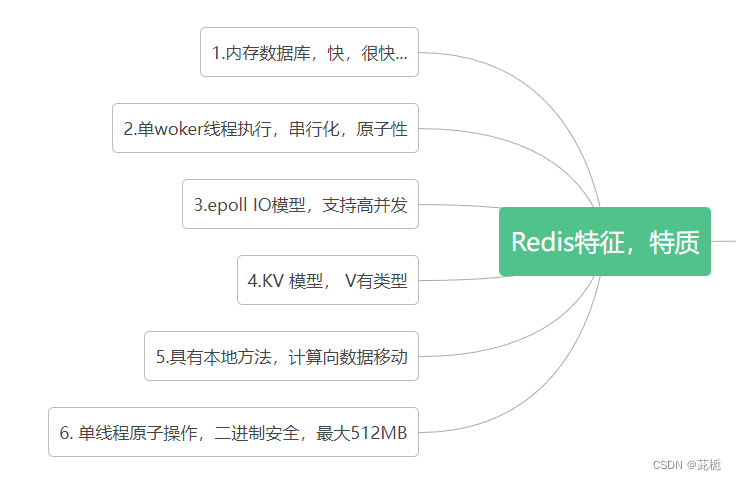
特性
面试题:为什么要用Redis
1,内存数据库,快 ,很快
2,工作单线程woeker (Redis 6.0之前是单线程的),串行化,原子操作,(IO线程是多线程的 )可以避免上下文切换
3,IO模型,(epoll ),支持高并发
4,kv模型,v具有类型结构
5,具有本地方法,计算向数据移动,(a,b)=> 交集
6,二进制安全,Value 最大就是512M
提问:(面试题) Redis 到底是多线程的还是单线程的?
答:工作线程是单线程的,IO线程是多线程的,多线程请求,单线程工作(在6.0之前是单线程的,之后是工作线程是单线程的,IO线程是多线程的)
Reids 数据持久化(掌握,面试题)
我们为什么要实现数据持久化?
Redis 提供了两种方式
1,RDB:存储数据的结果,关注点在数据上(类似于相机的快照)
2,AOF:存储操作过程,关注点在数据的操作过程(也就是说关注的是命令)
3.1,RDB(Redis DataBase)
在指定的时间间隔内将内存中的数据集中写入磁盘,也就是快照(Snapshot),数据恢复是将快照文件直接读到内存中。
Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入一个到一个临时文件(dump.rdb)中,待持久化过程结束后,再用本次的临时文件替换上次持久化后的文件。
fork函数的作用是复制一个与当前进程一样的进程,新进程的所有数据数值都和原进程一致,但是一个全新的进程,并作为原进程的子进程。
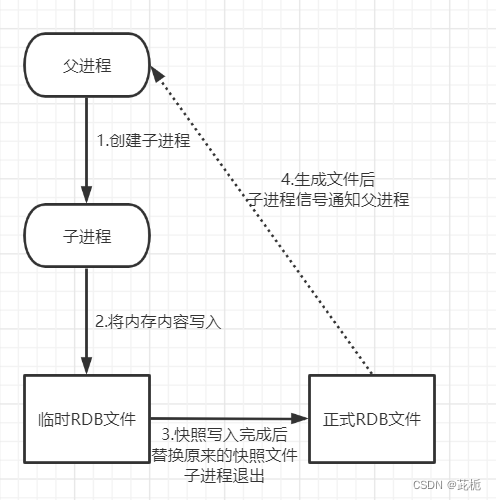
RDB的触发方式:
-
手动触发:通过命令手动生成快照 (save,bgsave)
-
自动触发:通过配置参数的设置触发自动生成快照
缺点:
-
快照时间有间隔,不能实时备份,丢失数据可能会比较多
-
开启子进程备份数据,在数据集比较庞大时,fork()可能会非常耗时,造成服务器在一定时间内停止处理客户端。
优点:
1.恢复数据比较快
2.备份的文件就是原始内存数据的大小,不会额外增加数据占用,
AOF(Append Only File)
当有写命令请求时,会追加到AOF缓冲区内,AOF缓冲区根据AOF持久化策略[always,everysec,no]将操作同步到磁盘的AOF文件中,当AOF文件大小超过重写策略或手动重写时,会对AOF文件进行重写来压缩AOF文件容量,redis服务重启时,会重新加载AOF文件中的写操作来进行数据恢复
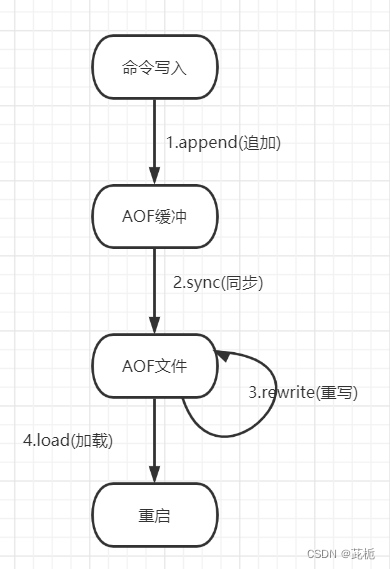
AOF的触发方式
1.手动触发
通过bgrewriteaof命令:重新AOF持久化生成aof文件(触发重写)
2.自动触发
默认情况,redis是没有开启AOF(默认使用RDB持久化),需要通过配置文件开启
AOF的优缺点

优点:
-
数据安全性高,不易丢数据
-
AOF文件有序保存了所有写操作,可读性强
缺点:
-
AOF方式生成文件体积变大
-
数据恢复速度比RDB慢
常用命令 面试题(掌握)
在百万keys的Redis里面,如何模糊查找某个key.
