JavaScript动态渲染页面爬取
JavaScript动态渲染得页面不止Ajax一种。例如,有些页面的分页部分由JavaScript生成,而非原始HTML代码,这其中并不包含Ajax请求。还有类似淘宝这种页面,即使是Ajax获取的数据,其Ajax接口中也含很多加密参数,使我们难以直接找出规律,也很难直接通过分析Ajax爬取数据。
为解决这些问题,可以直接模拟浏览器运行,然后爬取数据,这样就可以实现再浏览器中看到的内容是什么样,爬取的源码就是什么样——所见即所爬。无须去管网页内部的JavaScript使用什么算法渲染页面,也不用管网页后台的Ajax接口到底含有哪些参数。
Python提供了许多模拟浏览器运行的库,例如Selenium、Splash、Pyppetter、Playwright等,
可以实现所见即所爬,轻松爬取动态渲染页面。
Selenium的使用
在很多情况下,Ajax请求的接口含有加密参数,例如token、sign等,示例网址https://spa2.scrape.center/的Ajax接口就包含一个token的参数,如图所示:

由于请求Ajax接口时必须加上token参数,因此如果不深入分析并找到token参数的构造逻辑,是难以直接模拟Ajax请求的。
方法通常有两种:一种是深挖其中的逻辑,把token参数的构造逻辑完全找出来,再用Python代码复现,构造Ajax请求;另一种是直接模拟浏览器的运行,绕过这个过程,因为在浏览器里是可以看到这个数据的,所以如果能把看到的数据直接爬取下来,当然就能获取对应的信息了。
这里采用第二种方法,模拟浏览器的运行,爬取数据。由于使用的工具是Selenium,因此先了解一下它的基本使用方法。
Selenium是一个自动化测试工具,利用它可以驱动浏览器完成特定的操作,例如点击、下拉等,还可以获取浏览器当前呈现的页面的源代码,做到所见即所爬,对于一些JavaScript动态渲染的页面来说,这种爬取方式非常有效。
- 准备工作
以Chrome浏览器为例讲解Selenium的用法。在开始之前,请确保已经正确安装了Chrome浏览器,并配置好了ChromeDriver。另外,还需要正确安装好Python的Selenium库。
- 基本用法
首先大体看一下Selenum的功能,示例代码如下:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
# 创建一个Service对象,传入ChromeDriver的路径
service = Service(executable_path='./chromedriver')
# 创建一个WebDriver对象,传入Service对象
browser = webdriver.Chrome(service=service)
try:
browser.get('https://www.baidu.com')
input = browser.find_element(By.ID, 'kw')
input.send_keys('Python')
input.send_keys(Keys.ENTER)
wait = WebDriverWait(browser, 10)
wait.until(EC.presence_of_element_located((By.ID, 'content_left')))
print(browser.current_url)
print(browser.get_cookies())
print(browser.page_source)
finally:
browser.close()
运行代码后,会自动弹出一个Chrome浏览器。浏览器会跳转到百度页面,然后在搜索框中输入Python,就会跳转到搜索结果页,如图所示:
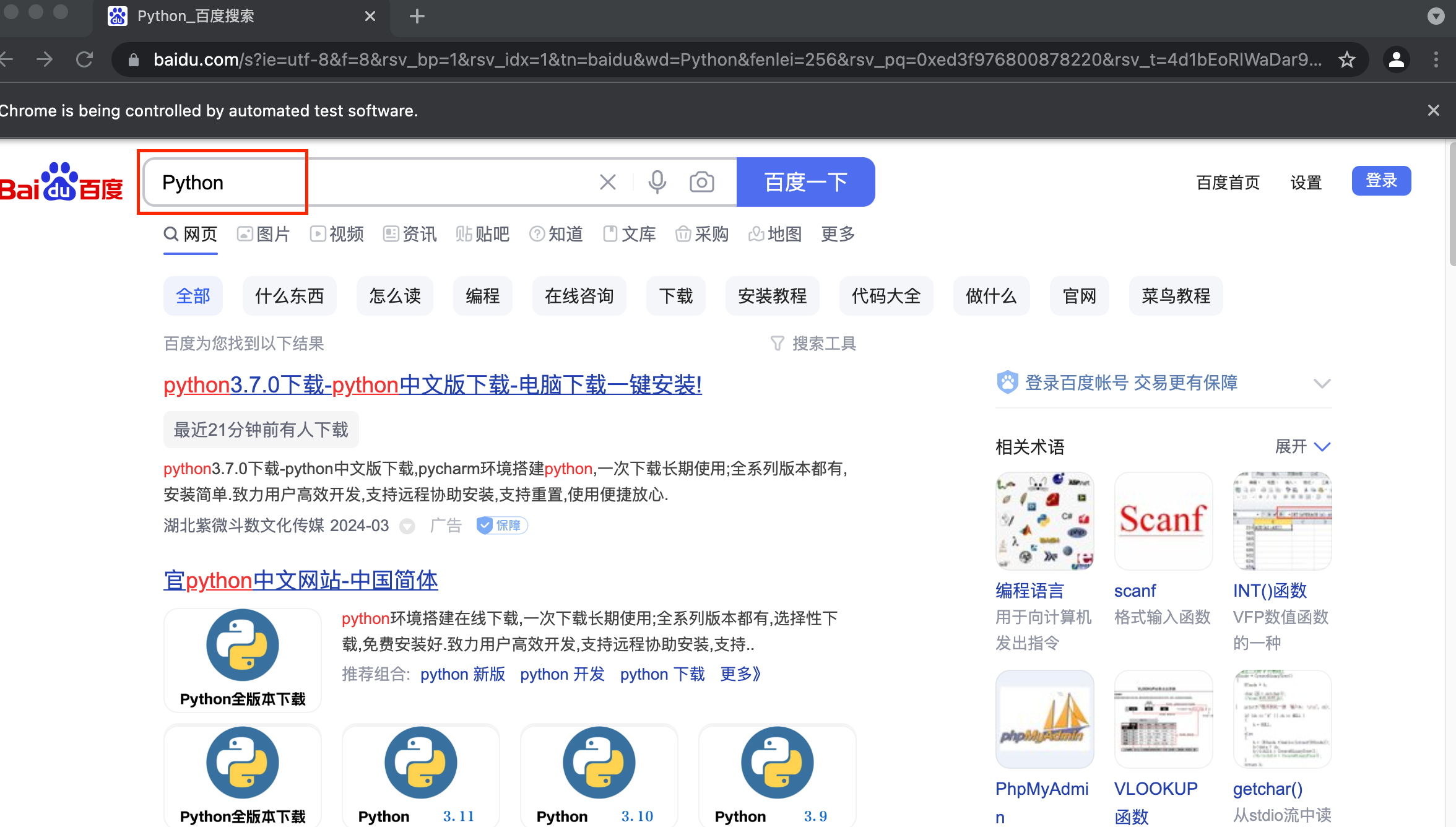
此时控制台的输出结果如下, 因为页面源代码过长,所以此处省略其内容:

可以看到,我们得到当前URL、Cookie内容和页面源代码都是浏览器中的真实内容。所以说,用Selenium驱动浏览器加载网页,可以直接拿到JavaScript渲染的结果,无须关心使用的是什么加密系统。
- 初始化浏览器对象
Selenium支持的浏览器非常多,既有Chrome、Firefox、Edge、Safari等电脑端端浏览器,也有Android、BlackBerry等手机端端浏览器。我们可以用如下方式初始化浏览器对象:
from selenium import webdriver
browser = webdriver.Chrome()
browser = webdriver.Firefox()
browser = webdriver.Edge()
browser = webdriver.Safari()
这就完成了浏览器对象的初始化,并将其赋值给了browser。接下来,我们要做的就是调用browser,执行其各个方法以模拟浏览器的操作。
- 访问页面
我们可以使用get方法请求网页,向其参数传入要请求网页的URL即可。例如,使用get方法访问淘宝,并打印出淘宝页面的源代码,代码如下:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
options = webdriver.ChromeOptions()
chrome_service = Service(executable_path='./chromedriver')
browser = webdriver.Chrome(options=options, service=chrome_service)
browser.get('https://www.taobao.com')
print(browser.page_source)
browser.close()
运行这段代码后,弹出了Chrome浏览器并且自动访问了淘宝,然后控制台输出了淘宝页面的源代码,随后浏览器关闭。通过上面几行代码,就可以驱动浏览器并获取网页源码,非常便捷。
如下图所示:

/usr/bin/python3 /Users/bruce_liu/PycharmProjects/崔庆才--爬虫/第7章JavaScript动态渲染页面爬取/Selenium/访问页面/visit_page.py
