
在 Elastic 的搜索团队中,我们一直在探索不同的 ETL 工具以及如何利用它们将数据传输到 Elasticsearch,并在传输的数据上实现 AI 助力搜索。今天,我想与大家分享我们与 Meltano 生态系统以及 Meltano Elasticsearch 加载器的故事。
Meltano 是一个声明式的代码优先数据集成引擎,允许你在不同的存储之间同步数据。在 hub.meltano.com 上有许提取器 (extractors) 和加载器 (loaders) 可用。如果你的数据存储在 Snowflake 中,并且想要为你的客户构建一个开箱即用的搜索体验,你可能会考虑使用 Elasticsearch,在那里你可以基于你拥有的数据为客户构建语义搜索。今天,我们将重点介绍如何将数据从 Snowflake 同步到 Elasticsearch。
要求
Snowflake 账号。 你在注册后将收到以下所有账号信息,或者你可以从 Snowflake 面板中获取它们。
- 账户用户名
- 账户密码
- 账户标识符(查看此处的说明以获取它)
Snowflake 数据集
如果你创建了一个新的 Snowflake 账户,你将拥有用于实验的示例数据。
然而,我将使用一个公共空气质量数据集,其中包含二氧化氮(NO2)的测量数据。
Elastic 账号
访问 https://cloud.elastic.co 并注册账号。
点击 “Create deployment”。在弹出窗口中,你可以更改或保留默认设置。
一旦准备好部署,请点击 “Continue”(或点击 “Open Kibana”)。它将重定向你到 Kibana 仪表板。
转到 Stack Management -> Security -> API keys,并生成一个新的 API 密钥。
安装 Meltano
在我的示例中,我将使用 Meltano Python 包,但你也可以将其作为 Docker 容器安装。
pip install "meltano"添加 Snowflake 提取器
