随着人工智能技术的飞速发展,大模型已经成为了推动各行各业进步的关键力量。从自然语言处理到图像识别,再到复杂的数据分析,大模型以其卓越的性能和广泛的应用前景,正逐渐成为AI领域的焦点。然而,大模型的高效运行离不开强大的算力支持,而存算架构的优化则是提升算力的关键所在。本文将探讨现有大模型对算力的需求以及RRAM架构优化如何为大模型的算力提升提供动力,为开发者提供一些实用的指导。
1、大模型涌现,ChatGPT 引爆 AI 奇点
1.1、ChatGPT 加速人工智能发展奇点来临
2022 年 11 月 OpenAI 发布 ChatGPT 聊天机器人,人工智能发展奇点加速来临。ChatGPT (Chat Generative Pre-trained Transformer)是由美国人工智能公司 OpenAI 开发的用于自 然语言处理的大型预训练语言模型,由人工智能技术驱动的自然语言处理工具,于 2022 年 11 月 30 日发布,是一款全新的聊天机器人模型,可以根据用户的对话输入,产生出与其相 关的回复,能够从文本输入中理解上下文因素,并生成有意义的句子回复,能够回答问题、 承认错误、质疑不正确的前提和拒绝不适当的请求。
ChatGPT 发布后,Open AI 网站访问量爆发式增长。据 SimilarWeb 数据显示,过去 7 个 月,网站 chat.openai.com 访问量快速增长,2023 年 6 月网站访问量达 16 亿次,平均访问 时长约 8 分钟,每次访问页数 4.26 个。从受众群体地区来看,美国、印度、日本、巴西、哥 伦比亚占比前五,分别为 12.12%、7.61%、4.17%、3.32%、3.16%。
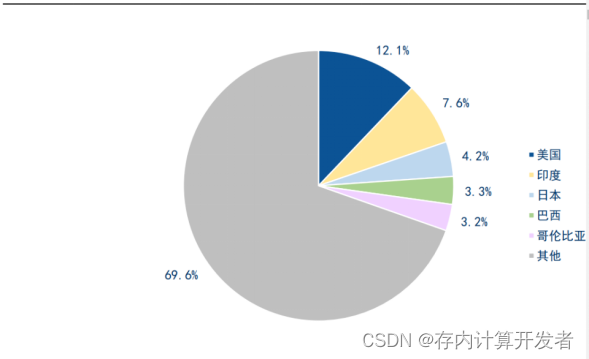
图1.2023年6月ChatGPT受众群体地区分布情况
ChatGPT 用户增速创历史新高,发布 5 天用户数突破 100 万,2 个月过亿。2022 年 11 月 30 日,OpenAI 推出 ChatGPT 聊天机器人产品。12 月 5 日,OpenAI 创始人 SamAltman 发推称,ChatGPT 上线仅 5 天,用户数突破 100 万。至 2023 年 1 月末,ChatGPT 用户数 突破 1 亿,距离发布时间仅 2 个月,成为史上用户数增长最快的消费者应用。 据英伟达在 ITF World 2023 演讲稿统计显示,海外版抖音 TikTok 发布后,大约用时 13 个月 达到月活 1 亿用户;Instagram 用时 26 个月(2 年多)达到月活 1 亿用户;Facebook 用时 42 个月达到月活 1 亿用户。
OpenAI 创始人背景深厚,与微软深度合作。2015 年 12 月,OpenAI 公司在美国旧金山成 立,由人工智能领域的顶尖科学家和企业家联合创立的一家非盈利的人工智能研究公司。联 合创始人包括美国创业孵化器 Y Combinator 总裁 Sam Altman(现 CEO)、马斯克(Elon Musk)、全球在线支付平台 PayPal 联合创始人 Peter Thiel、Ilya Sutskever(师从神经网络 之父 Geoffery Hinton,现首席科学家)等; 2019 年 3 月,OpenAI 创立了 OpenAI LP 公司,从非盈利公司转型至有限盈利公司;2019 年 7 月,微软向 OpenAI 注资 10 亿美元,同时微软 Azure 成为 OpenAI 的“独家”云计算 服务提供商; 2023 年 1 月,微软宣布与 OpenAI 扩大合作关系,其旗下所有产品将全线整合 ChatGP T, 除搜索引擎必应、Office 外,微软还将在云计算平台 Azure 中整合 ChatGPT, 作为 OpenAI 的独家云提供商,Azure 将为研究、产品和 API 服务中的所有 OpenAI 工作负载提供支持。