<html lang="zh-CN" class="ks-webkit537 ks-webkit ks-chrome97 ks-chrome"><head><script charset="utf-8" src="https://g.alicdn.com/tbhome/??taobao-2021/0.0.37/common/head/item-bar.jst.html-min.js,taobao-2021/0.0.37/common/head/item.jst.html-min.js" async=""></script><script charset="utf-8" src="https://g.alicdn.com/tbhome/??taobao-2021/0.0.37/common/head/index-min.js,taobao-2021/0.0.37/c/shop/item.jst.html-min.js,taobao-2021/0.0.37/c/live/item.jst.html-min.js,taobao-2021/0.0.37/c/hotsale/item.jst.html-min.js,taobao-2021/0.0.37/c/hotsale/config-min.js,taobao-2021/0.0.37/c/helper/item.jst.html-min.js,taobao-2021/0.0.37/c/goods/item.jst.html-min.js,taobao-2021/0.0.37/c/qiang/item.jst.html-min.js,taobao-2021/0.0.37/common/pipe/index-min.js,taobao-2021/0.0.37/c/fashion/item.jst.html-min.js" async=""></script><script charset="utf-8" src="https://g.alicdn.com/tbhome/??taobao-2021/0.0.37/common/inject-min.js,taobao-2021/0.0.37/c/shop/index-min.js,taobao-2021/0.0.37/c/sale/index-min.js,taobao-2021/0.0.37/c/live/index-min.js,taobao-2021/0.0.37/c/hotsale/index-min.js,taobao-2021/0.0.37/c/helper/index-min.js,taobao-2021/0.0.37/c/goods/index-min.js,taobao-2021/0.0.37/c/qiang/index-min.js,taobao-2021/0.0.37/c/fashion/index-min.js" async=""></script><script charset="utf-8" src="https://g.alicdn.com/tbhome/??taobao-2021/0.0.37/lib/lazy-min.js" async=""></script><script src="https://textlink.simba.taobao.com/?name=tbhs&cna=NR6JHrCS9Q0CAXqPOLap4j2O&nn=&count=13&pid=430266_1006&_ksTS=1711419448007_70&callback=jsonp71" async=""></script>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=10,chrome=1">
<meta name="renderer" content="webkit">
<title>淘宝</title>
<meta name="spm-id" content="a21bo">
<meta name="description" content="淘宝网 - 亚洲较大的网上交易平台,提供各类服饰、美容、家居、数码、话费/点卡充值… 数亿优质商品,同时提供担保交易(先收货后付款)等安全交易保障服务,并由商家提供退货承诺、破损补寄等消费者保障服务,让你安心享受网上购物乐趣!">
<meta name="aplus-xplug" content="NONE">
<meta name="keyword" content="淘宝,掏宝,网上购物,C2C,在线交易,交易市场,网上交易,交易市场,网上买,网上卖,购物网站,团购,网上贸易,安全购物,电子商务,放心买,供应,买卖信息,网店,一口价,拍卖,网上开店,网络购物,打折,免费开店,网购,频道,店铺">
<meta name="msvalidate.01" content="6E0390D0C5FFD883392E1B1E070FE901">
<link rel="dns-prefetch" href="//g.alicdn.com">
<link rel="dns-prefetch" href="//img.alicdn.com">
<link rel="dns-prefetch" href="//tce.alicdn.com">
<link rel="dns-prefetch" href="//gm.mmstat.com">
<link ref="dns-prefetch" href="//tce.taobao.com">
......
......
</div>
<script src="https://o.alicdn.com/tbhome/tbnav/index.js" crossorigin="anonymous"></script>
<script src="//g.alicdn.com/jstracker/sdk-assests/5.5.7/index.js" crossorigin="anonymous"></script>
<script>
if (window.JSTracker2 && typeof window.JSTracker2.setJsErrorFilters === 'function') {
window.JSTracker2.setJsErrorFilters([
}
</script>
<div id="J_SiteFooter" style="min-height: 150px;"></div><script src="//g.alicdn.com/dinamic/barrier-free/0.0.14/aria.js?appid=7e39dd4d92f393f9450d8fc1f6bafdf9" charset="utf-8" crossorigin="anonymous" id="ariascripts"></script><script src="https://mmstl-tianhe.tanx.com/imp?e=EI6Tcu1I57dhn5ny0MYV17itTH4elfHClgvvQMRvyKotVZ%2BMZXb1IKSGvYSTQULLnDGsL7%2F80wbNWHiDfQA%2FF6fPYeq%2BUVIUt4oS3Ry9Yvxg23JJPjcFGglyetaJTM3r%2BGu5AupyvbGqDwsvMj7DN0EuvZPul854QXIjWeWEI%2FstYFYNXrxPJfuP%2FYrCGX7dR%2FB7WOTSniHP9Ecdp4KYYYS5XFdX0LlQGwm%2Bxfh7VoYv4RRBLeVMrvuephet%2B1E4mcspDTYQS0UwhUQ2NLksNSP7O853W5Uf5jF5RF7FO%2Bt%2FvA2pFnpI57UFDS2I8FjMSJeNjyoZM49rHrSwCbjeYy8IR7EpTOapG9uyrT1CX02CV64WRid2L9sBdt3yP653pVMJdrB71p8vB0pm6TsM1QWUA7kM6OE7FxK524yezLCbguSRsYxRUzFUmr2wHpjlBVm8Dv1nqV3cHy1nwc85oL0mR7g%2B5FCLwdfeNb%2BUbTEoPcAHYnhtUmuZHtCovyEs&k=513"></script><iframe