meltano add extractor tap-snowflake --variant=meltanolabs验证提取器
meltano invoke tap-snowflake --test添加 Elasticsearch 加载器
meltano add loader target-elasticsearch配置提取器和加载器:
有多种方法可以配置 Meltano 提取器和加载器:
- 编辑 meltano.yml
- 使用 CLI 命令,例如
meltano config {loader} set config_name config_value使用 CLI 交互模式
meltano config {loader} set --interactive我将使用交互模式。
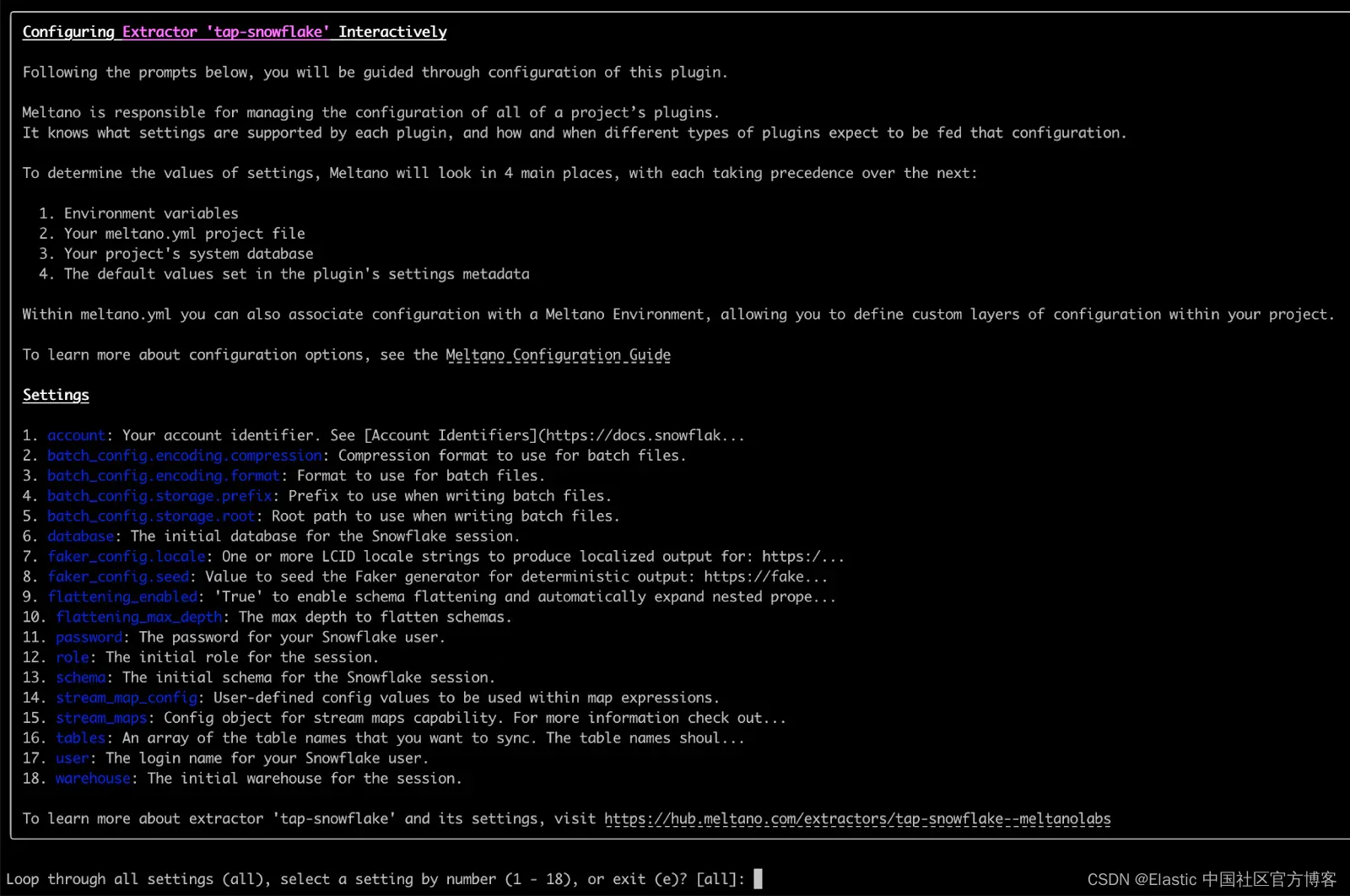
要配置 Snowflake 提取器,请运行以下命令并至少提供帐户标识符、用户名、密码和数据库。
meltano config tap-snowflake set --interactive你应该会看到以下屏幕,你可以在其中选择要配置的选项。
配置提取后,你可以测试连接。 只需运行以下命令:
配置 Elasticsearch 加载器并提供主机、端口、架构和 API 密钥,
meltano config target-elasticsearch set --interactive如果你想更改索引名称,可以运行以下命令并更改它:
meltano config target-elasticsearch set index_format my-index-namemeltano config target-elasticsearch set index_format my-index-name比如, 默认索引字符串定义为 ecs-{{ stream_name }}-{{ current_timestamp_daily}} ,结果为 ecs-animals-2022-12-25,其中流名称为 animals。
配置完所有内容后,我们就可以开始同步数据。
