ICLR 2024 REVIEWER打分 6666
1 论文介绍
- 论文提出了一种名为 Self-Debugging 的方法,通过执行生成的代码并基于代码和执行结果生成反馈信息,来引导模型进行调试
- 不同于需要额外训练/微调模型的方法,Self-Debugging 通过代码解释来指导模型识别实现错误
- 类似于人类程序员通过逐行向橡皮鸭解释代码行来提高调试效率的方法
2 论文方法
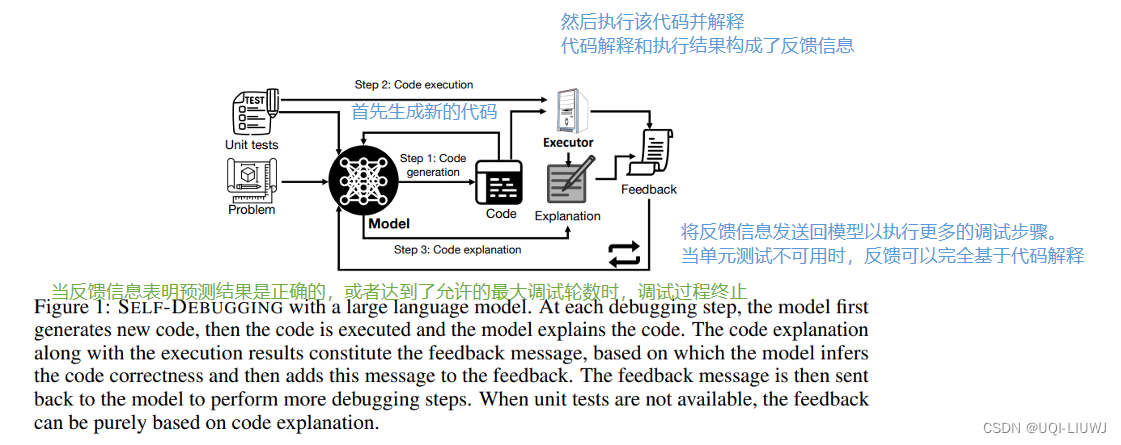
2.1 生成代码的prompt技术
2.1.1 Few-shot prompting
- 以文本到 SQL 生成为例,few-shot 提示在感兴趣的问题前面加上(question, SQL)对的列表
- 这样当模型被要求预测给定提示后的后续 token 时,它会按照提示的格式生成 SQL 查询语句

2.1.2 基于执行的代码选择
- 先前的研究表明,对于大型语言模型,在解码过程中生成多个预测结果可以显著提高性能
- Self-consistency improves chain of thought reasoning in language models, ICLR 2023
- 论文执行多次代码生成
- 选择在执行时没有遇到错误的预测中具有最频繁执行结果的代码,并对其应用 后续的Self-Debugging
- 一些代码生成任务伴随着单元测试,以指定程序的执行行为。在问题描述中给出单元测试时,执行基于多数投票的选择之前,会先过滤掉未通过单元测试的程序。
2.2 Self-Debugging 框架——反馈形式
- 现有的研究表明,语言模型可以通过训练来理解人类对代码的反馈,并根据指令进行修正。
- 然而,目前尚不清楚语言模型是否能够在没有人类辅助的情况下自行进行调试。
- 在接下来的讨论中,将探讨如何利用代码执行和 few-shot 提示来生成不同类型的自动获取和生成的反馈信息
2.2.1 简单反馈
- 最简单的自动反馈形式是一句话,仅指示代码的正确性,没有更详细的信息
- 比如:
-
“上面的SQL预测是正确的!”
-
“上面的 SQL 预测是错误的,请修正 SQL。”
-
- 比如:
2.2.2 单元测试(UT)
- 对于包含单元测试的代码生成任务,除了通过代码执行来检查代码的正确性外,还可以在反馈信息中呈现单元测试的执行结果,从而为调试提供更丰富的信息。
- 通过检查运行时错误消息和未通过的单元测试的执行结果,可以帮助人类程序员更有效地进行调试。
- 实验结果表明,利用单元测试可以显著提高调试性能。
2.2.3 代码解释
- 尽管大型语言模型在生成批评性反馈方面取得了一些进展,以避免生成有害的输出并在自然语言和推理任务中提高性能,但先前的研究尚未在代码生成任务中验证了反馈的有效性
- The capacity for moral self-correction in large language models.,arxiv 2023
- Reflexion: an autonomous agent with dynamic memory and self-reflection,arxiv 2023
- ——>论文提出通过解释生成的代码来教模型进行自我调试,而不是教它预测错误消息
- 调试过程类似于程序员通过向橡皮鸭逐行解释代码来进行调试。
- 研究验证了即使在没有单元测试的情况下,大型语言模型也可以从这种调试方法中获益。
2.2.4 模拟执行过程
- 当单元测试可用时,我们检查了另一种解释反馈格式,其中指导大型语言模型(LLM)逐行解释中间执行步骤
- 执行跟踪和逐行解释都来自模型生成,而不是代码执行
- 因此跟踪反馈不需要比纯代码解释反馈更多的信息(不需要访问中间执行状态)
2.2.5 几种反馈的对比