id="CrossStorageClient-dbab0f34-94de-47e8-afc6-63999a0409f8" src="https://www.taobao.com/wow/z/tbhome/default/kissy-search-suggest-iframe" style="display: none; position: absolute; top: -999px; left: -999px;"></iframe></body></html>
- 查找节点
Selenium可以驱动浏览器完成各种操作,比如填充表单、模拟点击等。例如,想要往某个输入框中输入文字,总得知道这个输入框在哪吧?对此,Selenium为我们提供了一系列用了查找节点的方法,我们可以使用这些方法获取想要的节点,以便执行下一步的操作或者提取信息。
- 单个节点
例如,想从淘宝页面中提取搜索框这个节点,首先就要观察这个页面的源代码,如图所示:
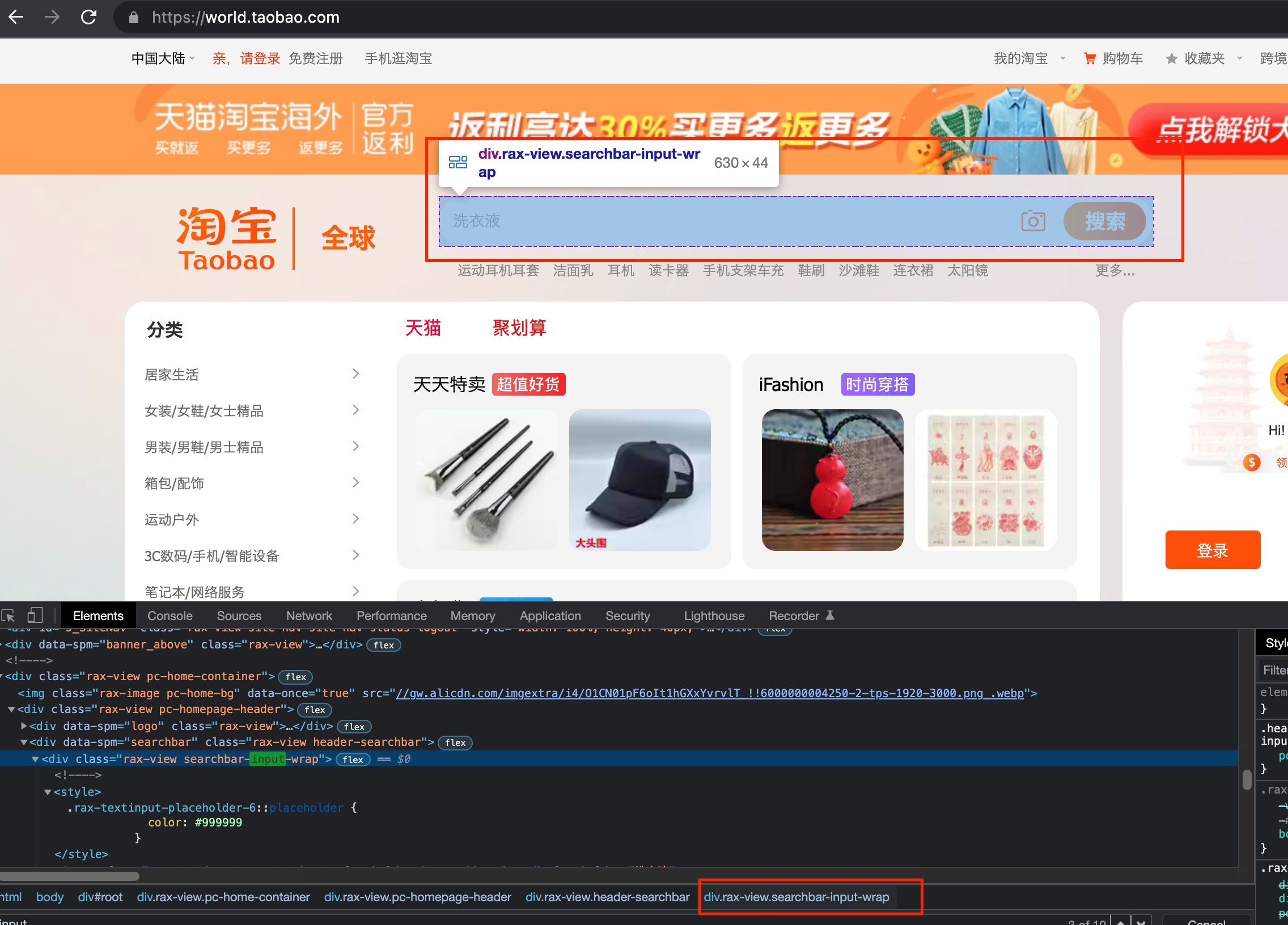
可以发现,淘宝页面的id属性值search-box,可以用多种方式获取它们。例如,find_element(By.ID, ‘search-box’), find_element(By.CSS_SELECTOR, ‘#search-box’),实现代码如下:
<selenium.webdriver.remote.webelement.WebElement (session="62cc2bc2e196c3aa7015201b8324b1bc",
element="9e8c29ae-072f-485f-8e2d-b6199566f37a")>
<selenium.webdriver.remote.webelement.WebElement (session="62cc2bc2e196c3aa7015201b8324b1bc",
element="9e8c29ae-072f-485f-8e2d-b6199566f37a")>
可以看到两种返回方式完全一致。
- 多个节点
如果查找的目标节点在网页中只有一个,那么用find_element方法就完全可以实现。但如果目标节点有多个,再用find_element方法查找,就只能得到第一个节点了,此时需要用find_elements方法才能找到所有满足条件的节点。注意,这个方法名称中的element后面多一个s,注意区分。
例如,要查找淘宝页面左侧导航条的所有条目,可以这样实现:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
options = webdriver.ChromeOptions()
services = Service(executable_path='./chromedriver')
browser = webdriver.Chrome(options=options, service=services)
browser.get('https://www.taobao.com')
lis = browser.find_elements(By.CSS_SELECTOR, '.service-bd li')
print(lis)
browser.close()
运行结果如下:
[<selenium.webdriver.remote.webelement.WebElement (session="d7c2af118c2c03214b1067aa0ab0bfab", element="369fdde2-69b4-474a-952f-a8645883cec8")>,
<selenium.webdriver.remote.webelement.WebElement (session="d7c2af118c2c03214b1067aa0ab0bfab", element="b07127c3-5ec0-44f8-92d4-caddac7c17b3")>,
<selenium.webdriver.remote.webelement.WebElement (session="d7c2af118c2c03214b1067aa0ab0bfab", element="0d25b16d-7ef3-47c9-a9b5-0996afff6ad5")>,
<selenium.webdriver.remote.webelement.WebElement (session="d7c2af118c2c03214b1067aa0ab0bfab", element="06cecb64-bd8f-45e2-9f77-65ab95221e51")>,
<selenium.webdriver.remote.webelement.WebElement (session="d7c2af118c2c03214b1067aa0ab0bfab", element="b60120cc-9692-4615-b44a-55f4fb482819")>,
<selenium.webdriver.remote.webelement.WebElement (session="d7c2af118c2c03214b1067aa0ab0bfab", element="ca538bd2-2ab6-4f88-be48-b3e56b67269d")>,
<selenium.webdriver.remote.webelement.WebElement (session="d7c2af118c2c03214b1067aa0ab0bfab", element="e394e356-827b-426c-be39-6523298cabd6")>,
<selenium.webdriver.remote.webelement.WebElement (session="d7c2af118c2c03214b1067aa0ab0bfab", element="072c5d22-5d9d-4ff8-ac71-0a33d956f815")>,
<selenium.webdriver.remote.webelement.WebElement (session="d7c2af118c2c03214b1067aa0ab0bfab", element="d124ebef-1274-45c1-bae5-ffa0da3ee6b8")>]
