第四章 SQL
-
基本内容
-
SQL介绍
- 特点
- 体系结构
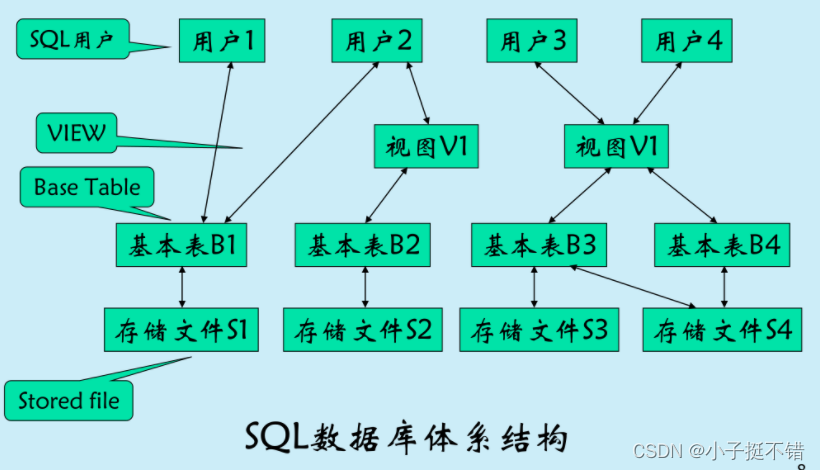
-
数据库存储结构
- 逻辑存储结构
- 物理存储结构
-
- 主数据文件,.mdf
- 数据库起点,指向数据库中的其他文件
- 每个数据库 有且仅有一个主数据文件
- 次要数据文件,.ndf
- 除了主数据文件之外的文件都是次要数据文件
- 一个数据库科可以包含零个或多个次要数据文件
- 事务日志文件,.ldg
- 存储所有事物及每个事务对数据库的修改,用于对数据库的恢复,
- 每个数据库至少有一个日志文件
- 主数据文件,.mdf
-
数据库主要对象
- 用户创建数据库时仅仅创建了物理文件,逻辑数据库在逻辑角度对数据库进行描述,提供给用户逻辑视图
- 主要对象有:表table,视图view,关系,存储过程procedure,触发器trigger,索引index,约束constrain,规则rule,角色role,用户user,用户定义数据类型,用户自定义函数function
-
数据库组成
- 系统数据库,用于记录系统信息的数据库
- master
- 记录SQL Server的所有系统级信息,还记录其他数据库是否存在,以及这些数据库文件的位置
- 需要经常备份master数据库,修改后备份一次
- model
- msdb
- resource
- tempdb
- master
- 用户数据库
- 示例数据库
- 系统数据库,用于记录系统信息的数据库
-
数据库数据类型
- 整数类型
- bigint,8字节
- int,4字节
- small,2字节
- tinyint,1字节
- 浮点数类型
- real,4字节,可以存储正或负的十进制数
- float,8字节
- decimal,小数
- numeric
- 字符类型
- char(n),固定长度字符串,1字节,n取值为1~8000
- varchar(n | max),可变长度字符串
- text,可变长度字符串
- 日期和时间类型
- date,3字节, 数据格式为“YYYY-MM-DD”
- time,5字节, 据格式为“hh:mm:ss[.nnnnnnn]”
- 整数类型
-
数据库操作, @面试
-
创建数据库
-