我们使用scan命令
SCAN 命令是一个基于游标的迭代器(cursor based iterator): SCAN 命令每次被调用之后, 都会向用户返回一个新的游标, 用户在下次迭代时需要使用这个新游标作为 SCAN 命令的游标参数, 以此来延续之前的迭代过程。
当 SCAN 命令的游标参数被设置为 0 时, 服务器将开始一次新的迭代, 而当服务器向用户返回值为 0 的游标时, 表示迭代已结束。
scan命令是迭代查询的,他有一个游标,从0开始,,一次只查找一块区域,注意这块区域的数量是随机的,然后回向用户返回一个新的游标,是否继续查询又用户决定,查询完毕会返回0,这样的redis就不会阻塞,也会减轻redis库的压力
Redis面试题-缓存穿透,缓存击穿,缓存雪崩
1.穿透: 两边都不存在(皇帝的新装) (黑名单) (布隆过滤器)
2 击穿:一个热点的key失效了,这时大量的并发请求直接到达数据库. (提前预热)
3 雪崩:大量key同时失效 (避免大量的key同一时间失效,错峰)

1,穿透的解决方法:我们可以创建一个黑名单,这样我们去查询的时候要是查询redis没有再去查询数据库也没有,就把这条数据存近黑名单里,这样的话下一次请求查询的时候redis里没有的话就直接去黑名单里查询,如果有直接就返回错误了,要是还没有就去数据库查,要是没有就又存入黑名单里,尽可能的减少数据库的压力。
2,击穿的解决方法:提前预热,就是在大量的接口调用之前调用一下这个接口
3,雪崩的解决方法: 错峰处理:将redis内的数据设置一个时间段内随机失效时间,为每个缓存项的过期时间增加一个随机范围,避免同一时刻大量缓存同时失效。
如果你看不懂我这篇缓存穿透,缓存击穿,缓存雪崩就看一下这篇:
1.Redis 过期删除策略
MySQL 里有 2000w 数据,Redis 中只存 20w 的数据,如何保证 redis 中的数据都是热点数据?