可以看到,得到的内容变成了列表类型,列表中的每个节点都属于WebElement类型。总结发现,如果使用find_element方法,只能得到匹配成功的第一个节点,这个节点是WebElement类型的。如果使用find_elements方法,那么结果是列表类型的,列表中的每个节点都属于WebElement类型。
获取多个节点可以使用find_elements(By.ID)、find_elements(By.XPATH)、find_elements(By.LINK_TEXT)、find_elements(By.TAG_NAME)、find_elements(By.CLASS_NAME)、find_elements(By.CSS_SELECTOR)。同理,我们可以直接使用find_elements(By.CSS_SELECTOR, ‘.service-bd li’)得到的结果是完全一致的。
- 节点交互
Selenium可以驱动浏览器执行一些操作。比较常见的用法有:用send_keys方法输入文字,用clear方法清空文字,用click方法点击按钮。示例如下:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import time
options = webdriver.ChromeOptions()
services = Service(executable_path='./chromedriver')
browser = webdriver.Chrome(options=options, service=services)
browser.get('https://www.taobao.com')
input = browser.find_element(By.ID, 'q')
input.send_keys('iPhone')
time.sleep(3)
input.clear()
input.send_keys('iPad')
button = browser.find_element(By.CLASS_NAME, 'btn-search')
button.click()
这里首先驱动浏览器打开淘宝,然后使用find_element(By.ID)方法获取输入框,再使用send_keys方法输入文字iPhone,等待3秒后用clear方法清空输入框,再次调用send_keys方法输入文字iPad,之后使用find_element(By.CLASS_NAME)方法获取搜索按钮,最后调用click方法实现搜索。
- 动作链
在上面的实例中,交互操作都是针对某个节点执行。例如,对于输入框,调用它的输入文字方法send_keys和清空文字方法clear;对于搜索按钮,调用了它的点击方法click。其实还有一些操作,它们没有特定的执行对象,比如鼠标拖拽、键盘按键等,这些操作需要用另一种方式执行,那就是动作链。
例如,可以这样实现拖拽节点的操作,将某个节点从一处拖拽至另一处:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver import ActionChains
options = webdriver.ChromeOptions()
service = Service(executable_path='./chromedriver')
browser = webdriver.Chrome(options=options,service=service)
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
browser.switch_to.frame('iframeResult')
source = browser.find_element(By.CSS_SELECTOR, '#draggable')
target = browser.find_element(By.CSS_SELECTOR, '#droppable')
actions = ActionChains(browser)
actions.drag_and_drop(source, target)
actions.perform()
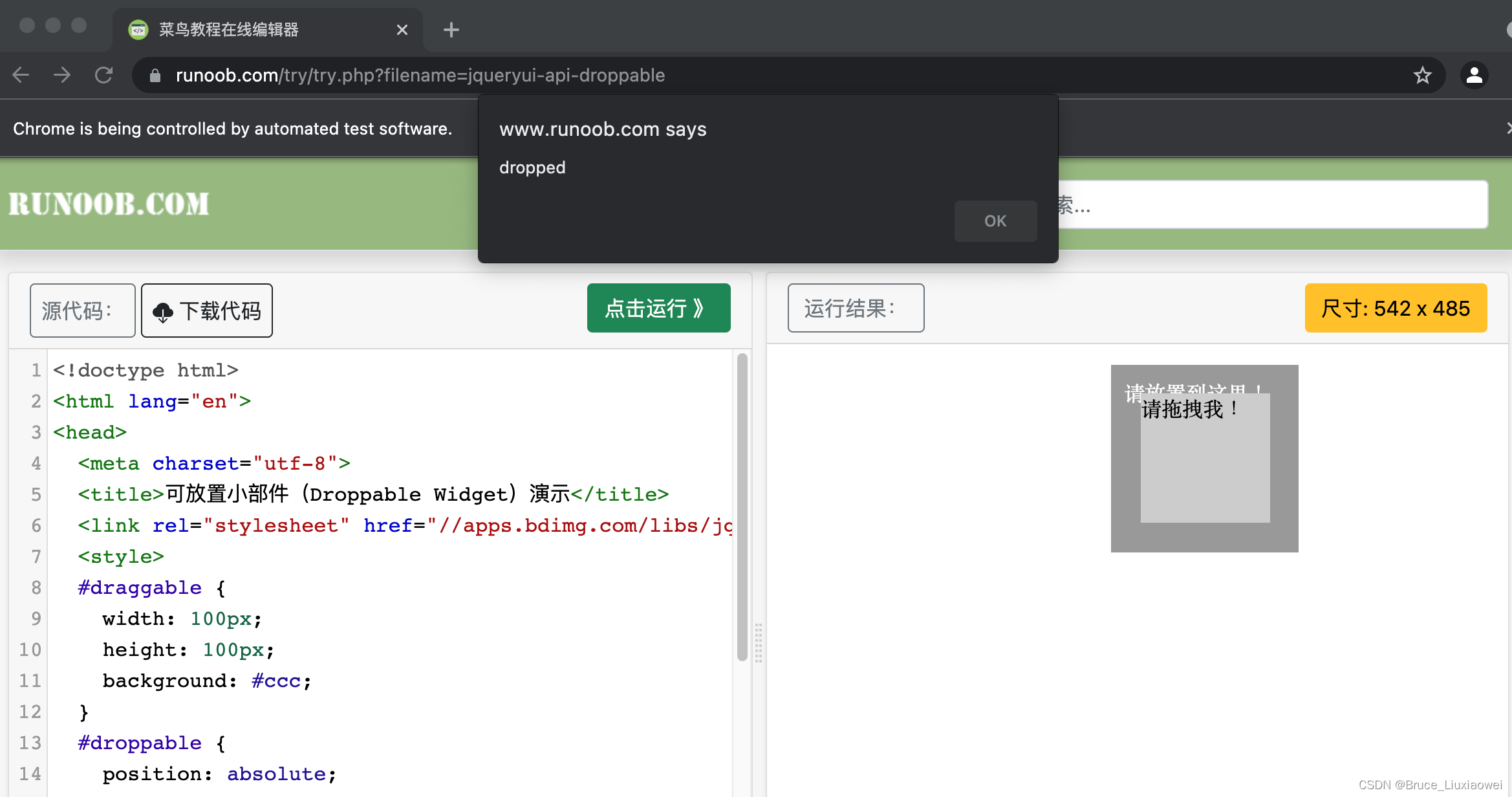
这里首先打开网页中的一个拖拽实例,然后依次选中要拖拽的节点和拖拽至的目标节点,接着声明一个ActionChains对象并赋值给actions变量,再后调用actions变量的drag_and_drop方法声明拖拽对象和拖拽目标,最后调用perform方法执行动作,就完成了拖拽操作,拖拽前和拖拽后的页面如图所示:
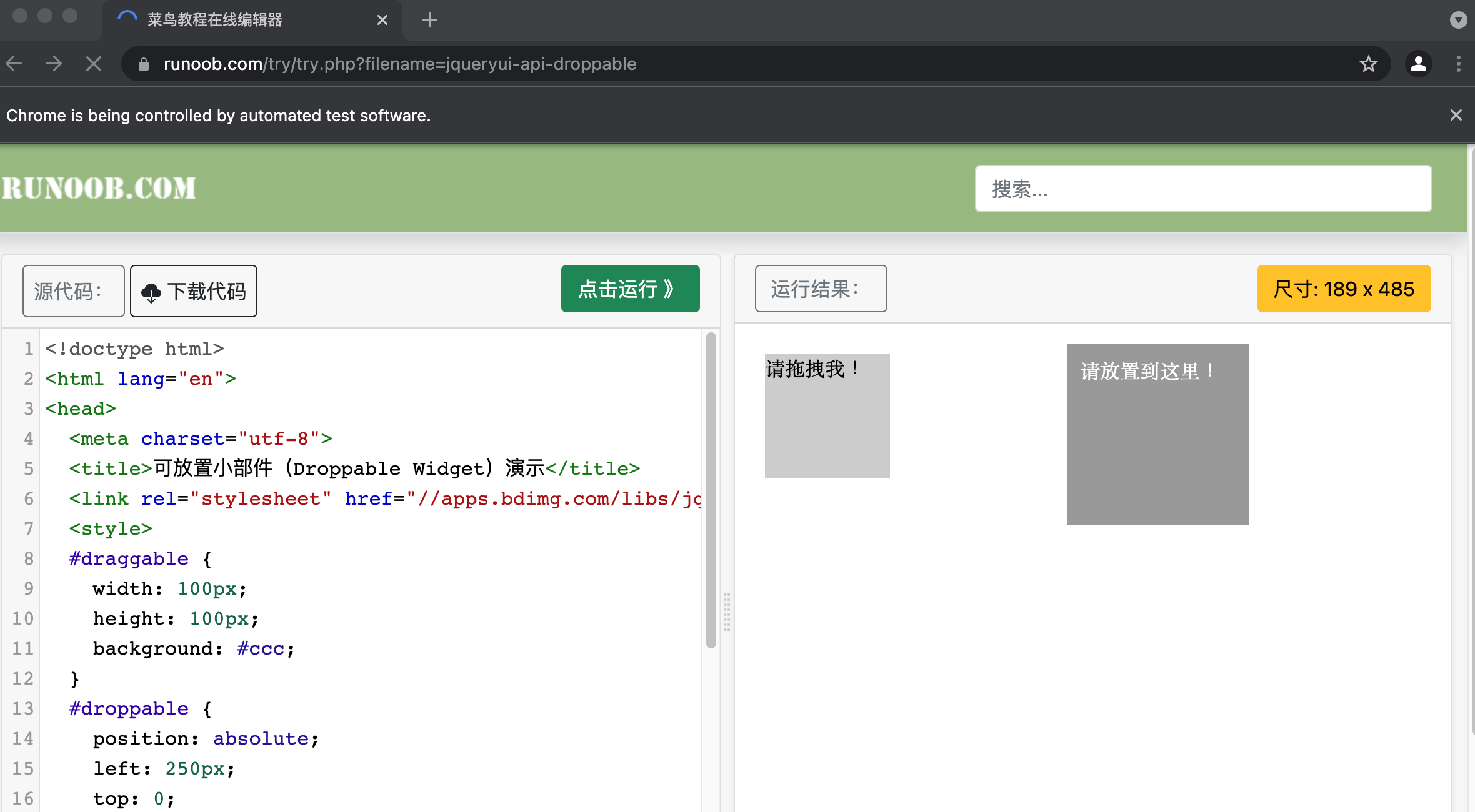
拖拽后的图片如下:
- 运行JavaScript
还有一些操作,Selenium没有提供API,例如下拉进度条,面对这种情况可以模拟运行JavaScript,此时使用execute_script方法即可实现,代码如下:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
import time
options = webdriver.ChromeOptions()
services = Service(executable_path='../chromedriver')
browser = webdriver.Chrome(service=services, options=options)
browser.get('https://www.zhihu.com/explore')
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.execute_script('alert("To Bottom")')
time.sleep(12)
browser.close()

这里利用execute_script方法将进度条下拉到最底部,然后就弹出了警告提示框。所以说有了execute_script方法,那些没有被提供API的功能几乎都可以运行JavaScript的方式实现。
- 获取节点信息
前面已经通过page_source属性获取了网页的源代码,下面就可以用解析库(如正则表达式、Beautiful Soup、pyquery等)从中提取信息了。
既然Selenium已经提供了选择节点的方法,返回的结果是WebElement类型,那么它肯定也有相关的方法和属性用来直接提取节点信息,例如属性、文本值等。这样我们就不需要通过解析源代码提取信息了。一起体验一下吧。
- 获取属性
可以使用get_attribute方法获取节点属性,但其前提是得先选中这个节点,示例如下:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
