
“
查询延迟高:每一次启动脚本,hive都会去调用mapdurce导致其启动时间长。
复杂查询性能有限:对于一些复杂场景(如:行列转换、递归查询等)。
数据更新和事务性操作不佳:不支持update、delete语句。
ACID:hive不是一个ACID模型数据库工具,不支持事务处理。
hive和传统数据库的对比

hive的数据存储
Hive的数据存储基于Hadoop HDFS
Hive没有专门的数据存储格式(txt、csv)
存储结构主要包括:数据库、表、视图、索引、数据(文件)
Hive默认可以直接加载文本文件(TextFile),还支持SequenceFile、RCFile
创建表时,指定Hive数据的列分隔符与行分隔符,Hive即可解析数据
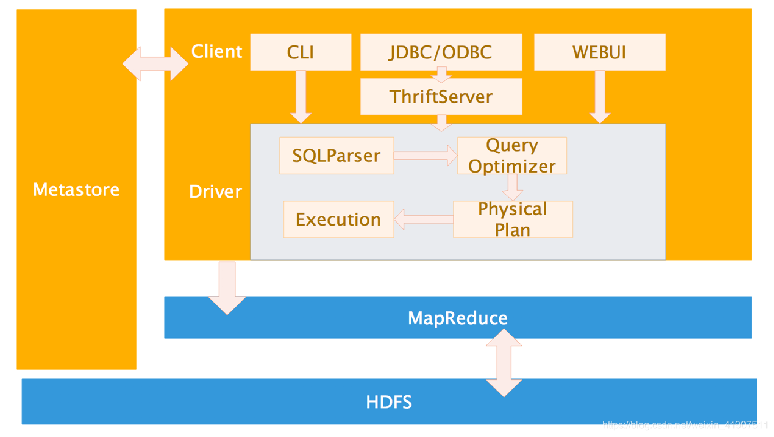
Hive的系统架构
用户接口,包括 CLI,JDBC/ODBC,WebUI
元数据存储,通常是存储在关系数据库如 mysql(常见的管理数据库), derby(默认自带数据库)中
内部运行自带:解释器、编译器、优化器、执行器
Hadoop:用 HDFS 进行存储,利用 MapReduce 进行计算
Hive运行模式
hive的运行模式有三种
本地模式、伪分布式模式和分布式模式
本地模式\伪分布式:这种模式下使用的是本地文件系统。在本地模式下,当执行Hadoopjob时(包含有大多数的Hive查询),Maptask和Reducetask在同一个进程中执行。
分布式模式:没有完整URL指定的路径默认都是分布式文件系统(通常是HDFS)中的路径,而且由JobTracker服务来管理job,不同的task 在不同的进程中执行。
即使在分布式模式下执行, Hive还是可以在提交查询前 判断是否可以使用本地模式来执行这个查询。这时它会读取数据文件,然后自己管理 MapReduce task,最终提供更快的执行方式。
hive相关操作指令
本文省略安装部署
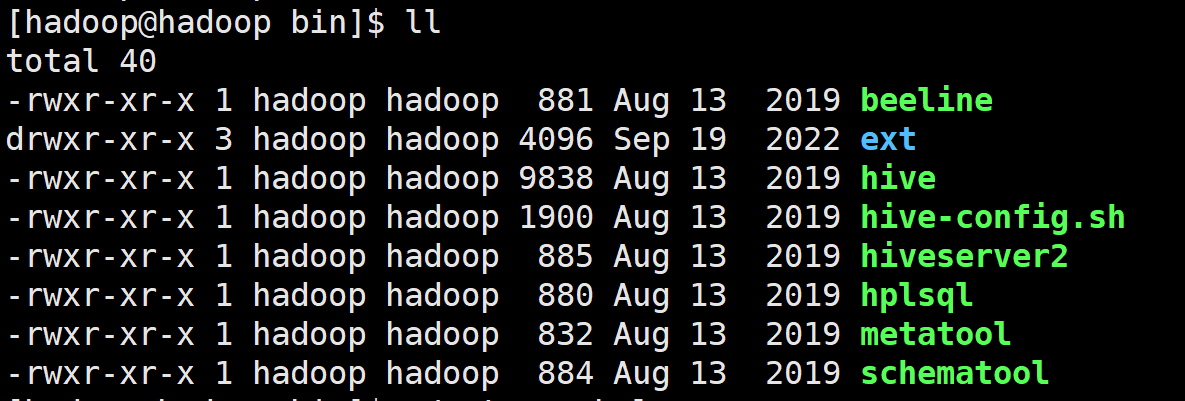
在hive的bin目录下有以下相关指令
beeline
ext
hive
hive-config.sh
hiveserver2
hplsql
metatool
schematool

beeline:
