> 数据类型 => 函数的返回值
# return 接返回值 => 函数如果没有return语句,表示返回None
# 文档注释(document string)和类型注解(type hint)都是可选的
def ctof(celsius:int) -> float:
""" document string 文档注释 => 直接用作帮助文档
:param celsius: 传递一个int类型的摄氏温度
:return: 返回一个float类型的华氏度温度
"""
result = 32+celsius*1.8
return result
# pass => 占位符 => 什么也不做 => 保持语法完整
print(ctof(10))
# 定义一个函数,实现摄氏度转华氏度
# 如果没有传温度过来,当作计算 0摄氏度对应的华氏度
# 默认参数
def ctof(celsius:int=0) -> float:
""" document string 文档注释 => 直接用作帮助文档
:param celsius: 传递一个int类型的摄氏温度
:return: 返回一个float类型的华氏度温度
"""
result = 32+celsius*1.8
return result
print(ctof())
# 默认参数的推荐写法:先给它一个默认值为None,在函数体中处理默认
def ctof(celsius=None) -> float:
""" document string 文档注释 => 直接用作帮助文档
:param celsius: 传递一个int类型的摄氏温度
:return: 返回一个float类型的华氏度温度
"""
if celsius is None:
celsius = 0
result = 32+celsius*1.8
return result
# *args => 可变长位置参数 => 接受多个(位置)参数
# **kwargs => 可变长关键字参数 => 接受多个(关键字)参数
# 实现一个mysum函数,可以接收多个数据,计算这个数据的和
# args => arguments
# kw =>keyword
def mysum2(*args, **kwargs) ->int :
"""
计算出所有传进来的数据之和
:param args:
:param kwargs:
:return:
"""
print("args:", args, type(args))
print("kwargs:", kwargs, type(kwargs))
mysum2(1,2,3,4, a=1, b=2, c=3)
# 注意 : SyntaxError: positional argument follows keyword argument
# 位置参数必须写在关键字参数的前面
mysum2(1, 2, a=1, b=2)
#!/usr/bin/env python
# @FileName :1.python函数.py
# @Time :2024/3/10 14:59
# @Author :wenyao
# 4月底 => 爬虫+数据分析+数据可视化
# requests => dir哪些功能, help函数具体怎么用
# requests.get函数
# get(url, params=None, **kwargs)
"""
# 注意参数类型的顺序
def 函数名(位置参数,默认参数,可变长位置参数,可变长关键字参数) -> 返回值类型:
pass
return 返回值
def function(a:int, b:int=0, *args, **kwargs) -> int:
return a
如果函数没有返回值,相当于return None
"""
def sum(*args, **kwargs)->int:
# args => 保存调用时传的所有的位置参数
# kwargs => 保存调用时传的所有的关键字参数(如:a=1)
print(args) # tuple
print(kwargs) # dict
s = 0
for i in args:
s+=i
for key in kwargs:
s+=kwargs[key]
return s
# 什么情况下需要return => 如果算出来的结果还有其他用途
print(sum(1,2,3,a=4,b=5,c=6))
"""
1. 函数定义参数的类型4类(注意顺序)
2. 函数调用参数类型2类(注意顺序)
3. 注释:文档注释(写的一些帮助信息->help时可以看到),类型注解(给参数和返回值做类型声明)
类型注解在高版本中是否有强制类型限制
4. 返回值: return =>如果结果还需要用(一般情况建议返回)
"""
import requests
help(requests.get)
11、requests模块
11.3、玩一下
#获取百度首页信息
import requests
url = "https://www.baidu.com"
response = requests.get(url)
print(response,type(response))
# requests模块功能
# 相当于一个模块浏览器,发送网络请求,获取数据
import requests
# 获取百度首页的数据
url="http://www.baidu.com"
response = requests.get(url)
print(response, type(response))
# status_code => 200 OK
# => 用代码的方式告诉你,你的请求是否正确
# =>2XX 成功
# =>4XX 客户端错误
# =>5XX 服务端错误
# => $? => 0 成功,其他错误
# 取出当前响应的状态码
print(response.status_code)
# 获取当前的网页数据
# text => string
print(response.text[:100])
# content => bytes
print(response.content[:100])
# 获取请求的url
print(response.url)
# 获取响应头信息
print(response.headers)
print(dir(response))
# 获取编码方式 UTF8(全球),GBK(中文)
print(response.encoding)
# 推荐!
print(response.apparent_encoding)
12、玩一玩豆瓣读书
import requests
def download(url:str) -> str:
"""
这个函数用来获取url的数据,返回网页的string
:param url: 这应该提供一个网址
:return: 返回网页的string类型的数据
"""
response = requests.get(url)
if response.status_code == 200:
return response.text
else:
return None
print(download("http://www.baidu.com"))
def download(url: str) -> str | None:
"""
这个函数用来获取url的数据,返回网页的string
:param url: 这应该提供一个网址
:return: 返回网页的string类型的数据
"""
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/58.0.3029.110 Safari/537.3'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
else:
return None
print(download("https://book.douban.com/"))
大佬写的:
import requests
import time
# def download(url:str) -> str:
# """
# 这个函数数用来获取url的数据,返回网页的string
# :param url: 应该提供一个网址
# :return: 返回网页的string类型的数据
# """
# response = requests.get(url)
# if response.status_code == 200:
# # 指定正确的网页编码
# response.encoding = response.apparent_encoding
# return response.text
# else:
# return ""
# try...except
def download(url:str) -> str:
"""
这个函数数用来获取url的数据,返回网页的string
:param url: 应该提供一个网址
:return: 返回网页的string类型的数据
"""
# 反爬虫1:添加user-agent
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36"
}
response = requests.get(url, headers=headers)
# 如果没有获取到网页或者获取到网页了,但状态码不对,那么请报异常
# 4xx , 5xx 都会抛出异常
response.raise_for_status()
# 指定正确的网页编码
response.encoding = response.apparent_encoding
# 反爬虫2:增加sleep
time.sleep(1)
return response.text
# print(download("http://www.baidu3sdf.com"))
# print(download("https://gitee.com/asdfasdf"))
# 1. 获取数据
data = download("https://book.douban.com/top250")
# 2. 提取数据
# re模块:正则表达式,速度最快,使用难度最高
# lxml(xpath): 速度较快,使用难度一般
# BeautifulSoup: 慢,最简单
PS E:\downloads\san_chuang\pycharm\allProjects\pa_chong> pip install beautifulsoup4
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting beautifulsoup4
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/b1/fe/e8c672695b37eecc5cbf43e1d0638d88d66ba3a44c4d321c796f4e59167f/beautifulsoup4-4.12.3-py3-none-any.whl (147 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 147.9/147.9 kB 1.1 MB/s eta 0:00:00
Collecting soupsieve>1.2 (from beautifulsoup4)
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/4c/f3/038b302fdfbe3be7da016777069f26ceefe11a681055ea1f7817546508e3/soupsieve-2.5-py3-none-any.whl (36 kB)
Installing collected packages: soupsieve, beautifulsoup4
Successfully installed beautifulsoup4-4.12.3 soupsieve-2.5
PS E:\downloads\san_chuang\pycharm\allProjects\pa_chong>