options = webdriver.ChromeOptions()
services = Service(executable_path='../chromedriver')
browser = webdriver.Chrome(options=options, service=services)
url = 'https://spa2.scrape.center/'
browser.get(url)
logo = browser.find_element(By.CLASS_NAME, 'logo-image')
print(logo)
print(logo.get_attribute('src'))
运行代码,它会驱动浏览器打开示例页面,然后获取其中class名称为logo-image的节点,最后打印出这个节点的src属性。控制台的输出结果如下:
<selenium.webdriver.remote.webelement.WebElement (session="c8bd8a8807d19a97572ebbbac014f8d8",
element="6d73a938-a051-4ba0-9b3b-3bb7057ae1d1")>
https://spa2.scrape.center/img/logo.a508a8f0.png
向get_attribute方法的参数传入想要获取的属性名,就可以得到该属性的值了。
- 获取文本值
每个WebElement节点都有text属性,直接调用这个属性就可以得到节点内部的文本信息,相当于pyquery中的text方法,示例如下:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
options = webdriver.ChromeOptions()
services = Service(executable_path='../chromedriver')
browser = webdriver.Chrome(service=services, options=options)
url = 'https://spa2.scrape.center/'
browser.get(url)
input = browser.find_element(By.CLASS_NAME, 'logo-title')
print(input.text)
控制台输出结果如下:
Scrape
- 获取ID、位置、标签名和大小
除了属性和文本值,WebElement节点还有一些其他属性,例如id属性用于获取节点ID、location属性用于获取节点在页面中的相对位置,tag_name属性用于获取标签的名称,size属性用于获取节点的大小、也就是宽高,这些属性有时候还是很有用的。示例如下:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
options = webdriver.ChromeOptions()
services = Service(executable_path='../chromedriver')
browser = webdriver.Chrome(service=services, options=options)
url = 'https://spa2.scrape.center/'
browser.get(url)
input = browser.find_element(By.CLASS_NAME, 'logo-title')
print('ID属性:', input.id)
print('location属性:', input.location)
print('tag_name属性:', input.tag_name)
print('size属性:', input.size)
运行结果如下:
ID属性: a9ae0c3c-677c-4c26-897d-526bf206e02b
location属性: {'x': 205, 'y': 13}
tag_name属性: span
size属性: {'height': 40, 'width': 73}
这里首先获取class名称为logo-title的节点,然后分别调用该节点的id、location、tag_name、size属性获取了对应的属性值。
- 切换Frame
网页中有一种节点叫做iframe,也就是子Frame,相当于页面的子页面,它的结构和外部网页的结构完全一致。Selenium打开一个页面后,默认是父Frame里操作,此时这个页面如果还有子Frame,它是不能获取子Frame里的节点,这时就需要使用switch_to.frame方法切换Frame。示例如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
options = webdriver.ChromeOptions()
services = Service(executable_path='../chromedriver')
browser = webdriver.Chrome(service=services, options=options)
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
browser.switch_to.frame('iframeResult')
try:
logo = browser.find_element(By.CLASS_NAME, 'logo')
except:
print('NO LOGO')
browser.switch_to.parent_frame()
logo = browser.find_element(By.CLASS_NAME, 'logo')
print(logo)
print(logo.text)
还是以演示动作链操作时的网页为例,首先通过switch_to.frame方法切换到子Frame里,然后尝试获取其中的logo节点(子Frame里并没有logo节点),如果找不到,就会抛出异常,异常被捕捉后,会输出NO LOGO。接着,切换回父Frame,重新获取logo节点,发现此时可以成功获取了。
控制台输出结果如下:
NO LOGO
<selenium.webdriver.remote.webelement.WebElement (session="a34f120f7337feed37fcca8aa3af86a7",
element="dea6705a-d39f-477a-b9ac-a7c042d274e6")>
所以,当页面中包含子Frame时,如果想获取子Frame中的节点,需要先调用switch_to.frame方法切换到对应的Frame,再进行操作。
- 延时等待
在Selenium中,get方法在网页框架中加载结束后才会结束执行,如果我们尝试在get方法执行完毕时获取网页源代码,其结果可能并不是浏览器完全加载完成的页面,因为某些页面有额外的Ajax请求,页面还会经由JavaScript渲染。所以,在必要的时候,我们需要设置浏览器延时等待一定的时间,确保节点已经加载出来。