作用: beeline是Hive的客户端工具,用于与HiveServer2进行交互式查询和操作。
功能:
允许用户通过JDBC远程连接到HiveServer2进行查询和管理Hive数据库。
支持使用HiveQL语言执行查询、创建表、加载数据等操作。
提供了连接参数配置、认证方式选择、输出格式设置等功能。
支持脚本执行,可以批量执行HiveQL脚本文件中的查询和命令。
通过beeline链接hive时,需提前启动。
在hive手册中提供以下使用命令示例
Example:
1. Connect using simple authentication to HiveServer2 on localhost:10000
$ beeline -u jdbc:hive2://localhost:10000 username password
2. Connect using simple authentication to HiveServer2 on hs.local:10000 using -n for username and -p for password
$ beeline -n username -p password -u jdbc:hive2://hs2.local:10012
3. Connect using Kerberos authentication with hive/localhost@mydomain.com as HiveServer2 principal
$ beeline -u "jdbc:hive2://hs2.local:10013/default;principal=hive/localhost@mydomain.com"
4. Connect using SSL connection to HiveServer2 on localhost at 10000
$ beeline "jdbc:hive2://localhost:10000/default;ssl=true;sslTrustStore=/usr/local/truststore;trustStorePassword=mytruststorepassword"
5. Connect using LDAP authentication