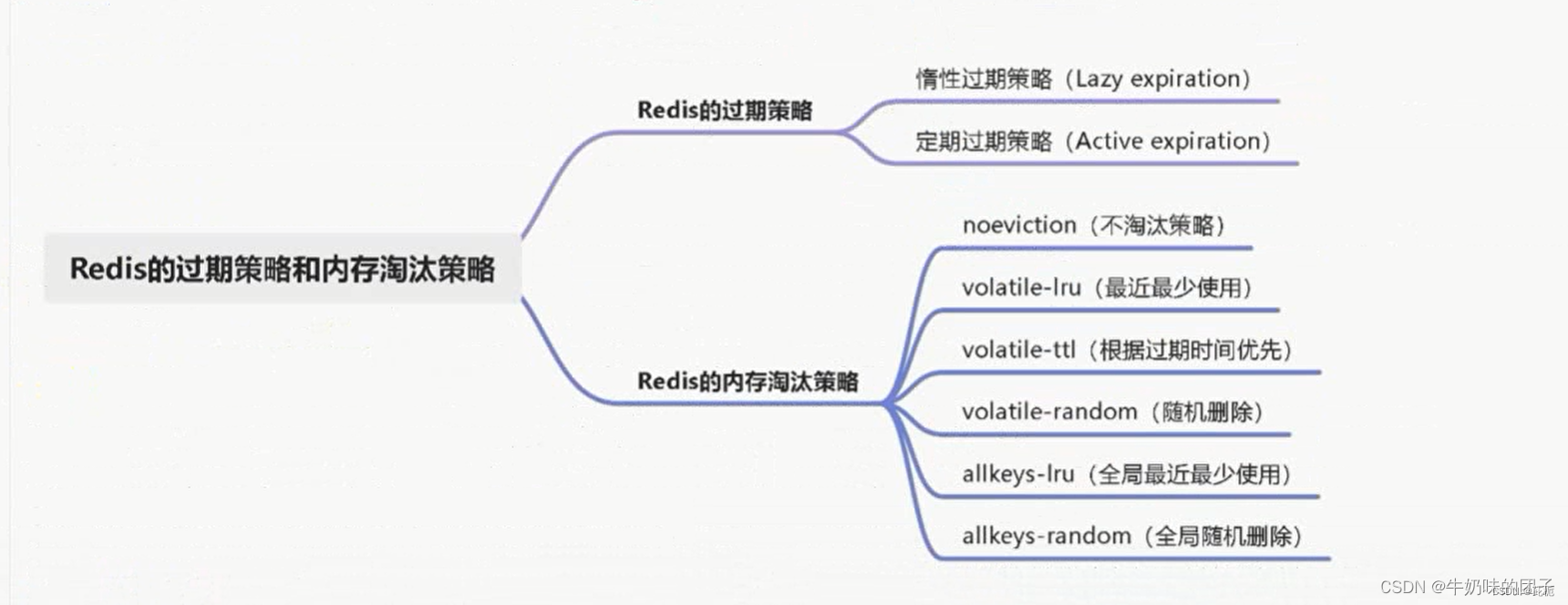
1.Redis 过期删除策略
惰性删除:放任键过期不管,但是每次从键空间中获取键时,都检查取得的键是否过期,如果过期的话,就删除该键;如果没有过期,就返回该键。但是会占用Redis很大的内存,因为只有访问到key时才会删除
定期删除:每隔一段时间程序就对数据库进行一次检查,删除里面的过期键。至于要删除多少过期键,以及要检查多少个数据库,则由算法决定。但是我们不可能说是设置个时间去让他查,因为如果是百万Redis的话压力太大了

2.内存淘汰策略
当Redis内存数据集大小上升到一定大小的时候,就会实行数据淘汰策略
Redis 提供了8种数据淘汰策略
LRU全称Least recently used,意思为淘汰掉最久未使用(即最老)的一条数据;
LFU全称Least-frequently used,意思为淘汰掉过去被访问次数最少的一条数据



3,Redis是单线程,但是为什么快
. 纯内存操作
2. 单线程操作,避免了频繁的上下文切换
3. 合理高效的数据结构
4. 采用了非阻塞I/O多路复用机制 epool
4,Redis 主从同步机制
全量和增量的区别:
全量:
是当从服务器启动并与主服务器连接时,从服务器向主服务器请求数据的时候主服务器会生成一个整个数据集的快照也就是RDB文件,然后把这个包含了全部数据的文件传输给从服务器,从服务器接受完RDB之后,从服务器就会将其载入内存,并提供服务之后继续监听主服务器发过来的写命令以完成同步
增量:
是在主服务器建立了正常的复制连接的情况下,主服务器会持续将后续写入的命令转发给从服务器,增量同步是对主服务器每次写操作产生的数据变化进行实时或近实时的同步,这样从服务器通过不断执行相同的写命令来逐步更新自己的数据集。
这种方式只复制数据差异部分,相比于全量同步更为高效,特别是对于大数据集而言,但依赖于主服务器维护的一个复制积压缓冲区,用来暂存部分最近的写命令。
总的来说,全量同步主要用于初次同步或重大同步事件中,适合数据集较大或者复制关系重建的情况。增量就是主从服务器建立连接了之后在后面一系列的写操作都暂时存进复制积压缓冲区,然后逐步更新自己的数据集。一般这两种同时使用,再全量之后我们就用增量去同步,增量同步则是在主从关系稳定时持续进行的高效同步方式。。Redis会根据实际情况智能地选择同步策略,优先尝试增量同步,如果条件不允许,则退化为全量同步。