meltano run tap-snowflake target-elasticsearch同步开始后,你可以转到 Kibana 并看到创建了一个新索引并且有一些索引文档。
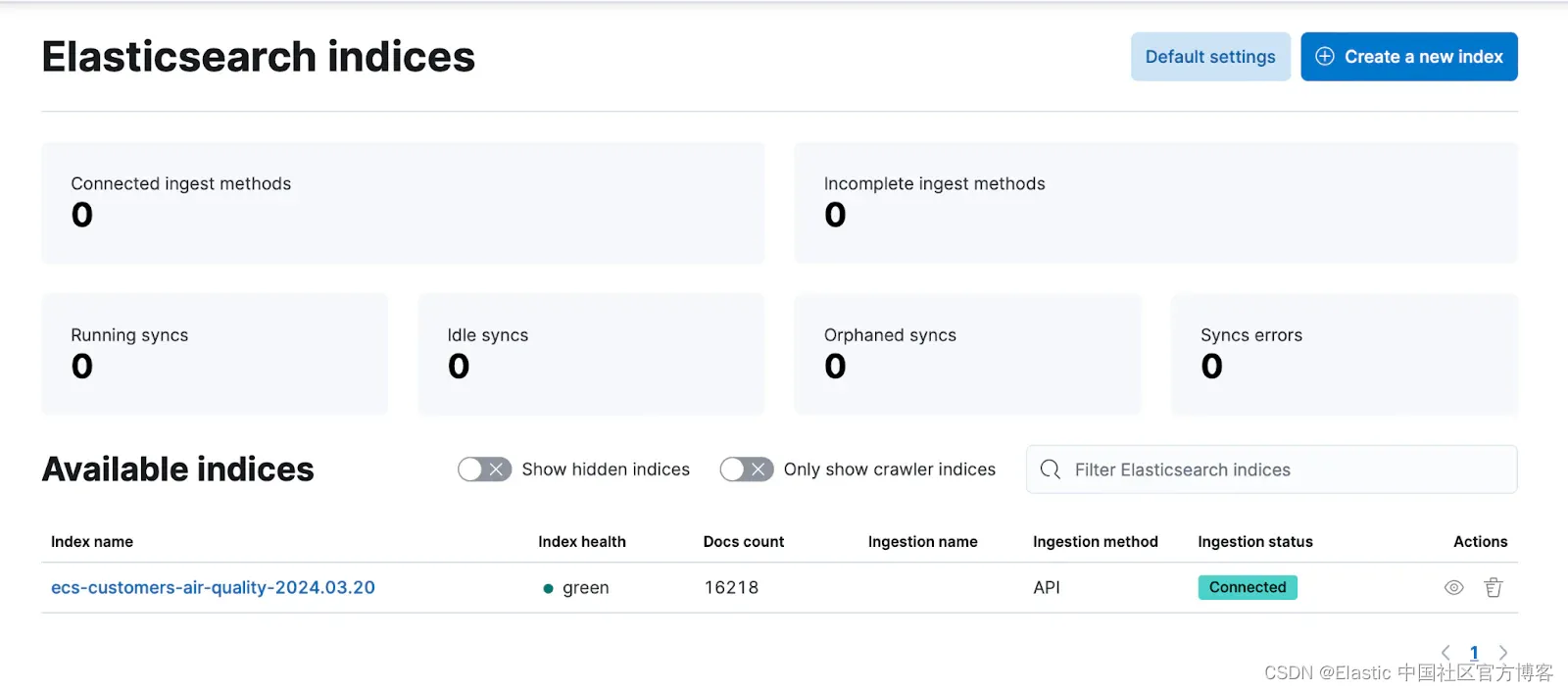
你可以通过单击索引名称来查看文档。 你应该查看你的文件。
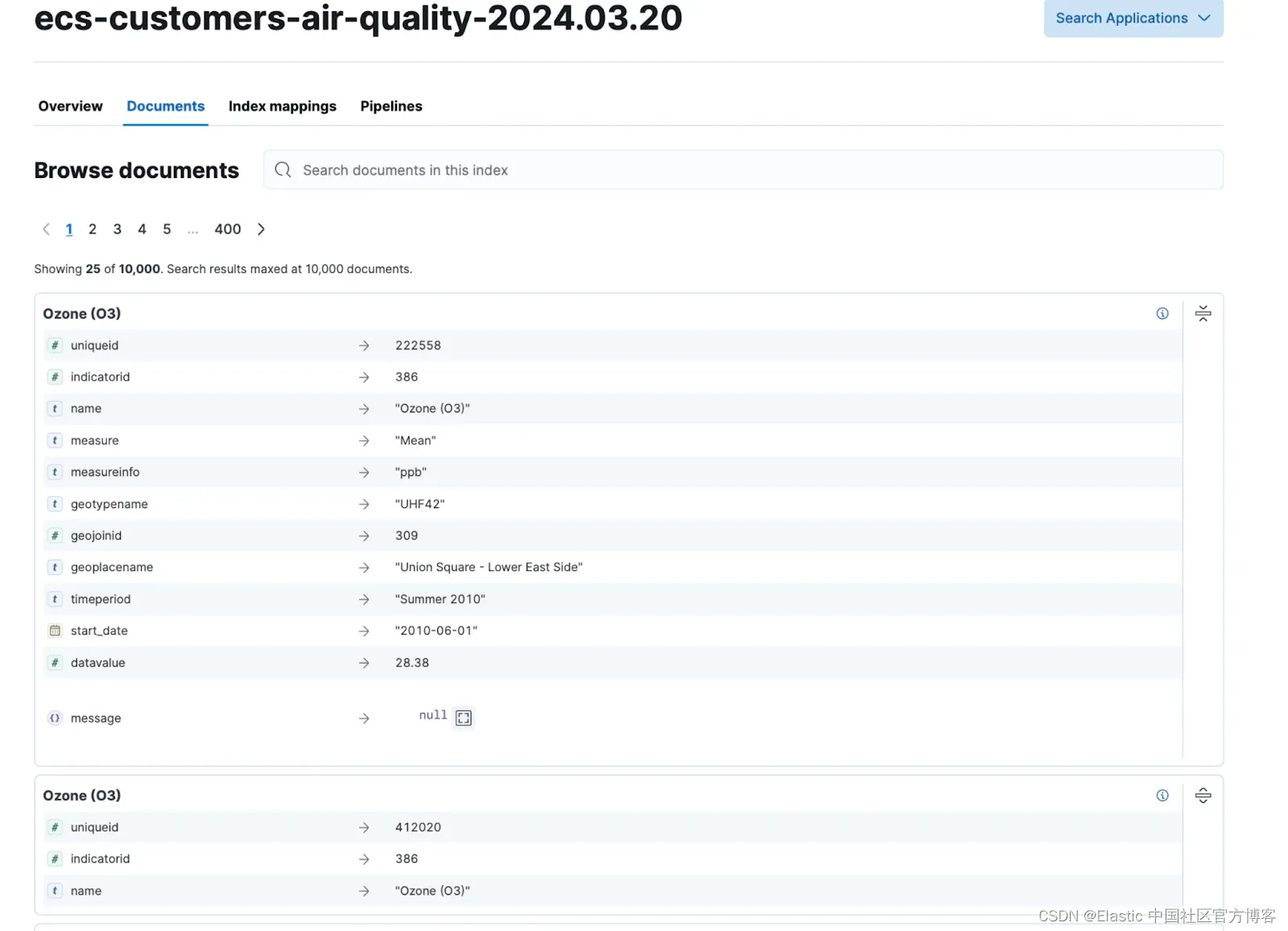
使用你的索引设置(或映射)
如果我们开始同步数据,加载器将自动创建一个具有动态映射的新索引,这意味着 Elasticsearch 将处理索引中的字段及其类型。 如果我们愿意,我们可以通过提前创建索引并应用我们需要的设置来更改此行为。 咱们试试吧。
导航到 Kibana -> DevTools 并运行以下命令:
创建新的摄入管道
PUT _ingest/pipeline/drop-values-10
{
"processors": [
{
"drop": {
"description": "Drop documents with the value < 10",
"if": "ctx.datavalue < 10"
}
}
]
}这将删除 datavalue < 10 的所有文档。
创建新索引
PUT my-snowflake-data应用索引设置
PUT my-snowflake-data/_settings
{
"index": {
"default_pipeline": "_ingest/pipeline/drop-values-10"
}
}更改 Meltano 中的索引名称
meltano config target-elasticsearch set index_format my-snowflake-data开始同步作业
meltano run tap-snowflake target-elasticsearch工作完成后,你可以看到索引中的文档比我们之前创建的要少

结论
我们已经成功地将数据从 Snowflake 同步到 Elastic Cloud。我们让 Meltano 为我们创建了一个新索引,并负责索引映射,我们将数据同步到了一个具有预定义管道的现有索引中。