等待方式有两种:一种是隐式等待,一种是显式等待。
- 隐式等待
使用隐式等待执行测试时,如果Selenium没有在DOM中找到节点,将继续等待,在超出设定时间后,抛出找不到节点的异常。换句话说,在查找节点而节点没有立即出现时,隐式等待会先等待一段时间再查找DOM,默认的等待时间是0。示例如下:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
options = webdriver.ChromeOptions()
services = Service(executable_path='../chromedriver')
browser = webdriver.Chrome(service=services, options=options)
browser.implicitly_wait(10)
browser.get('https://spa2.scrape.center/')
input = browser.find_element(By.CLASS_NAME, 'logo-image')
print(input)
运行结果如下:
<selenium.webdriver.remote.webelement.WebElement (session="278b608e46fa3c124a3fa7867b93a34e",
element="8b49c4ec-73bc-4176-948f-3a735fd84e55")>
这里我们用implicitly_wait方法实现了隐式等待。
- 显示等待
隐式等待效果其实不好,因为只规定了一个固定时间,而页面的加载时间会受到网络条件的影响。还有一种更适合的等待方式——显式等待,这种方式会指定要查找的节点和最长等待时间。如果在规定时间内加载出了要查找的节点,就返回这个节点;如果到了规定时间依然没有加载出点,就抛出超时异常。示例如下:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
options = webdriver.ChromeOptions()
services = Service(executable_path='../chromedriver')
browser = webdriver.Chrome(service=services, options=options)
browser.get('https://www.taobao.com')
wait = WebDriverWait(browser, 10)
input = wait.until(EC.presence_of_element_located((By.ID, 'q')))
button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '.btn-search')))
print(input, button)
这里首先引入WebDriverWait对象,指定最长等待时间为10,并赋值给wait变量,然后调用wait的until方法,传入等待条件。
这里先传入了presence_of_element_located这个条件,代表节点出现,其参数是节点的定位元组(By.ID, ‘q’),表示节点ID为q的节点(即搜索框)。这样做达到的效果是如果节点ID为q的节点在10秒内成功加载出来了,就返回该节点;如果超过10秒还没加载出来,就抛出异常。
然后传入的等待条件是element_to_be_clickable,代表按钮可点击,所以查找按钮时要查找CSS选择器为.btn-search的按钮,如果10秒内它是可点击的,就是按钮节点成功加载出来了,就返回该节点;如果超过10秒还是不可点击,也就是按钮节点没有加载出来,就抛出异常。
运行代码,在网速较佳的情况下是可以成功加载节点的。控制台输出结果如下:
<selenium.webdriver.remote.webelement.WebElement (session="84cc41714d2e631dd447da556a3585d0",
element="90a9a753-b7dc-45c5-b827-556a4f7a8fda")>
<selenium.webdriver.remote.webelement.WebElement (session="84cc41714d2e631dd447da556a3585d0",
element="16b85e70-d0cb-4217-ba93-77ea65a62474")>
可以看到,成功输出了两个节点,都是WebElement类型的。如果网络有问题,10秒到了还是没有成功加载,就抛出TimeoutException异常。
- 前进和后退
平常使用浏览器时,都是前进和后退功能,Selenium也可以完成这个操作,它使用forward方法实现前进,使用back方法实现后退。示例如下:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
import time
options = webdriver.ChromeOptions()
services = Service('../chromedriver')
browser = webdriver.Chrome(service=services, options=options)
browser.get('https://www.baidu.com/')
browser.get('https://www.taobao.com/')
browser.get('https://www.python.org/')
browser.back()
time.sleep(1)
browser.forward()
browser.close()
这里我们先连续访问了3个页面,然后调用back方法回到第2个页面,接着调用forward方法又前进到第3个页面。
- Cookie
使用Selenium,还可以方便地对Cookie进行操作,例如获取、添加、删除等。示例如下:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
options = webdriver.ChromeOptions()
services = Service('../chromedriver')
browser = webdriver.Chrome(service=services, options=options)
browser.get('https://www.zhihu.com/explore')
browser.add_cookie({'name':'name', 'domain':'www.zhihu.com', 'value':'germey'})
