一.什么是Hive
Apache Hive是一个建立在Hadoop上的数据仓库工具,它提供了类似于SQL的查询语言——HiveQL(类SQL语言),让用户能够轻松地对存储在Hadoop分布式文件系统(HDFS)中的大规模数据进行查询、分析和管理。Hive主要用于处理结构化数据,并且它的设计初衷是让那些熟悉传统数据库和SQL的人员能够快速上手大数据处理。
Hive将用户提交的HiveQL查询转换为MapReduce、Tez或Spark作业,在Hadoop集群上并行执行这些作业来处理数据。通过这种方式,用户可以利用Hadoop集群的计算资源来处理大规模数据,而无需编写复杂的MapReduce程序。
除了查询语言外,Hive还具有元数据存储、数据存储管理、数据提取转换加载(ETL)和数据访问控制等功能。它的架构包括Hive驱动程序、Hive服务、元数据存储和存储处理系统等组件,这些组件协同工作以提供高效的数据处理和查询服务。Apache Hive是一个强大的工具,使得用户可以在Hadoop集群上以SQL方式进行数据查询和分析,从而更轻松地处理大规模数据。
二.Hive功能实现原理
1.Apache Hive的功能实现原理涉及几个关键组件和流程
-
HiveQL到MapReduce/Tez/Spark转换:
- 用户使用HiveQL语言编写查询。
- Hive将HiveQL查询转换为相应的MapReduce、Tez或Spark作业。
- 这些作业负责在Hadoop集群上并行处理数据。
-
元数据存储:
- Hive使用数据库来存储元数据,包括表结构、分区信息、表位置等。
- 元数据存储在关系型数据库(如MySQL或Derby)中,默认情况下存储在Hive的元数据仓库中。
-
存储处理系统:
- Hive支持多种数据存储格式,包括文本文件、序列文件、ORC(Optimized Row Columnar)文件等。
- 当用户创建表时,可以指定表的存储格式以及数据存储的位置。
-
查询执行:
- 当用户提交查询时,Hive先通过元数据检索相关表的信息。
- 接着,Hive将HiveQL查询转换为相应的MapReduce、Tez或Spark作业。
- 作业被提交到Hadoop集群上执行。
- 结果被收集并返回给用户。
-
优化器和执行计划:
- 在生成作业之前,Hive会对查询进行优化。
- 这包括逻辑优化(如谓词下推、列剪裁等)和物理优化(如选择合适的连接算法、选择合适的文件格式等)。
- 优化后的查询会生成一个执行计划,该计划描述了如何在Hadoop集群上执行查询。
2. 流程图形化表示
Hive利用Hadoop生态系统的分布式计算和存储能力,通过将SQL查询转换为底层作业来实现对大规模数据的查询和分析。它的元数据存储和优化器等组件确保查询的高效执行和性能优化。
表1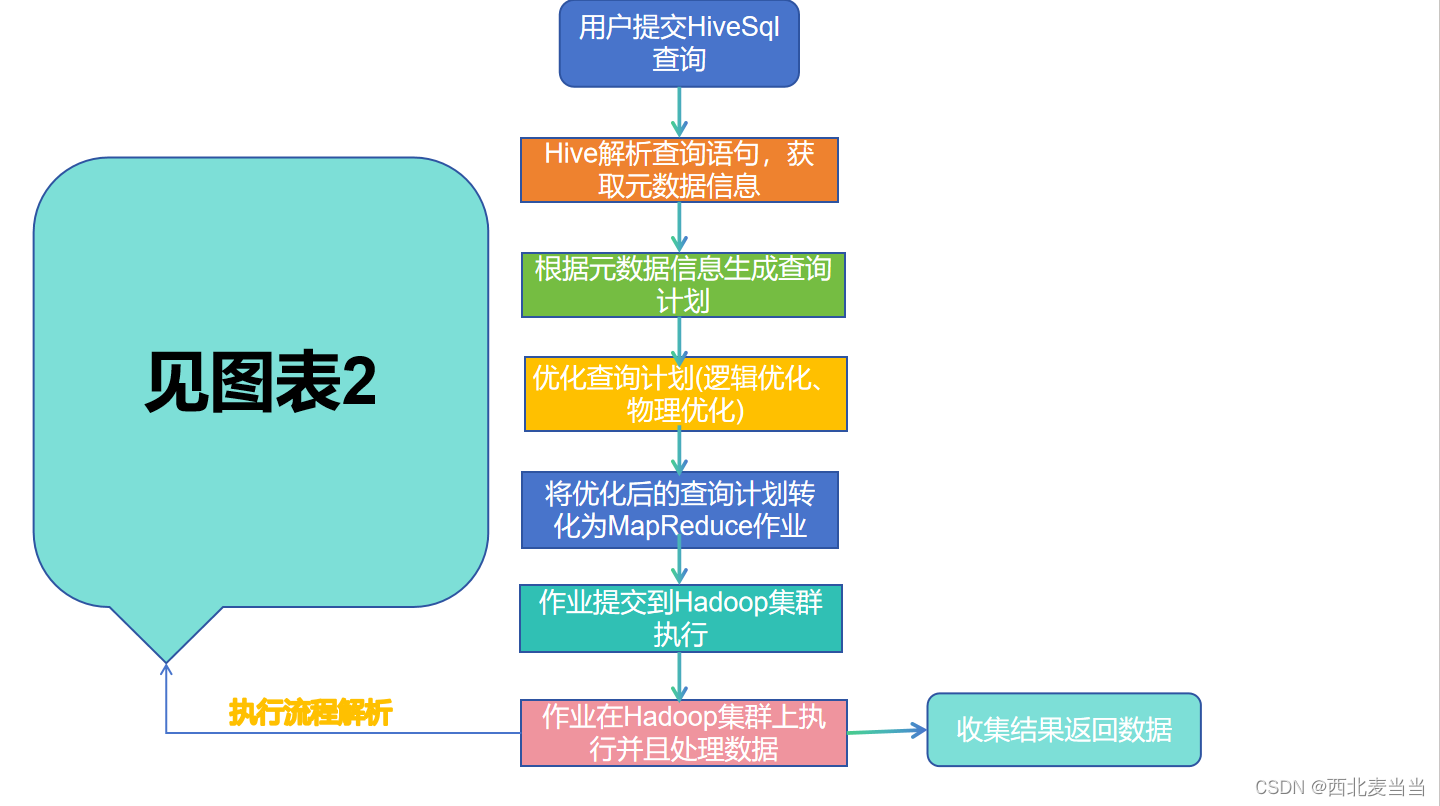
表2

hive如何将hdfs上的数据转为结构化的表数据?
举例:表名:tb_stu
| ID INT | NAME VARCHAR(20) | GANDER VARCHAR(20) |
|---|---|---|