ChatGPT 采用基于 GPT-3.5 架构的大型语言模型,引入人类反馈强化学习技术(RLHF)训 练模型。从技术原理看,ChatGPT是基于 GPT-3.5(Generative Pre-trained Transformer 3.5) 架构开发的对话 AI 模型,是 InstructGPT 的兄弟模型,采用“预训练+微调”的模型训练方 式,引入 RLHF 技术对 ChatGPT 进行训练,利用强化学习方法从人类标注者的反馈中学习。 训练过程可分为三个步骤: 1) 训练监督学习模型:首先 ChatGPT 从 prompt 数据库中抽取若干问题并向模型解释强化 学习机制,随后人类标注者撰写期望的输出值,对模型给予特定奖励或惩罚引导教育, 最后通过监督学习微调 GPT-3.5 模型; 2) 收集数据并训练奖励模型:从 prompt 数据库中取样,并由人类标注者们对模型输出的多 个结果进行投票,按质量排序,采用排序后的数据结果用于训练奖励模型; 3) 采用近端策略优化(PRO)强化学习微调模型:近端策略优化(Proximal Policy Optimization)是 2017 年 OpenAI 发布的强化学习算法,首先通过监督学习生成初始 PRO 模型,由奖励模型对回答打分后,将反馈结果优化和迭代初始 PRO 模型,通过多 次优化迭代获得质量更高的模型。
RLHF (Reinforcement Learning from Human Feedback) 是通过人类反馈强化学习技术 优化语言模型。将人类的反馈纳入训练过程,为机器提供了一种自然的、人性化的互动学习 过程,以更广泛的视角和更高的效率学习,允许人类直接指导机器,并允许机器掌握明显嵌 入人类经验中的决策要素。

图2.RLHF(人类反馈强化学习技术)训练模型技术原理
1.2、大模型军备竞赛,开启 AI 未来时刻
人工智能是引领未来的新兴战略性技术,是驱动新一轮科技革命和产业革命的重要力量。 1950 年艾伦·图灵(Alan Turing)提出了著名的“图灵测试”,给出了判定机器是否具有“智 能”的实验方法,即机器是否能够模仿人类思维方式来“生成”内容继而与人交互,人们开 始关注人类智能与机器之间的关系;直至 20 世纪 50 年代中期,由于计算机的出现与发展, 人们开始了具有真正意义的人工智能的研究。随着人工智能越来越多地被应用于内容创作, 人工智能生成内容(Artificial Intelligence Generated Content,AIGC)概念悄然升起。
AIGC 的发展可大致分为三个阶段: 早期萌芽阶段(1950s-1990s):受限于当时的科技水平,AIGC 仅限于小范围实验。在 1956 年的达特茅斯会议上,“人工智能”的概念被首次提出,在之后的十余年内人工智能迎来了 发展史上的第一个小高峰,研究者们纷纷涌入,取得了一批瞩目的成就。 沉淀积累阶段(1990s-2010s):AIGC 从实验性向实用性转变。2006 年,深度学习算法取 得重大突破,同时期图形处理器(GPU)、张量处理器(TPU)等算力设备性能不断提升,互 联网使数据规模快速膨胀并为各类人工智能算法提供了海量训练数据,使人工智能发展取得 了显著的进步,同时受限于算法瓶颈,应用仍然有限,效果有待提升。 快速发展阶段(2010s-至今):生成内容百花齐放,效果逐渐逼真直至人类难以分辨。自 2014 年起,随着以生成式对抗网络(GAN)为代表的深度学习算法的提出和迭代更新,AIGC 迎 来了新时代。
