今天分享的一篇最近阅读的论文是FAST'23的SMRstore: A Storage Engine for Cloud Object Storage on HM-SMR Drives。
https://www.usenix.org/conference/fast23/presentation/zhou
这篇文章是由阿里巴巴公司完成的,在这篇文章中,团队针对SMR的特性提出了一种新的存储引擎SMRSTORE,该存储引擎充分利用了SMR更高的存储密度来降低最高15%成本,并通过优秀的设计使得效率与CMR集群相当,对于阿里云这样的大规模存储集群而言,降低15%的成本且不需要付出性能代价会带来很大的收益。
如果对于不了解SMR的读者,可以点击副推查看相应知识点,对SMR硬盘有了一定的认识后也就不难理解阿里提出该引擎的根本动机——降低成本。但是,要降低成本,必须要以可接受的最小限度的性能牺牲为前提,接下来,我们就继续来看看,阿里采用了什么手段来优化SMR的性能。
我们先把结论放在前面,以下的优化手段类似于ZNS:
1)SMRSTORE直接管理了全部的地址空间,取代了文件系统,将空间划分为zone,每个zone只能append顺序写入,禁止随机写入;
2)无论元数据还是数据,都采用log的形式写入SMR顺序zone;
3)GC是导致性能下降的关键,指导数据放置,设计相关策略,每个zone只允许相似生命周期的数据共享,并尽可能为大数据分配完整zone。
背景
对象存储往往需要使用到大量的HDD,成本效益是构建一个具有竞争力的云对象存储的关键挑战。由于SMR的出现,通过堆叠磁道相较于CMR增加了25%的存储密度,但是由于对随机写的限制,需要设计新的软件栈或存储引擎。
当前市面上针对HM-SMR存在三种软件栈设计方式,分别位于不同的层次,首先是块IO子系统层,通过设计STL将SMR映射成为普通块设备(dm-zoned),其次是文件系统层,支持日志结构或copy-on-write的文件系统也可以直接适配SMR特性(F2FS),最后是实现于应用层(GearDB)或是直接应用于Alibaba Archive Storage Service 、Huawei Object Store等服务。