| 1 | 张三 | 男 |
| 2 | 李四 | 女 |
| 3 | 王五 | 男 |
三.Hive的部署
内嵌模式:
1、元数据使用外置的RDBMS,常见使用最多的是MySQL。
2、不需要单独配置metastore 也不需要单独启动metastore服务
缺点:
如果使用多个客户端进行访问,就需要有多个Hiveserver服务,此时会启动多个Metastore
有可能出现资源竞争现象。

本地模式:
1、元数据使用外置的RDBMS,常见使用最多的是MySQL。
2、不需要单独配置metastore 也不需要单独启动metastore服务
缺点:
如果使用多个客户端进行访问,就需要有多个Hiveserver服务,此时会启动多个Metastore
有可能出现资源竞争现象。

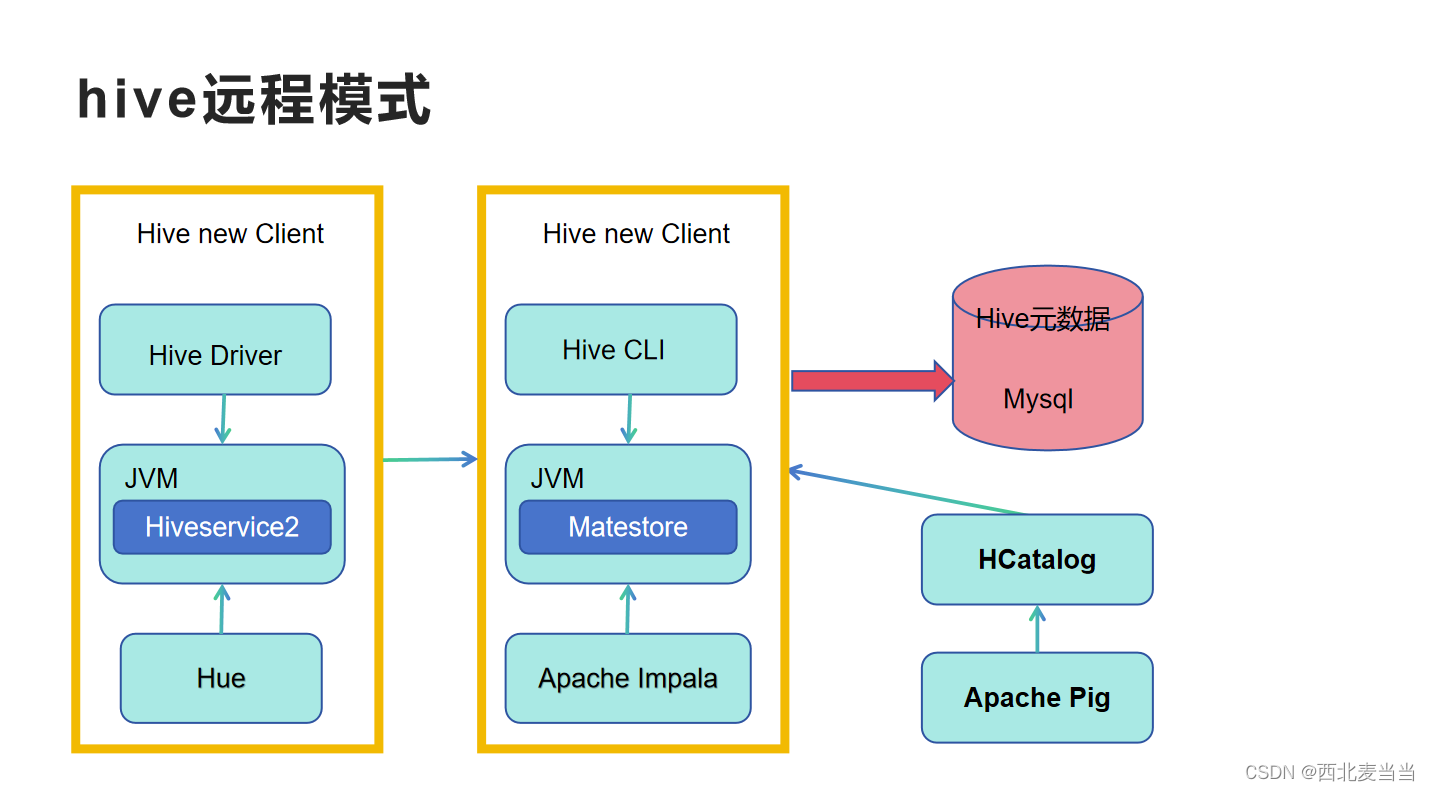
远程模式:
1、元数据使用外置的RDBMS,常见使用最多的是MySQL。
2、metastore服务单独配置 单独手动启动 全局唯一。
缺点:
这样的话各个客户端只能通过这一个metastore服务访问Hive。企业生产环境中使用的模式,支持多客户端远程并发操作访问Hive。也是我们课程中使用的模式。
 四.Hive远程客户端的使用
四.Hive远程客户端的使用
1.Hive使用
使用一代客户端在本地服务器上连接hive完成sql操作,需要先把metastore的元数据管理服务启动起来。那么我们必须先把虚拟机启动,启动集群服务(此处的演示我使用的是Finalshell操作终端)。
