文章目录
前言
在文章 1>>32的结果是1还是0 中提到了数据模型 L P 64 LP64 LP64 ,并提出这个数据模型主要是由 U n i x Unix Unix 以及类 U n i x Unix Unix 的操作系统使用居多,例如 L i n u x Linux Linux 。
除
L
P
64
LP64
LP64 外,在
64
b
i
t
64bit
64bit 下还有其余的数据模型,如下表所示:
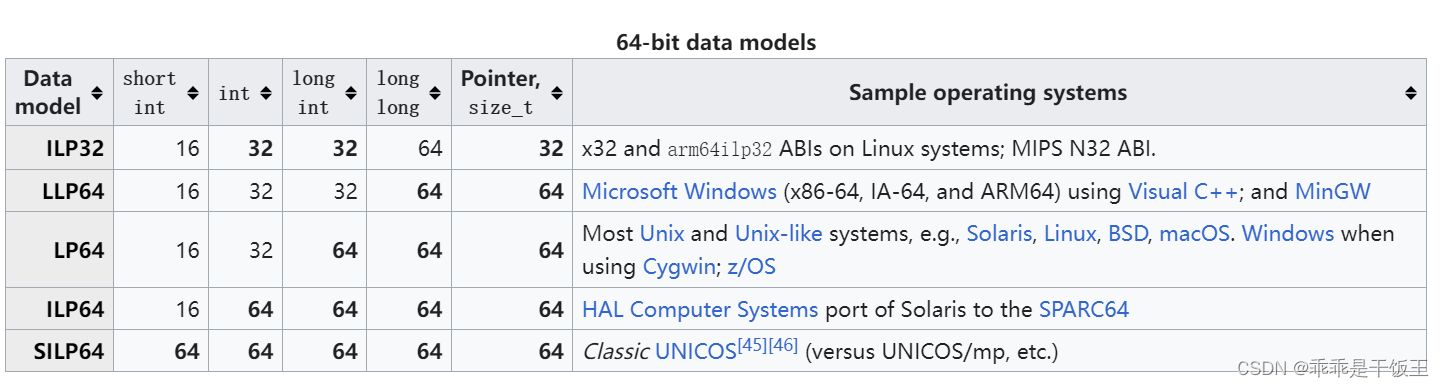 上表中
I
L
P
32
ILP32
ILP32 数据模型也用于许多具有 32 位处理器的平台。该模型减少了代码大小和包含指针的数据结构的大小,但代价是地址空间更小,适合嵌入式系统。
上表中
I
L
P
32
ILP32
ILP32 数据模型也用于许多具有 32 位处理器的平台。该模型减少了代码大小和包含指针的数据结构的大小,但代价是地址空间更小,适合嵌入式系统。
看过了上述所有数据模型,我们会引出疑问:对于C语言程序,用户书写代码并通过编译器编译为可执行文件执行,那么在这个过程中,由谁来决定数据模型的选择,是OS还是硬件架构,编译器又扮演什么角色?