文章分析认为,应用dm-zoned由于随机更新会使得吞吐量严重下滑,应用F2FS等文件系统由于大量GC会导致吞吐量的剧烈变化(文章第三章结合数据进行了测试),因此,前两种方法并不使用于实际,阿里巴巴团队选择了结合阿里OSS架构,利用ZBD接口,综合设计了GC、全日志化的直接设计了一个运行于用户态的存储引擎SMTSTORE。
OSS Workflow
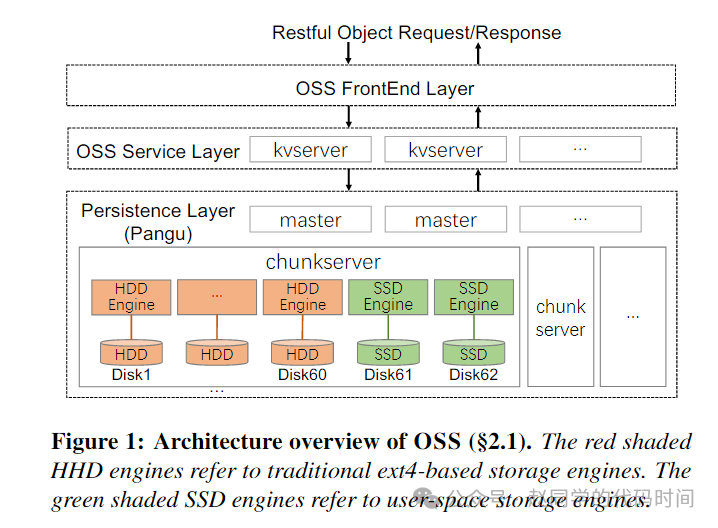
本次研发的SMRSTORE将应用于Alibaba Cloud Object Storage Service (OSS),因此,文章有必要介绍一下当前OSS工作流,OSS IO栈包含一个前端层、一个服务层和一个称为盘古的分布式存储持久化层,前端层的工作主要是处理HTTP请求,并将其发送到服务层,服务层由大量的KV服务器组成,它主要是两个职责,一个是将对象写入到盘古,另一个是使用基于LSM-Tree的KV存储维护对象的元数据(从对象名称到相应PANGU文件中的位置的映射),并将这些元数据写入额外的PANGU文件。
盘古是一个分布式文件系统,每个盘古集群由一组主服务器master和大量的仓储服务器chunkserver组成,主服务器中管理了盘古文件的元数据信息,仓储服务器中存储了盘古文件的具体数据。每个仓储服务器由60个负责存储的HDD和2个负责缓存的SSD组成,对于HDD利用Linux软件栈进行IO,采用EXT4文件系统管理,对于SSD则使用了一个自主设计的存储文件系统。
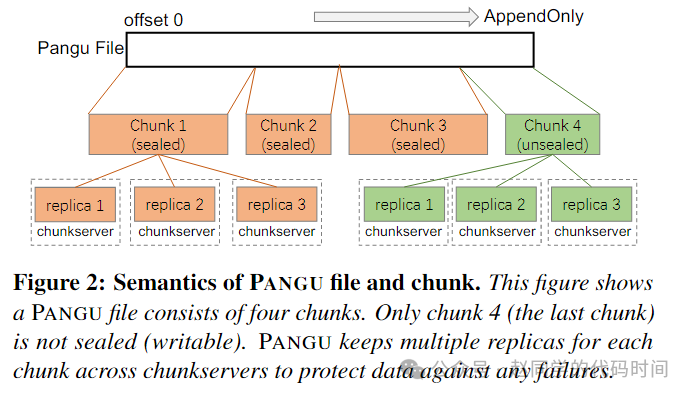
对于一个盘古文件,它都是一个只支持追加写的而且可能被切分存放于若干个大块Chunk,每个Chunk有一个唯一的UUID,盘古可以创建、追加写入、读、删除以及封装一个Chunk。封装操作会在1)Chunk大小达到限制;2)应用程序关闭了盘古文件或者写操作完成;3)遇到错误。时触发,因此,Chunk的大小不是固定的。对于一个盘古文件,只有最后一个Chunk可以被写入,只有已经封装的Chunk会从SSD缓存中持久化入HDD存储。盘古文件系统还设计了冗余和纠删码等功能以提供数据的容错能力。
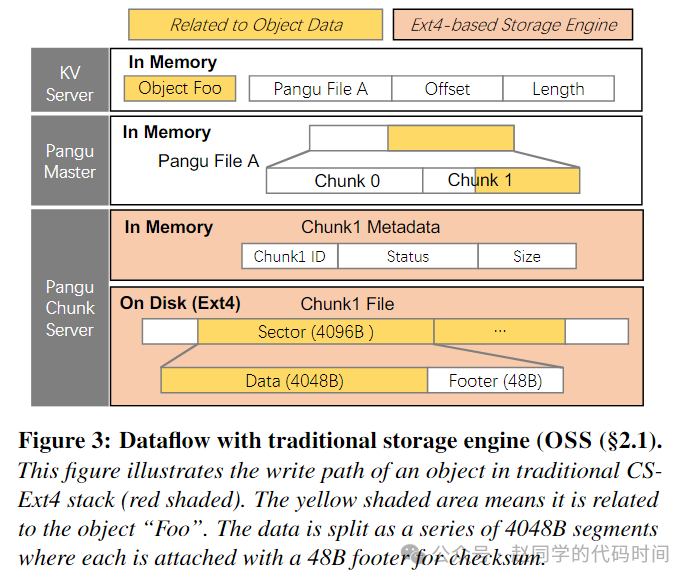