-
创建模式,创建模式就是创建数据库
-
- 也可以在创建表的时候,显示指明模式,从而同时创建二者
-
创建表
create table student(sno char(6) not null unique, sage int, ssex char(2), cno char(6) not null, constrain c1 check ssex in ('男','女'), constarin pk primary key(sno), constrain fk foreign key (cno));- constrain规定了列级(作用域一列)或者表级(作用于整个表)的约束
- 其中,可以使用创建域来约束域
-
修改表
alter table add 列名 类型alter table drop 列名 [cascade | restrict]alter table modify 列名 类型- 创建约束
-
- 添加主键约束
Alter table 表名 add Constraint 主键名 primary key(字段)-
- 添加唯一约束
Alter table 表名 add Constraint 约束名 unique(字段)-
- 添加默认约束
Alter table 表名 add Constraint 约束名 default(默认内容) for 字段名-
- 添加检查约束
Alter table 表名 add Constraint 约束名 check (字段表达)-
- 添加外键约束
Alter table 表名 add Constraint 约束名 foreign key(字段) references 表名(字段名)
-
-
撤销表
drop table table_name
-
删除数据,删除一个或多个元组
delete from table [where P]
-
插入数据, 列名和值一一对应 @面试 ,没有写到的属性为null
- 可以省略列名,默认为全部属性且values的值必须按照顺序进行排布。
- 成批插入数据是把一次子查询的所有结果插入指定表中
- DBMS在执行插入语句后会自动检查是否破坏了完整性约束
insert into table_name(属性列) values(值|子查询)
-
更新数据, 主码数据不允许修改 @面试
update table_name set 列名 = 表达式|子查询
-
截断表,
truncate table table_name -
- 比delete更快,且使用更少的事务和系统资源
- 操作不可以回滚,delete可以回滚
-
索引
-
- 索引的数据结构
- B树/B+树
- Hash索引
- 建立索引
- 有的DBMS自动创建索引,建立在PK上
- 也可以由DBA自己建立索引
create [unique] index index_name on table_name (列表名)
- 非聚簇索引
- 聚簇索引, @面试
-
- 一个表只能有一个聚簇索引,但是聚簇索引可以包含多个列
- 适用于:很少增删;很少对变长列修改
- 找到一个值后,寻找后续索引可以直接找相邻物理位置,有助于提高查询性能
- 删除索引
- 索引选择 @面试
-
- 对某一列进行索引可以提高其查询效率,还可以加快连接
- 带索引的表会占用更多空间,同时对数据进行插入、更新等操作会有更大的代价
- 更适合建立索引情况
- 查询操作多于更新操作
- 经常出现在where中的属性
- 索引优化 @面试
- 在进行查询操作时不要使用非索引列
- 可以使用多列索引提高效率
- 优先使用选择性强的索引,即在选择性强的列设置索引
- DBMS自动维护和使用索引,不需要用户管理
- 索引失效的情况
- 对数据进行增删
- 没有在索引列进行查找
- 使用like模糊查询
- 索引列的判断条件是is NULL或is not NULL
- 索引的数据结构
-
元组操作
-
-
查询select

- select选中的属性名默认是all,也可以使用distinct来消除重复值
- select中可以使用四则元素对属性的域进行修改,但是这种修改不会执行到数据库中
- 执行和编写顺序:join->where->group by->having
- group by中的属性必须在select中写出
- 查询语句与关系代数对应关系
- select——投影
- where——选择
- join——连接
-
聚集函数
- avg、max、min、sum(对数值类型进行操作)、count(对任意类型操作)
- 常常用在having操作中
- 不能出现在where子句中
-
like模糊查询, @面试
- % 包含 零个或更多 字符的任意字符串。
- _(下划线) 任何 单个 字符,如a_b可以是abb,aab,ahb
- 指定 范围 (例如 [a-f]) 或集合 (例如 [abcdef])内的任何单个字符。
- [^] 不在指定范围(例如 [^a - f])或集合(例如 [^abcdef])内的任何单个字符。
- 实例
- LIKE ‘赵%’ 将搜索姓赵的人名或者说以汉字‘赵’ 开头的字符串(如 赵刚、赵小刚等)。
- LIKE ‘%刚’ 将搜索以汉字‘刚’结尾的所有字符串(如 刘刚、李小刚等)。
- LIKE ‘%小%’ 将搜索在任何位置包含汉字‘小’的所有字符串(如赵小刚、李小刚、山本小郎等)。
- LIKE ‘_小刚’ 将搜索以汉字“小刚”结尾的所有三个汉字的名称(如 李小刚、赵小刚)。
-
-
集合操作
-
-
union:并集
-
intersect:交集
-
except:差集 @面试
-

-
以上都是自动去重,若不需要自动去重在后面加上all
-
order语句只能出现在最后
-
-
嵌套子查询
- where + 嵌套
-
集合成员比较where expression (not) in 子查询
-
- 实例