我想强调在我旅程中记下的一些关键点:
Elasticsearch 加载器(Meltano Hub 上的页面)
- 它尚未准备好处理大量的数据。你需要调整默认的 Elasticsearch 配置,使其更加健壮。我已经提交了一个 Pull Request,以暴露 “request_timeout” 和 “retry_on_timeout” 选项,这将会有所帮助。
- 它使用 Elasticsearch Python 客户端的 8.x 分支,因此你可以确保它支持最新的 Elasticsearch 功能。
- 它同步发送数据(不使用 Python AsyncIO),因此当您需要传输大量数据时可能会相当慢。
Meltano CLI
- 它非常棒。你不需要 UI,所以一切都可以在终端中配置,这为工程师提供了大量的自动化选项。
- 你可以仅通过一个命令即可运行按需同步。不需要其他正在运行的服务。
复制/增量同步
- 如果你的管道需要数据复制或增量同步,你可以访问这个页面阅读更多信息。
另外,我想提一下 Meltano Hub 真的很棒。它易于导航并找到你需要的内容。此外,你可以通过查看有多少客户使用它们来轻松比较不同的加载器或抽取器。
如果你对构建基于 AI 的应用程序感兴趣,请在以下博客文章中查找更多信息:
- 在你的数据集上实现全文和语义搜索能力。
- 连接你的数据与 LLMs,构建问题 - 答案。
- 构建一个使用检索增强生成(RAG)模式的聊天机器人。
准备将 RAG 构建到你的应用中了吗?想要尝试不同的 LLMs 与向量数据库吗? 查看我们在 Github 上关于 LangChain、Cohere 等的示例 notebooks,并加入即将开始的 Elasticsearch 工程师培训!
原文:Ingest Data from Snowflake to Elasticsearch using Meltano: A developer’s journey — Elastic Search Labs