print(browser.get_cookies())
browser.delete_all_cookies()
print(browser.get_cookies())
这里我们先访问了知乎。知乎页面加载完成后,浏览器其实已经生成Cookie了。然后,调用浏览器对象的get_cookes方法获取所有的Cookie。接着,添加一个Cookie,这里传入一个字典,包含name、domain和value等键值。之后,再次获取所有的Cookie,会发现结果中多了一项,就是我们新加的Cookie。最后,调用delete_all_cookies方法删除所有的Cookie并再次获取,会发现此事结果就空了。
控制台输出结果如下:
[{'domain': '.www.zhihu.com', 'httpOnly': False, 'name': 'name', 'path': '/',
'secure': True, 'value': 'germey'}, {'domain': 'www.zhihu.com',
'httpOnly': False, 'name': 'KLBRSID', 'path': '/', 'secure': False,
'value': 'ed2ad9934af8a1f80db52dcb08d13344|1711448448|1711448445'},
{'domain': '.zhihu.com', 'expiry': 1742984447, 'httpOnly': False,
'name': 'Hm_lvt_98beee57fd2ef70ccdd5ca52b9740c49', 'path': '/',
'secure': False, 'value': '1711448448'},
{'domain': '.zhihu.com', 'httpOnly': False,
'name': 'Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49', 'path': '/',
'secure': False, 'value': '1711448448'},
{'domain': '.zhihu.com', 'expiry': 1806056445,
'httpOnly': False, 'name': 'd_c0', 'path': '/',
'secure': False, 'value': 'ABBY2F-lXhiPTq3E1glsHl-yDs3b6u15x4w=|1711448445'},
{'domain': '.zhihu.com', 'httpOnly': False, 'name': '_xsrf', 'path': '/',
'secure': False, 'value': '34131e3a-3c44-4ff2-857a-563bd80c2f3f'},
{'domain': '.zhihu.com', 'expiry': 1774520445, 'httpOnly': False,
'name': '_zap', 'path': '/', 'secure': False,
'value': '62da9fb2-33b9-4234-b23e-a192b6f507e4'}]
[]
通过以上方法操作Cookie还是非常方便的。
- 选项卡管理
访问网页的时候,会开启一个选项卡。在Selenium中,我们也可以对选项卡做操作。示例如下:
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
services = Service(executable_path='../chromedriver')
options = webdriver.ChromeOptions()
browser = webdriver.Chrome(service=services, options=options)
browser.get('https://www.baidu.com')
browser.execute_script('window.open()')
print(browser.window_handles)
browser.switch_to.window(browser.window_handles[1])
browser.get('https://www.taobao.com')
time.sleep(1)
browser.switch_to.window(browser.window_handles[0])
browser.get('https://python.org')
这里首先访问百度,然后调用execute_script方法,向其参数传入window.open()这个JavaScript语句,表示新开启一个选项卡。接着,我们想切换到这个新开的选项卡。window_handles属性用于获取当前开启的所有选项卡,返回值是选项卡的代号列表。要想切换选项卡,只需要调用switch_to.windows方法即可,其中参数是目的选项卡的代号。这里我们将新开选项卡的代号传入,就切换到了第2个选项卡,然后在这个选项卡下打开一个新页面,再重新调用switch_to.window方法切换回到第1个选项卡。控制台的输出结果如下:
['CDwindow-D97D968F0BD8741543EE3C6FB42692CF', 'CDwindow-E218A8DBC3864BBE41F29F61A2E1ED78']
- 异常处理
在使用Selenium的过程中,难免会遇到一些异常,例如超时、节点未找到等,一旦出现此类异常,程序便不会继续运行了。此时我们可以使用try except语句捕获各种异常。
首先,演示一下节点未找到的异常,示例如下:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
options = webdriver.ChromeOptions()
services = Service(executable_path='../chromedriver')
browser = webdriver.Chrome(service=services, options=options)
browser.get('https://www.baidu.com')
browser.find_element(By.ID, 'hello')
这里首先打开百度页面,然后尝试选择一个并不存在的节点,就会遇到节点未找到的异常。控制台的输出结果如下:
selenium.common.exceptions.NoSuchElementException: Message: no such element: Unable to locate element:
{"method":"css selector","selector":"[id="hello"]"}
(Session info: chrome=97.0.4692.71);