上图表示了传统OSS中数据流,我们假设要写入一个Object Foo,首先在KV Server中找到对应的盘古文件及其偏移和大小,然后KV Server联系盘古主服务器,定位对应盘古文件的最后一个chunk的chunkserver,并由这个chunkserver将数据追加写入chunk对应的EXT4文件中,为了数据完整性检验,每个写入被切分为4KB大小,前4048B为数据,后48B为段位置和Checksum的footer,在每个chunkserver中,每个chunk在EXT4文件系统中的名字就是它的ChunkID。
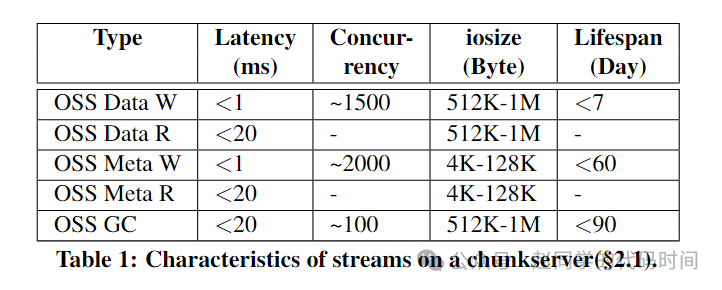
将一个打开的盘古文件定义为流,一个流始于KV服务器打开了一个盘古文件,终于KV服务器关闭了盘古文件,根据操作和数据类别的不同,可以将流划分为以下五种,并且它们具有不同的服务要求:
设计
从前面的背景中可以看出,HDD存在与仓储服务器中,将CMR替换为SMR在原来的EXT4+Kernel场景下已经不再适用,再结合之前的分析,无论是使用dm-zoned还是F2FS,都不足以满足阿里的高性能要求,因此,需要针对仓储服务器的HDD相关模块设计新的存储引擎以支持SMR。
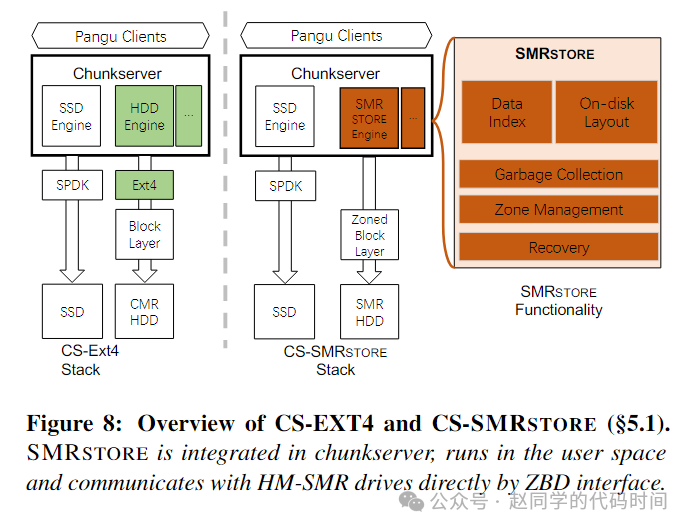
设计主要解决了以下几个关键挑战:
1)数据在存储引擎上应当如何排布?
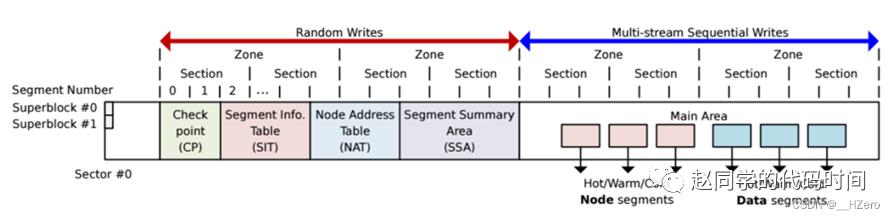
所有的地址空间都由SMRSTORE管理。地址空间被划分为superzone、metazone、datazone,采用“record”作为metazone和datazone的基本单元。这样的排布方式似乎有点类似于F2FS:
但是,无论metazone还是datazone,在SMRSTORE中均是日志化的顺序写入,以下图方式排列:
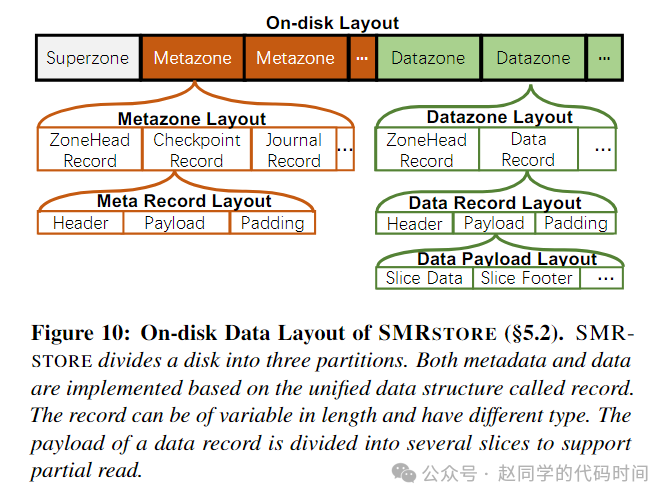
如图所示,superzone为第一个SMR zone,存放了格式化版本、时间戳和其他一些系统配置,metazone为紧接着400个zone,存放了SMRSTORE的一些元数据,它们由3种不同类别的record组成,剩余均为datazone,由2种类别的record组成,data record中的负载按4KB进行切片和添加footer,从而允许只对DataRecord进行部分读取并校验完整性。
2)在之前的EXT4系统中,采用ChunkID为文件名的方式,索引Chunk,在新的存储引擎中如何设计数据索引?