-
集合之间比较where expression comparison_operator some|any子查询
-

-
集合基数where (not) exist 子查询
-
- from + 嵌套
- having + 嵌套
- 可以用嵌套子循环替换and操作和一些自然连接, 优化效率
- where + 嵌套
-
空值操作, @面试
- SQL中有三种逻辑值:true,false,unknown
- 任何值(包括null)与null进行 逻辑运算 都会返回unknown
- null与 数值 进行运算时,会返回null
- 在where 和having条件中,unknown会被视作false处理
- 在check约束中,unknown会被视作true处理
- 空值判断只可以使用 name (not) is null, 可以使用 =,但是最好使用 is, 判断条件未必是个单值,如果返回值多个则会出错
- 聚集函数中,只有count不会忽视null进行操作
-
视图, @面试
-
-
特点
- 对不同用户提供 个性化服务
- 提高 数据库安全性 ,限制了用户对数据的访问范围
- 提供了 逻辑独立性
- 不会出现数据冗余 ,基表中数据发生变化,视图中数据也会变化
- 不占用存储空间 ,以定义的方式存储在数据库中,使用时只是执行了查询语句
- 视图上还可以定义视图
-
创建视图
-
撤销视图
-
插入视图
-
修改视图
-

- 最好不使用视图更新,有些视图是无法被更新的,更新视图是基于更新基本表的情况更新的
- 视图更新约束
- 只有视图包含基本表得主键时才可以更新
- 目标列不包含聚集函数
- 不使用unique和distinct
- 不包括group by
-
视图查询
- 检查视图是否存在
- 将视图临时实体化,生成临时表,
- 查询视图转化为查询临时表
- 查询完毕删除临时表
- 也可以使用视图消解法,即将对视图得查询语句进行修改,然后转化为对基表得查询语句
-
-
关系连接join @连接 第三章 关系数据库
- 内连接 inner join
-
select * from table1 inner join table2 on condition- 等值连接
select * from T_student s inner join T_class c on s.classId <运算符> c.classId
- 外连接 outer join
-
- 全连接,对于并集中没有的用null填充
- 自连接self join, @面试
-
- 当一个表需要多次使用时使用
- 交叉连接cross join
-
compute by
- group by返回的数据集中只保留合计数据,并没有保留原始数据,使用compute by函数可以使得合计数据作为附加项附加到原始数据集的最后