国内外厂商纷纷加入 AI 大模型军备竞赛。在 AI 大浪潮下,国内外科技厂商纷纷入局,密集 上线大模型,包括自然语言处理模型、计算机视觉大模型、多模态大模型等多种类型。谷歌、 OpenAI 等国际科技巨头处于领先地位,中国阿里巴巴、华为、百度等公司均推出了自己的 AI 大模型产品。2023 年 3 月百度发布文心一言,4 月华为发布盘古大模型,阿里发布通义 千问大模型,商汤科技公布“日日新 SenseNova”大模型体系,5 月科大讯飞发布星火大模 型,此外多家上市公司也开始布局 AI 大模型领域,积极探索索 AI 大模型技术的应用。 从模型参数量来看,模型参数量呈现上升趋势。多模态大模型参数量相对较大,多在千亿级 以上,PaLM-E、Visual ChatGPT、GPT-4 的模型参数量分别为 5620,1750 和 1750 亿。国 内大数据模型中,模型参数数量达千亿的模型有文心大模型(2600 亿),盘古 NLP (千亿 级)等。
ChatGPT 开启商业变现。当地时间 2023 年 2 月 1 日,美国人工智能公司 OpenA I 推出 ChatGPT 付费订阅版 ChatGPT Plus,每月收费 20 美元。订阅者可在免费服务基础上获得: 1)高峰时段免排队访问;2)更快的相应时间;3)优先使用新功能和优化等权益。2023 年 3 月 1 日,OpenAI 官方宣布正式开放 ChatGPT API。我们认为,付费订阅版 ChatGPT Plus 的推出,标志着 ChatGPT正式商业化,开启产品向商业变现之路。
OpenAI 盈利模式:开放付费 API 接口,提供多种模型。目前 OpenAI 提供 DALL·E、GPT3、Codex、Content filter 的 API 接口,用于执行图像模型、语言模型,每种模型又细分为多 种子模型型号,每种型号有不同的功能和价位。用户可以根据自身业务需求选择对应的模型, API 接口根据模型类型、业务量等指标进行收费。图像模型根据图片分辨率的不同按张数收 费,语言模型基于子模型型号按字符数收费,微调模型则包括训练和使用两部分的价格。 图像模型:基于 DALL·E 实现文本生成图像。通过使用 DALL·E 的 API,可实现 3 种与图 像交互的方法:1)基于文本提示从头开始创建图像;2)基于新文本提示创建对现有图像的 编辑;3)创建现有图像的变体。生成的图像有 256x256、512x512、1024x1024 像素三种规 格,尺寸较小的图像生成速度更快。用户只需简单输入一些文字描述,即可将文字描述的场 景以图片的形式真实展现出来。据 Open AI 官网披露,目前已有 300 万人使用 DALL·E 模 型扩展创造力,加快工作流程。 语言模型:不同功能和价格的语言模型。目前 OpenAI 提供三类语言模型,分别是 GP T-3、 Codex、Content filter。其中 GPT-3 能够理解自然语言提示,并生成自然语言,拥有 1750 亿 个参数;Codex 是 GPT-3 模型的后代,可以理解并生成代码,将自然语言转换成代码,并精 通多种编程语言;Content filter 是检测文本是否敏感或不安全。
Open API 已在多个应用程序中应用,从帮助人们学习新语言到解决复杂分类问题。GitHub Copilot 是一款 AI 编程器,由 OpenAI Codex 语言模型提供支持,帮助开发人员更快地编写 代码;Keeper Tax 是一款帮助独立承包商和自由职业者纳税的 App,由 GPT-3 模型提供支 持,可以实现提取文本并对交易分类;Viable 通过使用 GPT-3 语言模型,帮助公司从客户反 馈中获得见解,智能读取用户评论;Duolingo 使用 GPT-3 语言模型进行语法修正。