$ beeline -u jdbc:hive2://hs2.local:10013/default <ldap-username> <ldap-password>
ext:
该文件夹并不是一个可执行文件,内部包含了所需的基本.shell脚本
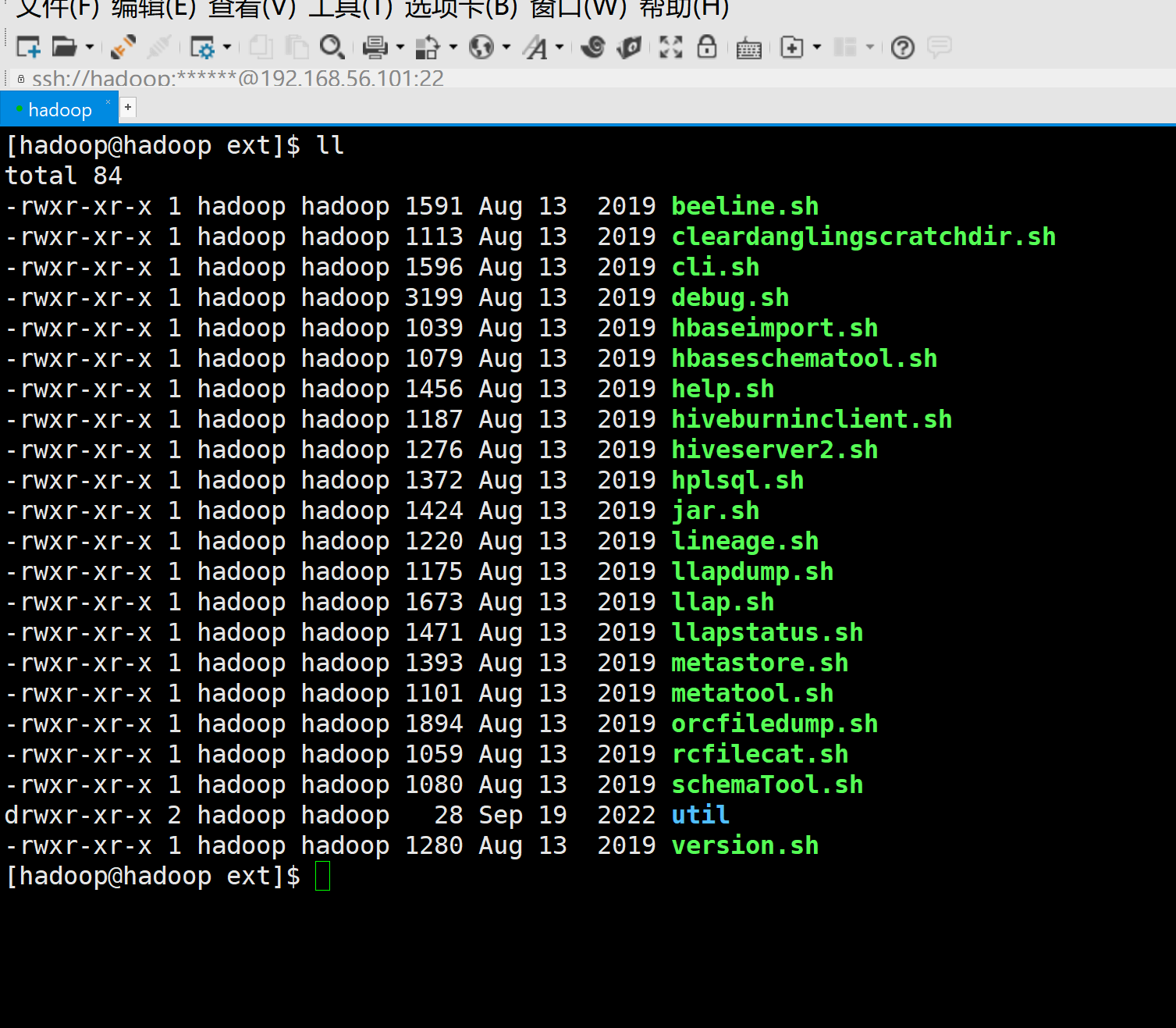
hive
是hive 本地的一个交互工具,
hive-config.sh
此命令是为变更hive运行的环境所使用,主要涉及
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# processes --config option from command line
#
this="$0"
while [ -h "$this" ]; do
ls=`ls -ld "$this"`
link=`expr "$ls" : '.*-> \(.*\)$'`
if expr "$link" : '.*/.*' > /dev/null; then
this="$link"
else
this=`dirname "$this"`/"$link"
fi
done
# convert relative path to absolute path
bin=`dirname "$this"`
script=`basename "$this"`
bin=`cd "$bin"; pwd`
this="$bin/$script"
# the root of the Hive installation
if [[ -z $HIVE_HOME ]] ; then
export HIVE_HOME=`dirname "$bin"`
fi
#check to see if the conf dir is given as an optional argument
while [ $# -gt 0 ]; do # Until you run out of parameters . . .
case "$1" in
--config)
shift
confdir=$1
shift
HIVE_CONF_DIR=$confdir
;;
--auxpath)
shift
HIVE_AUX_JARS_PATH=$1
shift
;;
*)
break;
;;