start-all.sh
检查集群启动状态:
jps
启动materstore服务:
nohup hive --service metastore &输入指令然后两次回车(此条语句目的让服务后台运行,避免占用终端界面)
启动成功检测:


metastore启动完成,再次启动hiveserver2
nohup hive --service hiveserver2 &
检测启动状态(需要等待几分钟)
lsof -i:10000
2.Datagrip连接使用


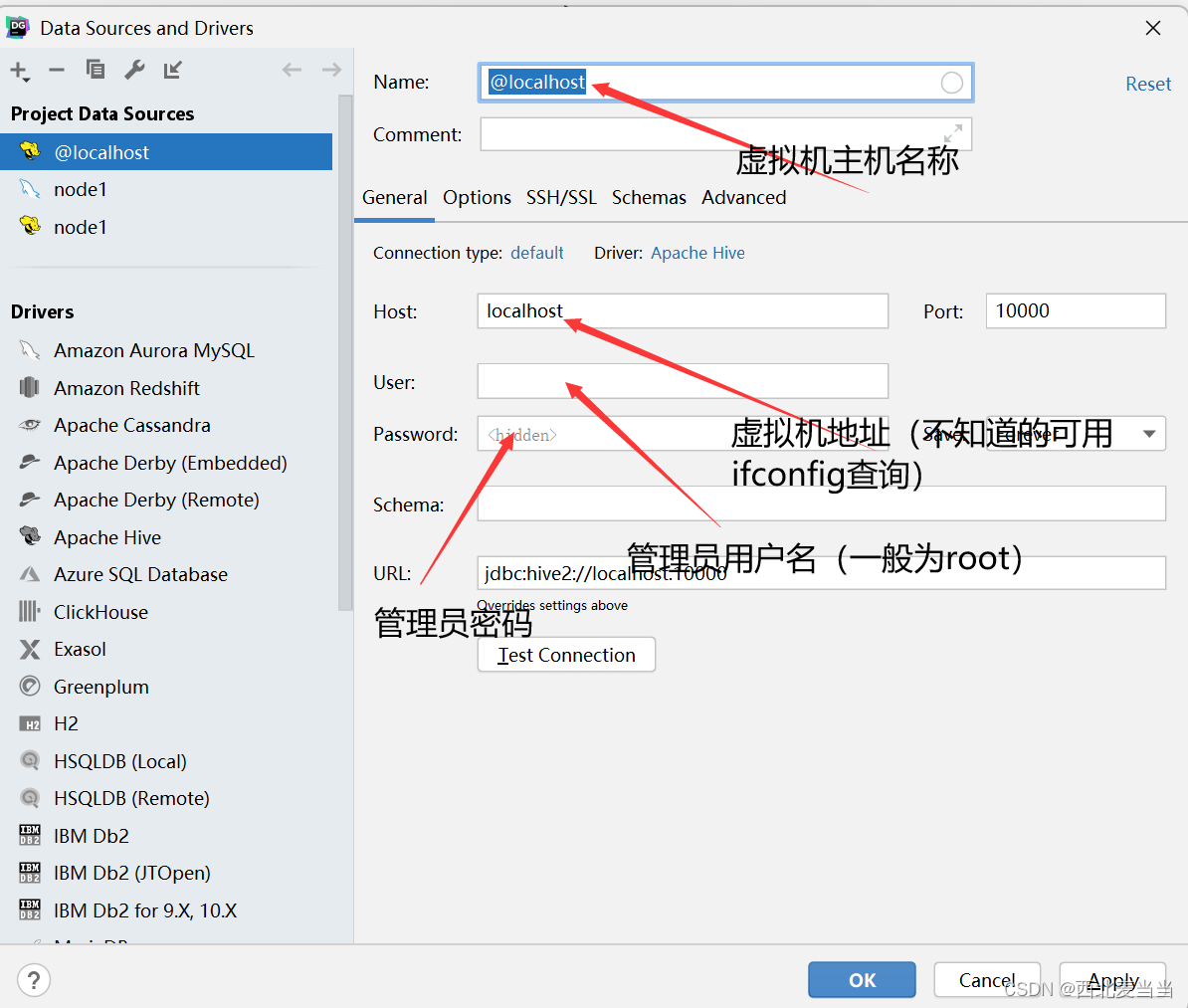
至此我们便启动并连接完成!
五.结语
总的来说,Apache Hive作为一个建立在Hadoop生态系统之上的数据仓库工具,为处理大规模数据提供了一个强大而灵活的解决方案。通过其类SQL的查询语言HiveQL,用户可以轻松地在Hadoop集群上进行数据查询、分析和管理,从而实现对结构化数据的高效处理。我简要介绍了下从HiveQL到作业执行的整个过程以及Hive是如何利用Hadoop的分布式计算和存储能力来处理大规模数据以及Hive的远程连接使用。然而,随着大数据技术的不断发展和进步,Apache Hive也在不断演进。未来,我们可以期待更多的性能优化、更灵活的查询引擎以及更丰富的功能扩展,以满足不断增长的数据处理需求。无论是面对传统的数据仓库挑战还是新兴的大数据应用场景,Apache Hive都将继续发挥重要作用,并为用户提供可靠的数据处理解决方案。