GitHub Copilot:AI 编程工具软件,提高开发效率。2021 年 6 月 29 日,微软与 OpenA I 共 同推出了一款 AI 编程工具 GitHub Copilot,2022 年 6 月 22 日,Copilot 正式上线,定价每 月 10 美元或每年 100 美元,对学生用户和流行开源项目的维护者免费提供。GitHub Copilot 由 OpenAI Codex 提供支持,这是一个由 OpenAI 创建的生成预训练语言模型,可以根据上 文提示为程序员自动编写下文代码。使开发人员更快地编写代码,专注于业务逻辑而不是样 板,提高工作效率。
推出 ChatGPT Plugins 插件功能,拓宽场景边界。当地时间 2023 年 3 月 23 日,OpenAI 推出ChatGPT Plugins 插件功能,宣布ChatGPT中初步实现对插件的支持。ChatGPT Plugins 插件专门为大语言模型设计,以安全为核心原则,能够帮助 ChatGPT 访问最新的信息,运 行计算,以及使用第三方服务,能够使 ChatGPT 参与开发者定义的 API 互动,增强 ChatGP T 的能力,拓宽场景边界。
2、算力质变,存内计算打造 AI 时代引擎
2.1、算力需求指数级增长,加速计算深度变革
算力是设备通过处理数据,实现特定结果输出的计算能力。算力实现的核心是 CPU、GPU、 FPGA、ASIC 等各类计算芯片,并由计算机、服务器、高性能计算集群和各类智能终端等承 载,海量数据处理和各种数字化应用都离不开算力的加工和计算算力数值越大代表综合计算 能力越强,常用的计量单位是每秒执行的浮点数运算次数(Flops,1EFlops=10^18Flops)。 据信通院测算,1EFlops 约为 5 台天河 2A 超级计算机,或者 25 万台主流双路服务器,或者 200 万台主流笔记本的算力输出。 算力可分为基础算力、智能算力和超算算力三部分,分别提供基础通用计算、人工智能计算 和科学工程计算。其中,基础通用算力主要基于 CPU 芯片的服务器所提供的计算能力;智 能算力主要是基于 GPU、FPGA、ASIC 等芯片的加速计算平台提供人工智能训练和推理的 计算能力;超算算力主要是基于超级计算机等高性能计算集群所提供的计算能力。
算力需求指数级增长,大模型参数指数级增长。经过大规模预训练的大模型,能够在各种任 务中达到更高的准确性、降低应用的开发门槛、增强模型泛化能力等。随着海量数据的持续 积累、人工智能算力多样化与算法的突破,大模型参数规模呈现指数级增长,先后经历了预 训练模型、大规模预训练模型、超大规模预训练模型三个阶段,参数量实现百万亿级突破。 与此同时,算力需求也呈现指数级增长。从行业分布上看,大模型的应用领域逐步从学术拓 展至产业,2010 年后产业界对大模型的应用与算力需求显著增长,成为主导力量。

图3.1950-2022年机器学习训练参数变化情况
AI 期刊论文与开源项目快速增长。ChatGPT引发了新一轮的 AI 浪潮,越来越多的研究机构 与公司加大对 AI 的研发投入。据斯坦福大学发布的《2023 年 AI 指数报告》统计,人工智能 论文的总数自 2010 年呈现翻倍增长,从 2010 年的 20 万篇增长到 2021 年的近 50 万 篇(49601),模式识别、机器学习和计算机视觉是人工智能领域研究的热门话题,从国家分 布看,中国保持领先地位,2021 年占比为 39.8%,其次是欧盟和英国(15.1%)与美国(10% )。 AI 开源项目方面,据 GitHub 统计,自 2011 年以来人工智能相关的 GitHub 项目稳步增长, 从 2011 年的 1536 个增长至 2022 年 34.79 万个,从国家分布看,2022 年印度软件开发人 员占比 24.2%,其次是欧盟和英国(17.3%)与美国(14%)。