- compute by前面必须使用order by
-
嵌入式SQL, @面试
- SQL使用方式
- 实现方式
- 嵌入式SQL在嵌入高级语言时,已经确定,无法更改
-
动态SQL, @面试
- 传统在高级语言中嵌入SQL(例如JDBC)需要预先编译好语句,虽然可以用占位符但是还是不方便
- 根据用户输入或者外部条件动态组合的SQL语句,根据不同的需求完成不同的任务
- 经过预处理和执行阶段
- 预处理只需要执行一次
- 多次调用需要多次执行编译
-
-
T-SQL,transact SQL, @面试
-
-
数据类型
-
系统定义数据类型
-
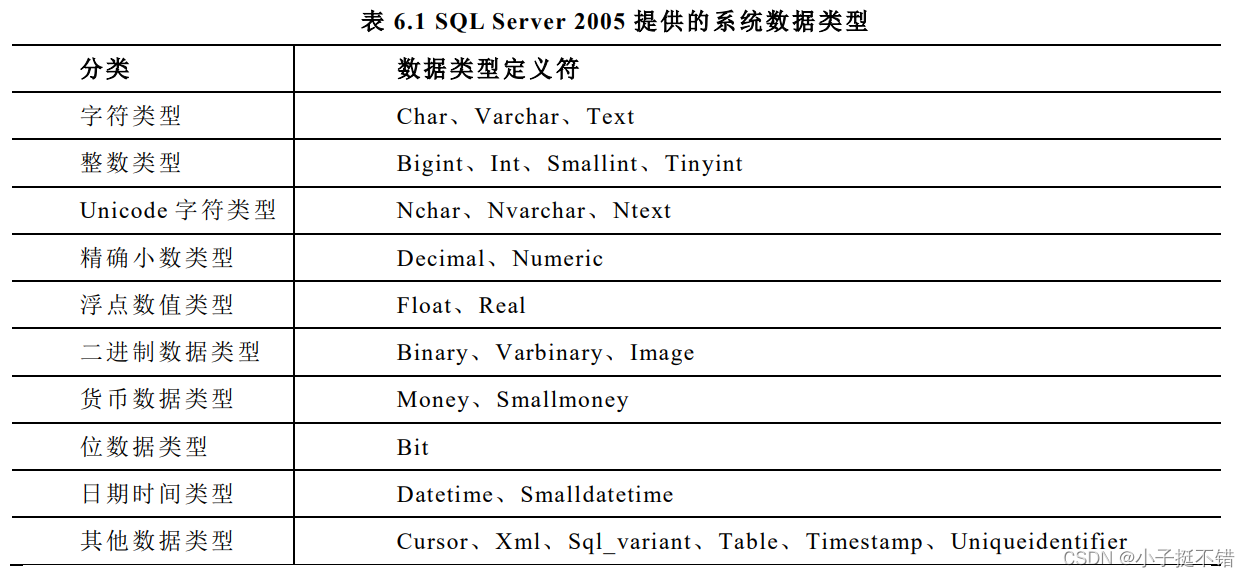
-
用户自定义数据类型
-
- 一般情况下,当多个表的列中要存储同样类型的数据,且想确保这些列具有完全相同的数据类型、长度、取值范围和是否等特点时,可使用用户定义数据类型。
- SQL Server 为 用 户 提 供 了 两 种 方 法 来 创 建 自 定 义 数 据 类 型 即
- 使 用 SQL ServerManagement Studio 创建用户自定义数据类型
- 调用 系统存储过程 sp_addtype 创建用户自定义数据类型。
-
-
常量
- 整型常量
- 实型常量
- 日期型常量
- 货币常量
-
变量
-
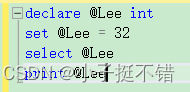
局部变量(必须先定义后使用)
- 命名: @ 标识符
- 定义:
declare @标识符 类型 - 赋值
set @标识符 = 值select @标识符 = 值- set 和select区别
- set一次只能赋值一个变量,select一次可以赋值多个变量
set @变量1 = value1set @变量2 = value2select @变量1 = value1,@变量2 = value2
- 当表达式返回多个值时,select会返回最后一个,而set会报错
set @变量 = (select 属性 from 表)(报错)select @变量 = 属性 from 表
- 当表达式返回空值时, set会赋空值,select则保持不变
set @变量 = (select 属性 from 表)(报错)select @变量 = 属性 from 表
- 使用标量子查询时,如果无返回值,SET和SELECT一样,都将置为NULL
- set一次只能赋值一个变量,select一次可以赋值多个变量
- 用途:函数和存储过程参数,局部使用,供用户使用
- 强制转化操作
- 初始化为null
-
全局变量
- 命名@@标识符
- 常见的由系统提供,存储系统的信息