esac
done
# Allow alternate conf dir location.
HIVE_CONF_DIR="${HIVE_CONF_DIR:-$HIVE_HOME/conf}"
export HIVE_CONF_DIR=$HIVE_CONF_DIR
export HIVE_AUX_JARS_PATH=$HIVE_AUX_JARS_PATH
# Default to use 256MB
export HADOOP_HEAPSIZE=${HADOOP_HEAPSIZE:-256}
以上是hive-config.sh指令的文件内容,通过解读该指令文件的源码,该指令主要是接收
–config
–auxpath
两个指令参数,用变更hive的HIVE_CONF_DIR、HIVE_AUX_JARS_PATH环境变量,该操作方式并不推荐,读者可以忽略
hiveserver2
因为早期 HiveServer 不能处理多于一个客户端的并发请求,这是由于 HiveServer 使用的 Thrift 接口所导致的限制,不能通过修改 HiveServer 的代码修正。因此在 Hive-0.11.0 版本中重写了 HiveServer 代码得到了HiveServer2 ,进而解决了该问题。 HiveServer2 支持多客户端的并发和认证,为开放 API 客户端如 JDBC 、 ODBC 提供更好的支持。

nohup hive --service metastore &
nohup hive --service hiveserver2 &
启动hiveserver2,必须先启动其元数据库,源数据库的配置可参照往期hive的安装博客
hplsql
hplsql是一个客户端工具,hqlsql 通常用于执行hive的SQL脚本语句;
hqlsql -H
可以查看到相关的指令参数

示例
在当前路径创建一个用于hive 执行的一个SQL脚本文件
[hadoop@hadoop ~]$ cat hive_text.sql
use test_db;
create table hqlsqpl_text(id integer);
select * from hqlsqpl_text;
使用hplsql指令去运行该脚本文件
hplsql -f hive_text.sql
进入客户端可以看到表结构已经创建。
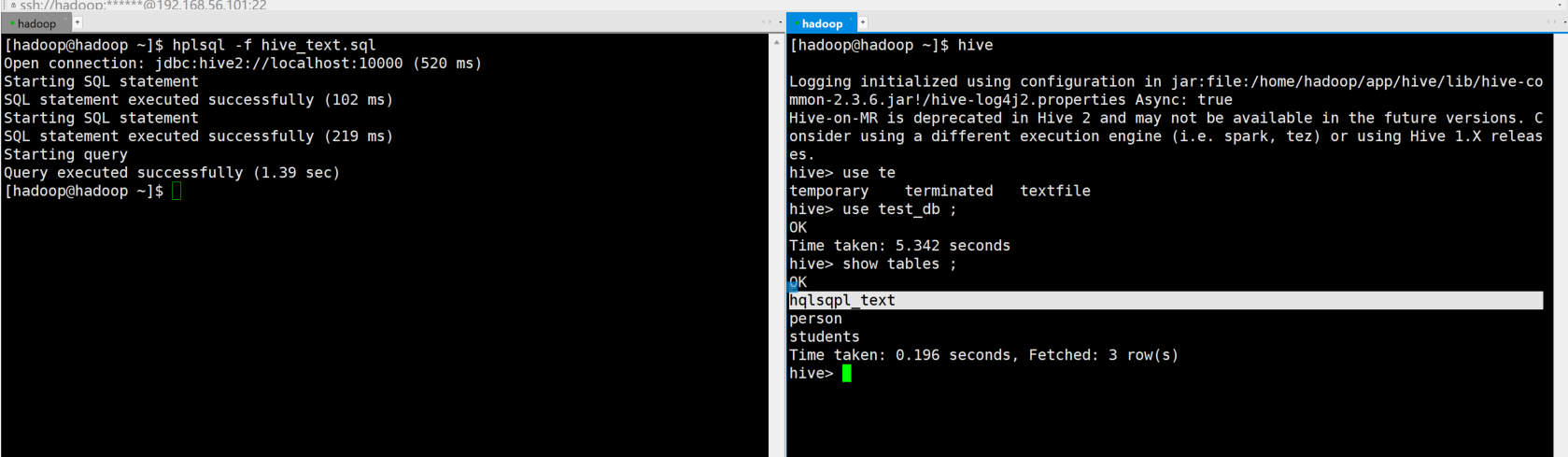
f参数是一个较为常用的指令。
e参数的使用范例
hplsql -e "USE test_db; SELECT * FROM hqlsqpl_text;"

这个指令其实较为鸡肋,hive并没有有效的
metatool
metatool是一个管理员对元数据进行管理和操作的一个指令。
能够在引用 NN 的元存储记录中搜索和替换 HDFS NN (NameNode) 位置。一种用途是将 Hive 部署转换为 HDFS HA NN(HDFS 高可用性名称节点)。
用于对元存储执行 JDOQL 的命令行工具 。对元存储执行 JDOQL 的功能对于用户和 Hive 开发人员来说都是一个有用的调试工具。
在使用metatool指令时,可指定以下参数
-serdePropKey <serde-prop-key>
S 特定于 SerDe 属性键,其值字段可能引用 HDFS NameNode 位置,因此可能需要更新。例如,若要更新 Haivvero 架构 URL,请为此参数指定 schema.url。
此选项仅对 updateLocation 选项有效。
-help
打印命令选项及其说明的列表。
-listFSRoot