全球算力规模不断增长。据 IDC 统计,2020 年全球算力总规模达到 429EFlops,同比增长 39%,其中基础算力规模(FP322,FP32 为单精度浮点数,采用 32 位二进制来表达一个数 字,常用于多媒体和图形处理计算)为 313EFlops3,智能算力规模(换算为 FP32)为 107EFlops4,超算算力规模(换算为 FP32)为 9EFlops5。据 IDC 预测,未来五年全球算力 规模将以超过 50%的速度增长,到 2025 年整体规模将达到 3300Eflops。 全球主要国家和地区纷纷加快算力布局。算力水平方面,据 IDC 统计 2021 年美国、中国、 欧洲、日本在全球算力规模中的份额分别为 36%、31%、11%和 6%。
中国智能算力规模持续扩大。据IDC统计与预测,2021年中国智能算力规模达155.2EFLOPS , 2022 年智能算力规模将达到 268.0 EFLOPS,预计到 2026 年智能算力规模将进入每秒十万 亿亿次浮点计算(ZFLOPS)级别,达到 1271.4EFLOPS。
全球企业持续增加对 AI 的投资。伴随数字经济的持续发展,为满足企业内部发展需求和外 部市场需求,企业一直大力投资数字化转型相关技术。据 IDC 统计,全球企业在包括软件、 硬件和服务在内的人工智能(AI)市场的技术投资从 2019 年的 612.4 亿美元增长至 2021 年 的 924 亿美元,有望到 2025 年突破 2000 亿美元,增幅高于企业数字化转型(DX)支出整 体增幅。
全球人工智能芯片搭载率将持续增长,低能耗为大势所趋。算力是实现 AI 产业化的核心力 量,AI 产业技术不断提升,产业商业化应用加速落地,推动全球人工智能芯片市场高速增长, 据 IDC 预测,至 2025 年全球人工智能芯片市场规模将达 726 亿美元。人工智能算力规模的 快速增长将刺激更大的人工智能芯片需求,未来 18 个月,人工智能服务器 GPU、AS IC 和 FPGA 的芯片搭载率均会上升。目前中国市场主要以 GPU 为主,GPU 芯片多用于图形图像处理、复杂的数学计算等场景。但GPU搭载传统架构用于AI计算需耗费的大量功耗以及成本,使得科研界另辟蹊径,其中,存内计算近年来呼声日益高涨,较之传统计算架构提升上百倍的算力以及减少数据搬运,打破内存墙的低功耗特性,产业界更加看好存内计算作为AI时代的首趋计算架构,
2.2、存内计算技术的潜力
为了应对大模型对算力的巨大需求,存内计算技术提供了一种潜在的解决方案。存内计算技术的基本思想是将数据计算移动到存储器中,实现原位计算,消除带宽限制和数据传输成本6。存内计算技术有望激发人工智能领域的下一波浪潮,目前,针对人工智能,特别是深度学习的,基于忆阻器的存内计算架构已经问世,以提升计算的能效,RRAM由于其非易失性和可变电阻特性,成为了存内计算(Computing-in-Memory, CIM)技术的理想选择之一。在CIM架构中,RRAM不仅用于数据存储,还能直接在存储单元上执行计算操作,如乘加运算等,从而减少了数据在处理器和存储器之间的传输,降低了延迟和功耗。
2.3基于RRAM的可扩展CIM芯片架构
可扩展架构的关键特点
1.模块化设计:CIM芯片的架构通常采用模块化设计,每个模块包含计算和存储单元。这种设计允许系统根据需要灵活地增加或减少模块,以适应不同的计算需求。