For documentation on this error,
please visit: https://www.selenium.dev/documentation/webdriver/troubleshooting/errors#no-such-element-exception
可以看到,这里抛出了NoSuchElementException异常,这通常表示节点未找到。为了防止程序遇到异常而中断运行,我们需要捕获这些异常,示例如下:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.common.exceptions import TimeoutException, NoSuchElementException
options = webdriver.ChromeOptions()
services = Service(executable_path='../chromedriver')
browser = webdriver.Chrome(service=services, options=options)
try:
browser.get('https://www.baidu.com')
except TimeoutException:
print('Time Out')
try:
browser.find_element(By.ID, 'hello')
except NoSuchElementException:
print('No Element')
finally:
browser.close()
这里我们使用try except语句捕获各类异常。例如,对查找节点的方法find_element_by_id捕获NoSuchElementException异常,这样一旦出现这样的错误,就会进行异常处理,程序也不会中断。控制台的输出结果如下:
No Element
- 反屏蔽
现在有很多网站增加了对Selenium的检测,防止一些爬虫的恶意爬取,如果检测到有人使用Selenium打开浏览器,就直接屏蔽。
在大多数情况下,检测到基本原理是检测浏览器窗口下的window.navigator对象中是否包含webdriver属性。因为在正常使用浏览器时,这个属性应该是undefined,一旦使用了Selenium,它就会给window.navigator对象设置webdriver属性。很多网站通过JavaScript语句判断是否存在webdriver属性,如果存在就直接屏蔽。
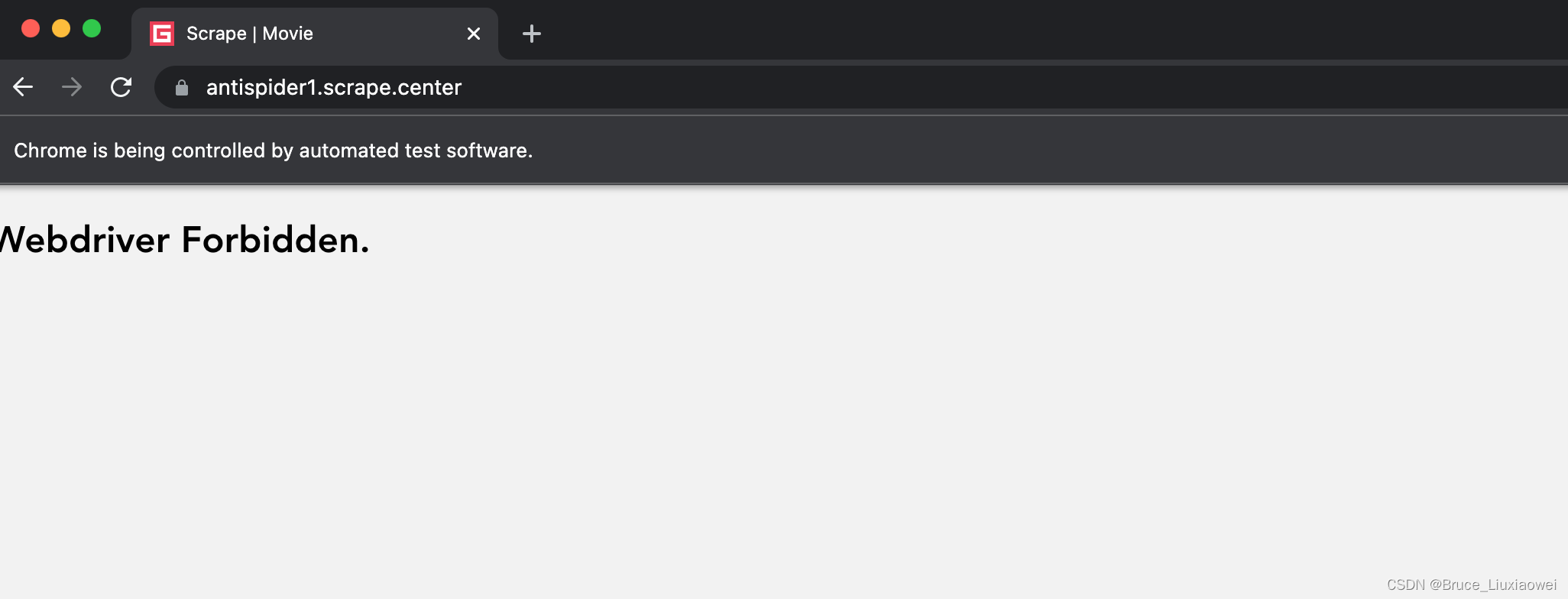
一个典型的案例网站https://antispider1.scrape.center/就是使用上述原理,检测是否存在webdriver属性,如果我们使用Selenium直接爬取该网站的数据,网站就会返回如图所示的页面:
在Selenium中,可以用CDP(即Chrome Devtools Protocol,Chrome开发工具协议)解决这个问题,利用它可以实现在每个页面刚加载的时候就执行JavaScript语句,将webdriver属性设置空,这里执行的CDP方法叫做Page.addScriptToEvaluateOnNewDocument,将上面的JavaScript语句传入其中即可。另外,还可以加入几个选项来隐藏WebDriver提示条和自动化扩展信息,代码实现如下:
from selenium import webdriver
from selenium.webdriver import ChromeOptions
from selenium.webdriver.chrome.service import Service
import time
option = ChromeOptions()
service = Service(executable_path='../chromedriver')
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_experimental_option('useAutomationExtension', False)
browser = webdriver.Chrome(service=service, options=option)
browser.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument',
{'source': 'Object.defineProperty(navigator, "webdriver",{get:() => undefined})'})
browser.get('https://antispider1.scrape.center/')
time.sleep(16)
这样就能加载出整个页面了,如图所示:
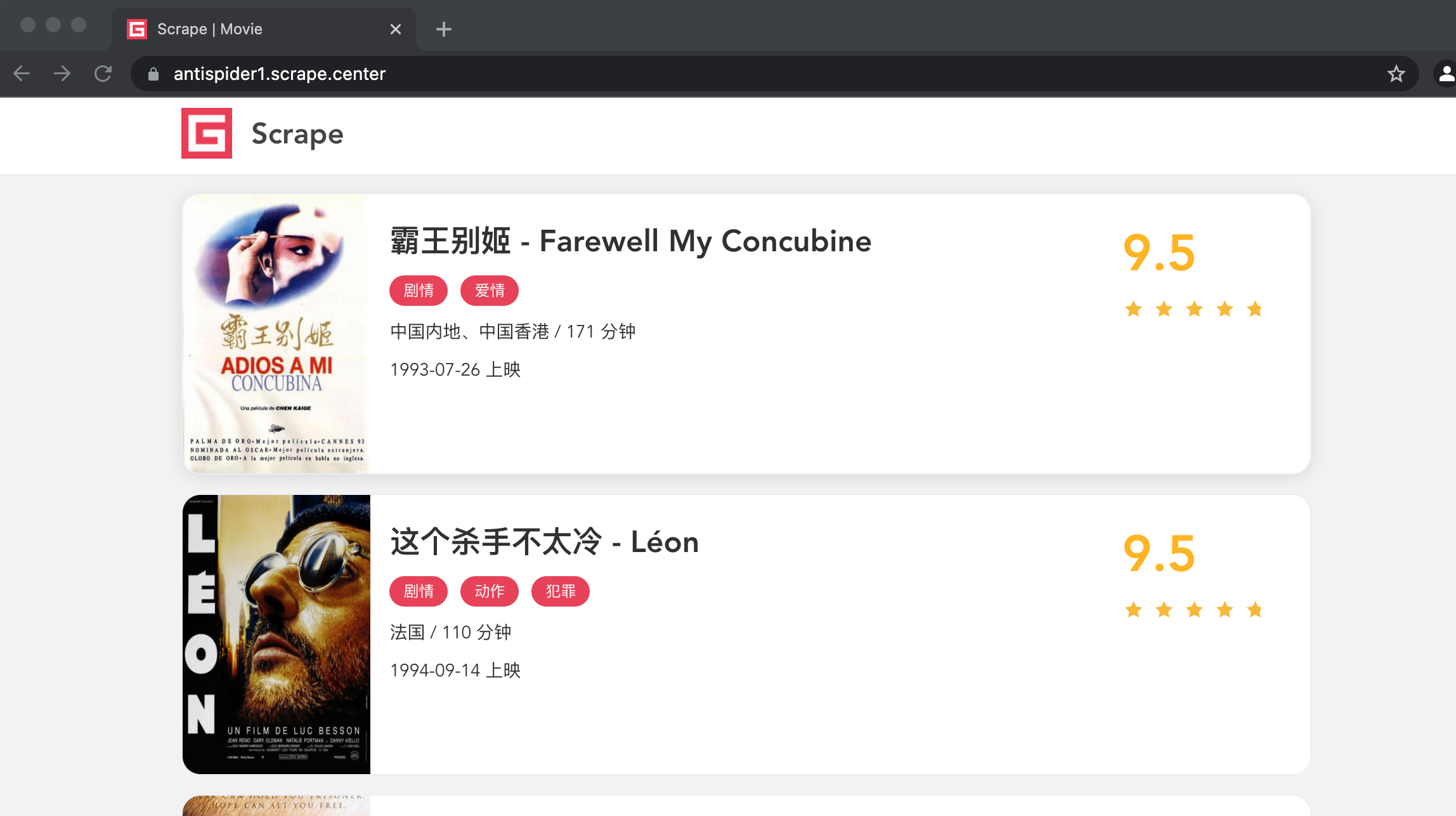
在多数时候,以上方法可以实现Selenium的反屏蔽。但也存在一些特殊网站会对WebDriver属性设置更多的特征检测,这种情况下可能需要具体排查。
- 无头模式
Chrome浏览器从60版起,已经开启了对无头模式的支持,即Headless。无头模式下,网站运行的时候不会弹出窗口,从而减少了干扰,同时还减少了一些资源(如图片)的加载,所以无头模式也在一定程度上节省了资源加载的时间和网络带宽。
我们可以借助ChromeOptions对象开启Chrome浏览器的无头模式,代码实现如下:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
option = webdriver.ChromeOptions()
option.add_argument('--headless')
services = Service(executable_path='../chromedriver')
browser = webdriver.Chrome(options=option, service=services)
browser.set_window_size(1366, 768)
browser.get('https://www.taonan.gov.cn')
browser.get_screenshot_as_file('preview.png')
这里利用ChromeOptions对象的add_argument方法添加了一个参数—headless,从而开启了无头模式。在无头模式下,最好设置一下窗口的大小,因此这里调用了set_window_size方法。之后打开页面,并调用get_screenshot_as_file方法输出了页面截图。
运行这段代码后,会发现窗口不会再弹出来了,代码依然正常运行,最后输出的页面截图如下图所示:
这样我们就在无头模式下完成了页面的爬取和截图操作。