打印当前文件系统根目录 (NameNode) 的位置。该值以 前缀。hdfs:// scheme
-dryRun
执行 updateLocation 更改的试运行 。将显示 updateLocation 更改,但不会保留。
此选项仅对 updateLocation 选项有效。
-executeJDOQL <query-string>
执行给定的 JDOQL 查询。
-tablePropKey <table-prop-key>
指定表属性键,其值字段可能引用 HDFS NameNode 位置,因此可能需要更新。例如,若要更新 Avro SerDe 架构 URL,请为此参数指定 avro.schema.url。
此选项仅对 updateLocation 选项有效。
-updateLocation <new-loc> <old-loc>
更新 Hive 元存储中的记录以指向新的 NameNode 位置(文件系统根位置)。new-loc 和 old-loc 都应该是具有有效主机名和方案的有效 URI。要升级到 HDFS HA NN,new-loc 应与属性的值匹配 。old-loc 应与 listFSRoot 选项返回的值匹配。dfs.nameservices
使用 dryRun 选项运行时 ,将显示更改,但不会保留更改。使用 serdepropKey/tablePropKey 选项运行时,updateLocation 会查找指定的 serde-prop-key/table-prop-key,并在找到时更新其值。
代码示例
查看元数据状态
hive --service metatool -listFSRoot
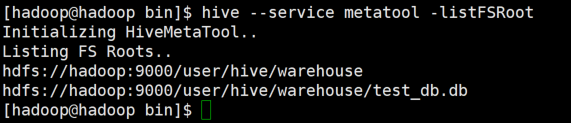
以上展示信息
hdfs://hadoop:9000/user/hive/warehouse:这是 Hive 默认的数据仓库目录。在这个目录下存放了所有 Hive 表的数据文件。
hdfs://hadoop:9000/user/hive/warehouse/test_db.db:这是一个数据库目录,test_db 是数据库的名称,.db 是数据库的后缀。在这个目录下存放了数据库 test_db 中所有表的数据文件。
-updateLocation示例
hive --service metatool -updateLocation hdfs://localhost:9000 hdfs://namenode2:8020 -tablePropKey avro.schema.url -serdePropKey avro.schema.url
使用 updateLocation ,tabletablePropKey 和 serdePropKey 选项将 NameNode 位置从 hdfs:// namenode2:8020 更新为 hdfs:// localhost:9000.
-executeJDOQL
执行给定的 JDOQL 查询。
查询所有表信息
hive --service metatool -executeJDOQL "select tableName from org.apache.hadoop.hive.metastore.model.MTable"
schematool
在安装hive 的时候 常用于初始化元数据库
schematool -dbType mysql -initSchema -verbose
查看当前版本以及元数据库JDBCurl信息
schematool -info -dbType mysql

这里显示的2.3并不是元数据库的信息 而是hive的版本号。
后续系列,马上更新,多多关注