2.阵列结构:RRAM阵列可以采用1T1R(一个晶体管和一个阻变存储器)或1TnR(一个晶体管控制多个阻变存储器)结构。这种阵列结构支持高密度集成,有助于提高芯片的存储密度和计算能力。
3.多级存储和计算:为了进一步提高可扩展性,RRAM CIM芯片可以设计为支持多级存储和计算。这意味着可以在不同的层级上执行不同的计算任务,从而实现更高效的并行处理。
4.编程和读取灵活性:RRAM单元可以被编程为多种电阻状态,这使得CIM芯片能够执行复杂的计算任务,如模拟神经网络中的权重更新和激活函数。
为了适应不同场景和性能要求,提出了一种具有可扩展计算性能的计算存储一体(CIM)芯片架构。每个基本计算模块都拥有独立的计算和存储资源,当映射不同规模的神经网络时,可以实现硬件资源的比例增长。基于RRAM的CIM架构由三个层级组成,即芯片层、瓦片层和基本处理单元(PE,也称为交叉阵列或XB)[2, 15],如图所示。最顶层,即芯片层,包括多个相互连接的瓦片和全局单元。瓦片之间的数据通过芯片内互连结构进行通信。数据流是数据驱动的。如果有足够的数据发送到瓦片的本地缓冲区,每个瓦片就会启动其计算。第二层,瓦片层,是为了便于层次化管理。瓦片层是面积高效的,因为一个瓦片中的XB可以共享一些电路单元,如加法器树、汇聚单元和激活单元。一个瓦片由几个XB、本地缓冲区、瓦片级控制器和特殊功能单元(SFUs)组成。第三层是XB层,由RRAM阵列和其他外围电路单元组成,如DACs、ADCs和写入驱动器。对于RRAM阵列,神经网络的权重表示为RRAM单元的电导值,输入特征图(IFMs)通过DACs编码的电压级别输入映射。VMM可以根据欧姆定律和基尔霍夫电流定律在RRAM阵列中实现。列的输出电流由ADCs量化,然后由SFUs处理。CIM芯片可以在瓦片层和XB层进行扩展,以实现大规模神经网络的部署。

图4.(a) 灰度面部图像分类[16]和(b) 在1k-1T1R阵列上的声音定位[17];(c) 在完全硬件实现的PCB级多阵列集成系统上的五层基于RRAM的CNN[5],© 2020 Nature;(d) 在160 kb完全集成的模拟RRAM芯片上的完整多层FCNN[19],© 2020 IEEE;(e) 在完全并行的128 Kb RRAM阵列上的5G/6G MIMO通信系统的混合预编码技术[21],© 2022 IEEE;(f) 在八个144 kb 2T2R RRAM阵列上的加密-解密过程,用于保护隐私[22],© 2022 IEEE。
2.4基于RRAM的存内计算-协同优化方法的概述:
1. 器件-宏结构-算法协同优化 :由于CIM系统中器件和电路的非理想性和噪声,需要进行噪声感知的离线训练和低位量化训练,以实现高分类准确度。在噪声感知训练期间,离线训练过程中考虑了非理想性和噪声。通过神经网络的自适应,为CIM系统训练特定的权重。在低位量化训练期间,神经网络权重根据RRAM器件的精度进行量化,输入特征图(IFMs)和输出特征图(OFMs)根据CIM系统中ADC/DAC的精度进行量化。
2. 器件-阵列协同优化 :由于RRAM的固有丝状导电机制,RRAM器件的变化难以消除。提出了一种阵列级增强方法,以减少由RRAM的有限精度和噪声引起的准确度损失[24]。阵列级空间扩展分配方法可以减少加法和平均值的变化。RRAM阵列被复制N次,计算阵列输出的平均值。此外,提出了贪婪空间扩展分配(GSEA)算法,以确定每层的复制次数N。使用阵列级增强方法,CIFAR-10数据集上ResNet-34的准确度接近基于软件的准确度(93.2%),面积约为56%的开销,功耗为36%。