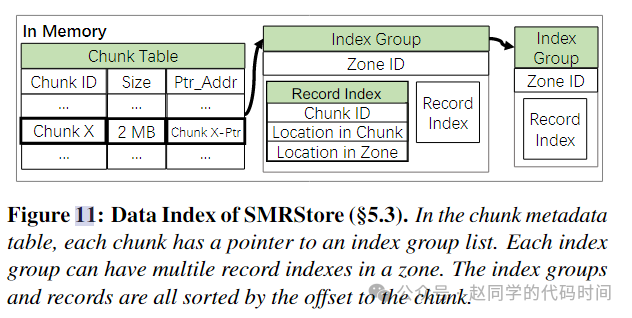
数据索引存在于内存中,建立了ChunkID+offset+size到Datazone+offset+size的三元组映射。一个Chunk可以有多个record,它们都按照数据在Chunk中的偏移进行排序并构成一个Index Group链表,链表的起始地址保存在ChunkTable中,对一个Chunk+offset+size的访问流程就是查ChunkTable,再查链表,从而定位Datazone+offset+size。
需要注意的是,具体的查找算法在论文中并没有讨论,采用的数据结构和占用内存大小也没有具体说明。
3)区块该如何管理?
区块管理上,SMRSTORE基本和ZNS一致,采用了一个状态转换自动机对zone进行管理:
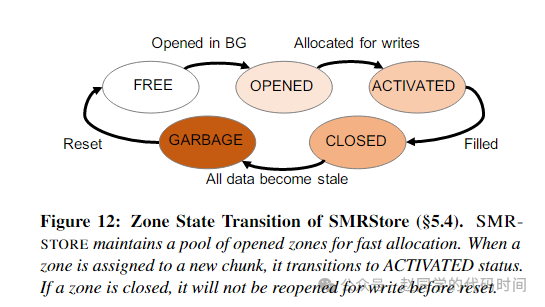
SMRSTORE维护了一个Zone Table,关联了ZoneID、状态、关联到zone的索引链表、写指针信息。在区块分配时,为了最大可能使得同一区块内的数据生命周期接近以及性能的稳定,分配时遵循以下原则:
仅允许相同流类型(见上表,他们具有接近的期望存在时间)的chunk共享一个datazone;
调整了最大的chunkSize=datazoneSize,使得对于大chunk,可以完整占据一个zone;
采用池化zone,为每个type的流预先分配和打开一定数量的zone。

4)垃圾回收应该怎么进行?
垃圾回收的步骤非常经典:受害段选择、数据迁移和元数据更新。受害段选择使用了贪心算法选取垃圾最多的zone回收,数据迁移时扫描zone关联的有效的索引,将他们的数据迁移到干净zone,并设置了一个动态的GC吞吐量阀门以避免后台GC对前台性能产生影响,元数据更新将对应的索引关系更新,即完成了整个垃圾回收过程。
5)启动时如何恢复当前拓扑结构?(recovery逻辑)
最后一个问题是如何恢复内存中数据结构,比如上面都有提及的metadata table和zone table,手段是将他们每隔一段时间存放在metazone里面。
SMRSTORE设计了checkpoint,作为当前内存中数据结构的快照。checkpoint由若干个record组成用于记录相关的table(例如,metadata table比较大,需要若干record,zone table通常一个table就够了),一个checkpoint从特殊的start_record开始,到end_record结束。
SMRSTORE 对于chunk的创建、封装、删除操作会写入journal记录,但是不会记录写入(性能考虑,但有其他方法可以确保相应结构正确),因为checkpoint的设计是non-blocking的,checkpoint的records可能会和journal交叉,journal的存在确保数据结构可以被正确恢复。

一个完整的恢复过程是:
找到最近的一个checkpoint,实现方法是直接扫描整个metazone区域(前400个zone);
将checkpoint加载入内存恢复出checkpoint快照保存下来的数据结构;
重放start-end之间的所有journal,恢复在checkpoint之后的操作;
扫描datazone,由于没有journal记录写入,应该扫描datazone,将对应的有效的元数据更新写入内存;
论文的实验部分不是本文重点关注的内容,感兴趣的读者可以自行阅读,阅读原文可以快速直达。