-
-
流程控制
-
- begin and相当于程序设计语言中的一个语句块,{ }
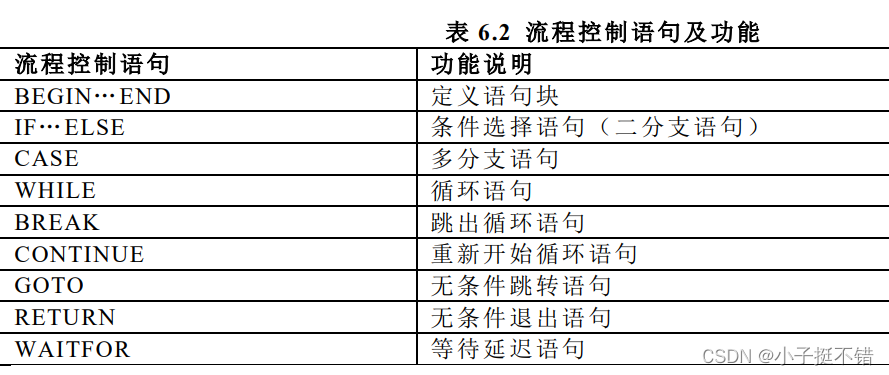
- 批处理中的语句一旦出现错误,和事务一样,一句也不执行
- begin and相当于程序设计语言中的一个语句块,{ }
-
函数
-
- 字符串函数
- 数学函数
- 时间和日期函数
DATENAME(YYYY,GETDATE())返回日期中某部分字符串DATEPART(MM,GETDATE())返回日期中某部分数据DATEADD(datepart,number,date)在一个日期格式上增加间隔,返回值还是日期值DATEDIFF(datepart,startdate,enddate)计算两个日期的间隔GETDATE()获取当前的日期
- 用户自定义函数
create function 【database_name】 function_name(【@参数名 参数类型】)returns**参数数据类型**asbeginfunction bodyreturn**返回参数**
end
- 使用函数
-
游标
-
- 可以被视作一个指针,可以指向结果集中的任意一个位置并对其进行处理,
- 使用过程:声明游标-》打开游标-》检索游标-》关闭游标-》释放游标
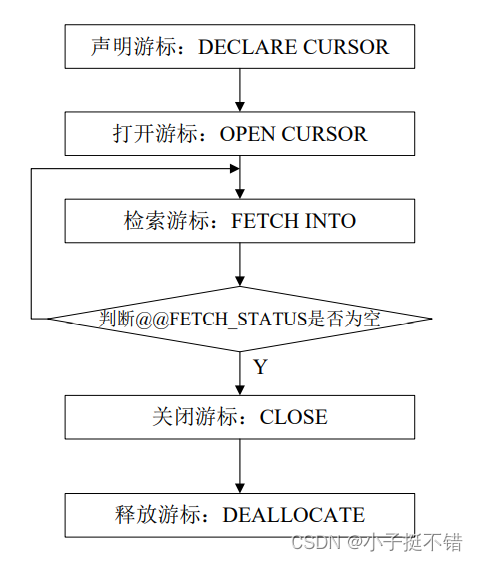
- 声明游标
- 打开游标
- 检索游标
- 检查游标,是否有更多行可以提取,使用系统变量 @@FTECH_STATUS
WHILE @@FTECH_STATUS = 0BEGINFETCH [NEXT | PRIOR | FIRST | LAST] FROM 游标名 into 变量名称
END
- 关闭游标,删除游标
-
- 关闭游标并释放资源,关闭了的游标与原来的查询结果集不再关联,可以被再次打开与新的结果集进行关联
- 游标系统变量
- @@CURSOR_ROWS 表示当前打开的游标中存在的记录数量。
- @@FETCH_STATUS 返回被 FETCH 语句执行的最后游标的状态
-
存储过程和触发器
- 存储过程
-
-
存储过程经数据库编译后存储在数据库服务端,应用程序只需要调用一次代码便可以执行存储过程的所有代码,类似于程序设计语言中的函数
-
优点
- 执行前已经存储在数据库中,比起函数有更好的性能
- 用户不用访问数据库的数据和对象
- 提供了安全性机制
- 减少了网络通信量,用户只需要执行存储过程即可,存储过程内大量的代码已经在服务器中存储
-
分类
- 系统存储过程:用于完成某些特殊的功能,以sp_开头
- 用户自定义存储过程
-
创建存储过程
-

-
执行存储过程
-
- 触发器, @面试
-
-
创建触发器
- 实现设置好:触发器名称、触发器关联的表、触发器触发的时间、触发器触发执行的操作的类型(uupdate、delete、insert)、触发器触发后执行的语句
-
分类
- update触发器:检查修改操作是否符合要求
- insert触发器:检查插入操作是否符合要求
- delete触发器:用作级联删除和记录外键的删除操作
-
原理
- 触发器创建时会创建两个表, deleted和inserted表 ,他们都是 临时表 ,DBMS会自动管理这些临时表, 触发器完成后自动删除 @面试
- deleted表中存储的是被delete操作和update操作影响的数据,在从原表中操作后会自动记录一份副本到deleted表中
- inserted表中存储的是inserted操作和update操作中受影响的数据,插入后会自动存一份副本到inserted表中
-
创建触发器
-

-
触发器性能考虑
- 触发器执行的语句尽量简单
- 触发器执行速度快,因为deleted和inserted表都在缓存中
- 尽量减少触发器中ROLLBACK语句使用,系统开销特别大
- 在使用触发器前最好还是考虑使用check约束
-
-