3. 阵列-算法协同优化 :针对IR-drop问题,提出了对角矩阵回归层(DMRL)[25]方法进行阵列优化。它将互连电阻效应和偷路径问题纳入神经网络的离线训练中。神经网络的导出梯度等于标准梯度和DMR模型对角矩阵的乘积[26]。
4. 器件-宏结构协同优化 :针对读噪声问题,提出了一种多偏置列映射方法[21],使用多个列代替一个表示为偏置的列。映射策略具有读噪声容忍性,且具有低能量和面积开销。
5.器件-芯片协同优化 :针对可靠性退化问题,提出了一种片上混合训练方案,可以恢复准确度损失[27]。该方法可以在几次迭代后提高接近基线的准确度。
6.结构优化:M3D优化
模拟RRAM阵列能够以极高的能效执行向量矩阵乘法(VMM)。然而,频繁的数据在RRAM阵列和带宽有限的片外存储器之间的传输会导致显著的延迟,并限制了CIM的并行性。此外,模数转换器/数模转换器(AD/DA)的面积和功耗开销也会降低系统级的能效。因此,提出了一种基于M3D的混合CIM架构,以进一步提高能效和并行性[28-30]。
M3D架构可以高效地完全实现大规模神经网络[31]。M3D芯片由三层组成:第1层是Si CMOS层,第2层是1T1R模拟RRAM阵列的CIM层,第3层是基于互补场效应晶体管(CFET)电路的近存储处理(PNM)层,这些电路与碳纳米管/铟镓锌氧化物(CNT/IGZO)相结合。层与层之间密集的层间通孔可以提供超高带宽。CIM和PNM层分别执行密集的VMM计算和数据处理。
在M3D芯片上实现了增强型深度超分辨率(EDSR)网络,与GPU相比,能耗降低了149倍。此外,还展示了另一种M3D架构,该架构结合了基于Si的CMOS逻辑、基于RRAM的CIM和基于碳纳米管场效应晶体管(CNTFETs)的三态内容寻址存储器(TCAM)层,实现了一次/少次学习。与GPU相比,它展示了162倍的能耗降低。
总结:
这些混合CIM架构的开发,不仅提高了系统的能效,还增强了处理大规模数据和复杂算法的能力。通过在芯片的不同层级上集成不同的技术和材料,M3D架构为实现下一代高性能、低能耗的AI计算系统提供了新的可能性。这些进展表明,通过跨学科的协同设计和技术创新,可以显著提升AI硬件的性能,推动人工智能技术的发展。
关键优化策略
1. 协同设计 :通过设备-电路-算法的协同设计,可以在不同层面上优化CIM系统的性能。这包括神经网络结构的调整、量化方法的改进、数据流的优化、电路设计的精细化以及器件参数的精确配置。
2. 阵列级增强 :针对RRAM器件的变化和噪声问题,采用阵列级增强方法和空间扩展分配方法,可以有效减少准确度损失,提高系统的容错能力。
3. 混合架构 :M3D架构通过集成Si CMOS层、RRAM CIM层和基于CFET的PNM层,提供了超高带宽和高效的数据处理能力。这种三层结构不仅优化了能耗,还提升了并行处理能力。
4. 能效提升 :通过在M3D芯片上实现特定的神经网络模型,如EDSR网络,与传统的GPU相比,能耗大幅降低,证明了CIM架构在大模型加速方面的潜力。
5. 一次/少次学习 :结合Si CMOS逻辑、RRAM CIM和CNTFETs TCAM层的M3D架构,能够实现一次或少次学习,这在某些应用场景中可以显著减少训练时间和资源消耗。
基于RRAM的CIM架构通过一系列创新的优化策略,为大模型的加速提供了有效的解决方案。这些优化不仅提高了模型的运行效率,还降低了能耗和硬件成本。随着技术的不断进步,预计CIM架构将在AI硬件领域发挥更加重要的作用,特别是在需要处理大量数据和执行复杂计算任务的应用中。未来的研究和开发将继续探索如何进一步提高CIM架构的性能,以满足日益增长的AI计算需求。