巧的是,已经有人在 S t a c k O v e r f l o w StackOverflow StackOverflow 上问过这个问题了,原链接在文末。
硬件架构的作用
我们知道,现在应用最为广泛的 64 64 64 位指令集架构是 x 86 _ 64 x86\_64 x86_64,又名 a m d 64 amd64 amd64 或 x 64 x64 x64 。它是 a m d amd amd 公司在 I n t e l Intel Intel 的 i 386 i386 i386 的基础上于 1999 1999 1999 年提出的指令集,主要优点在于能够在 64 b i t 64bit 64bit 机器上运行 32 b i t 32bit 32bit 指令。所以我们在当前 64 b i t 64bit 64bit 机器上也可以运行 32 b i t 32bit 32bit 可执行程序。
但在此我们以
R
I
S
C
V
RISCV
RISCV 指令集
R
V
64
I
RV64I
RV64I 为例。其提供指令
L
D
LD
LD,
L
W
LW
LW,
L
H
LH
LH和
L
B
LB
LB用于加载数据。其中,
L
D
LD
LD加载
64
64
64 位数据到寄存器,
L
W
LW
LW用于加载
32
32
32 位数据并符号扩展到
64
64
64 位寄存器,
L
H
LH
LH用于加载
16
16
16 位数据并符号扩展到
64
64
64 位寄存器,
L
B
LB
LB用于加载
8
b
i
t
8bit
8bit 数据。
同样的,用于加载数据并零扩展的指令有:
L
W
U
LWU
LWU,
L
H
U
LHU
LHU,
L
B
U
LBU
LBU。
用于存储数据的指令有:
S
D
SD
SD,
S
W
SW
SW,
S
H
SH
SH,
S
B
SB
SB。
根据上述我们知道一个 R I S C V RISCV RISCV 硬件可能支持多种操作模式,从 8 − 64 b i t 8-64bit 8−64bit 。
但只有硬件不够,还需要有OS的支持。我们可以在 64 b i t 64bit 64bit 处理器上运行 32 b i t 32bit 32bit 的OS,同时还可以在 64 b i t 64bit 64bit 的OS上运行 32 b i t 32bit 32bit 的用户程序。
OS的作用
在运行 L i n u x Linux Linux 中的程序时,程序可以遵循 I L P 32 ILP32 ILP32 和 L P 64 LP64 LP64 模型。当我在 W i n d o w s Windows Windows 系统时,程序可以遵循 I L P 32 ILP32 ILP32 和 L L P 64 LLP64 LLP64 模型。因此,即使在同一组硬件上,可以有两个操作系统待选择,不同OS在编译时又有两个“平台”可供选择。
以
L
i
n
u
x
Linux
Linux 为例,用户在编译时的选择中的两个常见的
L
i
n
u
x
Linux
Linux 平台为 x86_64-pc-linux-gnu 和 i386-pc-linux-gnu,分别对应
64
64
64 和
32
32
32 位用户程序。
编译器的角色
编译器主要对用户程序产生影响,我们知道,在 L i n u x 64 Linux64 Linux64 位系统中使用 G C C GCC GCC 编译程序时可以选择编译为 32 32 32 位或选择默认编译为 64 64 64 位可执行程序。那么编译器会根据编译参数,同时结合当前OS,即用户所处环境,强制用户程序所遵循的数据模型。
例如:用户在 l i n u x 64 linux64 linux64 下取用默认选项,那么其可执行程序为 64 b i t 64bit 64bit 程序且数据模型为 L P 64 LP64 LP64。同样的,在 w i n d o w 64 window64 window64 下我们使用 V i s u a l S t u d i o Visual \ Studio Visual Studio 指定编译选项为 x 64 x64 x64 时,其数据模型为 L L P 64 LLP64 LLP64。用户指定编译结果为 32 b i t 32bit 32bit 的话则统一编译为数据模型为 I L P 32 ILP32 ILP32 的可执行程序。
OS的数据模型
OS作为一种系统软件其必须遵循一种数据模型。OS的数据模型一定程度上受到硬件架构的影响,其选择的数据模型在所处硬件上必须支持,同时OS可以在范围内有自己的选择,这也导致了 L i n u x Linux Linux 和 W i n d o w s Windows Windows 数据模型的不同。
例如:32位处理器OS可以选择 I L P 32 ILP32 ILP32 和 L P 32 LP32 LP32 数据模型,但是在 L P 32 LP32 LP32 数据模型中, i n t int int 大小为 16 b i t 16bit 16bit,那么在 i 386 i386 i386 的处理器则不支持,由于在 32 b i t 32bit 32bit 模式下 16 b i t 16bit 16bit 数据的操作码比 32 b i t 32bit 32bit 更长更慢。
例如: L i n u x 64 Linux64 Linux64 遵循 L P 64 LP64 LP64 而 W i n d o w s 64 Windows64 Windows64 遵循 L L P 64 LLP64 LLP64 数据模型。
参考
原StackOverflow问答地址。希望对大家有所帮助。










